ChAP: Chaos Automation Platform

Uma das ferramentas mais interessantes da Netflix, do meu ponto de vista é o Chaos, e agora a Netflix anunciou o ChAP, o mais novo membro da família de ferramentas de chaos. O Chaos Monkey e o Chaos Kong são as ferramentas que garantem a resiliência a falhas de instâncias e regionais, porém, ameaças à disponibilidade também podem surgir de interrupções no nível dos microsserviços. Para se prevenir disso, eles desenvolveram o FIT, uma ferramenta que tem o intuito de injetar falhas no nível de microsserviços em produção. Em contra partida desenvolveram o ChAP, que tem o objetivo de superar as limitações do FIT para que assim eles possam aumentar a segurança, a cadência e a amplitude da experimentação.
Em um nível elevado, a plataforma interroga o pipeline de implementação para um serviço especificado pelo usuário. Em seguida, ela lança conjuntos de experiências e controle desse serviço e encaminha uma pequena quantidade de tráfego para cada um. Um cenário FIT especificado é aplicado ao grupo experimental, e os resultados da experiência são relatados ao proprietário do serviço.
Tamanho do experimento
Para que uma ferramenta desse tipo seja confiável ela não pode perturbar a experiência do cliente. De acordo com os Princípios Avançados da Engenharia do Chaos, os experimentos devem ser executados em produção. Para fazer isso, a Netflix precisa colocar alguns pedidos em risco para proteger sua disponibilidade geral. Como o teste é feito em produção, existe a necessidade de manter esse o risco em um nível mínimo. Isso levanta a questão: qual é o menor experimento possível de ser executado que ainda dá confiança no resultado?
Com o FIT, o impacto de um experimento afeta métricas para todo o sistema. As estatísticas da população experimental são misturadas com a população restante. O tamanho da população experimental (e o tamanho do efeito) deve ser grande para ser detectável no ruído natural do sistema.
Aqui está um gráfico de exemplo de um experimento FIT:
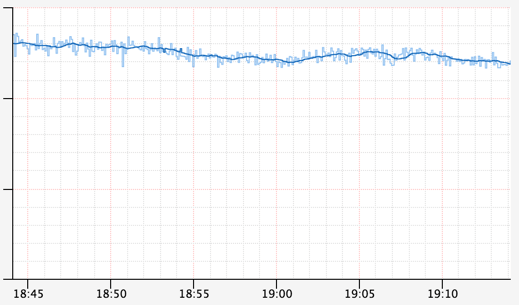
Legenda da imagem: Métrica variável de um experimento FIT. O evento foi apresentado em torno de 19:07
As perguntas que a Netflix se fez fora as seguintes, você pode determinar quando o experimento foi executado? Isso teve um impacto maior do que o ruído do sistema? A fim de criar maiores diferenças verificáveis por humanos e máquinas, os usuários acabaram por executar experimentos maiores e mais longos, arriscando interrupções desnecessárias para seus clientes.
Para limitar esse raio de explosão, no ChAP foi utilizado um pequeno subconjunto de tráfego e distribuído uniformemente entre um controle e um cluster experimental. Então eles escreveram um trabalho Mantis que rastreia seus KPIs apenas para usuários e dispositivos em cada um desses clusters. Isso torna muito mais fácil para seres humanos e computadores verem quando o experimento e os comportamentos de controle das populações divergem.
Aqui está um gráfico de exemplo de um experimento ChAP:
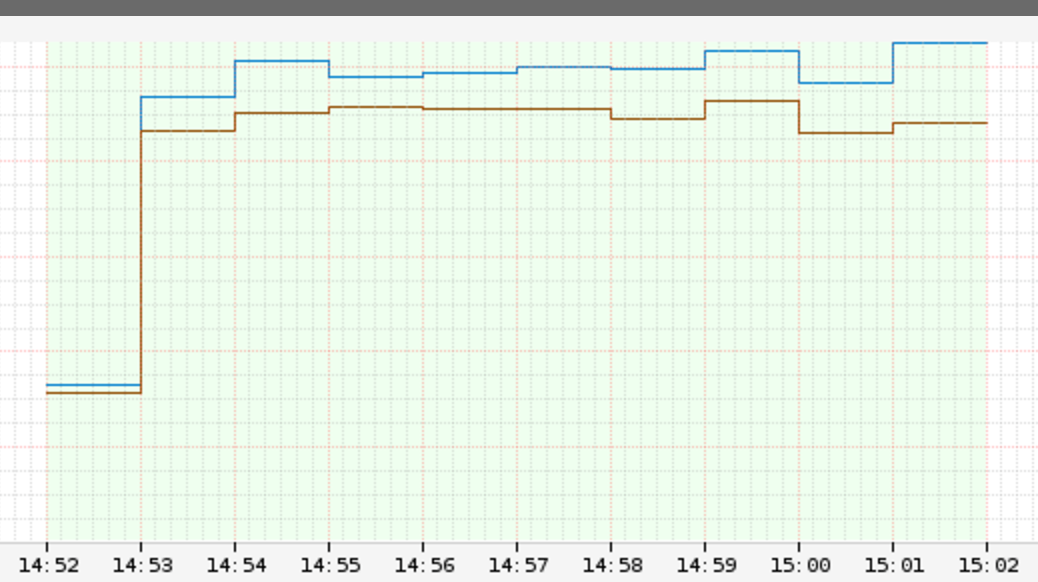
Legenda da imagem: Métricas comparativas para população experimental (vermelho, linha inferior) e população de controle (azul, linha superior).
É muito mais fácil ver como a população experimental divergiu do controle, mesmo que a população impactada fosse muito menor do que no experimento FIT.
Automação
Qualquer alteração no ambiente de produção altera a resiliência do sistema. Na Netflix, o ambiente de produção pode ver muitas centenas de implementações todos os dias. Como resultado, sua confiança em um resultado experimental diminui rapidamente com o tempo.
Para que os experimentos funcionassem sem supervisão, era necessário torná-los seguros. Assim, foi criado um disjuntor para o experimento que o encerraria automaticamente caso o orçamento de erro predefinido se excedesse. Uma análise automatizada e contínua se encaixa no mesmo sistema que é utilizado para fazer análises canário.
Antes do ChAP ser implementado, a Netflix dizia que uma vulnerabilidade podia ser identificada e corrigida, mas que em seguida, ela poderia regredir e causar um incidente. Afim de manter seus resultados atualizados, eles integraram o ChAP com o Spinnaker, seu sistema CI + CD para executar experimentos com frequência e continuamente. Desde a implementação dessa funcionalidade, eles relataram que foram, identificadas e impedidas, com sucesso as regressões de ameaça à resiliência.
Concentração
Alguns modos de falha só são visíveis quando a proporção de falhas para pedidos totais em um sistema cruza determinados limiares. O balanceamento de carga e o roteamento de pedidos para pedidos ornamentados com o FIT foram distribuídos uniformemente em toda a capacidade de produção da Netflix. Isso permitiu o aumento do consumo de recursos que deveriam ser absorvido pelo espaço livre de operação normal, que não conseguiu disparar os disjuntores. Esse experimento foi chamado de “difuso”. A ideia é que é bom verificar a correção lógica dos fallbacks, mas não as características do sistema durante a falha em escala.
Existem limiares críticos que são cruzados apenas quando uma grande parte dos pedidos está altamente latente ou falhando. Alguns exemplos:
- Quando um serviço downstream está latente, os pools de threads podem estar esgotados;
- Quando um fallback é computacionalmente mais caro do que o caminho feliz o uso da CPU aumenta;
- Quando os erros conduzem a exceções registradas, a contenção de bloqueio pode se tornar um problema em seu sistema de log;
- Enquanto tentativas agressivas ocorrem, você pode ter um ataque autoinfligido de negação de serviço.
Com tudo isso em mente, o objetivo da Netflix é alcançar uma alta proporção de falhas ou latência, limitando o potencial impacto negativo nos usuários. Semelhante à forma de segregar os KPIs para o experimento e controlar as populações, eles querem separar algumas máquinas para sofrer uma pressão extrema, enquanto o resto do sistema não foi afetado.
Exemplo
Digamos que eles querem explorar como a API, lida com a falha do sistema de classificação, o que permite que as pessoas avaliem filmes, dando-lhes um thumbs-up ou thumbs-down. Para configurar o experimento, foram implementados novos clusters de API que são proporcionalmente dimensionados para o tamanho da população que eles querem estudar. Para um experimento que afetou 0,5% da população em um sistema com 200 instâncias, geraríamos o experimento e controlaríamos clusters com uma instância cada.
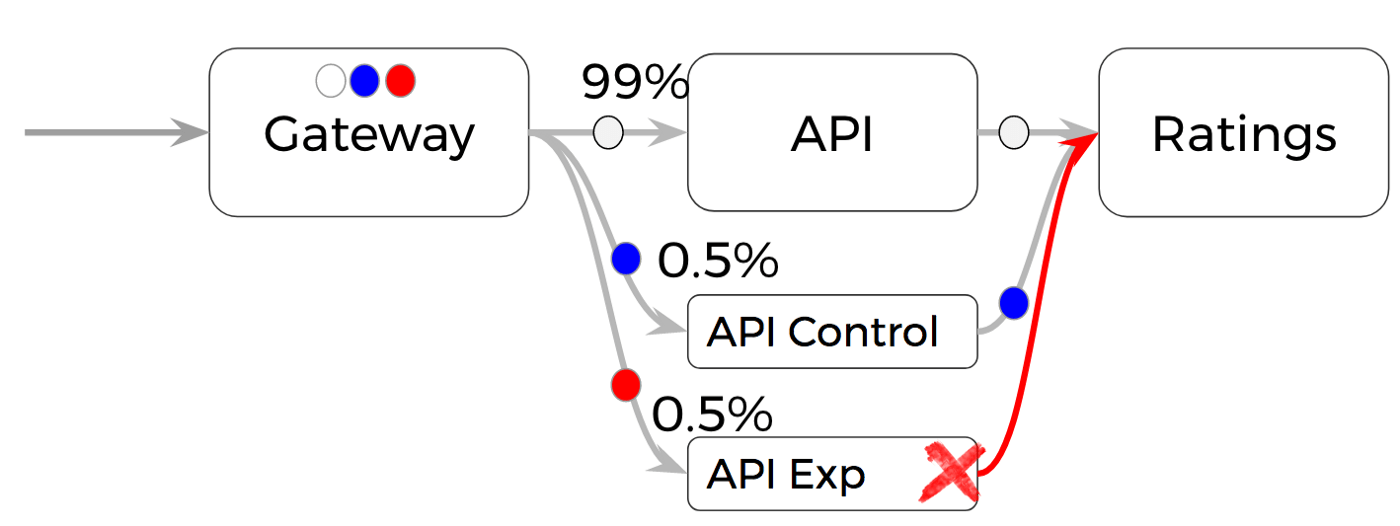
Em seguida, eles substituíram o roteamento de pedidos para as populações de controle e experimental para direcionar apenas esse tráfego para os novos clusters em vez do cluster de produção regular. Uma vez que apenas o tráfego experimental está sendo enviado para o cluster “experimento”, 100% dos pedidos entre API-experimento e classificação serão afetados. Isso verificará se a API pode realmente lida com qualquer carga aumentada que o cenário de falha possa causar. Esta classe de experimentos é chamada de “concentrados”.
O resultado? ChAP gera e-mails como o seguinte:
“TL; DR: executamos um ChAP canario que verifica que o caminho de fallback do [serviço em questão] funciona (crucial para a nossa disponibilidade) e conseguiu capturar um problema no caminho de fallback e o problema foi resolvido antes de resultar em qualquer incidente de disponibilidade!”
– um deslumbrante colega da Netflix
Com o ChAP, foi possível identificar de forma segura as políticas de reação incorretas, as falhas intensivas de CPU e as interações inesperadas entre disjuntores e balanceadores de carga.
Aprenda mais sobre Chaos
A Netflix escreveu o livro sobre Chaos Engineering, disponível gratuitamente por um tempo limitado em O’Reilly.
Aaron Blohowiak falou, na Velocity 2017 San Jose, sobre o tópico Precision Chaos.
Nora Jones também apresentou uma palestra na Velocity San Jose sobre nossas experiências com a adoção de ferramentas de chaos.
Fonte: https://medium.com/netflix-techblog/chap-chaos-automation-platform-53e6d528371f
Alex Lattaro é Mestre em Inteligência Artificial pela Unicamp e tecnólogo em Análise e Desenvolvimento de Sistemas pelo IFSP. Já trabalhou como líder de conteúdo no Imasters e na Microsoft, foi Especialista em Ciência de Dados na Kroton, Ilumeo e Santander e também atuou como professor no Samsung Ocean na Unicamp, ministrando aulas de Python, Ciência de Dados e Inteligência Artificial. Atualmente trabalha como especialista de projetos na Facti.