

Configurando e entendendo o AlertManager
No primeiro artigo, explorei um pouco do projeto opensource dockprom. Como ele é possível monitorar a sua aplicação em tempo real utilizando tecnologias como Prometheus e Grafana; também é possível enviar alertar caso alguma coisa saia do controle.
Na Kinghost começamos a utilizá-lo para monitorar sistema que já estão rodando em containers (Docker). Já falei um pouco sobre a configuração e monitorias; pois bem, agora gostaria de me aprofundar um pouco mais na parte de Alertas. Um tema super importante, afinal de contas, não adianta monitorar a aplicação se ela não me avisar quando algo estiver errado.
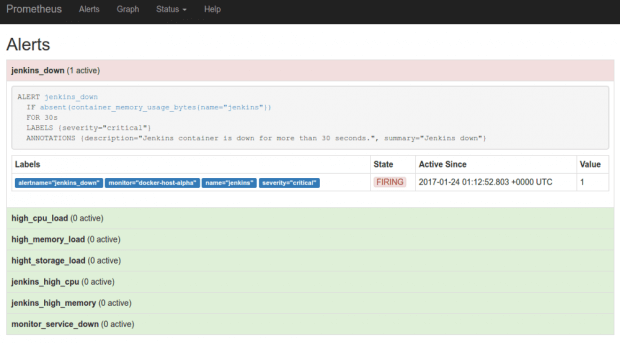
Arquivos de configuração
Nesse repositório do GitHub, os arquivos que você deve alterar estão na pasta Prometheus. Abaixo, um trecho do arquivo prometheus.yml.
[...]
global:
scrape_interval: 15s
evaluation_interval: 15s
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'docker-host-alpha'
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- "targets.rules"
- "host.rules"
- "containers.rules"
[...]
Importante reparar as três últimas linhas citadas, pois é ali que estamos fazendo referência aos demais arquivos para melhor organização das regras.
Todos os targets configurados nos scrappers terão uma métrica chamada “up”, que será populada automaticamente. Sendo assim, podemos criar nosso primeiro alerta:
Abaixo o arquivo targets.rules.
ALERT monitor_service_down
IF up == 0
FOR 30s
LABELS { severity = "critical" }
ANNOTATIONS {
summary = "Monitor service non-operational",
description = "Service {{ $labels.instance }} is down.",
}
Esse arquivo indica que: se a condição for verdadeira durante 30 segundos, devo disparar o alerta.
Isso pode ser feito para qualquer condição, inclusive em qualquer consulta, as mesmas que você possui no Grafana para visualizar os dados da aplicação.
Exemplo (mais elaborado):
ALERT hight_storage_load
IF (node_filesystem_size{fstype="aufs"} - node_filesystem_free{fstype="aufs"}) / node_filesystem_size{fstype="aufs"} * 100 > 85
FOR 30s
LABELS { severity = "warning" }
ANNOTATIONS {
summary = "Server storage is almost full",
description = "Docker host storage usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}.",
}
A condição acima verifica se a porcentagem de disco utilizado ultrapassa os 85%, então, envia um alerta. Como podemos ver, as possibilidades são infinitas.
Envio de mensagens
Os arquivos configuração dos alertas são propriedade do Prometheus, porém a saída é configurada no AlertManager. Você encontrará o seguinte arquivo em alertmanager/config.yml:
route:
receiver: 'slack'
receivers:
- name: 'slack'
slack_configs:
- send_resolved: true
text: "{{ .CommonAnnotations.description }}"
username: 'Prometheus'
channel: '#<channel-name>'
api_url: 'https://hooks.slack.com/services/<webhook-id>'
O arquivo acima diz que todas os alertas serão enviados via Slack para o grupo responsável. Mas podemos adicionar várias funcionalidades legais, por exemplo:
route:
#receiver padrão
receiver: 'email'
#rotas filhas
routes:
- match:
severity: critical
receiver: 'slack'
receivers:
- name: 'slack'
slack_configs:
- send_resolved: true
text: "{{ .CommonAnnotations.description }}"
username: 'Prometheus'
channel: '#<channel-name>'
api_url: 'https://hooks.slack.com/services/<webhook-id>'
receivers:
- name: 'email'
email_configs:
- to: 'devs@example.org'
Agora sim! Todos os alertas serão encaminhados por e-mail, e se acontecer algo crítico, pode ser enviado para a equipe imediatamente via Slack!
Importante!
Para melhor utilização dos alertas: encontramos uma dificuldade em relação a periodicidade das verificações, mas adicionando essa linha no alertmanager, a velocidade dos alertas ficou excelente, exatamente como nosso time precisava:
group_interval: 10s
Desse modo todos os alertas serão enviados a cada 10 segundos (o padrão é de 5 minutos).
Alertas pelo Grafana
A partir do Grafana 4.0, temos a possibilidade de alertas direto na ferramenta, sendo possível controlar os alertas da aplicação através da interface gráfica. Mas atenção: todos os alertas e configurações de envio não são as mesmas! São configurações exclusivas do Grafana.
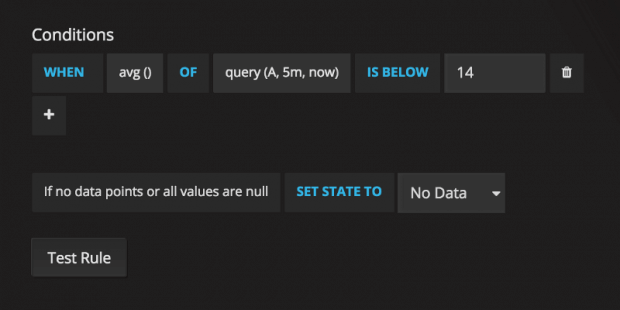
Abaixo uma amostra da configuração na interface do Grafana.
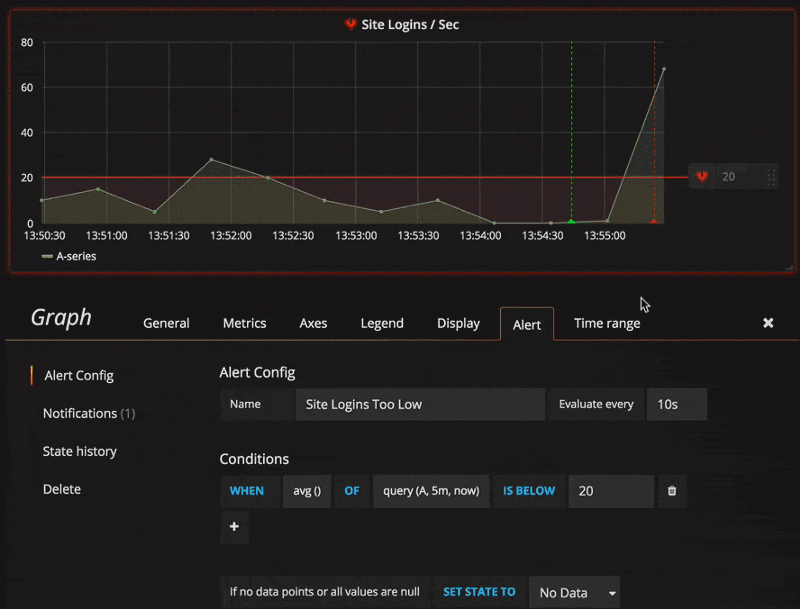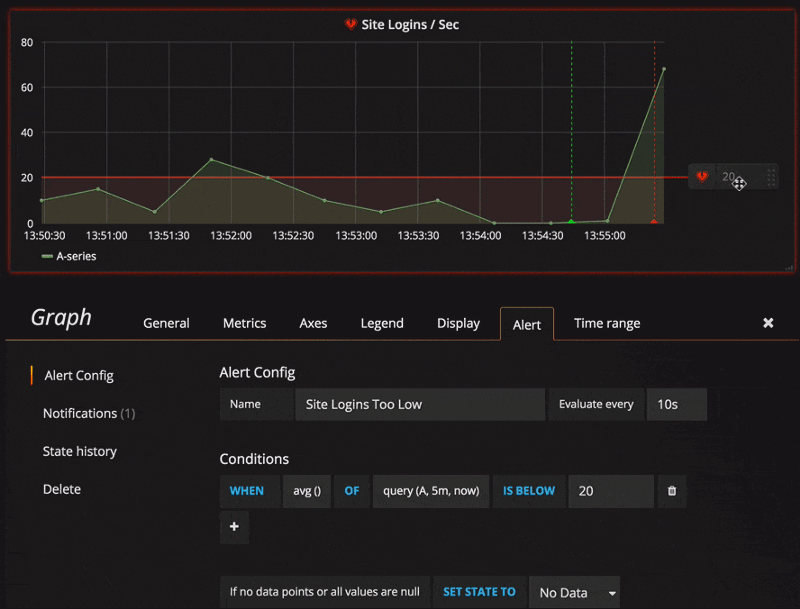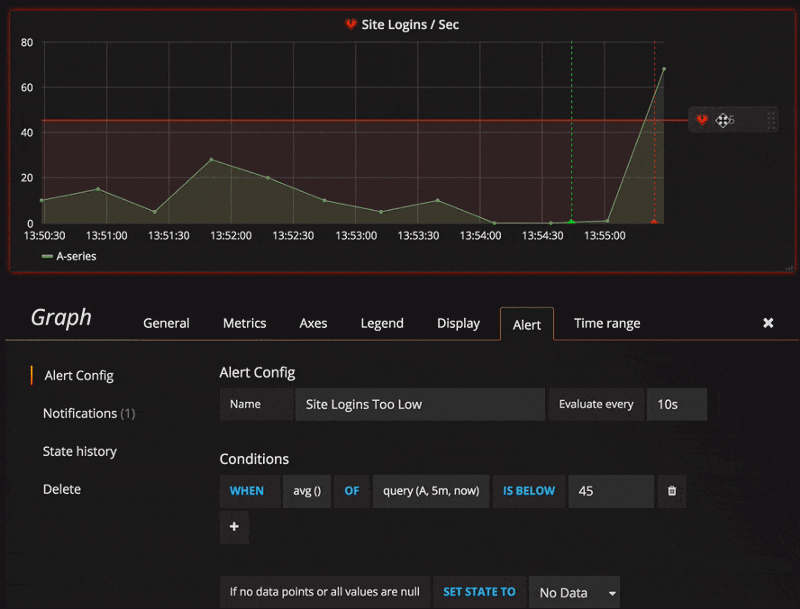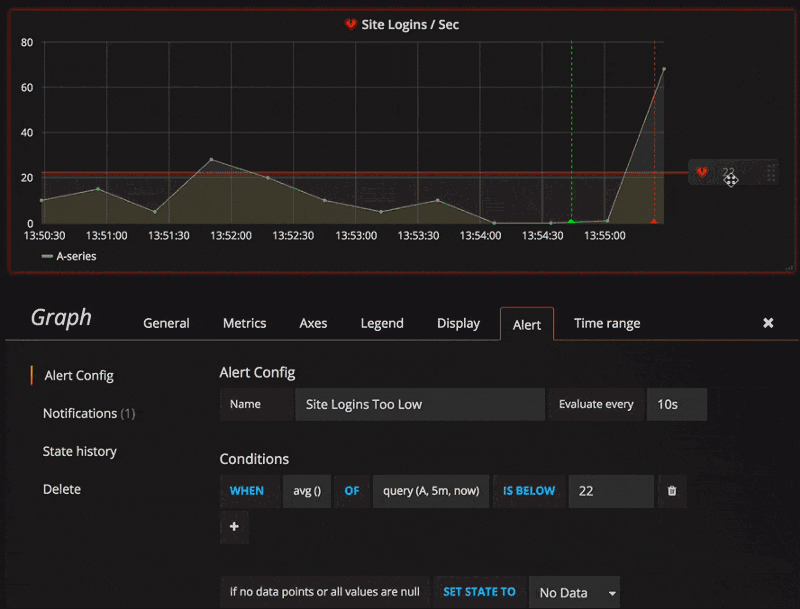
Para maiores informações sobre a versão 4.x do Grafana, basta acessar o link.
Conclusão
A configuração de alertas é um pouco confusa, pois é necessário configurar diversos arquivos para que todos os critérios sejam atendidos, mas em uma tarde dá pra entender legal a ferramenta. A adoção dessa solução foi tão boa entre as equipes de desenvolvimento da Kinghost que cada grupo já está fazendo suas próprias contribuições.
Espero que assim, como foi pra nós, que você também possa se surpreender e melhorar cada vez mais o seu processo de desenvolvimento. Muito obrigado e caso tenha testado ou tenha alguma opinião sobre o assunto, pode comentar abaixo!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?