

Nós sempre queremos que os produtos e serviços do Facebook funcionem bem para quem os utiliza, não importa onde eles estão no mundo. Isso nos motiva a ser proativos na detecção e resolução de problemas em nossa infraestrutura de produção, para que possamos evitar falhas que poderiam retardar ou interromper o serviço para as milhões de pessoas que usam o Facebook em um determinado momento.
Em 2011, nós introduzimos o serviço Facebook Auto Remediation (FBAR), um conjunto de programas que rodam no background que executam o código automaticamente em resposta a falhas de software e de hardware detectados em servidores individuais. Todos os dias, sem intervenção humana, o FBAR tira esses servidores da produção e envia pedidos para nossas equipes de data centers para executar reparos de hardware físico, tornando falhas isoladas uma nonissue.
Como a nossa infraestrutura continua a crescer, também temos de ser proativos na detecção e resolução de problemas ao nível do rack ou para outros domínios de falhas, tais como interruptores de rede ou unidades de energia de backup. Dado que vários serviços podem ser colocados em um único rack, realizar esse tipo de manutenção em uma base diária iria interromper dezenas de equipes, algumas várias vezes, ao longo do ano.
Para ajudar a minimizar a interrupção, construímos uma melhoria em cima do FBAR chamada de Aggregate Maintenance Handlers, que fornece uma maneira de automatizar com segurança a manutenção em vários servidores ao mesmo tempo. Para os casos em que a automação não é suficiente, também desenvolvemos o Dapper, uma ferramenta que permite a intervenção manual para garantir que a manutenção programada possa prosseguir com segurança. O resto deste artigo irá explorar como os Aggregate Maintenance Handlers trabalham em vários cenários de interrupção, incluindo o que acontece quando a automação falha, e como o Dapper é usado para coordenar processos automatizados e manuais.
Automatizando com Aggregate Maintenance Handlers
Enquanto FBAR inclui métodos para desativar e reativar um único host de cada vez, a execução desses métodos em série ou em paralelo não era uma abordagem bastante segura para o propósito de trabalhar em vários hosts de uma só vez. A abordagem serial pode ser demorada, ou arriscar que um serviço seja executado fora da capacidade de um servidor de cada vez. A abordagem paralela estava propensa a competições e poderia executar um serviço sem capacidade ainda mais rápido.
Aggregate Maintenance Handlers oferecem um framework para desativar e ativar servidores em massa automaticamente, proporcionando aos nossos engenheiros um contexto completo sobre o trabalho de manutenção executado e toda a gama de servidores afetados.
Tomando decisões com base no impacto da manutenção
Interrupções variam em tamanho, comprimento e tipo: algumas podem afetar um único rack, algumas podem afetar diversos; elas podem ser longas ou curtas; algumas podem afetar somente a conectividade de rede, enquanto outras podem interromper os fornecimentos de energia. Diferentes serviços lidam com diferentes interrupções de diferentes distintas. Quando agendamos trabalhos de manutenção, damos aos Aggregate Maintenance Handlers quatro pedaços de informação para determinar o impacto que isso terá sobre nossa infraestrutura geral:
- Escopo (uma lista completa de servidores afetados pela manutenção)
- Tipo de manutenção (interrupção de rede, interrupção de energia)
- Hora de início da manutenção (por exemplo, 10h horário padrão do pacífico)
- Duração de manutenção (por exemplo, duas horas)
Nossos engenheiros podem então usar essa descrição de impacto para tomar decisões sobre automação e otimizar a forma como a interrupção deve ser tratada. Vejamos três exemplos simplificados:
- Um servidor web sem estado pode lidar com uma interrupção de rede ou de energia de qualquer comprimento sendo removido de um conjunto de balanceador de carga. A única preocupação nesse caso seria garantir que existem servidores web suficientes ainda disponíveis para lidar com todas as solicitações.
- Uma máquina de cache servindo um índice estático da memória poderia lidar com uma longa interrupção de rede ao ser retirado de um conjunto de balanceador de carga. Uma vez que a rede é restaurada, a máquina poderia retomar imediatamente, servindo o índice. Uma interrupção de energia de curta duração, por outro lado, precisaria recarregar o índice para a memória. Lidar com uma reinicialização exigiria a substituição de forma proativa do servidor por um que não foi afetado pela mesma manutenção.
- Uma réplica MySQL com um fluxo de replicação ocupado poderia lidar com uma interrupção de energia curta. O host seria removido de um conjunto de balanceador de carga, os dados seriam armazenados em disco, e o servidor MySQL rapidamente recuperaria o atraso na replicação após a reinicialização. Por outro lado, interromper a conectividade de rede por horas poderia fazer com que ele ficasse muito para trás, e fazer uma substituição proativa do servidor de réplica é uma opção melhor.
Levar em conta o tamanho e o tipo das interrupções nos permite construir uma matriz simples de tomada de decisão para cada serviço:

Processo de manipulação desativado/ativado
Uma vez que a manutenção adequada foi selecionada e programada, o manipulador segue um fluxo de quatro etapas para desativar os hosts afetados:
- Verificação de comprovação
- Pré-desativação
- Desativação em nível de host
- Pós-desativação
Verificação de comprovação: A verificação de comprovação é chamada no início do processo de desativação e verifica se haveria capacidade suficiente disponível nos servidores não afetados pela manutenção que deve ser realizada com segurança. Ela retorna uma resposta verdadeira ou falsa que tanto permite que o trabalho de manutenção avance ou pare, respectivamente. A verificação de comprovação também pode ser chamada de forma independente como parte de um processo de agendamento, dando às equipes mais tempo para lidar com cenários em que a verificação de comprovação poderá retornar false.
Vamos imaginar a seguinte linha de seis racks em um centro de dados com as seguintes restrições:

Agora vamos imaginar dois cenários de manutenção:
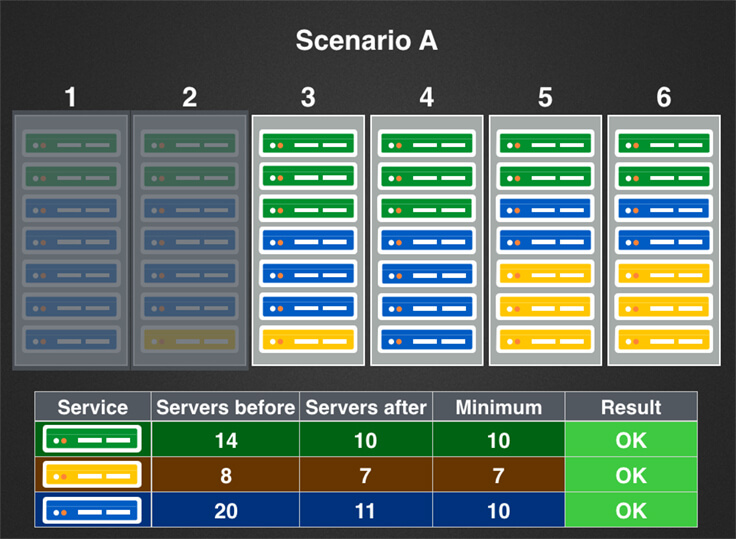

Verificações de comprovação para os servidores web iriam passar em ambos os cenários, mas, no cenário B, elas seriam um fracasso para os servidores de cache e de banco de dados, e a manutenção automática não poderia prosseguir (esse cenário é abordado em mais detalhes na próxima seção).
Quando todas as verificações de comprovação passarem, nossos Aggregate Maintenance Handlers permitirão embrulhar uma camada mais inteligente de código em torno da lógica pré-existente no nível do host desativar/ativar.
Pré-desativação: Essa etapa é geralmente usada para garantir que os hosts atualmente considerados como peças em nossos pools não são acidentalmente reintroduzidos na produção, quando vários hosts são trocados durante o nível de desativação do host ou operações em massa.
Desativação em nível de host: Em alguns casos, isso é um não-op porque hosts foram bulk-desativados em fase de pré-desativação. Em todos os outros casos, torna-se uma execução paralela de desativação em nível do host, lógica herdada do FBAR.
Pós-desativação: Esse passo é usado principalmente para verificar que a pré-desativação no nível de host foi bem sucedida. Ele também permite que o autor inspecione os resultados da etapa de desativação no nível do host e decida quando ignorar certos tipos de falhas se eles permanecerem abaixo de um limiar desejado.
Esse fluxo está representado na animação seguinte:

O processo de ativação é idêntico ao processo de desativação: pré-ativação, ativação em nível de host, e pós-ativação. Com a automação, podemos realizar com segurança a manutenção regular no nível do rack ou multi-rack, minimizando a interrupção para outras equipes de engenharia e os serviços que as pessoas usam no Facebook.
Coordenação com os seres humanos: quando a automação não é possível (ou falha)
Embora o nosso objetivo é o de sermos capazes de automatizar todo o trabalho de manutenção que deve acontecer na nossa infraestrutura, há momentos em que é necessária uma intervenção manual para assegurar que a manutenção aconteça de forma segura.
Verificações de comprovação de falha ou nenhuma automação
Em alguns casos, é possível que o trabalho programado afete conjuntos suficientemente grandes de servidores que as verificações de comprovação se recusam a permitir que a manutenção automática prossiga. Nossa automação é intencionalmente conservadora e prefere a intervenção manual nas operações de maior escala, possivelmente arriscadas. Em outros casos, a automação ainda não foi implementada ou foi desativada temporariamente, seja por razões de confiabilidade ou porque um serviço está em um estado degradado, e nós preferimos evitar que mudanças automatizadas aconteçam.
Falha na automação
Mesmo que nós tenhamos uma elevada taxa de sucesso quando invocamos nossos Aggregate Maintenance Handlers, ainda há ocasiões em que as coisas dão errado. Quando uma falha ocorre, o nosso processo de manutenção notifica o proprietário do serviço que a automação falhou. Uma vez que eles confirmaram manualmente que os hosts foram devidamente desativados, a manutenção é autorizada a continuar.
Misturando automação e trabalho manual
Para ajudar a coordenar os processos automatizados e manuais, nós desenvolvemos o Dapper, uma ferramenta que pode ser usada por uma variedade de equipes (por exemplo, as equipes de data center, gerentes de programas técnicos, engenheiros de infraestrutura, engenheiros de produção) para agendar o trabalho de manutenção, fornecendo a descrição do impacto mencionada acima (hosts afetados, tipo de manutenção, hora de início e duração).
O fluxo de trabalho para a manutenção executado pelo Dapper é o que segue:

Lições aprendidas
Aprendemos algumas lições no início, quando estávamos escalando desde reparos automatizados de um único host até trabalhos de manutenção em nível de rack e multi-rack.
Uso serial de lógica de desativação
Desativar hosts um de cada vez tinha dois possíveis efeitos colaterais negativos. O primeiro era ficar sem capacidade em algum momento durante a manutenção, resultando no bloqueio do trabalho de manutenção até que um ser humano interviesse:

Pior ainda, quando a lógica de swap para um serviço comum reutilizar hosts no mesmo rack, podemos acidentalmente reintroduzir hosts novamente em produção ou, na melhor das hipóteses, ser executado em um loop infinito:

Uso de lógica de desativação em paralelo
Trocar hosts em paralelo em vez de um de cada vez poderia evitar alguns dos problemas observados na abordagem serializada, mas introduz outros problemas. O problema mais comum era que a invocação da lógica de host único em paralelo poderia causar uma condição de corrida onde as operações individuais iriam encontrar uma substituição de host, mas o resultado agregado faria o serviço a perder a capacidade:

Expandindo a automação
O framework fornecido pelo Dapper e os Aggregate Maintenance Handlers cresceram para além de trabalhos de manutenção físico, expandindo para incluir a desativação e a ativação de hosts como parte dos releases de software, ou do kernel, BIOS e atualizações do sistema operacional.
Os engenheiros de produção que trabalham com o Dapper são apaixonados pela ideia de expandir ainda mais o alcance das ferramentas de automação e construção que permitem que as equipes de engenharia do Facebook diminuam a carga de trabalho das operações, liberando-os para enfrentar problemas maiores, mais desafiadores.
Para saber mais sobre FBAR e manipuladores de agregação de manutenção, assista a esta apresentação.
***
Romain Komorn é o autor deste artigo. A tradução foi feita pela Redação iMasters, e você pode ver o original aqui: https://code.facebook.com/posts/629906427171799/making-facebook-self-healing-automating-proactive-rack-maintenance/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?