Diminuindo tempo de resposta de uma API GraphQL fazendo cache de consultas no MongoDB
No seguinte artigo, o autor apresenta alguns métodos para otimizar o tempo de resposta de uma API desenvolvida em GraphQL.

Neste artigo quero compartilhar como fiz para reduzir o tempo de resposta de uma API desenvolvida em GraphQL fazendo cache das consultas no MongoDB.
Um pouco sobre cache
Cache é uma técnica comum e muito utilizada para melhorar a performance de qualquer aplicação, seja ela mobile, web, etc. Usando esta técnica, podemos poupar chamadas à banco de dados, requisições em API de terceiros, criando localmente no servidor uma cópia da requisição anterior.
Quando desenvolvemos uma aplicação web em conjunto com uma base de dados, cada requisição que fazemos ao servidor, pode implicar em uma ou mais requisições à base de dados e/ou algum processamento interno antes do servidor enviar a resposta para o cliente.
Durante esse texto vou explicar com mais detalhes sobre a implementação, mas só para você ter uma ideia, vou resumir o contexto.
Considere uma base de dados que armazena todos os artigos de um blog com as seguintes informações:
- _id
- titulo
- autor
- texto
- comentários
Imagine o cenário onde temos várias requisições para o nosso servidor buscando pela lista de autores. Imaginou? Várias requisições para obter – quase sempre – o mesmo dado.
API GraphQL
A API tem as seguintes entidades:
- Posts
- Comentários
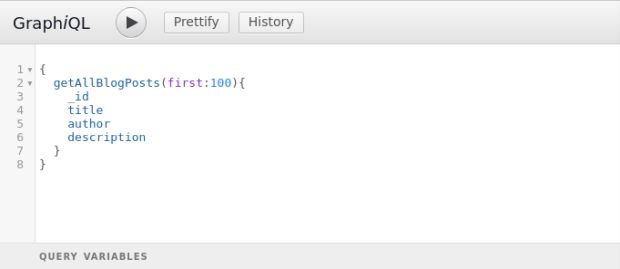
Diferente do Rest, que é baseado em endpoints, o GraphQL é baseado em, basicamente, dois esquemas: query e mutation. Um para consulta e outro para inserção de dados, respectivamente. A query da API desenvolvida nesse caso, possui os fields para buscar todos os artigos de um blog, todos os comentários de um determinado artigo e um artigo específico.
Em GraphQL, a resolução de uma operação é feita através do método resolve.
async resolve (root, {first = null, skip = null}, options, ast) {
return await BlogPostModel.getAllPosts(skip, first, ast);
}
Esse resolver recebe seus quatro parâmetros posicionais. Vamos trabalhar apenas com o segundo e o quarto.
No segundo parâmetro, um objeto com as propriedades first e null são definidos para efeito de paginação de resultados.
O quarto é o AST, que recebe quais informações foram solicitadas pelo cliente. Por exemplo, se na consulta o cliente solicitou apenas o autor e o titulo dos artigos, é através do ast que faremos a consulta no banco com base no que exatamente foi pedido pelo cliente.
Implementando o cache
Para implementar o cache na API, usei um pacote chamado node-cache que você pode instalar com o comando npm i node-cache -S
Ao invés de usar a própria API da node-cache, criei um módulo e assim tenho a vantagem do reaproveitamento de código.
export default (ttlInSeconds = 120) => {
const cache = new NodeCache({
stdTTL: ttlInSeconds,
checkperiod: ttlInSeconds * 10
});
const get = async (key, queryFunction) => {
const result = cache.get(key);
if (!result) {
const data = await queryFunction();
cache.set(key, data);
return data;
}
return result;
}
const flushAll = async () => {
cache.flushAll();
}
const remove = async (cacheKey) => {
cache.del(cacheKey);
}
return {
get,
flushAll,
remove
}
O módulo é uma função que recebe um parâmetro, onde é definido – em segundos – por quanto tempo o cache de cada elemento irá durar. Caso nenhum valor seja passado, por default, o cache irá durar por dois minutos. Mas se quisermos que o cache dure infinitamente, basta passarmos o valor 0.
Logo em seguida é criada uma nova instância de NodeCache, definindo as propriedades stdTTL onde passamos o valor de ttlInSeconds, para de fato definir por quanto tempo o cache ficará ativo e checkperiod onde setamos, em segundos, o intervalo de tempo onde a lib irá automaticamente deletar o cache. Nesse exemplo, após 20 minutos.
Depois definimos três funções:
- get: Recebe dois parâmetros, key que recebe um identificador único do cache e queryFunction que é uma função de callback que executa a função que busca o dado no banco.
Através do método get da API da Node Cache, verificamos se já existe um cache através da key. Caso não exista, é realizada a consulta no banco, o resultado é armazenado no cache com sua key correspondente e retornado o resultado para o cliente. Caso contrário, é retornado o resultado que já está no cache.
- flushAll: Que limpa todo o cache e todas as keys.
remove: Função que remove do cache o valor referente a key recebida como argumento.
Voltando para a API
Agora que já vimos a implementação do serviço responsável por manipular o cache, vamos fazer uso dele nos resolvers.
Vamos refatorar o resolver que retorna todos os dados do banco e que foi declarado no inicio desse texto para fazer uso do cache. Pra isso, precisamos seguir alguns passos:
- Gerar uma key única
- Chamar o método get do serviço de cache, passando a key gerada e a função que busca o dado no banco.
- Se o dado requisitado estiver no cache, então é retornado. Caso contrário todo o processo de busca no banco e armazenamento no cache é efetuado.
Para gerar a key, adotei a seguinte estratégia: como o GraphQL permite que o usuário peça na requisição apenas os campos que ele necessita, então a key é composta pelos nomes dos campos e os campos de paginação, field e skip, separados por _. Isso é feito através do quarto parâmetro recebido no resolver, o AST, onde armazemos em uma variável como string, ficando da seguinte forma:
const fields = JSON.stringify(ast);
const key = `${ fields }_${ first }_${ skip }`;
Agora fazemos uma chamada para o método get do serviço de cache passando a key e uma função de callback, que é executada caso a key não seja encontrada no cache. O resultado é retornado, sendo ou não do cache, ficando da seguinte forma:
return await cache.get(key, () => BlogPostModel.getAllPosts(skip, first, select));
O código completo do resolver ficou da seguinte forma:
async resolve (root, {first = null, skip = null}, options, ast) {
const fields = JSON.stringify(ast);
const key = `${ fields }_${ first }_${ skip }`;
return await cache.get(key, () => BlogPostModel.getAllPosts(skip, first, select));
}
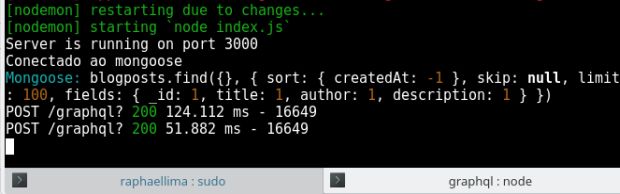
Resultados
Aplicando o cache nas consultas feitas no MongoDB, consegui diminuir em mais da metade o tempo de resposta da API em uma requisição que busca por 100 posts, conforme abaixo:
E quando a base de dados é atualizada?
Quando é inserido ou atualizado um registro no banco, basta chamar a função para limpar todo o cache, que nesse caso é a função flushAll().
O resolver da mutation add ficou dessa forma:
async resolve (root, params) {
const post = new BlogPostModel(params.data);
const result = await post.save();
if(!result) throw new Error('Erro ao adicionar um post');
cache.flushAll();
return result;
}
Finalizando
Se você quiser explorar um pouco mais a biblioteca node-cache e também aprender um pouco sobre GraphQL, dê uma olhada nos links abaixo:
Bom, por enquanto é só. Se você gostou, passe esse artigo pra frente. Poderá ajudar outros devs!
Bacharel em Ciência da Computação, trabalha com suporte e desenvolvimento web com as tecnologias JavaScript e Python. Entusiasta do movimento Software Livre, apaixonando por desenvolvimento de software, procurando sempre se manter atualizado com as novas tecnologias, aplicando-as na prática afim de buscar a combinação entre melhor solução e resolução de problemas. Além disso, acredita que conhecimento deve ser compartilhado e por isso publica textos, vídeos e tutoriais na internet afim de ajudar outras pessoas.