

Introdução
A Amazon Web Services (AWS) é uma plataforma de cloud computing flexível, de baixo custo e fácil de usar. Pacotes de softwares NoSQL são facilmente instaláveis na nuvem da AWS. Rodar o seu próprio banco de dados na Amazon Elastic Cloud Compute (Amazon EC2) é o melhor cenário para usuários cujas aplicações precisam de benefícios únicos de configuração e estrutura para operações de grande performance em grandes conjunto de dados.
Este artigo irá ajudar você a entender uma das mais populares opções de NoSQL disponível na plataforma de cloud computing da AWS, a aplicação open source MongoDB. Nós faremos um overview pelas boas práticas de uma forma geral que se aplicam na maioria dos NoSQLs, e nós examinaremos as características de implementação mais importantes do MongoDB, como performance, durabilidade e segurança. Nós daremos uma importância particular à identificação dos recursos que suportam escalabilidade, alta disponibilidade e tolerância a falhas.
O que é NoSQL?
NoSQL é um nome popular para um grupo de software de armazenamento estruturado que é desenhado e otimizado para alta performance de operações em grandes conjunto de dados. Essa otimização vem com um prejuízo ao estrito cumprimento do ACID ( atomicidade, consistência, isolamento e durabilidade) e, como o próprio nome já diz, sintaxe SQL nativa. O software NoSQL é fácil para desenvolvedores utilizarem, escalável horizontalmente e otimizado para específicos tipos de trabalho.
Hoje existem três principais categorias de aplicações NoSQL:
- Bancos chave-valor, como Cassandra, Riak, e o Projeto Voldemort
- Banco de dados gráficos, como Neo4j, DEX, e InfiniteGraph
- Bancos orientados a documentos como MongoDB, eXist, e BaseX*
Essas aplicações NoSQL são ou softwares open source (OSS) ou projetos comerciais de código fechado. As aplicações são escritas em diferentes linguagens – eles têm diferentes interfaces e implementam diferentes otimizações.
NoSQL no Amazon EC2
A Amazon Web Services (AWS) provê uma excelente plataforma para rodar vários sistemas de dados avançados na nuvem. Algumas das características únicas que uma nuvem pública fornece são fortes benefícios para cargas de trabalho NoSQL. De vários modos, a infraestrutura da AWS é similar à infraestrutura física, local, mas há algumas diferenças. Um conhecimento geral dessas diferenças pode ajudar muito na tomada de boas decisões a respeito da infraestrutura do seu sistema.
A AWS tem um serviço nativo de NoSQL que não precisa de administração direta e oferece um preço baseado no uso. Considere essas opções como uma possível alternativa para construir o seu próprio sistema com uma aplicação NoSQL open source ou comercial.
O Amazon Simple Storage Service (Amazon S3) possui um serviço de interface web simples que pode guardar e entregar qualquer quantidade de dados a qualquer momento para qualquer lugar na web. O Amazon S3 dá a qualquer desenvolvedor o acesso à mesma infraestrutura altamente escalável, confiável, segura, rápida e barata que a Amazon usa para rodar sua própria rede global e seus websites. O Amazon S3 maximiza os benefícios da escala e passa esses benefícios para você.
O Amazon DynanoDB é um serviço completamente gerenciável de banco de dados que possui rapidez e performance previsível com a mesma escalabilidade. Todos os dados são armazenados em SSDs e são automaticamente replicados pelas três Availability Zones em uma região AWS para prover alta disponibilidade e durabilidade de dados. Com o Amazon DynamoDB, você pode tirar o peso da administração de operar um cluster de banco de dados escalável e de alta disponibilidade enquanto paga um preço pequeno e variável apenas pelos recursos que você consumir.
Performance
A performance de um sistema NoSQL no Amazon EC2 depende de vários fatores, incluindo o tipo de instância EC2, o número e a configuração dos volumes Amazon Elastic Block Stores (Amazon EBS), a configuração do software NoSQL, e a carga de trabalho da aplicação. Nós encorajamos que você faça um comparativo da sua atual aplicação com vários tipos de instâncias EC2 e configurações de armazenamento para que você consiga selecionar a configuração mais apropriada.
Para aumentar a performance do seus sistemas, você precisa saber quais recursos do servidor restringem a sua performance. Se a CPU ou a memória limita o desempenho do seu sistema, você pode escalar os recursos de memória, processamento e rede apenas selecionando um tipo maior de instância EC2. Lembrando: Amazon Machine Images (ou AMIs) de 32 bits não podem rodar em instâncias de 64 bits, então se você já prevê a necessidade de instâncias de alta performance, comece com uma instância 64 bits. Lembrando, também, que a mudança de uma instância existente para uma de tamanho diferente requer um ciclo de stop/start.
Se a sua performance está limitada pelo I/O de disco, você pode considerar a mudança nas configurações de seus recursos de disco. Os volumes Amazon EBS e o bloco de armazenamento persistente disponível no Amazon EC2 são conectados através da rede. Um aumento na performance da rede pode ter um impacto significante para agregar performance, então tenha certeza de escolher o tamanho apropriado da instância. Se sua instância suporta a opção EBS-Optimized, habilitando-a você irá adicionar 500 Mbps ou 1000 Mbps (dependendo do seu tipo de instância) de largura de banda para o EBS. Para escalar performance de I/O além de 100 IOPS (input output operations per second) que um simples volume padrão EBS pode entregar, você pode alavancar os volumes Provisioned IOPS, que permitem configurações acima de 4000 IOPS por volume.
Se você precisa de grandes concentrações de I/O, pode aumentar o número de volumes EBS como um armazenamento proporcional de EBS (8 x 250 GB volumes EBS versus 2 x 1000 GB volumes). Se você precisa de um conjunto, pode usar um software de RAID (Redundant Array of Independent Disks), 0 (distribuição de disco) ou RAID 10 (um espelho de discos) através de múltiplos volumes EBS para aumentar um o IOPS total de um único volume lógico. Lembrando: utilizar RAID 0 reduz a durabilidade operacional do volume lógico, diminuindo inversamente proporcional o número de volumes EBS do conjunto. De forma similar, RAID 10 provê um aumento na redundância e, se um volume falhar, existe a habilidade de substituir um volume EBS simples sem matar sua aplicação. RAID 10 também oferece um aumento no rendimento de leitura para cada pedaço de dados, e a redução de até 50% no conjunto de performance de escrita. Avalie com muito cuidado o modelo de redundância que você vai usar em sua aplicação.
Um volume padrão EBS simples pode ter aproximadamente 100 IOPS em média, e uma simples instância com um array de 10 ou mais discos EBS acoplados pode oferecer cerca de 1000 IOPS. Provisionar IOPS em volumes EBS permite que você quadruplique essa performance com um simples volume provisionado sem aumentar o risco de falha associado com a agregação do RAID 0. Com dois volumes EBS Provisioned IOPS configurados para 4000 IOPS em instâncias m3.2xlarge m2.4xlarge ou m1.xlarge EBS-Optimized, 8000 IOPS de leitura e escrita ficam disponíveis em uma instância simples, o que pode saturar muito o link de rede entre EBS Optimized e o EBS. Com a intenção de melhorar essa performance, os tamanhos dos blocos devem ser limitados a 16 KB, e a fila de mais de 5 requisições a cada 1000 IOPS deve ser mantida. Pelo fato de Provisioned IOPS poder processar requisições de I/O menores do que esse limite de 16 KB, aplicações com uma média de tamanho de blocos de escrita/leitura menores que 16 KB podem aumentar sua performance apenas aumentando o número de volumes Provisioned IOPS. Por exemplo, nos mesmos hosts descritos acima, se a média de tamanho do bloco é 8 KB, quatro volumes Provisioned IOPS podem ser anexados para entregar mais de 16.000 8 KB IOPS.
Para acesso sequencial a disco, discos nativos (efêmeros) do Amazon EC2 oferecem alta performance e não impactam na conectividade da sua rede. Alguns consumidores usam discos nativos em conjunto com Amazon EBS para economizar largura de banca e I/O do EBS para operações pequenas e aleatórias.
Em muitos casos, as variáveis são muito abstratas. Em geral, você pode usar o mesmo sistema de performance ajustando opções no ambiente Amazon EC2, da mesma forma que faz no seu ambiente de servidores físicos. Você pode também escalar a performance total do seu sistema NoSQL, escalando horizontalmente através de múltiplos servidores com distribuição, cache e estratégias de replicação síncrona ou assíncrona.
Durabilidade e disponibilidade
Nenhuma abordagem para armazenamento de dados estruturados é completa sem usar as opções disponíveis em cada sistema para uma redundância no nível de aplicação. O ambiente do Amazon EC2 e o serviço Amazon NoSQL possuem as ferramentas que você precisa para entregar serviços altamente duráveis, como mostra a tabela abaixo:

Elasticidade e escalabilidade
Em vários casos, usuários de soluções NoSQL no Amazon EC2 podem usar a vantagem da elasticidade e escalabilidade por trás da infraestrutura da AWS. Por exemplo, uma vez que você possui uma instância Amazon EC2 configurada com sua aplicação de armazenamento de dados estruturados, você pode agregar a instância em uma AMI customizada e depois criar múltiplas instâncias com suas configurações em alguns minutos.
Para muitos consumidores, selecionar uma classe de instância com alta performance é o método mais fácil de aumentar a performance de uma aplicação. Selecionar instâncias e mais instâncias de alta performance é atualmente conhecido como “scaling up”. Scaling up é particularmente útil se você tem várias janelas de manutenção e pode aguentar o seu sistema offline. Métodos mais avançados de escalabilidade, distribuição, ou qualquer outro modo de distribuir as pesquisas ao banco de dados através de múltiplas instâncias Amazon EC2 podem trazer ainda mais performance. Aumentar performance inserindo instâncias adicionais e distribuindo a carga através delas é conhecido como “scaling out”.
Configuração
Para criar um armazenamento de dados estruturados NoSQL em uma instância Amazon EC2, você pode lançar uma instância de uma AMI que possui um sistema operacional base que você quer e depois instalar a aplicação usando o software padrão de instalação oferecido pelo sistema operacional. Lembre: não há drives de DVD na nuvem, então você deve fazer o download do software requerido.
Após a sua aplicação estar instalada e configurada na instância Amazon EC2, você pode interagir com sua instância usando a interface de gerenciamento, também disponibilizando essa interface através da web (ou uma VPN) para usar localização ou acessando remotamente o servidor através de SSH, NX, VNC, ou RDP. Você pode trabalhar com uma aplicação no Amazon EC2 apenas como você quer com as premissas do software de aplicação. Você irá precisar configurar os grupos de segurança da sua instância para permitir trafego através das portas que a aplicação NoSQL vai usar. Todas as portas são desabilitadas por padrão, então tenha certeza de que você abriu todas as portas que irá precisar.
Os volumes Amazon EBS que funcionam como drives da raiz da instância Amazon EC2 são nativamente redundantes, e eles são desenhados para sobreviver a falhas físicas da instância Amazon EC2 ou um erro individual de hardware EBS; no entanto, você poderá ter um sistema operacional complexo e configurações que devem ser preservadas; dessa forma, faça uma cópia da sua AMI.
Preço
Não precisar gerenciar o hardware e ter a capacidade de rapidamente provisionar mais capacidade para o seu armazenamento de dados estruturados NoSQL fazem da nuvem da AWS uma ótima solução para rodar o seu sistema NoSQL. A nuvem AWS não te dá apenas flexibilidade no design, o que nós iremos cobrir com grandes detalhes nas próximas seções deste artigo, mas também reduz custos operacionais. Dependendo da arquitetura da sua solução NoSQL, há vários fatores que você deve considerar para estimar o custo da entrega:
- Processamento: Cobrança de instância/hora do Amazon EC2, tanto on-demand como Reserved (Light, Medium ou Heavy) como modelos de Spot para processar o sistema.
- Armazenamento: Volumes EBS (os dois, standard e Provisioned IOPS) para seu armazenamento (tanto capacidade de armazenamento atual quando I/O para disco).
- Transferência de dados: Tráfego de rede, cobranças diferenciadas para comunicação entre Availability Zone com configurações que abrangem muitas zonas, como em replicas sets).
- Backups: Armazenamento Amazon S3 para snapshots de configurações de volumes (EBS) de dados.
Sinta-se à vontade para usar as ferramentas, como a AWS Simple Monthly Calculator, para modelar o projeto de sua carga de trabalho.
MongoDB no Amazon EC2
Overview
O MongoDB é um sistema de armazenamento de dados estruturados escalável, de alta performance e open source. O MongoDB contém um armazenamento em estilo JSON, orientado a documentos com suporte para full index, distribuição, replicação sofisticada e compatibilidade com o paradigma Map/Reduce. O MongoDB é focado na flexibilidade, força, velocidade e facilidade de uso.
Nota: Os procedimentos neste artigo usam duas linhas de comando distintas. Os itens que começam com $ estão rodando na linha de comando padrão do Linux, o que requer ajustes de sintaxe para sistemas Windows. Os itens que começam com > estão rodando no mongo shell e representam comandos para o processo mongod.
Dicas básicas
- MongoDB é atualizado frequentemente; www.mongodb.org é uma fonte importante para as últimas melhorias no código, documentação e novidades nesse projeto open source (OSS).
- 10gen desenvolve o MongoDB e oferece assinaturas, o que inclui recursos entreprise que não estão no código open source, suporte em produção, treinamento e consultoria para MongoDB.
- Use apenas instâncias 64 bits. MongoDB armazena apenas 2,5 GB de dados em sistemas de 32 bits. Para mais informações, vá em http://blog.mongodb.org/post/137788967/32-bit-limitations
- Instâncias T1.micro não são recomendadas para usar com o MongoDB em produção, incluindo árbitros, servidores de configuração e gerenciadores de distribuição mongos.
- Use XFS ou Ext4. Esses sistemas de arquivos suportam a suspensão de I/O e limpeza na escrita de cache, o que é critico para a criação de snapshots consistentes em multidiscos, e também é uma opção importante de melhora na performance do MongoDB.
- Use volumes EBS Provisioned IOPS com o RAID 10. O MongoDB é especificamente otimizado para os benefícios do RAID 10.
- Tenha cuidado com objetos grandes. O MongoDB atualmente restringe os objetos a 16 MB. Se você precisa acomodar grandes objetos, use o GridFS com o Mongo. Para mais informações, vá para https://mms.mongodb.com/manual/reference/gridfs/
- Use o MongoDB 2.2 ou superior. Recursos significantes foram implementados na versão 2.0, incluindo segurança em ambientes compartilhados e outros elementos críticos.
- Desligue o atime e o diratime quando montar volumes de dados. Fazer isso reduz muito o I/O e desabilita recursos que não serão úteis para o MongoDB.
Instalação básica do MongoDB
- Inicie uma instância Amazon EC2 usando uma AMI da sua escolha (no nosso exemplo, usaremos a Amazon Linux 64-bit AMI).
- Crie um volume Amazon EBS para usar como armazenamento do MongoDB e anexe-o à sua instância.
- Conecte via SSH.
- Crie um sistema de arquivos no seu volume EBS:$ sudo mkfs -t ext4 /dev/*the_connection_you_attached_the_volume_to_for_example_sdf*
- Crie um diretório onde esse sistema de arquivos possa ser montado.
$ sudo mkdir -p /data/db/$ sudo chown mongod:mongod /data/db - Edite o seu fstab para o volume ser montado no start up da máquina.
$ sudo sh –c “echo ‘/dev/sdf /data/db auto noatime,noexec,nodiratime 0 0’ >> /etc/fstab“ - Monte o volume
$ sudo mount -a /dev/sdf /data/db –o noatime,noexec,nodiratime - Instale o MongoDB com o gerenciador de pacotes: para fazer isso, crie o seguinte arquivo:/etc/yum.repos.d/10gen.repo
- Edite o conteúdo do arquivo para o seguinte: [10gen]name=10gen Repositorybaseurl=http://downloads-distro.mongodb.org/repo/redhat/os/x86_64gpgcheck=0
- Após criar o arquivo, rode o seguinte comando:
$ sudo yum install mongo-10gen mongo-10gen-server - Edite o arquivo /etc/mongod.conf para incrementar o oplogSize, habilitar o journaling e setar os diretórios de dados e logs.dbpath = /data/db
logpath = /data/db/logs - Use o Painel de Gerenciamento da AWS para permitir acesso ao servidor de aplicação através das portas apropriadas criando regras no seu Amazon EC2 Security Group. A porta padrão é a 27017.
- Inicie o mongod $ service mongod start
Arquitetura
O design da sua instalação do MongoDB no Amazon EC2 vai depender do tipo de escala que você deseja operar. Você está experimentando o MongoDB por sua conta em um projeto privado? Se sim, você irá, provavelmente, instalar o mongod (a aplicação MongoDB rodando) na mesma máquina que o resto de seu software, e colocará a estrutura de arquivos do mongod com o resto de sua aplicação no mesmo volume root da sua instância. Isso escala bem para experiências em desenvolvimento; entretanto, para entregas em produção, replica sets e, em alguns casos, distribuição, devem ser usados para prover uma alta performance e tolerância a falhas.
O MongoDB possui duas construções separadas para topologias multi nodes. Essas construções, replica sets e replica sets distribuídos, são oferecidas em conjunto em sistema de alta performance. As replicas sets são clusters de replicação assíncrona e com tecnologia automática de failover, e o sharding é um sistema de distribuição de dados automático. Aumentar o número de instâncias em uma replica set aumenta a tolerância a falhas. Enquanto aumenta o número de shards (cada um é uma replica set completa), você pode distribuir os dados para processos mongod separados, o que provê uma escalabilidade horizontal para performance de leitura e escrita.
O processo mongos distribui cada request para o shard apropriado, o que provê acesso contínuo ao seu conjunto de dados distribuído. Você pode usar o atributo ReadPreference nas suas solicitações se você quer habilitar a distribuição de requests para os membros secundários.
Construindo blocos
mongod
O mongod é a aplicação primária do MongoDB. Ele é responsável pelo sistema de armazenamento estruturado. O mongod irá rodar em cada réplica do cluster que você utilizar.
mongos
O mongos é o processo de roteamento e coordenação que faz com que os nós mongod se pareçam como um único sistema de arquivos. O processo mongos não armazena dados; em vez disso, ele pega o seu estado do processo configserver na inicialização. Qualquer mudança que acontecer no processo configserver será propagada para cada processo mongos. O processo mongos armazena alguns estados, por exemplo, cursores abertos para clientes. Perder um processo mongos irá invalidar esses cursores, mas não resultará em nenhum dado perdido.
O processo mongos pode rodar nos servidores compartilhados por eles mesmos, mas eles são leves o bastante para rodar cada um em um servidor de aplicação. Vários processos mongos podem rodar simultaneamente, porque esses processos não coordenam um ao outro.
Configserver
O configserver é um processo mongod que replica de forma síncrona as informações de estado de um ambiente compartilhado. Embora o configserver possa rodar sozinho, para a segurança dos dados e para alta disponibilidade, todo ambiente de produção deve ter três processos configserver que contêm cópias dos mesmos metadados. O processo configserver é bastante leve, mas requer CPU e recursos de disco. Definir o tamanho de um servidor mongos irá depender do volume de dados, número de shards, número de collections e do número de servidores mongos no ambiente. Os dados no processo configserver são críticos para a operação do cluster, e muito cuidado deve ser tomado para não perder os três processos configserver ou os seus dados.
Para mudar o endereço de IP de um processo configserver, você irá precisar derrubar o seu cluster ou mudar a localização para onde o hostname aponta. Uma prática fácil é ter um registro DNS para cada instância configserver. Dessa forma, você pode mudar as localizações facilmente. Essa prática insere uma dependência em sua solução de DNS. O Amazon Route 53 provê um serviço de DNS de alta disponibilidade e alta performance dentro do Amazon EC2 que é muito fácil de configurar, ou você pode rodar um BIND ou qualquer outro serviço de DNS dentro da sua rede.
O configserver é exigido apenas em ambientes compartilhados. Se você estiver rodando apenas uma replica set, não há necessidade do configserver.
Design de produção
Então, depois desse overview, como um sistema pode escalar para acomodar o crescimento do processamento ao longo do tempo? Os próximos passos e diagramas irão guiá-lo por um exemplo de design de um ambiente de produção que escala a medida que o processamento sobe.
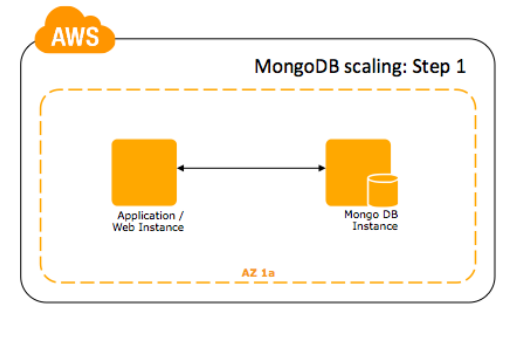
Passo 1: Separe o servidor mongod do servidor de aplicação. Nesta configuração, não há a necessidade do configserver, ou mongos, porque não há uma estrutura compartilhada para as aplicações navegarem.
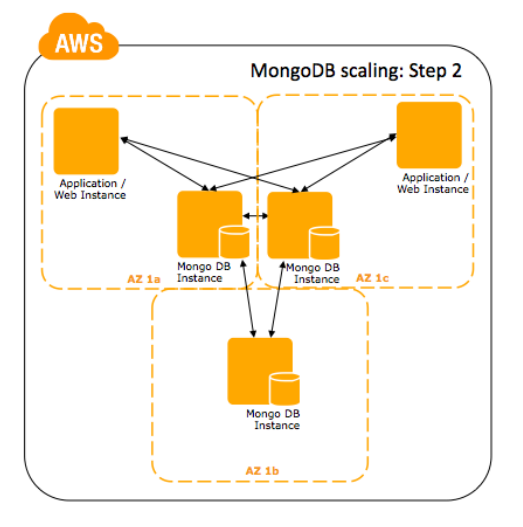
Passo 2: Para replica sets, rode múltiplas instâncias do mongod através de separadas Availability Zones (ou Regions).
Nota: A replicação do MongoDB é assíncrona; se você quer ter certeza de que as escritas estão sendo propagadas pelos múltiplos nós depois que o nó primário as aceita, use o Write Concern. Para mais informações, veja o termo Write Concern na documentação do MongoDB.
Use um número ímpar de instâncias. Neste exemplo nós usamos três, mas você pode usar mais se precisar de mais performance de leitura. Quando o MongoDB detecta que o primeiro nó no cluster falhou, ele faz uma eleição para determinar qual nó será o novo primário. É critico neste caso que a maioria esteja disponível para a eleição. Na intenção de prevenir a falha de uma eleição, um número ímpar de nós deve ser escolhido. Para garantir alta disponibilidade, essas replicas devem ser colocadas em diferentes Availability Zones.
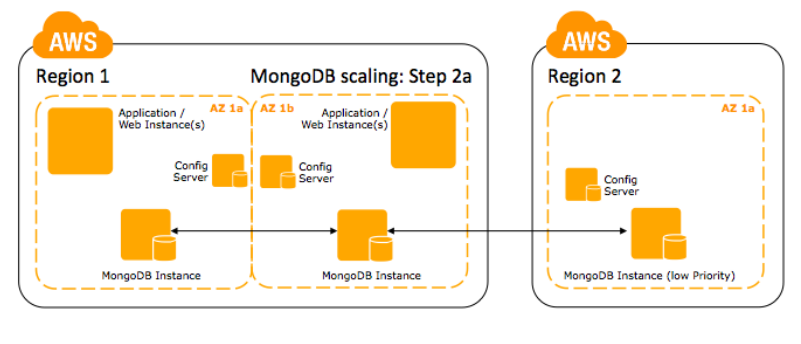
Passo 2a: Se você deseja uma região que suporta apenas duas Availability Zones, considere replicar para a outra região mais próxima. Configure essa replica com uma baixa prioridade, e faça uma otimização para a conexão através de regiões.
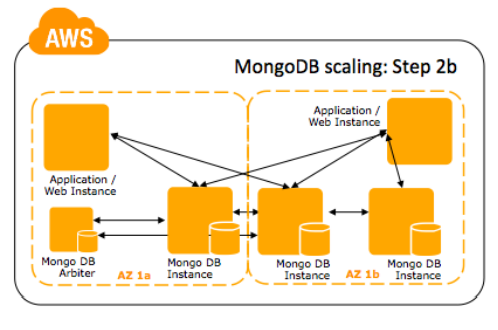
Passo 2b: Como alternativa, você pode colocar uma instância árbitro na Availability Zone com o menor número de instâncias membros da replica set. Tendo uma instância árbitro, você pode ter um faillover quando a maioria das replicas (neste exemplo 2/3) caem.
Passo 3: Crie um cluster distribuído de replica sets. Neste exemplo, três processos configserver estão rodando em instâncias EC2 m1.small ou maiores, cada uma em uma Availability Zone separada.
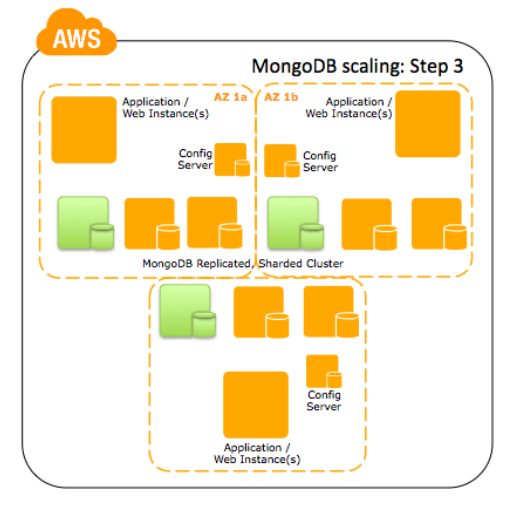
Passo 4: Escale para um sistema multi região que usa uma replica temporizada para fazer um Warm Backup. Este não é um passo de alta escala, mas é um padrão para alta disponibilidade.
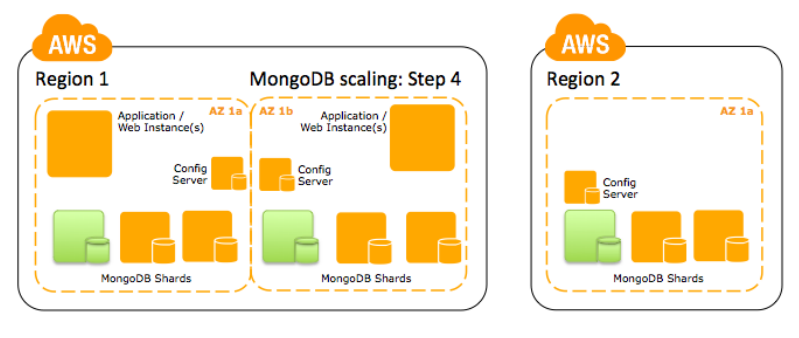
Considerações adicionais de escalabilidade
Escalabilidade vertical não oferece os mesmos benefícios da escalabilidade horizontal. Instâncias de alta performance verticalmente escaláveis podem prover muitos benefícios de performance de uma replica mais complexa e topologia distribuída, mas lembre-se de que essas instâncias escaláveis verticalmente vêm com nenhum benefício significante de tolerância a falhas. Enquanto isso é critico para a maioria dos casos para prover um processo mongod com memória e IOPS de disco suficientes, lembre que você tem uma gama ilimitada de recursos virtuais se você escalar horizontalmente.
Escalar passo a passo, quando você sabe que precisa de um sistema grande, não é eficiente no MongoDB. Há custo/benefícios muito significantes para iniciar um set cheio de shards que você espera rodar ou aumentar o número de instâncias na replica set todas de uma vez. Desconsidere passos incrementais se você puder.
Da mesma forma, escalar sob o máximo de carga não é uma boa ideia. O MongoDB precisa de recursos significantes de processamento, armazenamento e rede para expandir suas pegadas. Esperar até que você tenha 99% de carga para começar o processo de compartilhamento não irá ajudar; irá simplesmente adicionar mais trabalho ao sistema no momento menos oportuno. Nós recomendamos que você faça mudanças com antecedência e escale horizontalmente o mais cedo possível, enquanto você possuir capacidade para gastar na transição. Um paliativo em potencial que você pode tentar se você estiver com uma situação de overload é construir o seu novo bloco de instâncias usando backups das instâncias em produção – pegue uma pequena janela de manutenção para sincronizar o novo bloco mais poderoso, e depois retorne o serviço.
Desenhando o armazenamento para suportar o MongoDB
O padrão de escalonamento de instâncias para um cluster MongoDB é desenhar para entregar processos de memória adicionais para sua carga de trabalho. Você irá querer desenhar sua infraestrutura com muito cuidado para não deixar gargalos no seu armazenamento e fazer o melhor uso dos seus recursos de armazenamento disponíveis.
O MongoDB tem uma série de processos internos que precisam de rápido acesso ao disco, mas com diferentes padrões de acesso.
Journal – É um log de transação de updates no banco de dados. Toda operação de update é armazenada no journal antes de ser aceita. O journal é periodicamente enviado para o disco. Esse envio acontece tipicamente a cada 100 ms, embora às vezes aconteça com mais frequência. O tamanho de cada envio de journal irá depender do volume de dados que foram escritos no MongoDB.
Background flushing – O MongoDB usa nmap para acessar o banco de dados suportado pelo seu sistema de arquivos. Depois que os updates são escritos no journal, eles são aplicados na memória para uma versão nmapped dos arquivos de dados. Com a intenção de sincronizar as mudanças na memória com a versão dos dados no disco, o MongoDB periodicamente sincroniza a versão na memória dos dados com a versão em disco. Por padrão, isso ocorre a cada 60 segundos, mas você pode melhorar esse intervalo usando a opção syncDelay. O volume atual de dados sincronizados durante esse processo vai depender do seu tipo de trabalho. Se você faz muitos updates de objetos variados no MongoDB, você precisará sincronizar uma grande quantidade de páginas de memória durante o processo. Por outro lado, se você faz apenas updates em um único objeto repetidamente, é possível que você só precise sincronizar a parte da memória que possui esse objeto.
Page faults – Para o MongoDB processar uma operação em um objeto, esse objeto deve estar alocado na memória. Quando você executa uma operação de escrita ou leitura em um objeto que não está atualmente na memória, um page fault é disparado. Em um page fault, o sistema operacional busca essa página do disco e carrega na memória. Se sua aplicação estiver trabalhando com capacidade maior do que a RAM, a solicitação de acesso a alguns objetos irá causar page faults antes que a operação possa ser completada. Da mesma forma, se você inicia o MongoDB frio (ex.: onde não há nenhum dado carregado no cache de página), há um período de aquecimento no qual as operações podem disparar uma grande quantidade de page faults. (Reiniciar o processo mongod não resulta em um cenário de “inicialização a frio”, porque as páginas estão atualmente cacheadas pelo sistema operacional e continuam na memória quando o processo reinicia).
O tamanho das requisições de I/O nos dispositivos de blocos subjacentes são tipicamente controlados pela sua escolha de sistema operacional, sistema de arquivos e configurações de dispositivos de blocos. Em particular, você deve prestar atenção nas configurações read-ahead dos seus dispositivos de blocos para ver quanto de dados é lido quando ocorre um page fault. Ter uma configuração alta para o read-ahead é um erro típico, pois isso fará com que o sistema leia mais páginas que o necessário na memória e desalojará outras páginas que podem ser muito úteis para a sua aplicação. Isso é verdade particularmente para serviços que limitam o tamanho do bloco, como os volumes Provisioned IPOS EBS.
Entender o total de processamento de I/O criado pelo journal, o background flush e a ocorrência de page faults é a chave para selecionar uma configuração de armazenamento apropriada. A maioria do I/O gerado pelo MongoDB é aleatória, e a coisa na qual você mais deve prestar atenção é em quantos IOPS são precisos para suportar sua carga de trabalho. Se o seu trabalho é muito maior que a memória com padrões de acesso aleatórios, você precisará de milhares de IOPS para sua camada de armazenamento satisfazer a demanda.
Uma vez que você determinou a carga de IOPS para seu banco de dados, volumes Provisioned IPOS dispõem de uma solução excelente para construir uma camada de armazenamento de alta performance para sua instância MongoDB. Volumes regulares do EBS não são desenhados para disponibilizar um grande raio de I/O para o armazenamento provisionado. Por outro lado, os volumes Provisioned IOPS suportam taxas de IOPS especificamente configuradas, fazendo que fique muito mais fácil prever a performance esperada de uma configuração de sistema. Os volumes Provisioned IOPS podem ser provisionados com mais de 4000 IOPS, e o software de RAID pode ser usado para amarrar esses volumes todos juntos em um array que exibe uma performance muito maior.
Então, como você deve crescer? Estas são algumas configurações eficientes para armazenamento que incrementam a densidade de uma instância. Sua carga de trabalho específica pode requerer uma configuração diferente, mas estes são bons lugares para começar.
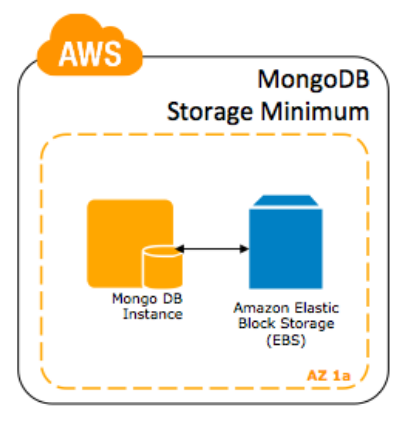
Escala Mínima – Use um Amazon EBS. O Amazon EBS tem um cache de escrita significante e possui uma performance de I/O, e isso provê grande durabilidade para os discos efêmeros das instâncias Amazon EC2. Se você está querendo usar os discos efêmeros em instâncias que possuem mais de um único volume, tenha certeza de espelhar esses volumes (usando RAID 1 ou RAID 10 no x1.xlarge) para acrescentar durabilidade operacional. Lembre:, mesmo se esses discos estiverem espelhados, se a instância parar, falhar ou terminar, você perderá todos os seus dados. Usar os volumes Amazon EBS é uma ótima pedida para sistemas que entregam menos de 100 operações MongoDB por segundo, ou são tolerantes a variações de performance do armazenamento.
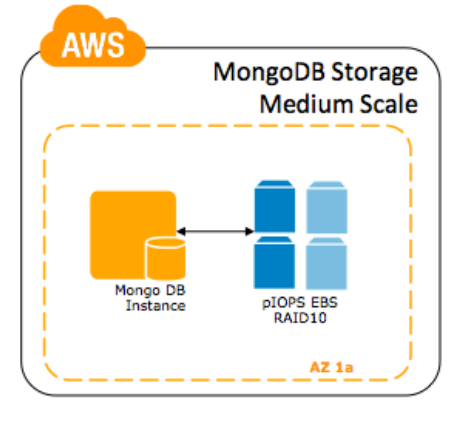
Escala Média – Para otimizar para alta durabilidade e escalabilidade de leitura, use o RAID 10 em volumes Provisioned IOPS EBS. Para uma melhor performance do volume nessa escala, use uma instância m1.large, m2.2xlarge ou m3.xlarge com a opção EBS-Optimized habilitada. Cada uma provê um link de 500 Mbps para o EBS. Nós sugerimos usar quatro volumes para o mdadm RAID 10 e criar volumes LVM com o volume mdadm par seu arquivo /data/db, journal e arquivos de logs.
Escala Grande – Mude para um dos tipos de instâncias com grande largura de banda e EBS-Optimized (m1.xlarge, m2.4xlarge, m3.3xlarge possuem links de 1000Mbps para o EBS), e aumente o tamanho do RAID 10 para um grupo de oito volumes. Nesse nível de performance, você notará que ficará com o rendimento um pouco limitado para o Amazon EBS pela rede do Amazon EC2 durante sequâncias atípicas de cargas de trabalho.
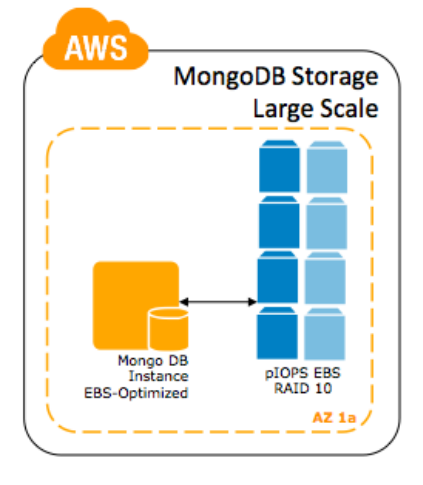
Escala Extra Grande – Em sistemas de densidades muito grandes, você provavelmente irá otimizar coisas específicas da sua carga de trabalho. Fazendo isso, você poderá ter vantagens das diversas opções de instâncias Amazon EC2 que possuem alguns acordos. Aqui estão três diferentes abordagens:
- CC2.8xlarge – Para cargas de trabalho nas regiões us-east-1, us-west-2 e eu-west-1, nós podemos prover instância com uma quantidade ligeiramente menor de memória que nossa instância m2.4xlarge, mas com muito mais largura de banda na conexão com volumes Amazon EBS e muito mais largura de banda nó-para-nó para replicação. Assumindo uma otimização em torno de típicos 4 KB de carga de trabalho, essas instâncias podem explorar 24 ou mais volumes Provisioned IOPS por peça, batendo de frente com a performance da nossa instância hi1.4xlarge com maior redundância.
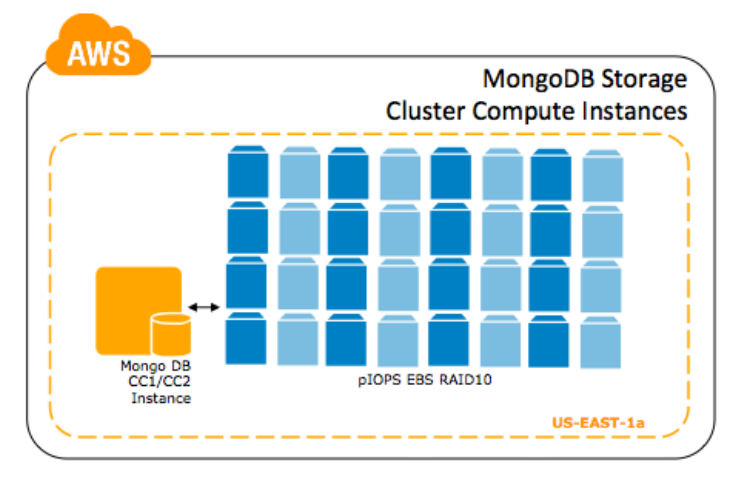
- Hi1.4xlarge – Para cargas de trabalho com uma grande tendência para leituras e conjuntos de dados muito grandes, instâncias com alto I/O podem entregar mais de 120.000 4 KB de IOPS de escrita aleatórios e entre 10.000 e 85.000 4 KB de IOPS de leitura aleatórias (dependendo do bloco lógico ativo no espaço de endereçamento) para aplicações sobre dois volumes de dados locais de 1 TB. Esses volumes podem ser configurados em ambos RAID1 (reduzindo a saída de leitura em 50%) ou RAID 0. Tenha muito cuidado quando usar instâncias hi1.4xlarge como armazenamento primário de dados; como todo disco efêmero, comandos de parada ou falhas na instância podem causar perdas irreversíveis de dados. Snapshots não estão disponíveis em discos efêmeros, então nós recomendamos operar o hi1.4xlarge em replicas e adicionar outra replica que usa volumes EBS (em uma instância CC2), com replicação para simplificar os backups para o Amazon S3 com snapshots.
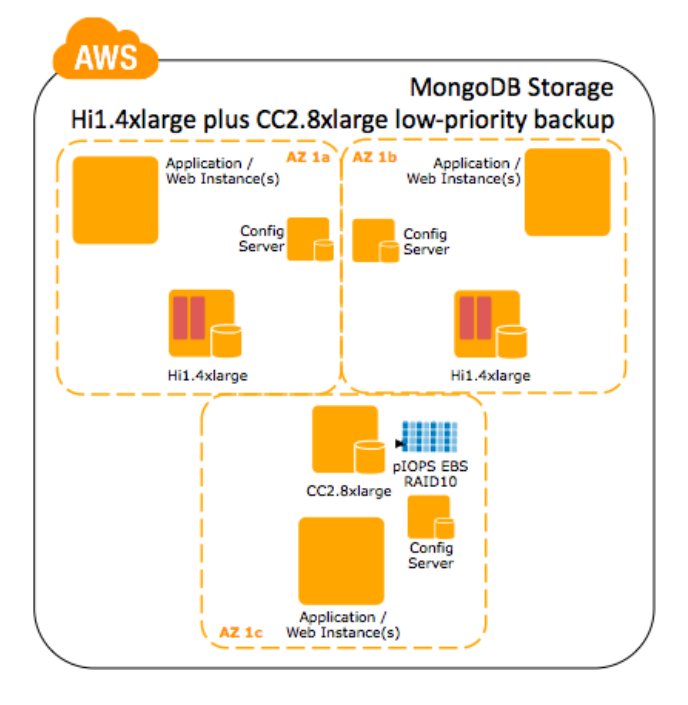
- CR1. 8xlarge – Uma instância CR1.8xlarge provê um máximo de memória corrente de 244GB de memória utilizável, o que oferece uma vantagem muito significante para o MongoDB, pois possui uma quantidade muito maior de memória do que o disponível em outros tipos. Essas instâncias também possuem um par de discos locais de 120 GB SSDs que operam a uma performance mais baixa do que a instância Hi1.4xlarge acima. Se o seu conjunto de dados é maior que 60 GB mas menor do que 240 GB, usar volumes efêmeros locais pode prover uma performance acima de um volume EBS Provisioned IOPS. Se o seu conjunto de dados passa de 240 GB por nó, usar volumes Provisioned IOPS seguidos do padrão cc2.8xlarge é altamente recomendado.
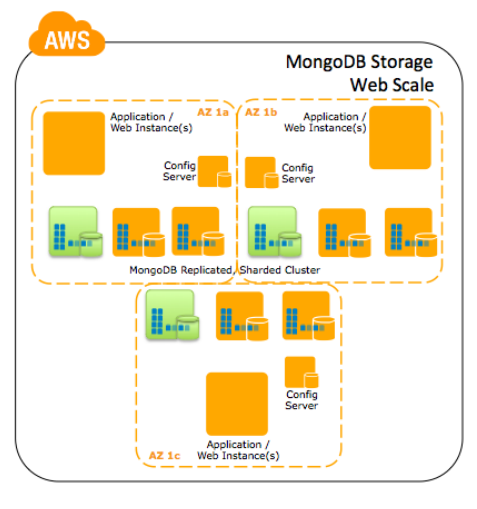
Escala Web – Compartilhe a sua instalação MongoDB através de várias instâncias EC2. Performance de leitura em escala suportada pelo MongoDB pode ser fortemente limitada se o conjunto de dados trabalhado não estiver na memória, então tenha certeza de que você tem largura de compartilhamento suficiente para prevenir excessos de page faults. Mudar a configuração da instância para as opções Extra Grande acima é o que melhor se encaixa nesse caso, e criar instâncias suficientes para atender às suas necessidades.
Criando uma Replica Set
Configurar uma replicação assíncrona no MongoDB é um processo de três passos:
- Provisionar os requisitos de instâncias e armazenamento.
- Instalar e iniciar o processo mongod.
- Oficialmente iniciar o conjunto.
Para criar uma replica set
1. Inicie três instâncias EC2 idênticas, cada uma com disco suficiente para um escalonamento médio, como discutido acima.
$ ec2-run-instances ami-1b814f72 -b /dev/sdf=:80::io1:500 -b /dev/sdg=:80::io1:500 -b /dev/sdh=:80::io1:500 -b /dev/sdi=:80::io1:500 -g smongo -m -t m1.xlarge –ebs-optimized true -z us-east-1a $ ec2-run-instances ami-1b814f72 -b /dev/sdf=:80:io1:500 -b /dev/sdg=:80::io1:500 -b /dev/sdh=:80::io1:500 -b /dev/sdi=:80::io1:500 -g smongo -m -t m1.xlarge –ebs-optimized true -z us-east-1b $ ec2-run-instances ami-1b814f72 -b /dev/sdf=:80::io1:500 -b /dev/sdg=:80:io1::500 -b /dev/sdh=:80::io1:500 -b /dev/sdi=:80::io1:500 -g smongo -m -t m1.xlarge –ebs-optimized true -z us-east-1c
2. Siga as instruções básicas de instalação discutidas anteriormente, com a seguinte alteração no passo 13, inicie o mongod:
$ mongod –replSet thenameofyourreplicaset –port 27017 –dbpath /data/db
3. Quando você rodar o comando mongod, o nó deve lançar uma mensagem de erro dizendo que a replica set não está funcionando e rodando ainda. Você pode usar o DNS para trocar hosts individuais de replica set, então crie três entradas de DNS no Amazon Route 53 ou no sistema de DNS de sua escolha. Como alternativa, você pode hospedar as instâncias MongoDB dentro da Amazon Virtual Private Cloud (Amazon VPC), onde você tem controle sobre IPs estáticos das instâncias.
4. Inicie o mongo shell em qualquer um dos hosts da replica, crie a configuração para a replica set, e então inicie a replicação.
$ Mongo
$ > config = {_id: ‘foo’, members: [
{_id: 0, host: ‘replicaset1.mongohosts.mysite.com:27017′},
{_id: 1, host: ‘replicaset2.mongohosts.mysite.com:27017′},
{_id: 2, host: ‘replicaset3.mongohosts.mysite.com:27017′}]}
$ > rs.initiate(config);
Você pode passar, se necessário, a opção priority:value para cada nó. Essa opção controla a prioridade de cada nós quando acontecer uma eleição em caso de falha do master. Configurar o priority:value é útil para designar nós que são para backup ou para regiões distantes. Nesse caminho, se um de dois nós na região principal falha, o outro nó nessa região (não o nó distante para recuperação de desastres) será eleito o nó primário.
Criando um Cluster MongoDB compartilhado e replicado
Para suportar alta disponibilidade da arquitetura e performance de leitura e escrita escaláveis, sistemas distribuídos devem ser construídos no topo dos sistemas de replicação.
Para criar um cluster MongoDB distribuído
1. Inicie hosts adicionais para o mongod, configurando a opção –shardsvr pra habilitar a distribuição, e passe um nome _id para identificar cada replica set. Habilitar a distribuição muda a porta padrão para 27018. Por exemplo, você pode ter três shards com três replicas (uma primária e duas secundárias) cada, em um total de nove instâncias EC2.
2. Confirme que você iniciou o processo configserver setando a opção –configsrv para habilitar o processo configserver. Habilitar o processo configserver irá mudar a porta padrão para 27019. Esses servidores de configuração podem ser distribuídos pelos servidores mongod aleatoriamente, ou eles podem rodar em uma instância separada (m1.small ou maior, dependendo do tamanho do seu cluster). Servidores de configuração devem ser espalhados através das Availability Zones para ter certeza de que eles não falharam todos juntos. Se você estiver rodando o MongoDB através de múltiplas regiões, você deve distribuir servidores de configuração por essas regiões.
3. Instale os roteadores mongos em cada host de aplicação, inciando-os com a opção –configdb, passando os nomes de DNS e as portas de todas as três instâncias config server.
4. Habilitar a distribuição no banco de dados para habilitar o comando shardcollection no seguinte passo:
> db.runCommand( { enablesharding : “<dbname>” } );
5. Distribua as collections relevantes. A chave é o objeto na coleção que será indexado e usado para distribuir pedaços dos itens através do seu cluster. Uma vez que uma collection é distribuída, ela não pode ser reagrupada novamente sem um ciclo de backup/restore, então tenha cuidado quando você selecionar uma chave de distribuição.
> db.runCommand(
{ shardcollection : “<namespace>”,key : <shardkeypatternobject> });
Operações
Backup
Para rodar o MongoDB no Amazon EC2, nós recomendamos fortemente que você use a versão 2.0.7 ou superior e habilite a função –journal. Nós também recomendamos que coloque o journal em um volume Amazon EBS Provisioned IOPS. O mecanismo de backup atual é muito simplificado pelo Amazon S3, capacidade de snapshot nativa para o Amazon EBS.
Para rodar um backup
1. Libere e bloqueie o mongod usando os comandos fsync e lock.
> db.runCommand({fsync:1,lock:1}); { “info” : “now locked”, “ok” : 1 }
2. Crie um snapshot para cada volume Amazon EBS que você para guardar dados, journals, ou oplogs do mongod, usando o número de volumes na sua instância específica. Você pode encontrar esses números no Console de Administração AWS ou usando o comando ec2-describe-instances.
$ ec2-create-snapshot -d thedescriptionofyourbackup vol-11111111
3. Depois do comando ec2-creat-snapshot retornar o estado Pending para o snapshot, é seguro retornar as operações do mongod. Destrave o banco de dados e reinicie o processo.
> db.$cmd.sys.unlock.findOne(); { “ok” : 1, “info” : “unlock requested” }
Nota: Enquanto durar o snapshot (antes de ele ser listado como “Completed”), haverá um impacto negativo variável na performance de disco do Amazon EBS. Se você estiver operando próximo da capacidade, você deve rodar os snapshots do seus sistema em uma replica temporizada.
Restore
Para restaurar de um backup
1. Crie um volume Amazon EBS de cada um dos snapshots que você fez backup dos seus dados. Esse passo pode precisar de mais de um volume. Você pode achar o ID do snapshot e criar os volumes usando o Console de Administração AWS ou o comando ec2-describe-snapshots
$ ec2-create-volume –availability-zone us-east-1a –snapshot snap-12345678
2. Anexe os volumes à instância. Lembre-se: se você estiver restaurando um conjunto RAID, deve substituir os volumes na mesma ordem para facilitar a recriação do volume RAID no sistema operacional.
$ ec2-attach-volume –instance i-aaaaaaa –device /dev/sdp vol-01010101
3. Faça um diretório que você possa montar o sistema de arquivos.
$ sudo mkdir -p /data/db/ $ sudo chown `id -u` /data/db
4. Monte o volume
$ sudo mount /dev/sdp /data/db
5. Inicie o mongod e então verifique a restauração das suas collections do MongoDB
$ service start mongod
> db.thenameofyourcollection.validate({full:true})
Monitorando
O serviço Amazon CloudWatch provê um monitoramento robusto de instâncias Amazon EC2, volumes Amazon EBS e outros serviços. O Amazon CloudWatch pode enviar um alarme por SMS ou e-mail quando limites definidos pelo usuários são ultrapassados no AWS. Por exemplo, você pode definir um alarme para alertar sobre transferências excessivas de armazenamento. Como alternativa, você pode escrever uma métrica customizada para o Amazon CloudWatch, por exemplo, memória livre corrente na sua instância, e pode definir um alarme ou um disparo automático em resposta quando esse limite estipulado por você for ultrapassado.
A 10gen, companhia por trás do MongoDB, lançou o MongoDB Monitoring Service (MMS, um produto gratuito, baseado na nuvem, para monitorar e gerenciar instalações MongoDB. Para mais detalhes sobre o serviço vá até: https://www.mongodb.com/products/mongodb-management-service).
Segurança
Rede
Para ter acesso aos recursos do MongoDB de outras instâncias Amazon EC2 ou de servidores remotos, você precisa configurar seus grupos de segurança para permitir o acesso através das portas TCP apropriadas. Como qualquer outro serviço de rede, essas portas devem ser abertas com cuidado; por exemplo, abrir apenas para o seu escritório ou para para outras máquinas autenticadas e autorizadas que precisem desse acesso.
Os números das portas padrão dos processos MongoDB são:
Um processo único mongod: 27017
mongos: 27017
servidor distribuído. (mongod –shardsrv): 27018
servidor de configuração (mongod –configsrv): 27019
Página de estatísticas para o mongod: adicione 1000 ao número da porta (28017, por padrão)
A maioria das páginas de estatísticas na interface HTTP não estão disponíveis a menos que a opção –rest seja especificada. Para desabilitar a página de estatísticas, use –nohttpinterface. (Se você usar a porta 28017, você deve protegê-la. Em todo caso, as informações na página de estatísticas são apenas leitura.)
Portas podem ser abertas para todos os computadores no mesmo grupo de segurança Amazon EC2, para outro grupo de segurança, para um endereço especifico de IP ou para uma faixa de endereços CIDR IP. Parâmetros dos grupos de segurança podem ser modificados a qualquer momento. Para uma segurança extra, alguns usuários usam scripts automatizados para abrir essas portas quando necessário e fechar logo depois quando os recursos do MongoDB não estão em uso.
A boa prática em uma arquitetura multicamadas é permitir acesso operacional para a camada do mongod apenas de servidores que estão no grupo de segurança e que precisam desae acesso e liberar acesso de controle apenas de IPs administrativos conhecidos.
Autenticação
Para habilitar a autenticação, rode o processo mongod com a opção –auth. Você precisa adicionar um usuário na collection admin antes de iniciar o servidor, ou então adicione o primeiro usuário pela interface localhost
> use admin > db.addUser(“theadmin”, “anadminpassword”)
Para autenticar em uma instalação mongod replicada ou distribuída
1. Crie um arquivo chave (Base64, 6 ou mais caracteres, nunca maior que 1 KB) que pode ser copiado para cada servidor dentro do conjunto.
2. Modifique as permissões para que seja somente leitura para o usuário apropriado.
3. Inicie cada servidor no cluster, incluindo todos os membros da replica set, todos os confiservers, e todos os processos mongos, com a opção –keyFile /path/to/file.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?