

O trabalho de IA que prioriza o estímulo inicial é ótimo para exploração. Mas não é suficiente para a entrega.
Quando o trabalho começa a importar, as perguntas mudam. Precisamos saber o que a funcionalidade deve fazer, o que está fora do escopo, como o backend e o frontend se integram, como validamos o fluxo e como mantemos a IA dentro dos limites que realmente desejamos. É aí que o desenvolvimento orientado a especificações se torna útil.
Um dos motivos pelos quais criei essa estrutura (e a desenvolvi deliberadamente passo a passo) é que observo uma divisão real nas equipes de engenharia atualmente. Engenheiros seniores, que já possuem fundamentos sólidos, tendem a se adaptar rapidamente às ferramentas de IA. Engenheiros juniores, que ainda estão construindo esses fundamentos, muitas vezes têm dificuldade em obter resultados consistentes. Um fluxo de trabalho vago amplia essa lacuna. Um fluxo estruturado ajuda a reduzi-la. Meu objetivo com o SDD é fornecer às equipes com diferentes níveis de experiência um processo compartilhado que todos possam seguir, para que a qualidade do resultado não dependa exclusivamente do tempo de experiência em programação de cada um.
Neste post, quero mostrar o caminho completo que recomendo para uma funcionalidade real: integrar um repositório ao fluxo de trabalho, escrever a especificação, revisá-la, projetar a solução, implementar o backend em Spring Boot, adicionar a camada Angular e fechar o ciclo com validação de ponta a ponta. Os exemplos são baseados na estrutura de desenvolvimento orientado a especificações que criei, portanto, não se trata apenas de teoria: eu a utilizo para realmente entregar código em produção em um ambiente corporativo.
Para facilitar a compreensão do contraste, aqui está a diferença entre a programação orientada a instruções (prompt-first) e o desenvolvimento orientado a especificações (spec-driven):
| Aspecto | Prompt-First (Vibe) | Orientado por especificações (SDD) |
|---|---|---|
| Fonte da verdade | O histórico da conversa | O .specarquivo no repositório |
| Controle de escopo | “Melhor esforço” da IA | Objetivos não definidos explicitamente |
| alinhamento multicamadas | É difícil manter as camadas sincronizadas. | Alinhamento com foco no contrato |
| Risco de deriva | Alto: a intenção só existe no histórico do chat. | Baixa: a intenção persiste no repositório. |
| Resultado | Exploração / prototipagem | Entrega pronta para produção |
Neste post, abordaremos:
- Como integrar um repositório existente ao fluxo de trabalho orientado a especificações
- Como escrever uma especificação antes de qualquer projeto ou código.
- Como revisar a especificação em busca de ambiguidades e decisões ausentes.
- Como transformar a especificação em projeto de alto e baixo nível
- Como implementar o backend em Spring Boot primeiro
- Como adicionar o componente Angular acima do contrato de backend
- Como validar todo o fluxo de ponta a ponta
Este post não trata de truques de incentivo. Trata-se de um post sobre como construir um fluxo de trabalho que torne a entrega assistida por IA previsível.
0. Integre o repositório e instale o fluxo de trabalho.
Antes da primeira especificação, o repositório precisa estar alinhado com o fluxo de trabalho. Se o repositório não tiver os artefatos corretos, a IA não terá um modelo operacional compartilhado para seguir. Ela ainda poderá gerar código, mas não o fará dentro de um processo claro.
Por isso, o processo de integração vem em primeiro lugar.
Nesta etapa, o objetivo não é construir uma funcionalidade. O objetivo é preparar o repositório para que o fluxo de trabalho seja reproduzível. Isso significa:
- Identificando a pilha de tecnologias e o formato atual do projeto.
- Confirmar se o repositório é novo ou já existente.
- Adicionando as pastas de fluxo de trabalho e os artefatos de especificação.
- Copiar os agentes, habilidades, prompts e modelos para o repositório de destino.
- Garantir que o repositório esteja pronto para a primeira
/specexecução.
Se você estiver usando a estrutura que eu desenvolvi, é aqui que o repositório obtém a estrutura necessária para suportar o processo, em vez de combatê-lo. Na prática, isso significa que a etapa de integração deve produzir um ponto de partida mínimo, porém explícito: a classificação da pilha, o estado inicial e os arquivos de fluxo de trabalho que a IA usará a partir desse ponto.
Uma boa maneira de pensar sobre essa etapa é simples: antes de pedir à IA para escrever uma especificação, certifique-se de que o repositório possa suportar um fluxo de trabalho orientado por especificações sem necessidade de adivinhação.
O exemplo usado ao longo deste post é o sdd-spring-angular-example , um monorepo com dois subprojetos: sdd-api(Spring Boot 4 com MySQL) e sdd-ui(Angular 21). Ambos foram criados usando as ferramentas oficiais: Spring Initializr para a API e o Angular CLI para a interface do usuário. Este é o estado inicial antes da implementação de quaisquer artefatos de fluxo de trabalho:
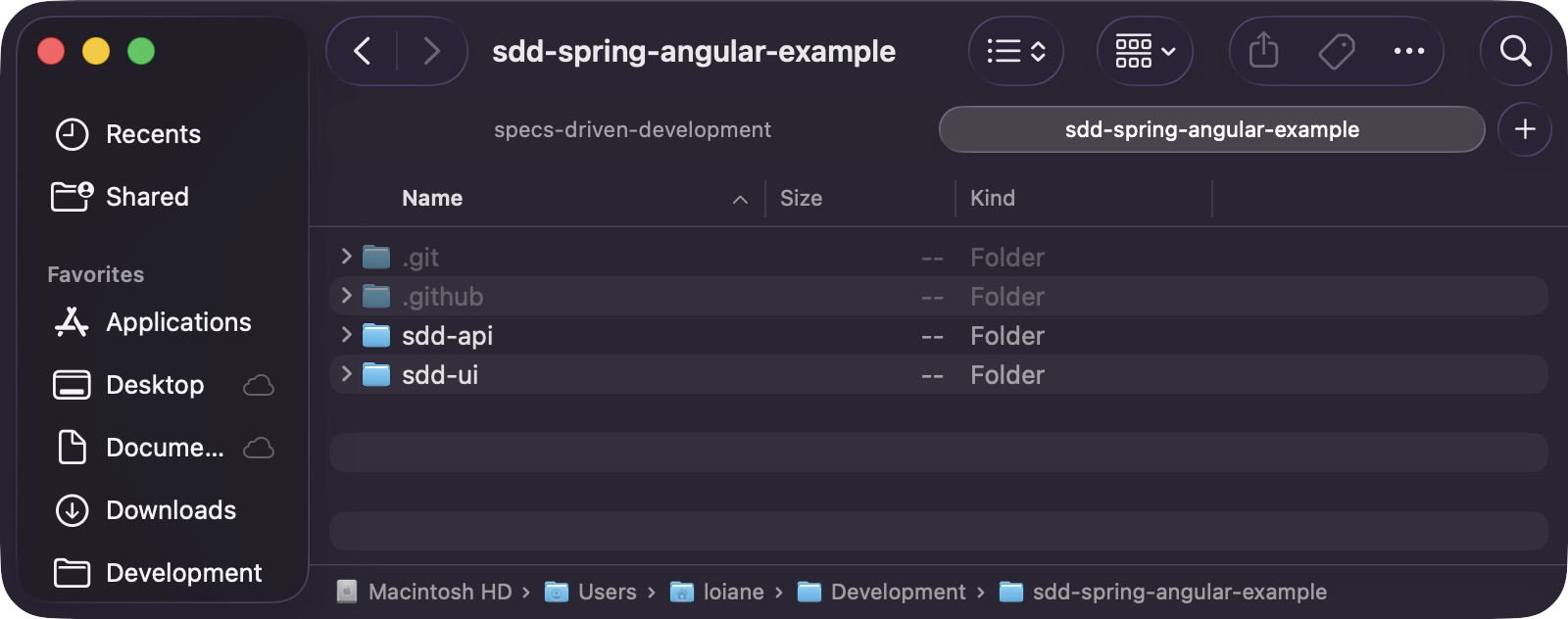
O que a etapa de integração deve produzir
- Uma classificação de repositório clara
- Um resumo da pilha
- Nota de projeto básica ou inicial
- Os arquivos de fluxo de trabalho foram copiados para o repositório.
- Uma
.specs/estrutura que pode conter artefatos de recursos - Um ponto de partida conhecido para a primeira característica.
O que copiar para o repositório
O repositório do framework é organizado em torno de artefatos de fluxo de trabalho compartilhados. Para uma equipe que o adota, o importante não são apenas as ideias, mas sim os arquivos em si. Todos os modelos de especificação, agentes, comandos, habilidades e listas de verificação de revisão usados nesta publicação estão disponíveis no repositório de desenvolvimento orientado a especificações .
No mínimo, eu copiaria os arquivos de fluxo de trabalho relevantes para o repositório de destino:
- Agentes e comandos
- Habilidades
- Modelos de prompts
- Modelos de especificação
- Listas de verificação de revisão
- Documentação do fluxo de trabalho
Isso confere ao repositório uma linguagem consistente para:
- Redação de especificações
- Análise das especificações
- Decomposição de tarefas
- Testando
- Validação
- Integração
A estrutura exata das pastas depende da ferramenta utilizada, mas o princípio permanece o mesmo: o fluxo de trabalho reside no código-fonte, não na cabeça de alguém. Neste exemplo, estou usando o Claude Code , então copiei a .claudepasta. Se você estiver usando o GitHub Copilot, copie a .githubpasta correspondente (embora .claudetambém funcione com o Copilot). Se você usar outra ferramenta, verifique onde ela espera encontrar as definições de agente e prompt e copie a pasta correspondente do repositório do framework.
Após copiar os arquivos de fluxo de trabalho, o repositório ganha uma .claude/pasta contendo agentes, listas de verificação, comandos, habilidades e modelos: o modelo operacional compartilhado que a IA usará em cada etapa subsequente:
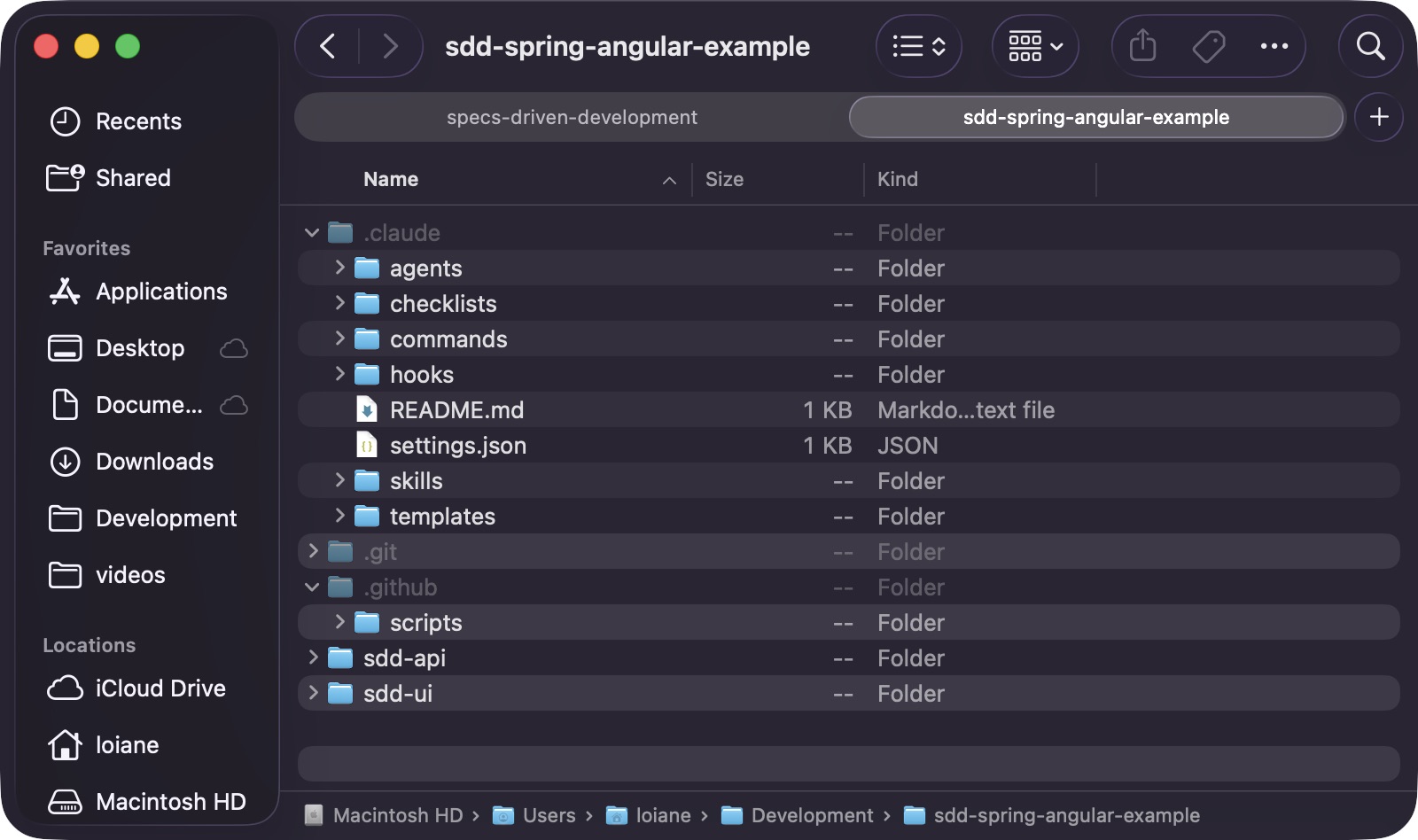
Por que isso é importante?
Sem um processo de integração, cada nova tarefa começa do zero.
Com a integração, o repositório já possui:
- Convenções compartilhadas
- Instruções compartilhadas
- Portões de revisão compartilhados
- Artefatos compartilhados
- expectativas de validação compartilhadas
Isso torna o restante do fluxo de trabalho muito mais confiável.
Um fluxo de integração prático se parece com isto:
- Inspecione a estrutura do repositório e identifique a pilha de dependências.
- Decida se este é um terreno virgem ou um terreno já urbanizado.
- Copie os arquivos do fluxo de trabalho para o repositório.
- Crie a
.specsestrutura inicial. - Registre o estado inicial ou de referência do projeto.
- Verifique se a primeira funcionalidade pode ser iniciada a partir de um ponto de entrada de fluxo de trabalho conhecido.
O primeiro comando a ser executado em qualquer repositório é `git pull` /onboard. Ele inspeciona o projeto, classifica a pilha de tecnologias e copia os arquivos de fluxo de trabalho do framework para o repositório:
/onboardO /onboardagente inspeciona a pilha, classifica o repositório, identifica lacunas e grava dois artefatos .specs/: um _stack.jsoncom as escolhas de tecnologia e outro _onboarding.mdcom o estado inicial. Para o repositório de exemplo, ele classificou o projeto como novo e sinalizou três lacunas a serem resolvidas antes da primeira compilação: ausência de ferramenta de migração, ausência de ambiente de teste e ausência de configuração do Testcontainers.
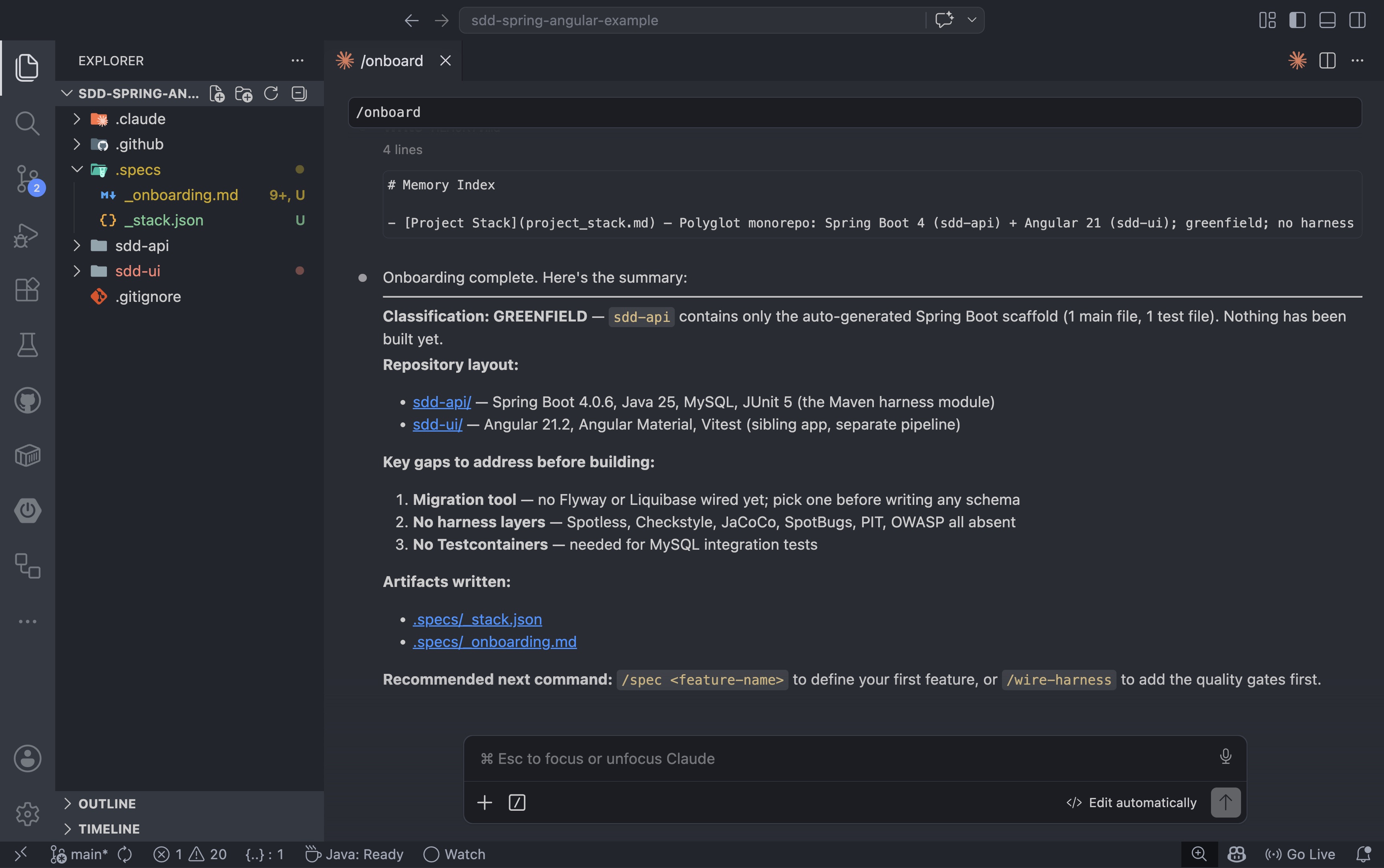
Se o repositório for um ambiente já existente, o processo de integração deve também levar em consideração as restrições existentes, as dívidas conhecidas e o estado atual do sistema. Se o repositório for novo, o objetivo é mais simples: estabelecer o fluxo de trabalho desde o primeiro dia para que a primeira funcionalidade siga sempre o mesmo caminho.
Existe uma regra importante para projetos totalmente novos: não deixe que a ferramenta de IA crie a estrutura do projeto para você.
O motivo é simples. O modelo tem um limite de conhecimento, enquanto as versões de frameworks e linguagens estão em constante evolução. Se você pedir para a IA criar a estrutura de um projeto totalmente novo do zero, há uma grande chance de que ela gere algo que já esteja um passo atrás da configuração recomendada atualmente.
Para projetos Spring, utilize o Spring Initializr para criar a aplicação. Para projetos Angular, utilize o Angular CLI para gerar o espaço de trabalho e a estrutura inicial. Somente após a estrutura oficial do projeto estar pronta, você deve começar a usar IA para auxiliar nas especificações, design, implementação e validação.
Antes de escrever a primeira especificação, vale a pena configurar os mecanismos de controle de qualidade. O /wire-harnesscomando adiciona a configuração do ambiente de testes ao projeto: limites de cobertura, regras de linting e executores de testes de integração. Para um projeto Spring Boot conectado ao MySQL, o agente realiza uma verificação prévia primeiro:
/wire-harness |
Se uma decisão necessária estiver faltando, o comando para e pergunta em vez de tentar adivinhar. Neste caso, o projeto tinha uma dependência do MySQL, mas nenhuma ferramenta de migração estava configurada ainda:
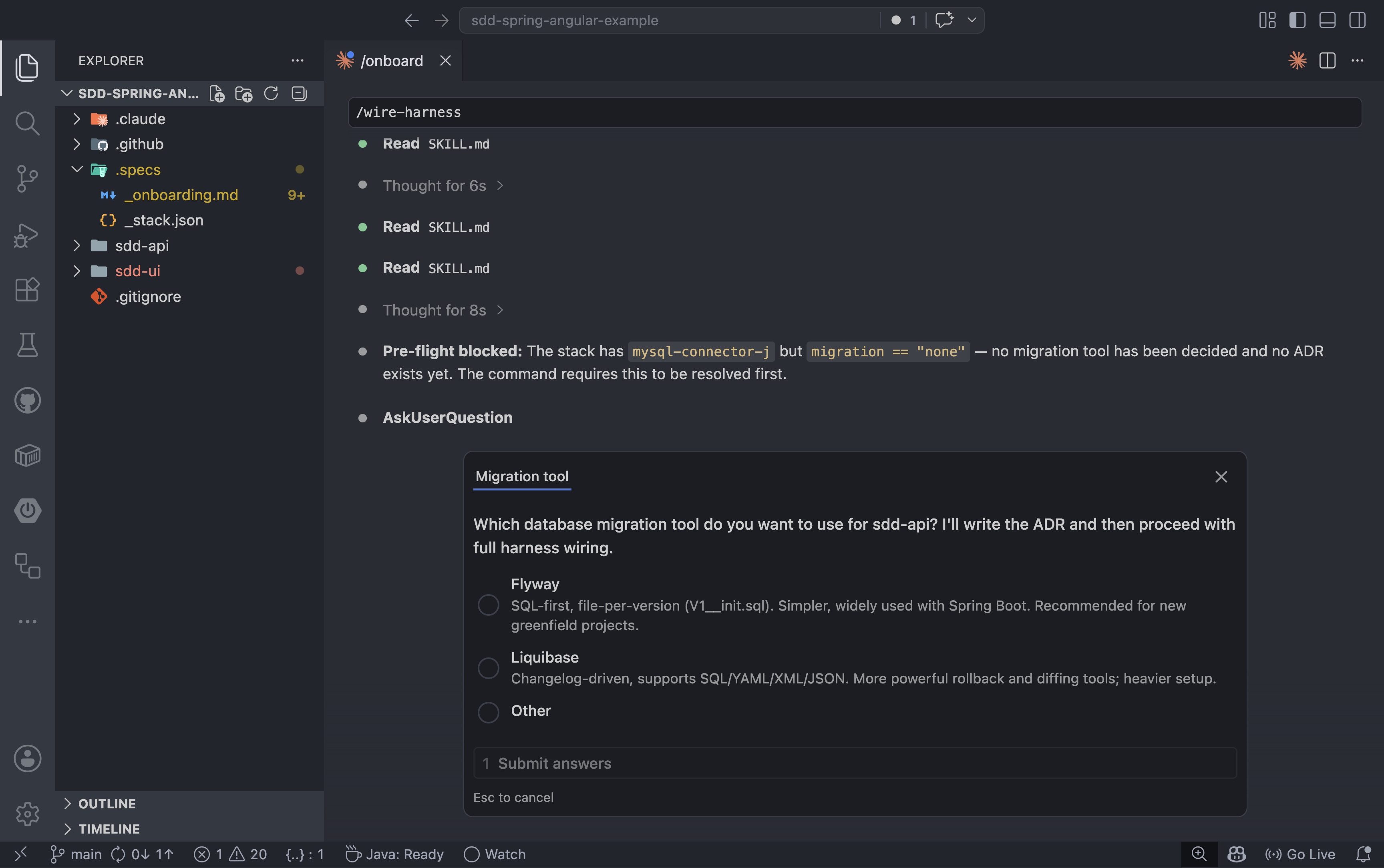
1. Por que especificações primeiro, e não o prompt primeiro?
Os estímulos podem te ajudar a começar, mas são as especificações que mantêm o trabalho alinhado quando o recurso deixa de ser uma demonstração e começa a se tornar algo que você precisa revisar, testar e manter.
Essa é a diferença entre experimentar e entregar resultados.
Quando ignoramos a especificação, a IA ganha muita liberdade em áreas inadequadas. Ela pode escolher valores padrão incorretos, ignorar casos extremos ou implementar uma funcionalidade que parece plausível, mas que na realidade não atende às necessidades do produto. Um prompt pode solicitar código. Uma especificação define o que o código deve realizar.
Isso se torna ainda mais importante quando a funcionalidade abrange tanto o backend quanto o frontend. Sem uma especificação compartilhada, o backend e o frontend podem se distanciar rapidamente. O contrato da API torna-se implícito. A interface do usuário assume um comportamento que o backend não garante. A equipe gasta tempo corrigindo problemas de coordenação que deveriam ter sido resolvidos antes do início da implementação.
É por isso que prefiro um fluxo de trabalho que priorize a especificação:
- A intenção do produto é capturada antes mesmo da existência do código.
- As decisões são explicitadas antes do início da implementação.
- Os critérios de aceitação ficam visíveis antes da elaboração dos testes.
- Questões em aberto são identificadas antes que se tornem bugs.
É também neste ponto que a IA se torna mais útil, e não menos. O modelo funciona melhor quando o objetivo é claro. Ele não precisa inferir todo o sistema a partir de uma descrição vaga. Ele recebe um fluxo de trabalho concreto, uma funcionalidade concreta e limites concretos.
2. Exemplo de História do Produto e Funcionalidade
Um bom exemplo faz diferença.
A funcionalidade deve ser simples o suficiente para ser compreendida, mas realista o bastante para demonstrar validação, limites de contrato e coordenação entre front-end e back-end.
Para este post, o exemplo é um fluxo de negócios clássico: a criação de um cliente. Ele possui regras de validação claras, um contrato de API explícito e uma interface de usuário real — suficientemente concreta para demonstrar o fluxo de trabalho sem se perder em complexidades de negócios. A história de usuário completa está descrita na próxima seção como parte da especificação.
3. Redija a especificação
É aqui que a intenção do produto se torna algo concreto.
A especificação deve responder às perguntas que a equipe realmente precisa responder antes do início da implementação:
- Qual é o objetivo?
- O que está incluído no escopo?
- O que está fora do escopo?
- Como se define o sucesso?
- Que terminologia precisamos definir?
- O que ainda é desconhecido?
Isso significa que a especificação final deve incluir:
- História do usuário
- Regras de validação em nível de campo
- Critérios de aceitação
- Não-Objetivos
- Requisitos não funcionais
Antes de escrever a especificação, comece com a entrada explícita de histórias de usuário:
História do usuário
Como usuário da área de vendas ou suporte, quero criar um novo cliente pelo aplicativo para poder registrar os dados do cliente de forma consistente e visualizar erros de validação antes que o registro seja salvo.
O próximo passo é transformar isso nas seções de especificação estruturadas usadas pelo fluxo de trabalho.
Campos do cliente e regras de validação
| Campo | Obrigatório | Comprimento máximo | Formato/Regras |
|---|---|---|---|
| Primeiro nome | sim | 100 | Letras, hífens, apóstrofos; sem dígitos. |
| Sobrenome | sim | 100 | Letras, hífens, apóstrofos; sem dígitos. |
| sim | 255 | Formato de e-mail válido; exclusivo para todos os clientes. | |
| Telefone | não | 20 | Dígitos, espaços, +, (, ), -apenas |
| Empresa | não | 150 | Texto livre |
Critérios de aceitação
Renderização de formulário
- AC-001: Quando um usuário acessa a página Criar Cliente, o sistema deve exibir um formulário com os campos: Nome, Sobrenome, E-mail, Telefone e Empresa.
- AC-002: Quando um usuário acessa a página Criar Cliente, o sistema deve exibir um botão de envio que ficará desabilitado até que o Nome, Sobrenome e E-mail sejam validados no lado do cliente.
Validação de campo em linha
- AC-003: Quando um usuário deixa os campos Nome, Sobrenome ou E-mail em branco e move o foco para outro campo, o sistema deve exibir uma mensagem de erro “Este campo é obrigatório” ao lado do campo em questão.
- AC-004: Quando um usuário insere um valor no campo Nome ou Sobrenome que contenha dígitos ou caracteres não permitidos, o sistema deve exibir um erro de formatação embutido sem enviar o formulário.
- AC-005: Quando um usuário insere um valor no campo “E-mail” que não esteja em um formato de e-mail válido, o sistema deve exibir uma mensagem de erro “Endereço de e-mail inválido” sem enviar o formulário.
- AC-006: Quando um usuário insere um valor no campo Telefone que contém caracteres diferentes de dígitos, espaços, vírgulas
+,(vírgulas)ou-vírgulas, o sistema deve exibir um erro de formatação embutida sem enviar o formulário. - AC-007: Quando um usuário corrige um campo anteriormente inválido, o sistema deve remover imediatamente a mensagem de erro embutida para esse campo.
Guardando o registro
- AC-008: Quando um usuário enviar o formulário com todos os dados válidos, o sistema deverá salvar o novo registro do cliente.
- AC-009: Quando o registro for salvo com sucesso, o sistema deverá exibir uma confirmação de sucesso e direcionar o usuário para a página da lista de clientes.
Erros de validação ao salvar
- AC-010: Quando o usuário enviar o formulário e um campo obrigatório estiver faltando, o sistema não deverá salvar o registro e deverá exibir uma mensagem de erro identificando quais campos precisam ser preenchidos.
- AC-011: Quando o usuário enviar um formulário com um e-mail que já pertence a outro cliente, o sistema não deverá salvar o registro e deverá exibir uma mensagem de erro no campo de e-mail indicando que ele já está em uso.
- AC-012: Quando o usuário enviar um formulário com um valor de campo muito longo, o sistema não deverá salvar o registro e deverá exibir uma mensagem de erro no campo em questão.
- AC-013: Quando ocorrer um erro inesperado durante o salvamento, o sistema deverá exibir uma mensagem de erro genérica e manter o usuário no formulário para que nenhum dado seja perdido.
Não-Objetivos
- Editar ou atualizar um cliente existente
- Excluir ou arquivar um cliente
- Pesquisar ou listar clientes
- Campos para endereço, cargo ou observações (matéria futura)
- Importação em massa/CSV
- Auto-cadastro do cliente
Requisito não funcional
- A ação de salvar deve ser concluída em menos de 500 ms (P95): Problema nº 1
Essa é a importância de começar com uma história de usuário bem definida: ela fornece à equipe material claro para transformar em uma especificação de alta qualidade antes do início do design e da codificação.
Com o repositório integrado e a infraestrutura configurada, a primeira funcionalidade pode ser iniciada. O /speccomando aceita a URL de uma issue do GitHub e a transforma em um arquivo de especificação estruturado. Para a funcionalidade de criação de cliente:
/spec https://github.com/loiane/sdd-spring-angular-example/issues/1 |
Para que isso funcione, você precisa configurar e conectar o servidor GitHub MCP ao seu assistente de IA. O agente acessa a API do GitHub por meio do servidor MCP para ler o título, o corpo e os comentários da issue: sem necessidade de copiar e colar.
Este é um bom momento para dar um passo atrás e observar o que realmente está acontecendo aqui. O desenvolvimento assistido por IA não se resume apenas a sugestões. Ao combinar um assistente de IA com servidores MCP e chamadas de ferramentas, o agente pode ler seu sistema de rastreamento de problemas, inspecionar seu código-fonte, chamar suas APIs e gravar as alterações em seu repositório, tudo em um único fluxo de trabalho. É aí que reside o verdadeiro ganho de produtividade: não em uma sugestão mais inteligente, mas em um sistema conectado.
O mesmo princípio se aplica ao seu conjunto de ferramentas específico:
- Se sua equipe usa o Jira em vez do GitHub Issues, você precisará de um servidor Jira MCP que o agente possa consultar. Sem ele, a solução alternativa é copiar e colar o texto da história no prompt antes de executar o comando
/spec. - Se o problema ou a história incluir links para designs do Figma , você precisará ter o servidor Figma MCP conectado para que o agente possa ler a especificação visual e extrair a intenção do layout, os nomes dos componentes e as notas de interação. Sem isso, o agente funcionará apenas com a descrição textual.
- Outras fontes (páginas do Confluence, itens de trabalho do ADO, tickets do Linear) seguem o mesmo padrão: um servidor MCP capaz de ler a fonte é o que transforma um assistente de IA genérico em um que realmente entende o seu contexto.
A principal conclusão é a seguinte: quanto mais rico for o contexto que você puder fornecer ao agente por meio de ferramentas conectadas, menos tempo você gastará preenchendo essa lacuna manualmente. Os servidores MCP não são um mero recurso adicional. Eles são o que torna o fluxo de trabalho repetível em escala de equipe.
O agente lê o problema, extrai todos os critérios de aceitação e grava a especificação .specs/2026-05-09-create-new-customer/01-spec.md. Ele também identifica quaisquer questões em aberto que precisem de respostas antes que o projeto possa começar.
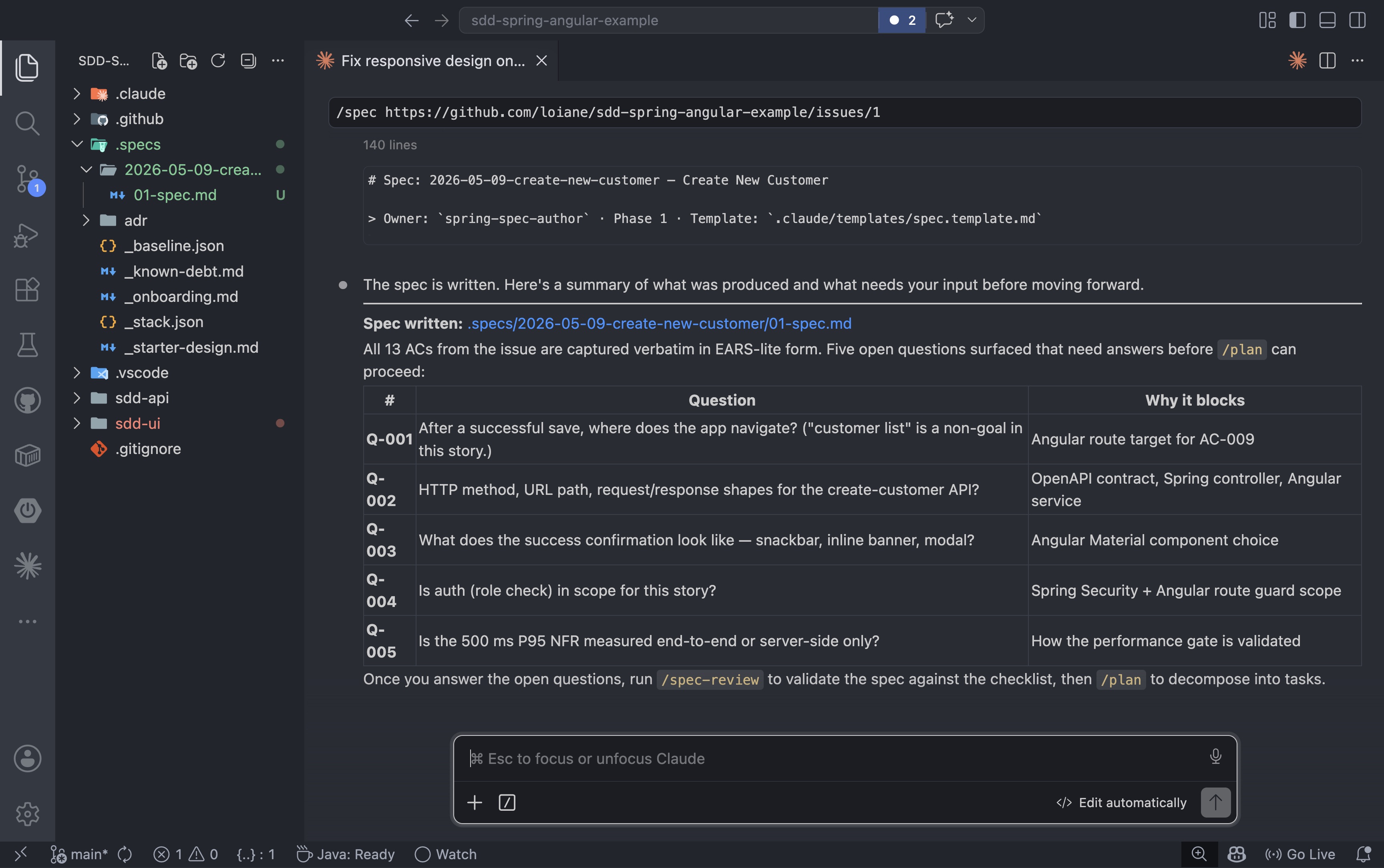
Antes de prosseguir, responda a todas as perguntas em aberto que o agente levantou. Continue /speccom as respostas atualizadas até que não haja mais perguntas em aberto. Uma especificação com perguntas não resolvidas não está pronta para revisão.
4. Analise as especificações antes do projeto.
Uma especificação só é útil se for clara.
Nesta etapa, a ambiguidade vem à tona e é resolvida antes que a equipe comece a tomar decisões de implementação. O objetivo não é ser formal por si só, mas sim evitar que suposições implícitas se infiltrem no código.
Na prática, a revisão deve verificar aspectos como:
- O objetivo está escrito em termos visíveis para o usuário?
- Os critérios de aceitação são atômicos?
- Os critérios são testáveis?
- Os objetivos não concretos são explícitos?
- As questões em aberto são realmente resolvidas antes do início do projeto?
É aqui também que o fluxo de trabalho mostra a sua importância.
Sem uma etapa de revisão, as equipes muitas vezes avançam muito rapidamente para a arquitetura e implementação, ainda carregando suposições não resolvidas. É assim que se acaba com um código tecnicamente correto, mas funcionalmente desalinhado.
Com uma etapa de revisão, a equipe pode responder a perguntas como:
- O que acontece quando a entrada é inválida?
- Como se define o sucesso?
- Qual comportamento é obrigatório?
- Qual comportamento está fora do escopo?
Se a especificação ainda não consegue responder a essas perguntas, a atitude correta não é adivinhar. A atitude correta é parar, esclarecer e resolver primeiro as lacunas.
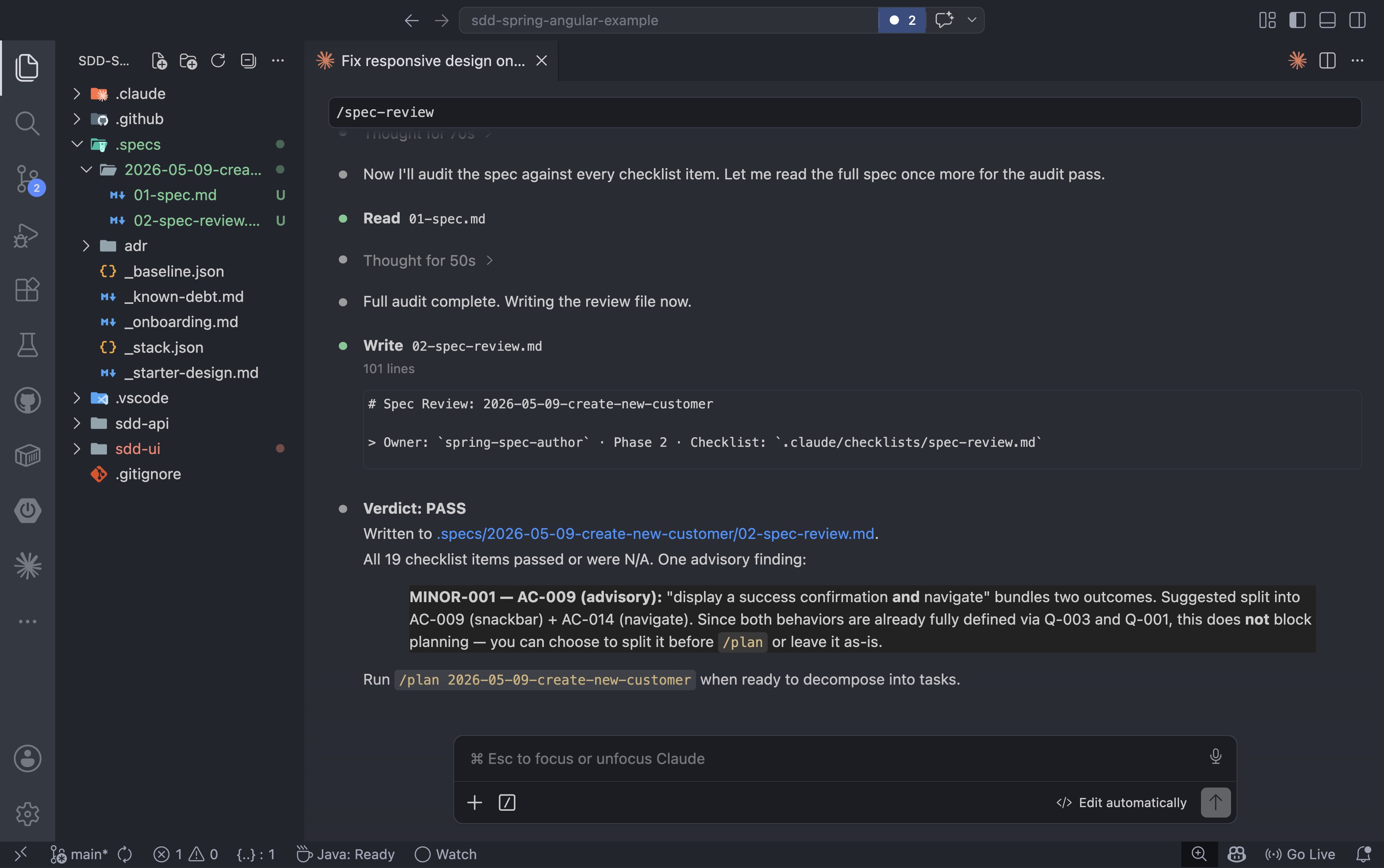
Após as questões em aberto serem respondidas e adicionadas à especificação, a etapa de revisão verifica cada seção em relação à lista de verificação:
/spec-review 2026-05-09-create-new-customer |
APROVADO significa que a especificação é clara o suficiente para que o projeto possa ser desenvolvido com base nela. REPROVADO significa que há itens a serem resolvidos antes que o planejamento possa começar.
5. Projeto de Alto Nível
Assim que a especificação estiver estável, o próximo passo é traduzi-la em uma visão do sistema.
Neste momento, não queremos código. Queremos o formato da solução.
Sim, dedicamos tempo a compreender o problema antes mesmo de tocar no teclado. Isso é intencional. Bons engenheiros não começam a escrever código sem entender o que estão construindo e porquê. Essa não é uma ideia nova: é simplesmente uma boa prática. Com IA, a mesma regra se aplica. Se você planeja enviar esse código para produção, não pode pular a fase de planejamento e ir direto para a implementação. Pode parecer que você está perdendo tempo, mas na verdade está economizando: um projeto bem definido reduz as alucinações da IA, restringe o espaço de soluções e produz um código mais fácil de revisar, testar e manter. As etapas de especificação e projeto não são custos adicionais. Elas são a parte que torna o restante do fluxo de trabalho confiável.
Para o fluxo de criação de clientes, o design de alto nível deve explicar:
- Qual parte pertence ao backend?
- Qual parte pertence ao frontend?
- Como os dados se movem entre eles
- Como é o contrato da API?
- Como a validação é dividida entre camadas
- Quais erros são esperados e como eles são representados.
Uma visão geral simplificada poderia ser assim:
- O formulário Angular coleta dados do cliente.
- O Angular envia o formulário para uma API do Spring Boot.
- O Spring Boot valida a requisição e aplica as regras de negócio.
- O Spring Boot persiste o cliente se a validação for bem-sucedida.
- O Spring Boot retorna uma resposta de sucesso.
- O Angular exibe erros de sucesso ou validação.
É aqui que a equipe deve tomar decisões sobre:
- Estrutura da API
- Formato da carga útil de erro
- Responsabilidades de validação
- Estados de carregamento
- Comportamento de repetição
- Quaisquer regras de domínio que sejam importantes
O importante é que o projeto vem depois da especificação, não antes. A especificação define o comportamento. O projeto define como a equipe irá implementá-lo.
6. Plano de Projeto e Implementação de Baixo Nível
É aqui que o trabalho se torna executável.
O projeto de baixo nível deve dividir a funcionalidade em pequenas partes vinculadas aos critérios de aceitação, para que a implementação possa ser revisada e validada em etapas. Em vez de pedir à IA que construa toda a funcionalidade de uma só vez, pedimos que ela trabalhe em uma parte de cada vez, com um resultado definido. Isso se adequa muito melhor à forma como o modelo realmente se comporta.
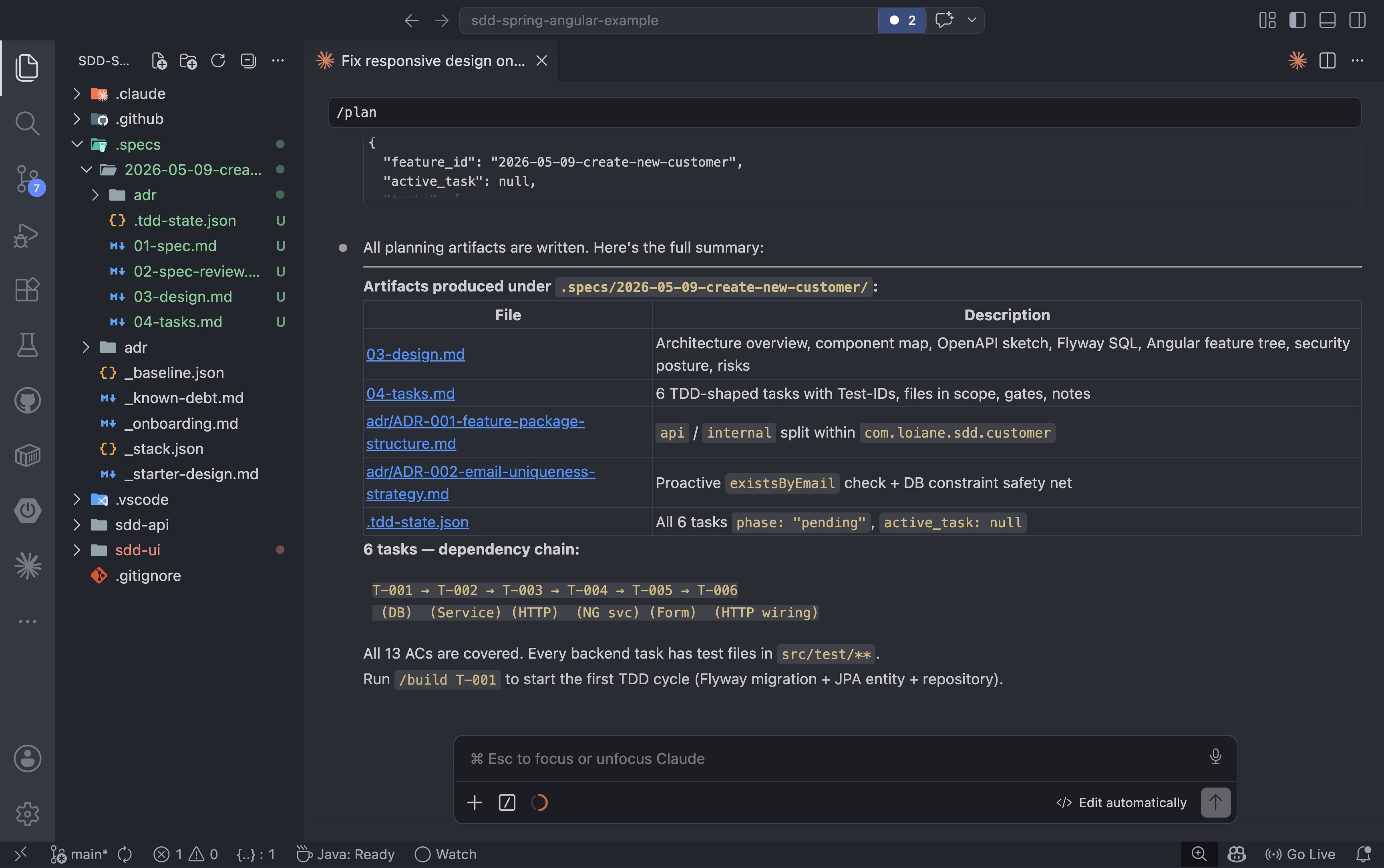
Com uma especificação aprovada em mãos, o próximo passo é transformá-la em um plano executável. O /plancomando lê a especificação e o documento de design e decompõe a funcionalidade em tarefas no formato TDD com uma cadeia de dependências:
/plan 2026-05-09-create-new-customer |
Cada tarefa corresponde a critérios de aceitação específicos, lista os arquivos que serão alterados e define o ponto de verificação que a marca como concluída. O planejamento para o recurso de criação de cliente gerou seis tarefas: três de backend e três de frontend.
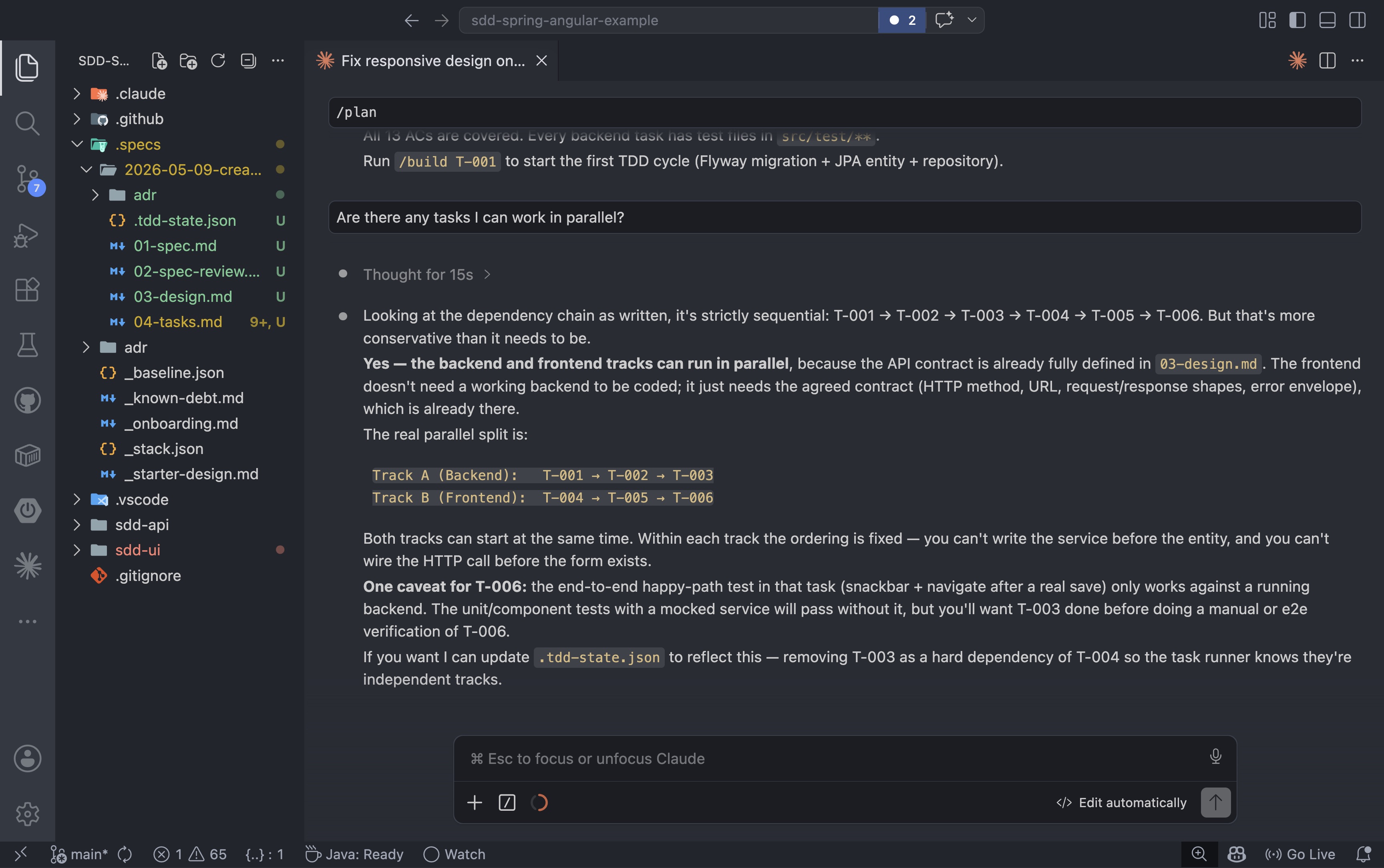
Assim que as tarefas são geradas, a cadeia de dependências torna-se visível. Como o contrato da API está totalmente definido no documento de design, os fluxos de backend e frontend não precisam esperar um pelo outro para iniciar:
Dividir uma funcionalidade complexa em tarefas pequenas e bem definidas é um dos hábitos mais importantes que você pode adotar no desenvolvimento assistido por IA. É nos detalhes que você ainda pode detectar suposições errôneas e equívocos antes que se acumulem em vários arquivos. A IA pode gerar código mais rápido do que qualquer humano, mas a velocidade sem revisão é o que leva à publicação de bugs.
Como gosto de dizer: no fim das contas, é o seu nome que está no commit. Você é responsável por cada linha de código que a IA produz. Dividir o trabalho em pequenas tarefas significa ter diffs menores e que podem ser revisados de fato. Revisar um ou dois métodos é uma experiência muito diferente de abrir um PR com 20 arquivos modificados e tentar descobrir se alguma coisa está correta.
Ao revisar cada tarefa, aproveite esse momento de forma estratégica. Dê feedback ao agente sobre o que você gostou e o que não gostou, para que os mesmos erros não se repitam na próxima tarefa. Verifique se a IA está seguindo as melhores práticas definidas para seus agentes e habilidades e sinta-se à vontade para alterá-las. Eu criei essa estrutura com base nas minhas próprias opiniões e nas práticas em que confio; sua equipe pode ter padrões diferentes, e a estrutura deve refletir os seus.
A frase “ah, a IA criou o código assim” não é uma explicação aceitável em uma revisão de código. É sua responsabilidade garantir que o código que você está aprovando seja o mais próximo possível do código que você mesmo escreveria, ou melhor.
Neste ponto, vale a pena perguntar ao agente quais tarefas são independentes e quais podem ser executadas em paralelo. É aqui que a execução multiagente se torna uma opção: em vez de construir tarefa por tarefa em uma única sessão, você pode atribuir trilhas independentes a agentes separados que executam simultaneamente. Se sua ferramenta de IA for compatível, trilhas paralelas como as fatias de backend e frontend aqui apresentadas são uma solução natural: cada agente trabalha com base nas mesmas especificações e artefatos de design, e nenhum bloqueia o outro.
Após /plana conclusão, a .specs/2026-05-09-create-new-customer/pasta conterá todos os artefatos de planejamento: a especificação, a revisão, o projeto, a lista de tarefas, os ADRs (Artigos de Decisão de Implementação) e a .tdd-state.jsonmáquina de estados. Este é o conjunto completo de documentos que o ciclo de implementação utilizará:
Esse conjunto de artefatos também é o que torna o fluxo de trabalho resiliente ao longo do tempo. Se o recurso levar vários dias ou se você se ausentar durante o fim de semana, o estado nunca será perdido. Ao retornar, você pode perguntar ao agente onde parou: ele .tdd-state.jsonrastreia cada fase da tarefa e o registro de implementação captura o que foi feito e o que ainda está pendente. Você não precisa guardar tudo na cabeça.
7. Implementação do backend em Spring Boot
Agora a implementação pode começar, e o backend vem primeiro.
Essa escolha é deliberada. O backend define o contrato. O frontend deve consumir algo estável, e não tentar adivinhar o que o servidor poderá fazer posteriormente. Todo comportamento do backend (regras de validação, respostas a erros, mensagens de sucesso) deve estar mapeado de acordo com a especificação, portanto o contrato da API é explícito antes mesmo de qualquer código da interface do usuário ser escrito.
Cada tarefa é construída usando o /buildcomando. O framework rastreia o progresso em um .tdd-state.jsonarquivo que move cada tarefa através de um ciclo de vida TDD: pending→ red→ green→ refactor→ done. Iniciar a primeira tarefa de backend se parece com isto:
/build T-001 |
Assim que o agente processa o teste T-001, o arquivo de estado é atualizado: active_taskpassa de nullpara T-001e a fase muda de pendingpara red, sinalizando que o primeiro teste com falha está pronto para ser gravado:
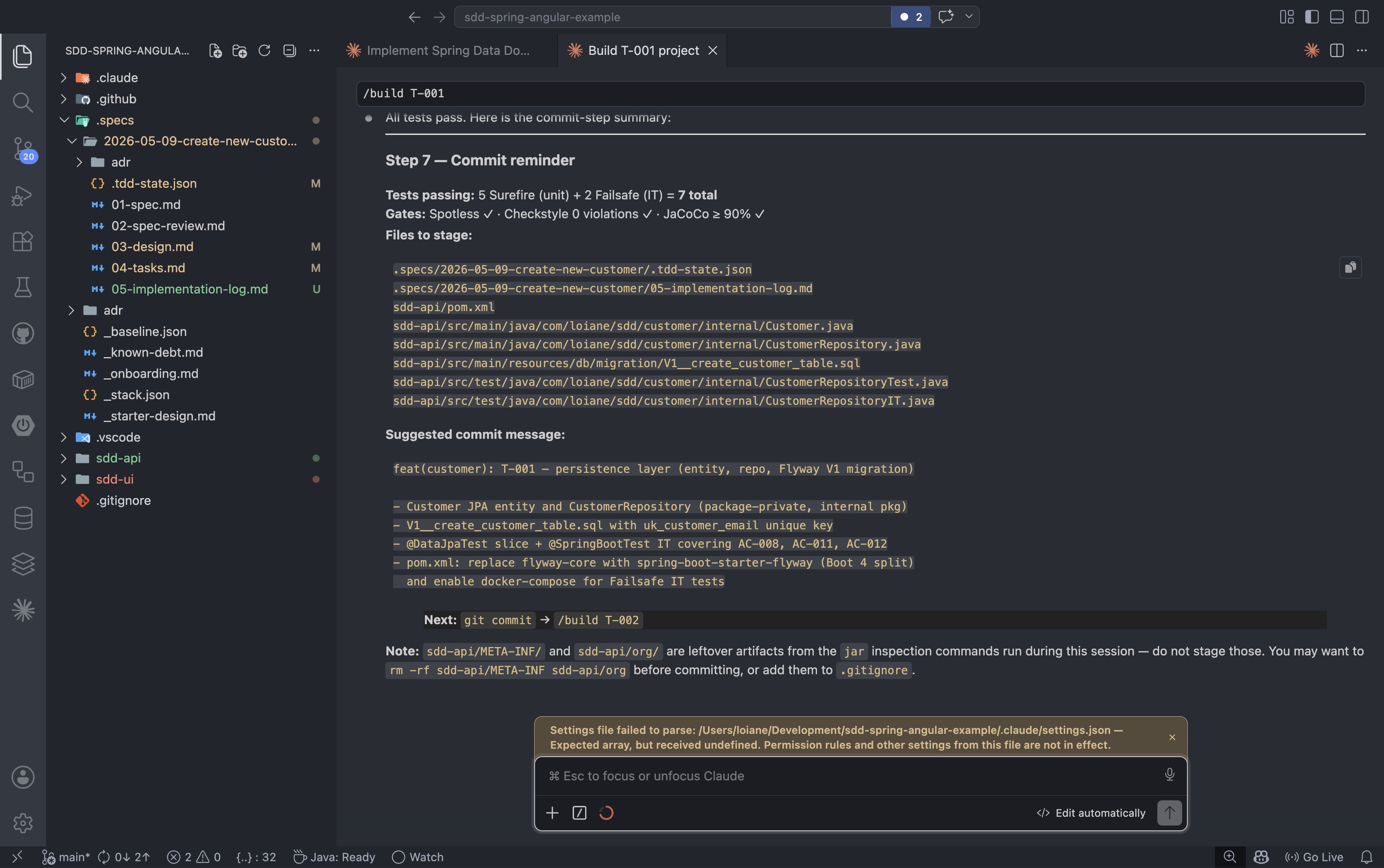
O /buildagente executa o ciclo vermelho-verde-refatorar para cada tarefa: escreve o teste que falha, implementa o código mínimo necessário para que ele seja aprovado e, em seguida, limpa o código. Quando o ciclo é concluído e todos os pontos de verificação são aprovados, o agente gera a mensagem de commit e avança o estado para concluído.
O uso de tokens também é uma preocupação importante a ser considerada. Como cada etapa gera um artefato documentado no repositório, você pode iniciar uma nova sessão para cada tarefa sem perder o contexto. A especificação, o design, a lista de tarefas e o arquivo de estado estão todos lá. A próxima sessão continua exatamente de onde a anterior parou, sem a necessidade de reconstruir uma longa janela de contexto. Quanto maior o contexto e mais longa a sessão, mais tokens você gasta. Este framework foi projetado especificamente para que você possa fechar uma sessão após cada etapa e abrir uma nova para a próxima, mantendo cada sessão pequena, focada e com custo eficiente.
8. Implementação de Frontend em Angular
Assim que o contrato de backend estiver estável, a camada Angular pode ser adicionada por cima.
É aqui que a escolha de priorizar o backend se mostra vantajosa. Como o contrato da API já existe, o código Angular pode ser escrito com confiança: campos de formulário, estados de erro, resposta de sucesso e comportamento de carregamento são todos conhecidos. A interface do usuário não precisa especular sobre o contrato; ela pode implementá-lo diretamente. Isso mantém o frontend enxuto, honesto e alinhado com a especificação.
As tarefas do Angular seguem o mesmo padrão do backend. A tarefa T-006 é a última: conectar o envio do formulário ao serviço de backend e mapear as respostas de erro do servidor para os campos corretos do formulário. Quando concluída, todas as seis tarefas em ambas as trilhas estarão finalizadas.
/build T-006 |
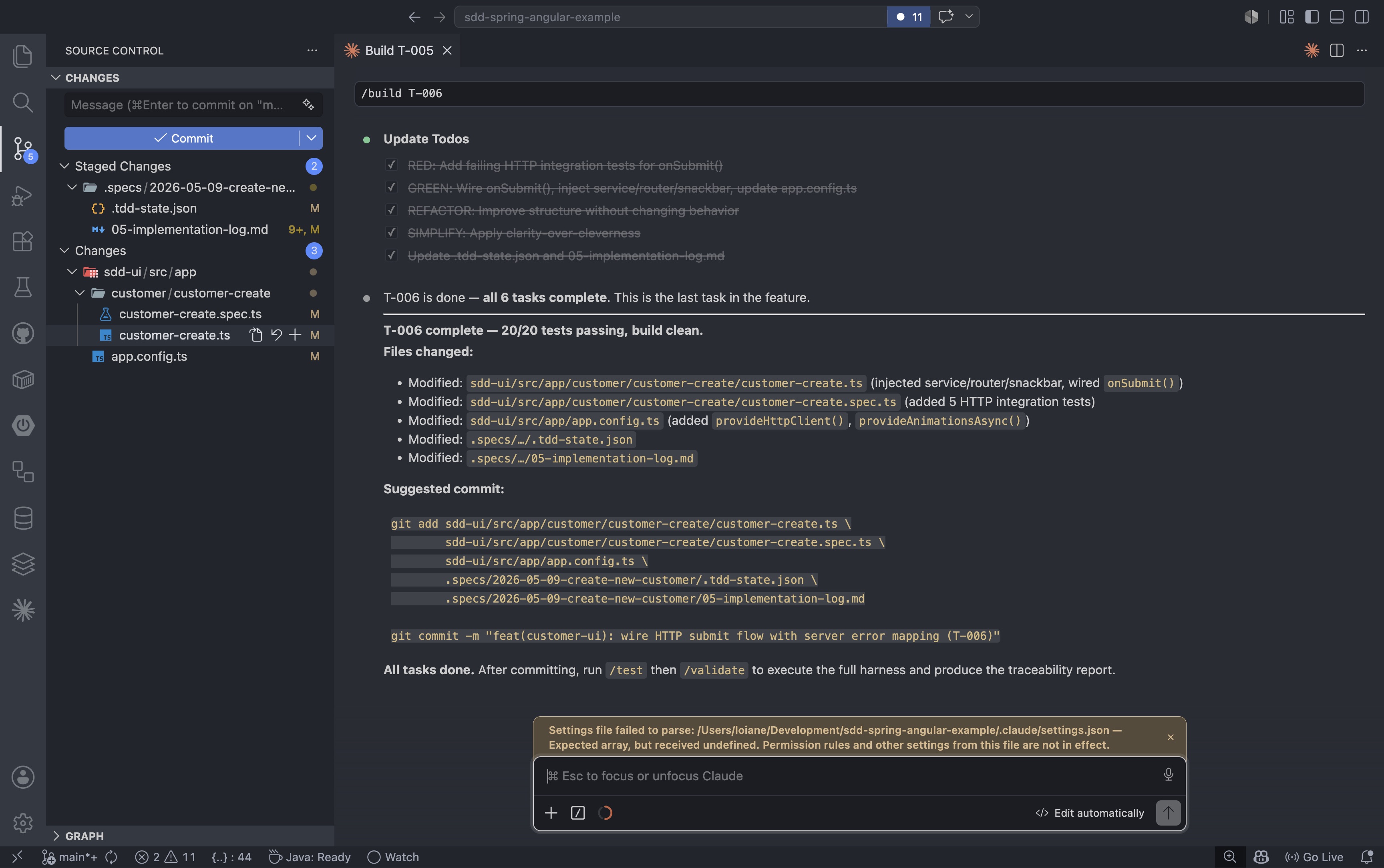
Repita o processo até que todas as tarefas estejam concluídas. Confirme as alterações após a conclusão de cada tarefa. O /buildagente inclui até mesmo uma sugestão de mensagem de confirmação para que você não se esqueça. Confirmações pequenas e focadas são uma prática recomendada, e esse fluxo de trabalho as torna a unidade natural de progresso.
9. Validar, revisar e concluir o ciclo
Os testes unitários não são o fim da história.
O fluxo em nível de navegador é onde tudo se junta, onde você vê se o fluxo de trabalho realmente funcionou de ponta a ponta.
É aqui que a validação de ponta a ponta se torna importante.
Para um fluxo de criação de clientes, um teste de ponta a ponta deve confirmar aspectos como:
- O usuário pode abrir o formulário.
- O usuário pode preencher os campos obrigatórios.
- O usuário pode enviar o formulário.
- A mensagem de sucesso aparece após o envio de um arquivo válido.
- Os erros de validação aparecem quando o formulário é inválido.
- O sistema se comporta corretamente quando o servidor rejeita a solicitação.
Isso fecha o ciclo.
A especificação indicava o que deveria acontecer. O design definia o formato da solução. O backend e o frontend a implementavam. O teste de ponta a ponta comprova que a experiência funciona como um todo.
Com todas as tarefas concluídas, o próximo passo é a execução completa do conjunto de testes. O /validatecomando executa o conjunto de testes, verifica os limites de cobertura e realiza todas as verificações de formatação e linting:
/validate |
Caso algo falhe, o comando reporta exatamente o que precisa ser corrigido antes da etapa de revisão. No exemplo executado, 18 testes unitários e 6 testes de integração foram aprovados com 97% de cobertura de linhas e 100% de cobertura de branches. Dois arquivos Angular apresentavam problemas de formatação no Prettier que precisavam de uma correção rápida:
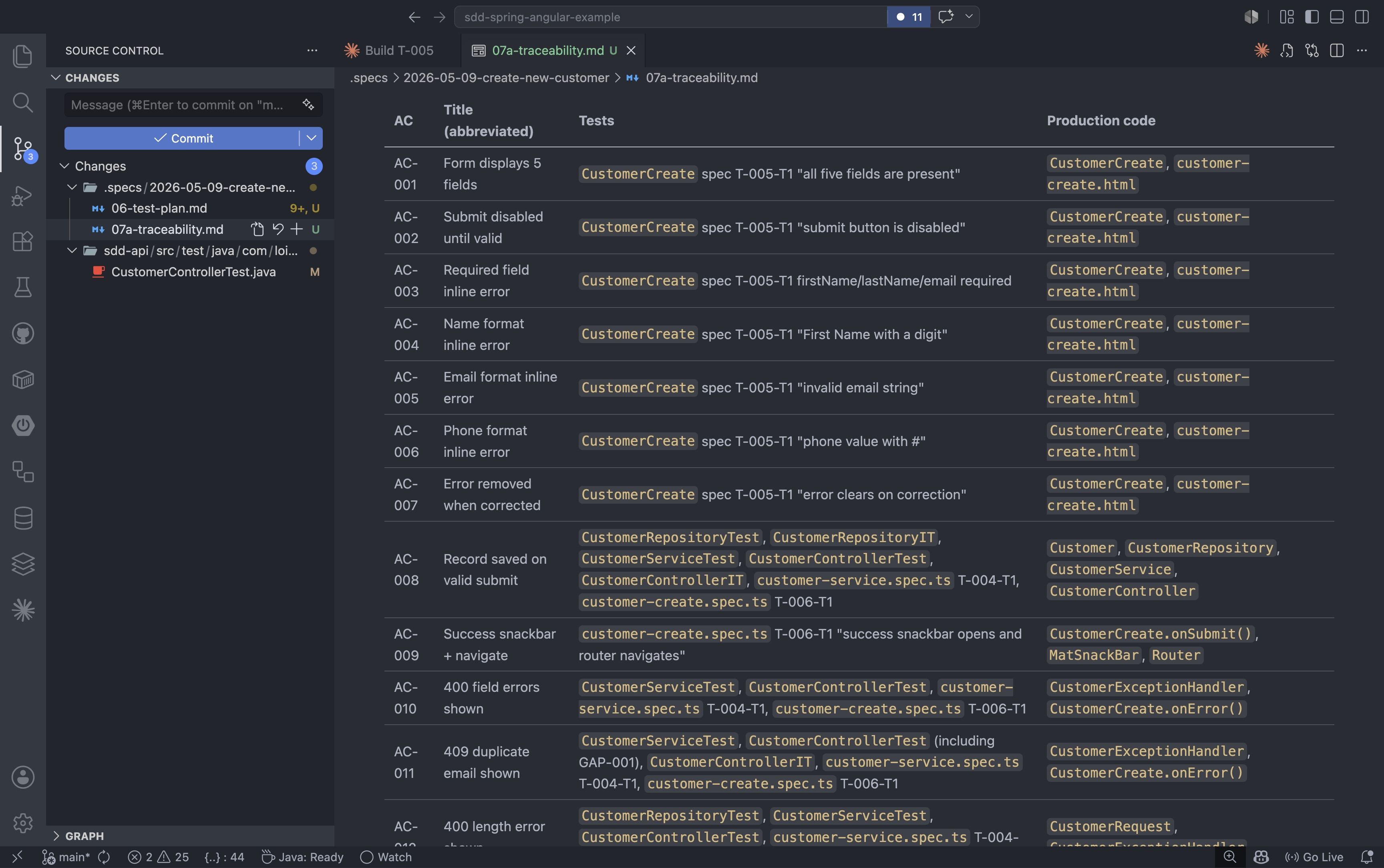
Após a formatação estar correta e a validação ser aprovada, o /reviewcomando realiza uma auditoria final da implementação em relação à especificação: verificando se todos os critérios de aceitação foram atendidos e sinalizando quaisquer problemas de qualidade do código antes do commit:
/review |
A revisão verifica itens como manipuladores de exceção excessivamente abrangentes, lógica de validação duplicada e anotações de escopo ausentes. Ela retorna um veredicto estruturado com categorias de correção obrigatória, correção recomendada, detalhes a serem melhorados e elogios:
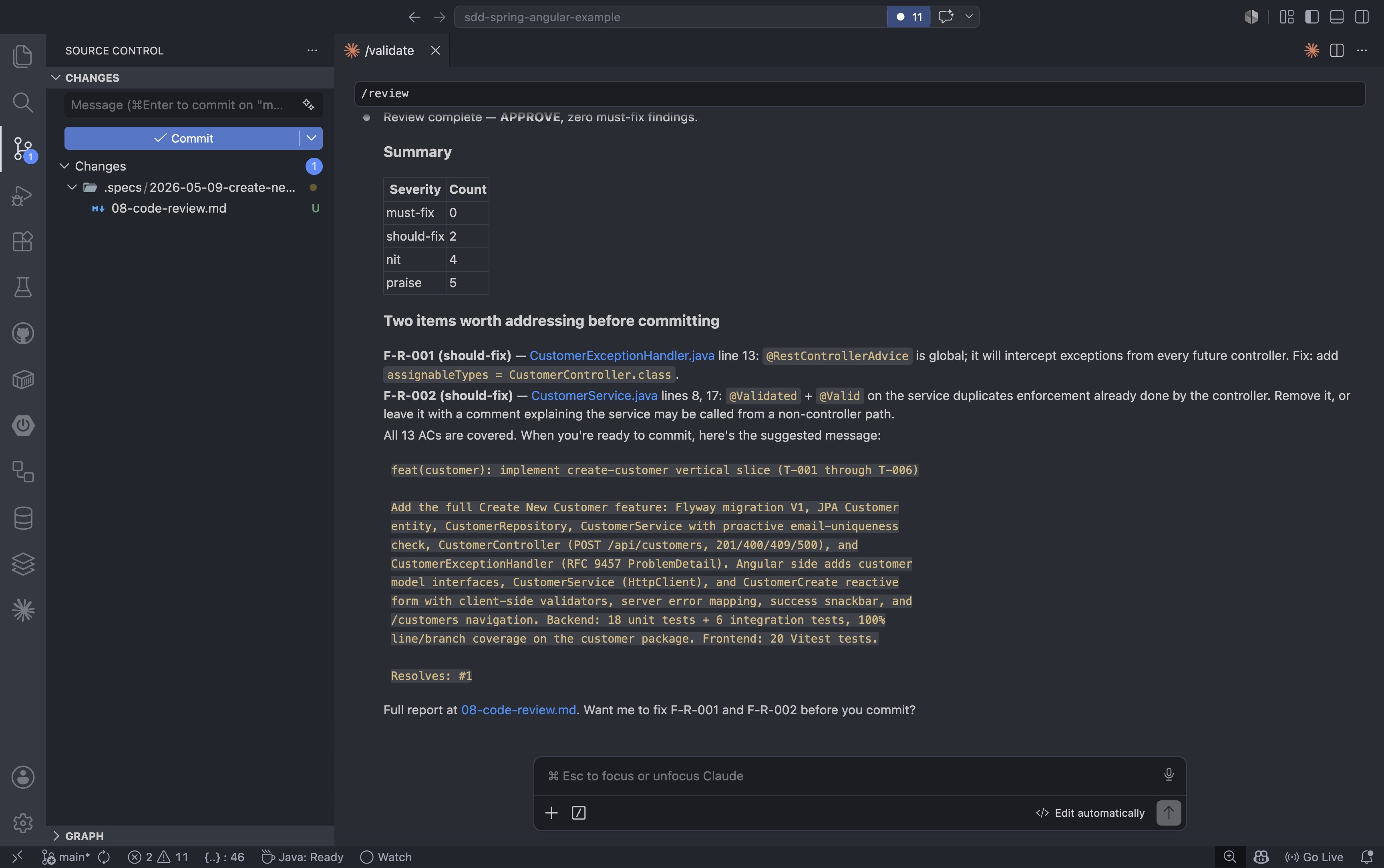
Após a aprovação da revisão, a .specs/2026-05-09-create-new-customer/pasta contém o histórico completo do ciclo de vida do recurso. Todos os documentos, desde a especificação inicial até a revisão final do código, são incluídos no repositório junto com o código do aplicativo.
Essa é a diferença entre o código que existe e o código que é efetivamente entregue.
10. Mantendo o repositório saudável à medida que as especificações aumentam.
Quando as equipes adotam o desenvolvimento orientado a especificações com engenharia de integração, uma coisa fica óbvia muito rapidamente: o repositório começa a acumular muitos documentos.
Isso não é um efeito colateral. Faz parte do modelo.
Nesse fluxo de trabalho, as especificações não são notas passivas. São artefatos vivos que impulsionam a geração, revisão, validação e entrega. Portanto, a questão não é “Como evitar documentos?”. A verdadeira questão é “Como gerenciá-los com o mesmo rigor que o código-fonte?”.
Eis a abordagem que recomendo.
1. Defina um ciclo de vida claro, da especificação ao artefato.
Uma vez que o código esteja em produção, o papel de uma especificação muda. A estrutura do seu repositório deve deixar isso explícito.
- Mantenha as especificações ativas em uma pasta dedicada, como
/specsou/docs/blueprints - Mover especificações implementadas e que não são mais utilizadas para
/archiveou/history - Confirme a versão final do código de suporte e estrutura para que o repositório possa ser compilado sem ferramentas de IA.
- Ignore os arquivos temporários de ponte para
.gitignoreque as saídas transitórias não poluam o repositório.
Isso mantém a área de superfície ativa limpa, preservando ao mesmo tempo o histórico.
2. Manter um registro de especificações para facilitar a descoberta.
Com o aumento das especificações, as pessoas perdem tempo apenas para encontrar o documento certo.
- Mantenha um arquivo de índice (por exemplo, `.htaccess`
README.mdou `index.json.htaccess`) na pasta `specs`. - Mapeie cada especificação para o módulo, serviço ou contexto delimitado que ela rege.
- Adicione metadados de front matter YAML, como
status,author,target_module, elast_reviewed
Com isso implementado, você pode criar scripts para verificações de integridade e responder rapidamente: quais especificações estão ativas, obsoletas ou descontinuadas?
3. Validar especificações automaticamente em CI (Integração Contínua)
Um repositório SDD saudável requer especificações legíveis por máquina e com estrutura consistente.
- Adicione verificações de estrutura para garantir que as seções necessárias estejam presentes (por exemplo: Entrada, Saída, Regras de Negócio).
- Adicionar verificações de sincronização que comparem as revisões das especificações com o código gerado ou implementado.
- Avisar ou interromper o pipeline quando a especificação for alterada, mas a implementação não for atualizada.
A entrega orientada por especificações exige o mesmo nível de rigor que os testes e a verificação de código.
4. Separe os modelos de chicotes elétricos das especificações comerciais.
A engenharia de chicotes elétricos introduz uma cola específica para cada estrutura. Mantenha essa camada isolada.
- Armazene modelos de prompts reutilizáveis e scripts de execução separadamente das especificações de recursos.
- Atualize os modelos quando o comportamento do framework mudar (por exemplo, atualizações do Spring Boot ou do Angular).
- Evite modificar todos os arquivos de especificação para alterações no nível da cadeia de ferramentas.
- Periodicamente, elimine especificações intermediárias pontuais que não agregam mais valor à arquitetura.
Isso mantém a intenção comercial estável enquanto os mecanismos de aproveitamento evoluem com segurança.
5. Utilize documentação em várias camadas para evitar confusão.
Nem todas as especificações devem estar no mesmo nível.
- Especificações do domínio: comportamento de negócios de alto nível, longa duração.
- Especificações técnicas: decisões de implementação em nível de serviço, atualizadas com mais frequência.
- Especificações de interação: contratos de front-end/back-end, essenciais para a consistência de ponta a ponta.
Quando essas camadas são explícitas, o repositório permanece navegável e as conversas de revisão permanecem focadas.
A principal conclusão é simples: trate os ativos de especificação como código de produção. Versioná-los, analise-os com lint, indexe-os, valide-os e descarte-os intencionalmente. É assim que você evita um cemitério de documentos e mantém o SDD como uma vantagem operacional em vez de um fardo administrativo.
11. Quando usar este fluxo de trabalho
Este fluxo de trabalho é ideal para funcionalidades com comportamento real e risco real: regras de negócio, contratos de API, validação, coordenação entre interface do usuário e backend, verificação de ponta a ponta e rastreabilidade relevante.
Não abuse de todo o processo para pequenas edições cosméticas ou experimentos descartáveis. O objetivo não é a formalidade, mas sim o controle onde ele realmente importa.
O desenvolvimento orientado a especificações não visa tornar tudo mais lento. Trata-se de tornar o trabalho importante explícito, testável e mais confiável.
Se você quiser entender o raciocínio por trás desse fluxo de trabalho, as duas postagens anteriores desta série abordam os fundamentos:
- Programação intuitiva, mas pronta para produção: um ciclo de feedback orientado a especificações para desenvolvimento assistido por IA.
- Engenharia de Aproveitamento: A Camada Ausente no Desenvolvimento de IA Orientado por Especificações
Conclusão final
O trabalho com IA que começa com um estímulo é uma boa maneira de explorar ideias.
O desenvolvimento orientado por especificações é uma maneira melhor de entregá-las.
Se a funcionalidade for importante, o processo deve tornar a intenção visível, as decisões explícitas, a implementação testável e a validação inevitável. É assim que a IA se torna útil em uma equipe de software real.
O fluxo de trabalho que descrevi aqui é o que eu realmente uso para entregar, especialmente para Epics, onde você pode realmente ver a beleza do desenvolvimento acelerado: integrar o repositório, escrever a especificação, revisá-la, projetar a solução, implementar o backend, adicionar a fatia de Angular e testar tudo de ponta a ponta. Essa é a diferença entre receber o código e entregar uma funcionalidade.
Uma última coisa que vale a pena notar: em todos os comandos que executamos, não usamos nenhum recurso de “incentivo”. Nada de “aja como um desenvolvedor sênior de Spring Boot”, nada de truques de persona inteligentes, nada de instruções cuidadosamente elaboradas. Essa é a beleza deste framework. O recurso de incentivo é mínimo, e é exatamente por isso que ele ajuda a nivelar uma equipe, independentemente do nível de experiência. Os poucos incentivos que usamos aqui se resumem a responder perguntas e fornecer feedback. A estrutura carrega o peso, não o incentivo.
Espero que esta estrutura ajude você e sua equipe. Sinta-se à vontade para modificá-la de acordo com suas necessidades e boa programação!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?