

Os serviços cognitivos da Microsoft têm evoluído muito desde seu início. Como é sabido, ele começou no Microsoft Research com o famoso Project Oxford, que já disponibilizava uma série de APIs para se trabalhar especialmente com Visão Computacional e Processamento de Linguagem Natural.
Focando na Visão Computacional, quando a Microsoft lançou o Cognitive Services, as APIs de serviços cognitivos já disponibilizavam uma grande capacidade e variedade, te possibilitando trabalhar de uma simples análise de imagens a detecção de faces com análise de sentimentos. Algumas combinações de serviços nos proporcionam inúmeras possibilidades de uso, como por exemplo, uma análise de sentimento em texto que dava a possibilidade do usuário enviar uma imagem que era interpretada via OCR, e tinha sua análise de sentimento exatamente igual ao texto digitado.
Contudo, não era possível trabalhar de forma específica. Imagine que você precisa identificar um determinado elemento. Você tem diversas possibilidades, porém não era possível realizar um treino para a obtenção de um resultado definido – até agora!
No Build deste ano (2017), a Microsoft lançou o Serviço de Visão Customizada. Este novo serviço possibilita que você trabalhe com seu próprio dataset de treino a fim de aprender e identificar estes mesmos padrões em outras imagens.
Seu funcionamento é extremamente simples: basta enviar seu dataset de treino, definir um label para o mesmo, mandar treinar e verificar a acurácia do modelo. O próximo passo e gerar sua API de acesso para consumir seu modelo personalizado.
Under the Hood
Existe uma série de conceitos por debaixo dos panos. Não vou entrar em questões mais específicas sobre visão computacional ou esse aprendizado, nem tão pouco dicutir os algorítmos em si. Entretanto alguma base é necessária para se utilizar o Custom Vision.
Da forma mais básica e genérica possível, podemos pensar neste aprendizado e treino como o input de dados e extração de características para uma posterior classificação/reconhecimento de imagens.
Ok, como é possível usar o Cognitive Services que já está treinado para atividades específicas, e usá-lo para reconhecer um padrão meu?
Olhando mais a fundo, estamos falando aqui do conceito de Transfer Learning, já que na realidade, temos os algorítimos de Deep Learning e modelos pré-treinados que são ensinados a procurar detalhes a recurso distintos em um novo dataset que é informado posteriormente.
Transferência de aprendizagem é um campo de pesquisa na aprendizagem de máquinas que se concentra no armazenamento de conhecimento adquirido ao resolver um problema, e o usa para resolver um problema diferente, mas relacionados.
Sendo assim, Transfer Learning se trata da capacidade de usar modelos pré-treinados para solucionar problemas relacionados com um treinamento reduzido.
Em nosso caso, o serviço de visão computacional do Azure já possui em amplo treinamento em diversos domínios, o que nos da a possibilidade de transferir essa aprendizagem a um domínio menor… E assim temos nosso Custom Vision API.
Para conseguirmos um resultado satisfatório, nosso objetivo deve ser o reconhecimento de padrões de algo específico. O melhor cenário aqui é trabalhar na detecção de algo único, com um bom dataset das diversas posições, perspectiva, iluminação etc.
Show me the code – First Try
Uma vez que já temos uma base, vamos aos passos necessários para realizar nosso primeiro treino com o Microsoft Congnitive Service Vision Custom e discutir um pouco sobre sua aplicação prática.
Criando um novo projeto
Primeiro, você vai precisar acessar o site específico do Custom Vision em customvision.ai. Agora, é só fazer o login com sua conta do Microsoft Azure.
Assim que você estiver logado, vai ver a tela com os seus projetos, e a opção para a criação de um novo projeto. Assim como segue abaixo:
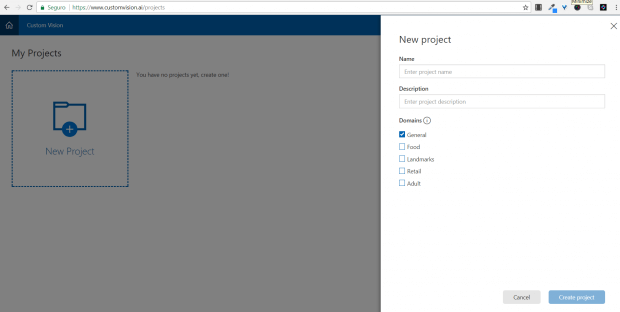
Crie um novo projeto informando o nome do mesmo, uma descrição e selecione a opção General. Você pode treinar um modelo usando um cenário específico, é bastante útil em caso de já utilizarmos uma memória de auxílio. No meu caso, eu usei como nome do projeto vehicles, e como modo de treino a opção General.
Carregando nosso dataset
Com o projeto criado, precisamos treinar nosso modelo. Isso só é possível se tivermos dados. Então, vamos lá: clique no botão upload e envie suas fotos.
Lembre-se da importância de um bom conjunto de dados, com fotos em diversos ângulos, tamanhos, variações de iluminação etc. Quanto mais variado, mais características serão aprendidas.
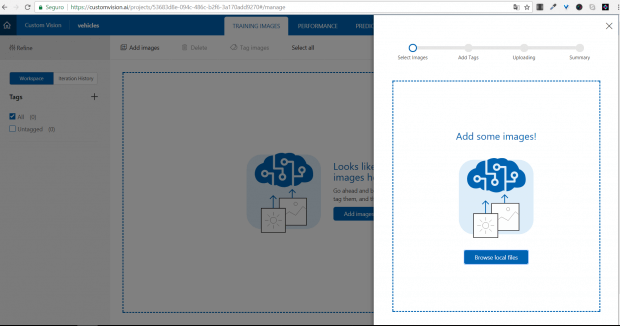
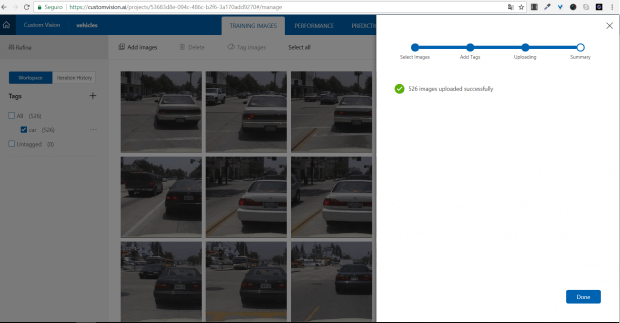
Para este teste, estive procurando uma opção simples de treino. Eu utilizei conjunto de datasets disponibilizado pela Caltech com foco em visão computacional. Estou utilizando neste primeiro momento o dataset CARS de 2001.
Aqui, eu tenho minha primeira surpresa: existe uma limitação na quantidade de arquivos a serem enviados. No total, para cada projeto, podemos enviar apenas 1000 imagens para o treino.
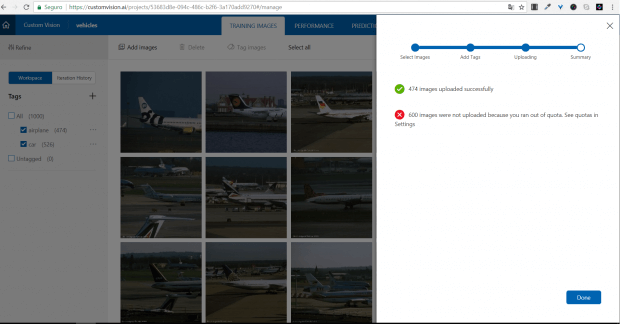
Quem já trabalhou com este tipo de treinamento, provavelmente pode cair na mesma cilada, já que geralmente temos grandes quantidades de imagens para este tipo de treino.
É importante ler todas as limitações e cotas de utilização de um serviço antes de usá-lo. Por exemplo, temos limitação de 1000 imagens, imagens somente até 4MB, somente JPG, PNG e BMP etc.
Sendo assim, resolvi mudar minha estratégia: dividir minhas imagens em grupos de 300, já que estou falando de três tipos de veículos que quero identificar:
- Cars
- Motorbikes
- Airplanes
O que eu fiz foi criar um simples script em Python para selecionar 300 imagens aleatórias do meu dataset, para cada categoria.
import os
import random
import numpy as np
from sklearn.model_selection import train_test_split
dir_src = "{diretório fonte}"
dir_test = "{diretório destino de teste}"
dir_train = "{diretório destino de train}"
# Quantidade de imagens a serem selecionadas no dataset
qtd_images = 300
print('\nDiretório\n')
print('-'*30)
def get_filepaths(directory):
file_paths = []
for root, directories, files in os.walk(directory):
for filename in files:
# Supported image formats: JPEG, PNG, GIF, BMP.
if filename[-4::] == 'jpeg' or filename[-3::] == 'jpg' or filename[-3::] == 'png' or filename[-3::] == 'gif' or filename[-3::] == 'bmp':
file_paths.append(filename)
return file_paths
full_file_paths = get_filepaths(dir_src)
result = random.sample(set(full_file_paths), qtd_images)
print('\nNúmero de arquivos do dataset: ' + str(len(full_file_paths)))
print('\nItens selecionados randomicamente: ' +str(len(result)))
X = y = result
# use 1/4 data for testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
for xt in X_test:
os.rename(dir_src + xt, dir_test + xt)
for yt in X_train:
os.rename(dir_src + yt, dir_train + yt)
print('\nQuantidade de arquivos no conjunto de treino: ' + str(len(X_train)))
print('\nQuantidade de arquivos no conjunto de teste: ' + str(len(X_test)))
Você pode fazer o download deste código direto no meu gist diretamente neste link. O output será como o descrito abaixo:
λ python split.py Diretório ------------------------------ Número de arquivos do dataset: 526 Itens selecionados randomicamente: 300 Quantidade de arquivos no conjunto de treino: 225 Quantidade de arquivos no conjunto de teste: 75
Nosso diretório vai ficar parecido como o descrito na imagem abaixo:
Não esqueça que esse procedimento deve ser realizado para cada uma das categorias de veículos que queremos testar.
Agora, eu posso fazer o upload dessas imagens. Quando cada uma das categorias são carregadas, é necessário informar uma tag, que vai representar aquele recurso, logo ao executarmos um teste, teremos de resposta a porcentagem da mesma ser ou não correspondente ao conjunto representado pela tag.
Um pouquinho mais sobre o reconhecimento de objetos e o tagueamento
O serviço de visão computacional do Cognitive Service hoje, é treinado para o reconhecimento de mais de 2000 objetos, sendo eles seres vivos, cenários ou ações.
Este reconhecimento é classificado e categorizado seguindo a seguinte taxonomia:
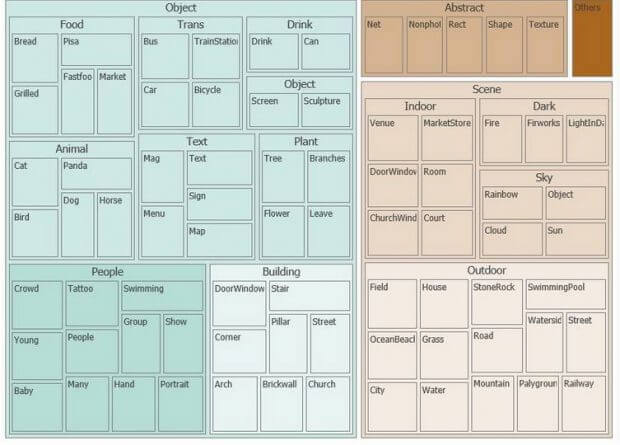
Em nosso caso, estamos criando um modelo simples com apenas quatro classes e que são distintas entre si. Como já vimos anteriormente, temos carros, motos e aviões. Se passarmos um de nossos dados de treino para o serviço de análise de imagem do Cognitive Services teremos como resultado o que se segue abaixo:

"categories": [
{
"name": "others_",
"score": 0.00390625
},
{
"name": "outdoor_road",
"score": 0.296875
},
{
"name": "trans_car",
"score": 0.67578125
}
],
"description": {
"captions": [
{
"confidence": 0.9560722703980943,
"text": "a car parked on the side of a road"
}
],
"tags": [
{
"confidence": 0.9992092251777649,
"name": "outdoor"
},
{
"confidence": 0.9986016154289246,
"name": "car"
},
{
"confidence": 0.9985461235046387,
"name": "sky"
},
{
"confidence": 0.9938879609107971,
"name": "road"
},
{
"confidence": 0.9547197818756104,
"name": "way"
},
{
"confidence": 0.8574815392494202,
"name": "scene"
},
{
"confidence": 0.8200963139533997,
"name": "street"
},
{
"confidence": 0.6744081974029541,
"name": "highway"
},
{
"confidence": 0.37572911381721497,
"name": "stopped"
}
]
Observe que nossa imagem foi categorizada em três locais, onde as duas melhores classificações são relativas a carros. Em relação ao tagueamento, vemos car na segunda posição. A descrição indica a car parked on the side of a road.
Faça o mesmo teste com outras images, incluindo avião e moto. Você vai perceber que o serviço tem uma boa acurácia em relação ao reconhecimento dessas imagens.
Do nosso lado, o tagueamento é importante para representar corretamente as imagens, e ter um retorno claro, já que a ideia final é consumir esse modelo via REST.
Treinando o modelo
Agora, vamos ao passo mais simples, clique no botão Train. No meu caso, o treinamento levou 23.09 segundos.
Com o modelo treinado, você pode ir na página PERFORMANCE, onde encontramos o seguinte gráfico:
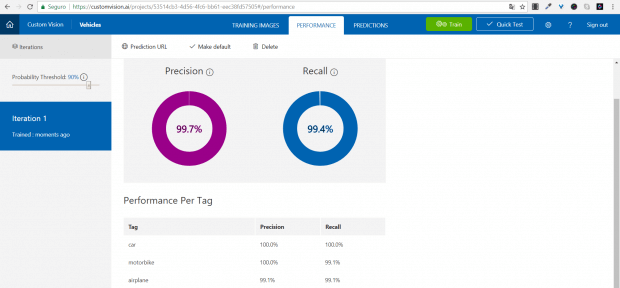
Este gráfico possui duas medidas: Precision e Recall, sendo que Precision representa a probabilidade de seu classificador conseguir identificar corretamente uma imagem. Recall representa a porcentagem de imagens contendo os itens que queremos identificar no conjunto enviado.
Em nosso caso, temos uma precisão de 99.7%, o que indica que alguma imagem enviada não foi reconhecida e, portanto, foi descartada.
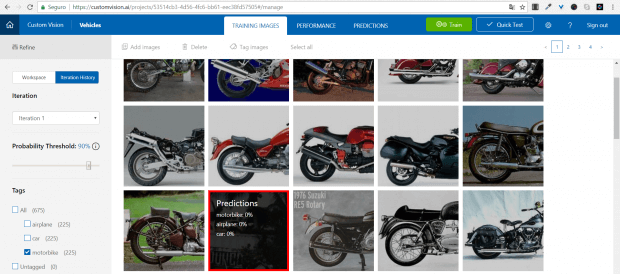
Para fazer o double check, acesse a guia TRAINING IMAGES e depois Iteration History. Agora, podemos ver qual imagem confundiu nosso modelo.
Hora do teste
Agora vamos aos testes. Podemos fazer isso de forma simples, utilizando o próprio site. Vamos para a aba Quick Test, selecione a opção Browse local files e selecione uma imagem para teste.
No meu caso, estou utilizando uma das imagens de teste que separei anteriormente. Você pode selecionar uma imagem da própria web.
Ao fazer o upload, note que você já terá a classificação da imagem segundo seu modelo.
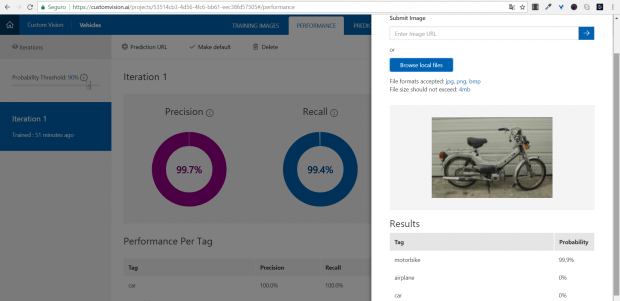
Tente utilizar outras imagens de teste… Temos os carros, aviões ou até mesmo coisas que não tenham nenhuma ligação com o modelo treinado.
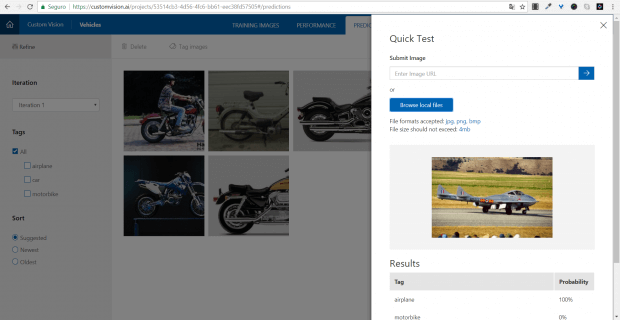
Outra coisa interessante é que, ao realizar estes testes, você pode acessar a guia PREDICTIONS. Lá você vai ver todas as imagens que foram enviadas para teste.
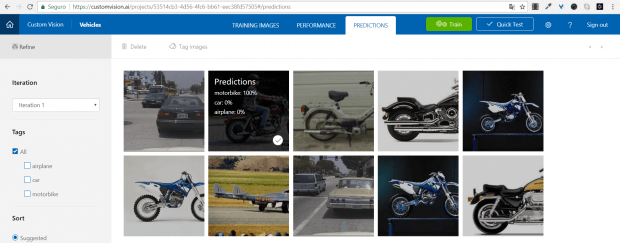
Note que aqui temos a classificação que foi realizada para cada imagem. Você pode deletar uma ou todas as imagens, como também realizar um novo treino com essas imagens sendo adicionadas ao dataset original. Isso pode ou não melhorar a precisão do nosso modelo.
Este artigo está fortemente baseado na utilização do portal. Lembre-se que podemos fazer da ingestão ao treino via código.
Gerando novos modelos
Durante os testes, você pode verificar que seu modelo precisa melhorar. Você já sabe que um bom modelo vai depender da qualidade de seus dados, e segundo essa linha você adiciona novas imagens com mais ângulos, cores e perspectivas diferentes.
Pronto, agora você só precisa realizar outro treino para verificar se o novo conjunto vai ou não melhorar sua classificação.
O resultado deste processo é que será gerado a cada treino um novo modelo que será chamado aqui de Iteration.
Gerando nosso modelo as a service
Já temos nosso modelo treinado, realizamos alguns testes e agora chegou o momento de usar consumir nosso modelo.
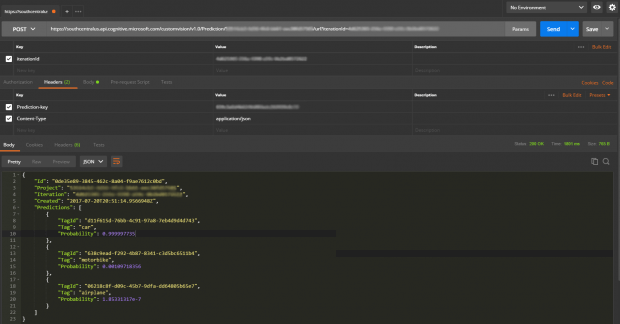
Para isso, você só precisa clicar em Prediction URL. Com isso, veremos o endpoint da nossa aplicação, que vamos usar para consumir o modelo. Aqui também temos nossa Prediction-Key, que deve ser informada no cabeçalho da requisição.
Um detalhe importante é que você pode definir qual Iteration você quer consumir. Sendo assim, é possível usar o modelo padrão ou definir um modelo com melhor precisão.
Em relação ao código, é tudo muito simples. Você pode enviar a URL ou o binário. Para efeitos práticos, realizei o primeiro teste utilizando o postman.
A imagem utilizada segue abaixo. Você pode acessar a imagem no seguinte link: car-train. Essa foi uma imagem retirada da internet, você pode passar um link qualquer para realizar seu teste.
{kind=link}

Neste caso, estou utilizando a API de Custom Vision Prediction, que aponta diretamente para o nosso modelo.
Conclusão
Esta é uma parte introdutória do assunto e do serviço, porém já é possível perceber todo o potencial oferecido pelo produto. Existem ainda algumas observações importantes a serem feitas, tanto na questão mais prática em relação ao desenvolvimento, quanto na questão mais teórica, a fim de entender os propósitos e assim construir modelos satisfatórios.
Estou roterizando um vídeo sobre o assunto, e creio que lá será mais simples expor todo o conteúdo e realizar melhor os testes. Assim que o mesmo estiver publicado, atualizo este artigo.
Por hora, é isso ai pessoal.
Referências

De 0 a 10, o quanto você recomendaria este artigo para um amigo?