

Sou um grande fã do time de basquete Portland Trail Blazers e, no começo dos anos 2000, meu jogador favorito era Rasheed Wallace. Os fãs o amavam ou o odiavam. Wallace liderava em faltas técnicas quase todos os anos e na maioria das vezes ele não considerava que tinha cometido falta alguma. Muitas delas aconteciam quando o jogador do outro time perdia um lance livre e “Sheed” apaixonadamente gritava o seu mantra: “A BOLA NÃO MENTE”.
“Sheed” afirma que uma bola de basquete possui um poder metafísico que atua como um sistema que checa e equilibra a integridade do jogo. Isso pode até ser discutível (ok, provavelmente não é verdade), mas há um paralelo com o SEO: pessoas de marketing e desenvolvedores normalmente cometem faltas de SEO ao planejar um site ou criar conteúdo, mas implicitamente negam que há alguma coisa errada.
Como SEOs, utilizamos todo tipo de ferramenta para compreender questões técnicas que podem estar nos afetando: web analytics, crawl diagnostics, Google e Bing Webmaster tools. Todas essas ferramentas são úteis, mas há indiscutivelmente lacunas nos dados. Há apenas um registro verdadeiro de como motores de busca, tais como os robôs do Google, processam o seu website: são os logs do servidor web. Tenho certeza de que Rasheed Wallace concordaria que logs são uma fonte poderosa e normalmente subutilizada de dados que ajudam a manter a integridade do rastreamento do seu site por mecanismos de pesquisa.

O log de um serviço é um registro preciso de cada ação realizada por um serviço particular. No caso de um servidor web, você pode conseguir muitas informações úteis. Na verdade, antes de os analytics gratuitos (como o Google Analytics) existirem, era comum fazer o parser e a revisão de logs web com softwares como o AWStats.
Eu planejei inicialmente escrever um único artigo sobre esse assunto, mas continuei escrevendo e percebi que há muito mais para cobrir. Então eu dividirei o tema em duas partes, cada uma destacando diferentes problemas que podem ser encontrados nos logs do seu servidor web:
- Este artigo: como recuperar e fazer o parser de um arquivo de log e identificar problemas baseados no código de resposta do servidor (404, 302, 500 etc.).
- O próximo artigo: Identificar conteúdo duplicado, encorajar rastreamento eficiente, revisar tendências e procurar por padrões e alguns bônus de dicas não-relacionadas a SEO.
Passo 1: Recuperar um arquivo de log
Logs de servidores web existem em muitos formatos diferentes, e o método para recuperá-los depende do tipo de servidor que o seu site está executando. Apache e Microsoft IIS são os dois mais comuns. Os exemplos neste artigo serão baseados em um arquivo de log do Apache do SEOmoz.
Se você trabalha em uma empresa com um Sys Admin, seja muito legal e peça a ele/ela por um arquivo de log com dados de um dia e os campos listados abaixo. Eu recomendaria que o arquivo ficasse abaixo de 1Gb, uma vez que o parser do arquivo pode ter problemas para lidar com arquivos maiores. Se você tiver que gerar o arquivo você mesmo, o método para fazer isso depende de como o seu site é hospedado. Alguns serviços de hospedagem armazenam os arquivos no seu diretório home em uma página chamada /logs e salvam um arquivo de log comprimido diariamente nessa página. Você precisa se certificar de que ele inclua as seguintes colunas:
- Host: você utilizará isso para filtrar tráfico interno. No caso do SEOmoz, RogerBot passa muito tempo rastreando o site, e é preciso removê-lo para a nossa análise.
- Data: se você estiver analisando múltiplos dias, isso permite que você analise as tendências de rastreamento dos mecanismos de busca em diferentes dias.
- Página/Arquivo: isso irá te dizer em qual diretório ou arquivo está sendo rastreado e pode ajudar a apontar questões específicas em certas seções ou tipos de conteúdo.
- Código de resposta: saber a resposta do servidor – a página carregou bem (200), não foi encontrada (404), o servidor não estava disponível (503) – fornece compreensão inestimável sobre a ineficiência com a qual os crawlers podem estar atuando.
- Referências (Referrers): não é necessariamente útil para robôs de análise de pesquisa, mas pode ser muito valioso para outras análises de tráfego.
- User Agent: esse campo te informa qual mecanismo de pesquisa fez a requisição e, sem ele, uma análise de rastreamento não pode ser realizada.
Arquivos de logs do Apache são, por padrão, criados sem User Agent ou referências – isso é conhecido como “common log file”. Torne a vida de seu Sys Admin um pouco mais fácil (e talvez até mesmo cause uma boa impressão) e peça o seguinte formato:
LogFormat “%h %l %u %t \”%r\” %>s %b \”%{Referer}i\” \”%{User-agent}i\””
Para o Apache 1.3, você só precisa de “combined CustomLog log/acces_log combined”.
Para aqueles que precisam pegar os logs manualmente, você precisará criar uma diretiva no arquivo httpd.conf com uma das configurações acima. Muito mais detalhes sobre esse tema aqui.
Passo 2: Fazendo parser de um arquivo de log
Você agora provavelmente possui um arquivo comprimido de log como “meulog.gz” e é hora de começar a se aprofundar. Há uma miríade de programas, livres e pagos, para analisar e/ou fazer o parser dos seus arquivos de log. Meus principais critérios para escolher um inclui: a habilidade para visualizar dados brutos, a habilidade de aplicar filtro antes de fazer o parser e a habilidade de exportar para CSV. Eu encontrei o Web Log Explorer, e ele tem funcionado bem para mim há anos. Eu o utilizarei para esta demonstração juntamente com o Excel. Utilizei o AWStats para uma análise básica, mas descobri que ele não oferece o nível de controle e flexibilidade que eu preciso. Tenho certeza de que há muitos outros por aí que podem realizar a tarefa.
O primeiro passo é importar o seu arquivo para o software de parser. A maior parte dos parsers de web logs aceitarão vários formatos e possuem assistentes simples para guiá-lo pela importação. Com o primeiro passo da análise, gosto de ver todos os dados e não aplicar filtro algum. Nesse ponto, você pode fazer uma das duas coisas: preparar os dados no parser e exportá-los para análise no Excel, ou fazer a maioria das análises no próprio parser. Eu gosto de fazer análises no Excel para poder criar um modelo de trocas (falarei mais sobre isso no próximo artigo). Se você quiser fazer uma análise rápida dos seus logs, usar o software de parser é uma boa opção.
Assistente de importação: certifique-se de incluir os parâmetros na string da URL. Como demonstrarei mais tarde neste artigo, isso nos ajudará a encontrar caminhos problemáticos de rastreamento e fontes potenciais para conteúdos duplicados.
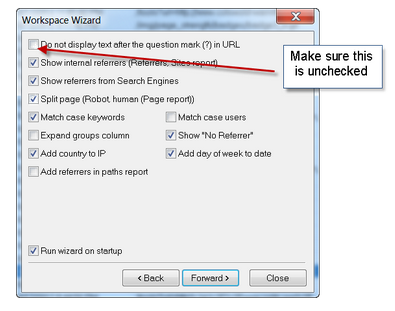
É possível escolher um filtro para os dados utilizando um regex básico de expressões regulares antes de fazer o parser. Por exemplo, se quiser analisar apenas o tráfego de uma seção particular do seu site, você pode fazer o seguinte:
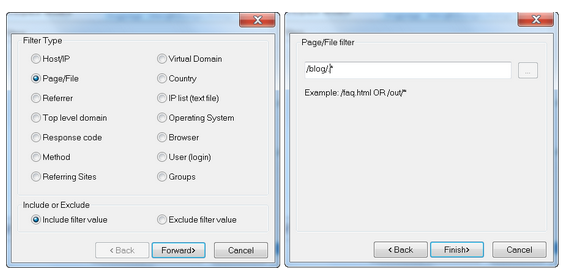
Uma vez que os dados forem carregados no parser de log, exporte todas as requisições de crawlers e inclua todos os códigos de resposta:
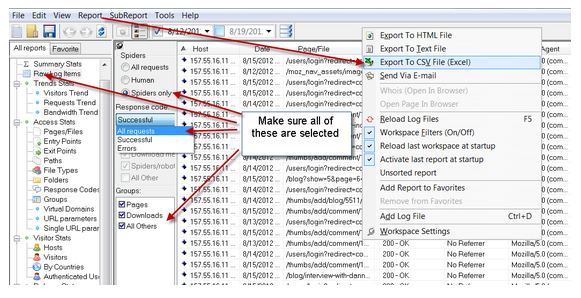
Depois que tiver exportado o arquivo para CSV e o aberto no Excel, aqui estão alguns passos e exemplos para deixar os dados prontos para a análise e pivotagem:
1. Página/Arquivo: em nossa análise, tentaremos expor os diretórios que podem ser problemáticos, portanto queremos isolar o diretório dos arquivos. A fórmula que usei para fazer isso no Excel foi esta:
Fórmula: <colocar isso em algum campo>
=IF(ISNUMBER(SEARCH(“/”,C29,2)),MID(C29,(SEARCH(“/”,C29)),(SEARCH(“/”,C29,(SEARCH(“/”,C29)+1)))-(SEARCH(“/”,C29))),”no directory”)
2. User Agent: para limitar nossa análise a mecanismos de busca com os quais nos preocupamos, precisamos pesquisar neste campo por robôs específicos. Neste exemplo, estou incluindo Googlebot, Googlebot-Images, BingBot, Yahoo, Yandex e Baidu.
Formula (sim, ela é F-E-I-A)
=IF(ISNUMBER(SEARCH(“googlebot-image”,H29)),”GoogleBot-Image”, IF(ISNUMBER(SEARCH(“googlebot”,H29)),”GoogleBot”,IF(ISNUMBER(SEARCH(“bing”,H29)),”BingBot”,IF(ISNUMBER(SEARCH(“Yahoo”,H29)),”Yahoo”, IF(ISNUMBER(SEARCH(“yandex”,H29)),”yandex”,IF(ISNUMBER(SEARCH(“baidu”,H29)),”Baidu”, “other”))))))
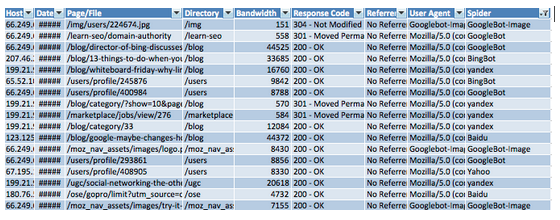
Seu arquivo de log está agora pronto para algumas análises e deve se parecer com isso:
Vamos fazer uma pausa?
Passo 3: Descobrir códigos de erros de resposta e do servidor
A forma mais rápida de examinar as questões que os mecanismos de pesquisa estão tendo para fazer o rastreamento do seu site é olhar para os códigos de resposta do servidor que estão sendo enviados. Muitos 404 (página não encontrada) podem significar que o rastreamento está sendo desperdiçado. Excessivos redirecionamentos 302 podem apontar para links quebrados na arquitetura do seu site. Apesar de o Google Webmasters Tools fornecer algumas informações sobre tais erros, eles não fornecem um cenário completo: LOGS NÃO MENTEM.
O primeiro passo da análise é pivotar uma tabela a partir dos dados do seu log. Nosso objetivo é isolar os crawlers com os códigos de resposta que estão sendo servidos. Selecione todos os seus dados e vá para ‘Data> Pivot Table.’
No nível mais básico, vejamos quem estava rastreando o SEOmoz neste dia específico:
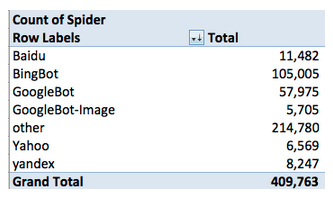
Não podemos tirar conclusões definitivas a partir desses dados, mas há algumas coisas que devem ser percebidas para uma análise mais profunda. A primeira delas é que o BingBot está rastreando o site numa taxa 80% maior. Por quê? Em segundo, “outros” robôs somam quase metade dos rastreamentos. Deixamos algo de fora de nossa pesquisa no campo User Agent? Como é possível ver em seguida, podemos ter uma boa ideia de que a maior parte do que é contabilizado como “outros” é o RogerBot – podemos excluí-lo.
Em seguida, vejamos os códigos do servidor para os mecanismos que nos interessam mais.
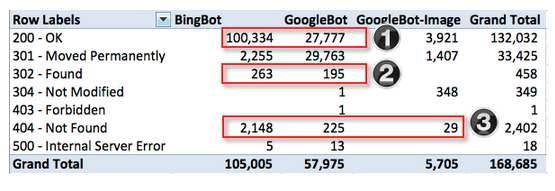
Eu destaquei as áreas que veremos mais de perto. No geral, a relação entre o que é bom e ruim parece saudável, mas já que vivemos pelo mantra de que “cada pouquinho importa”, vejamos o que está acontecendo.
1. Por que o Bing está rastreando o site 2x mais do que o Google? Devemos investigar se o Bing está fazendo um rastreamento ineficiente e se há algo a fazer para ajudá-lo, se é o Google que não está indo tão a fundo quanto o Bing e se há algo que possamos fazer para encorajá-lo a efetuar um rastreamento mais profundo.
Ao isolar as páginas que foram servidas com sucesso (códigos 200) ao BingBot, o potencial culpado aparece imediatamente. Próximo de 60 mil das 100 mil páginas que o BingBot rastreou com sucesso foram redirecionamentos de logins de usuários a partir do link de um comentário.
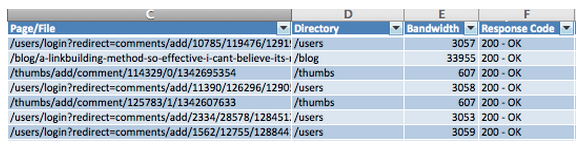
O problema: o SEOmoz é projetado de forma que se um link de comentário é requisitado e o JavaScript não estiver habilitado, ele enviará um redirecionamento (oferecido com um código 200 pelo servidor) para uma página de erro. Com 60% do rastreamento do Bing sendo desperdiçado com páginas desse tipo, é importante que o SEOmoz bloqueie os mecanismos de rastrear essas páginas.
A solução: acrescentar rel=’nofollow’ a todos os links de comentários e respostas. Tipicamente, o método ideal para dizer a um robô para não rastrear algo é uma diretiva no arquivo robots.txt. Infelizmente, isso não funcionaria nesse cenário porque a URL está sendo servida via JavaScript após o clique.
O GoogleBot está lidando com os links de comentários melhor do que o Bing e evitando todos eles. Entretanto, o Google está rastreando de forma bem-sucedida um punhado de links que são redirecionamentos de logins. Dê uma olhada no robots.txt, e você verá que esse diretório deve estar provavelmente bloqueado.
2. O número de respostas 302 sendo servidas ao Google e ao Bing é aceitável, mas não custa fazer uma revisão caso haja maneiras melhores de lidar com alguns dos casos mais extremos. Na maior parte dos casos, o SEOmoz está usando 302 para categorias extintas do blog que redirecionam o usuário para a página principal do blog. Elas também estão sendo usadas para páginas de mensagens privadas/messagens e uma diretiva no robots.txt deve excluir essas páginas de serem rastreadas.
3. Um dos dados mais valiosos que você pode conseguir a partir dos logs do servidor são páginas que resultaram em um 404 ao serem rastreadas. O SEOmoz tem feito um bom trabalho ao administrar esses erros e não possui um nível alarmante de 404s. Uma forma rápida de identificar potenciais problemas é isolar os 404s por diretório. Isso pode ser feito ao pivotar uma tabela com “Directory” como o rótulo das linhas e a contagem de “Directory” no seu campo de valores. Você vai ter algo como:
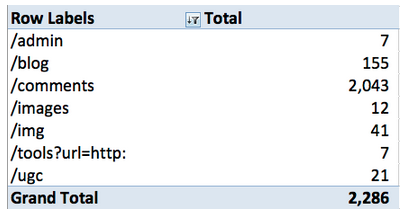
O problema: o principal problema que está ocorrendo é que 90% dos 404s estão em um único diretório/comments. Dada a questão relativa ao BingBot e ao redirecionamento JavaScript mencionado acima, não se trata exatamente de uma surpresa.
A solução: a boa notícia é que já estamos usando rel=’nofollow’ nos comentários que levam a esses 404s, e isso resolverá também esse problema.
Conclusão
As ferramentas de webmaster do Google e do Bing fornecem informações sobre erros de rastreamento, mas em muitos casos os dados são limitados. Como SEOs, devemos utilizar todas as fontes disponíveis, afinal, há apenas uma única fonte de dados em que você pode confiar de verdade: a sua própria.
LOGS NÃO MENTEM!
E para o seu prazer, aqui está um clipe de bônus por ter lido todo o artigo.
***
Este artigo é uma republicação feita com permissão. Moz não tem qualquer afiliação com este site. O original está em http://moz.com/blog/seo-finds-in-your-server-log

De 0 a 10, o quanto você recomendaria este artigo para um amigo?