

Com mais de cinco milhões de viagens realizadas diariamente pelo Uber em todo o mundo, é importante para os engenheiros da empresa que eles garantam que os dados são precisos. Se usados corretamente, metadados e dados agregados podem rapidamente detectar abuso de plataforma, de spam a contas falsas e fraude de pagamento. Amplificar os sinais de dados certos torna a detecção mais precisa e, portanto, mais confiável.
Para enfrentar esse desafio em nossos sistemas e outros, a Engenharia da Uber e a Databricks trabalharam juntas para colaborar com a Locality Sensitive Hashing (LSH) para o Apache Spark 2.1. O LSH é um algoritmo randomizado e uma técnica de hashing comumente usado em tarefas de aprendizagem em máquina de grande escala, incluindo agrupamento e pesquisa aproximada do semelhante/do vizinho mais próximo.
Neste artigo, vamos demonstrar como essa poderosa ferramenta é usada pela Uber para detectar viagens fraudulentas em escala.
Por que LSH?
Antes de a Engenharia da Uber implementar LSH, usamos a abordagem N^2 para filtrar através de viagens; embora fosse precisa, a abordagem N^2 era, em última instância, muito demorada, intensiva em volume e dependente de hardware para o tamanho e escala da Uber.
A ideia geral do LSH é usar uma família de funções (conhecidas como famílias LSH) para fazer hash de pontos de dados em buckets, de modo que os pontos de dados próximos uns dos outros estejam localizados no mesmo bucket com alta probabilidade, enquanto pontos de dados longe uns dos outros estejam provavelmente em buckets diferentes. Isso facilita a identificação de viagens com vários graus de sobreposição.
Como referência, o LSH é uma tecnologia multiuso com inúmeras aplicações, incluindo:
- Detecção quase duplicada: o LSH é comumente usado para de-duplicar grandes quantidades de documentos, páginas da web e outros arquivos.
- Estudo de associação da abrangência do genoma: os biólogos frequentemente usam o LSH para identificar expressões genéticas semelhantes em bancos de dados genômicos.
- Pesquisa de imagens em grande escala: o Google usou o LSH juntamente com o PageRank para construir sua tecnologia de pesquisa de imagens VisualRank.
- Impressão digital de áudio/vídeo: nas tecnologias multimídia, o LSH é amplamente utilizado como uma técnica de impressão digital de dados A/V.
LSH na Uber
O caso de uso primário do LSH na Uber é detectar viagens semelhantes com base em suas propriedades espaciais, um método de identificação de motoristas fraudulentos. Os engenheiros da Uber apresentaram esse caso de uso durante a park Summit 2016, onde discutiram as motivações da nossa equipe por trás do uso do LSH no framework Spark para transmitir todas as viagens e filtrar pelas fraudulentas. Nossas motivações para usar o LSH na Spark são três:
- Spark é parte integrante das operações da Uber e muitas equipes internas atualmente usam o Spark para vários tipos de processamento de dados complexos, incluindo aprendizado da máquina, processamento de dados espaciais, computação em séries temporais, análise e previsão e exploração ad hoc de dados científicos. De fato, a Uber usa quase todos os componentes do Spark, como MLlib, Spark SQL, Spark Streaming e processamento direto do RDD em YARN e Mesos; como nossa infraestrutura e ferramentas são construídas em torno do Spark, os engenheiros da Uber podem criar e gerenciar aplicativos Spark facilmente.
- Spark torna eficiente fazer limpeza de dados e engenharia de recursos antes que qualquer aprendizagem de máquina real seja conduzida, tornando o número de crunching muito mais rápido. O grande volume de dados coletados da Uber faz com que a resolução desse problema por abordagens básicas seja não escalável e muito lenta.
- Não precisamos de uma solução exata para essa equação, portanto não há necessidade de comprar e manter hardware adicional. As aproximações nos fornecem informações suficientes para fazer chamadas de julgamento sobre atividades potencialmente fraudulentas e, nesse caso, são boas o suficiente para resolver nossos problemas. O LSH nos permite negociar alguma precisão por economizar muitos recursos de hardware.
Por essas razões, resolver o problema implementando LSH no Spark foi a escolha certa para nossos objetivos de negócios: escala, escala e escala novamente.
Em um nível elevado, nossa abordagem para usar LSH tem três etapas. Primeiro, criamos um vetor de recursos para cada viagem dividindo-a em segmentos de área de igual tamanho. Então, nós fazemos hash dos vetores com MinHash para função de distância Jaccard. Por último, ou fazemos junção de similaridade em grupo ou pesquisa k-Nearest Neighbor em tempo real. Em comparação com a abordagem básica de força bruta de detecção de fraude, nossos conjuntos de dados permitiram que os trabalhos do Spark terminassem mais rápido em uma ordem completa de magnitude (de cerca de 55 horas com o método N^2 para 4 horas usando o LSH).
Tutorial da API
Para melhor demonstrar como funciona o LSH, vamos mostrar um exemplo de como usar o MinHashLSH no conjunto de dados da Wikipedia Extraction (WEX) para encontrar artigos semelhantes.
Cada família LSH está ligada ao seu espaço métrico. No Spark 2.1, existem dois estimadores de LSH:
- BucketedRandomProjectionLSH para Distância Euclidiana
- MinHashLSH para Distância Jaccard
Nesse cenário, usamos MinHashLSH, uma vez que trabalharemos com vetores de recursos reais de contagem de palavras.
Carregar dados brutos
Primeiro, precisamos lançar um cluster EMR (Elastic MapReduce) e montar um conjunto de dados WEX como um volume EBS (Elastic Block Store). Detalhes adicionais sobre esse processo estão disponíveis através das documentações da AWS sobre EMR e EBS.
Depois de configurar o ambiente de texto, carregamos uma amostra de dados WEX para HDFS com base no tamanho do cluster EMR. No shell d Spark, carregamos os dados de amostra em HDFS:
// Read RDD from HDFS import org.apache.spark.ml.feature._ import org.apache.spark.ml.linalg._ import org.apache.spark.sql.types._ val df = spark.read.option(“delimiter”,”\t”).csv(“/user/hadoop/testdata.tsv”) val dfUsed = df.select(col(“_c1”).as(“title”), col(“_c4”).as(“content”)).filter(col(“content”) !== null) dfUsed.show()
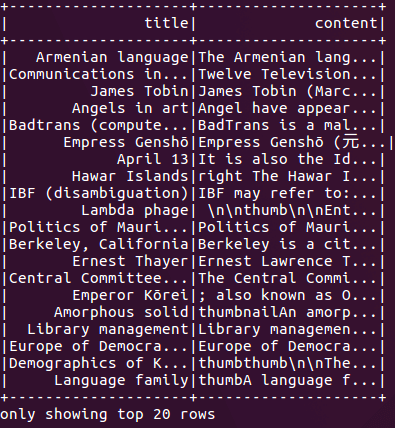 Figura 1: Os artigos da Wikipedia são representados como títulos e conteúdo no Spark.
Figura 1: Os artigos da Wikipedia são representados como títulos e conteúdo no Spark.
A Figura 1 mostra os resultados de nosso código anterior, exibindo artigos por título e assunto. Usaremos o conteúdo como nossas chaves hash e aproximadamente encontraremos artigos semelhantes da Wikipedia nas experiências seguintes.
Preparar vetores de recursos
MinHash é uma técnica de LSH muito comum para estimar rapidamente como dois conjuntos são semelhantes entre si. Com o MinHashLSH implementado no Spark, representamos cada conjunto como um vetor binário esparso. Nesta etapa, vamos converter os conteúdos de artigos da Wikipédia em vetores.
Usando o código a seguir para engenharia de recursos, dividimos o conteúdo do artigo em palavras (Tokenizer), criamos vetores de recursos de contagens de palavras (CountVectorizer) e removemos artigos vazios:
“ // Tokenize the wiki content
val tokenizer = new Tokenizer().setInputCol(“content”).setOutputCol(“words”)
val wordsDf = tokenizer.transform(dfUsed)
// Word count to vector for each wiki content
val vocabSize = 1000000
val cvModel: CountVectorizerModel = new CountVectorizer().setInputCol(“words”).setOutputCol(“features”).setVocabSize(vocabSize)
.setMinDF(10).fit(wordsDf)
val isNoneZeroVector = udf({v: Vector => v.numNonzeros > 0}, DataTypes.BooleanType)
val vectorizedDf = cvModel.transform(wordsDf).filter(isNoneZeroVector(col(“features”))).select(col(“title”), col(“features”))
vectorizedDf.show()
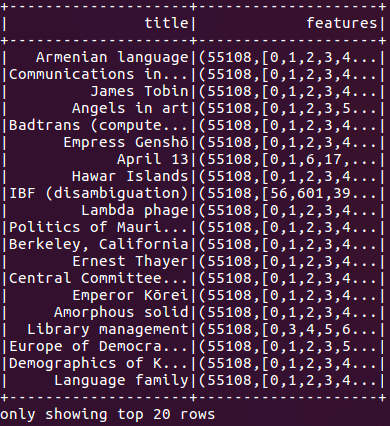 Figura 2: Após realizar a engenharia de recurso do nosso código, os conteúdos de artigos da Wikipédia são convertidos em vetores binários esparsos.
Figura 2: Após realizar a engenharia de recurso do nosso código, os conteúdos de artigos da Wikipédia são convertidos em vetores binários esparsos.
Ajustar e consultar um modelo LSH
Para usar o MinHashLSH, primeiro ajustamos um modelo MinHashLSH em nossos dados remodelados com o comando abaixo:
val mh = new MinHashLSH().setNumHashTables(3).setInputCol(“features”).setOutputCol(“hashValues”) val model = mh.fit(vectorizedDf)
Podemos fazer vários tipos de consultas com o nosso modelo LSH, mas para os propósitos deste artigo, primeiro executamos uma transformação de recurso no conjunto de dados:
model.transform(vectorizedDf).show()
Esse comando nos fornece os valores de hash, que podem ser úteis para junções manuais e para geração de recursos.
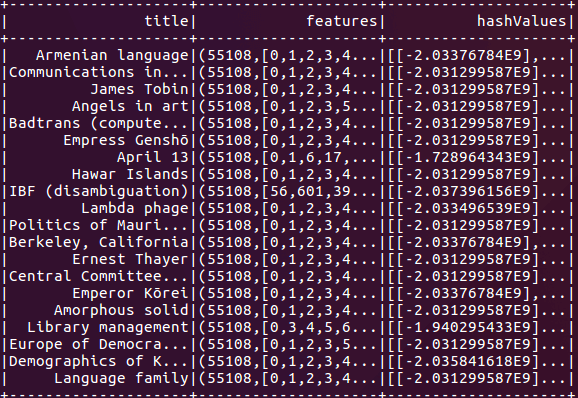 Figura 3: MinHashLSH adiciona uma nova coluna para armazenar hashes, com cada hash representado como um array de vetores.
Figura 3: MinHashLSH adiciona uma nova coluna para armazenar hashes, com cada hash representado como um array de vetores.
Em seguida, executamos uma pesquisa aproximada do semelhante mais próximo para encontrar o ponto de dados mais próximo do nosso alvo. Por uma questão de demonstração, nós procuramos por artigos com conteúdo aproximadamente correspondente à frase united states.
val key = Vectors.sparse(vocabSize, Seq((cvModel.vocabulary.indexOf(“united”), 1.0), (cvModel.vocabulary.indexOf(“states”), 1.0))) val k = 40 model.approxNearestNeighbors(vectorizedDf, key, k).show()
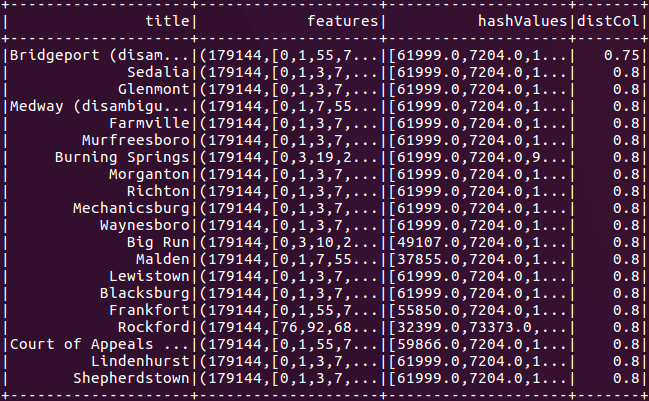 Figura 4: Uma pesquisa aproximada do semelhante mais próximo encontra artigos da Wikipédia relacionados a “united states”.
Figura 4: Uma pesquisa aproximada do semelhante mais próximo encontra artigos da Wikipédia relacionados a “united states”.
Finalmente, executamos uma junção de similaridade aproximada para encontrar pares semelhantes de artigos dentro do mesmo conjunto de dados:
// Self Join val threshold = 0.8 model.approxSimilarityJoin(vectorizedDf, vectorizedDf, threshold).filter(“distCol != 0”).show()
Observe que, embora usemos uma auto junção, abaixo também poderíamos juntar diferentes conjuntos de dados para obter os mesmos resultados.
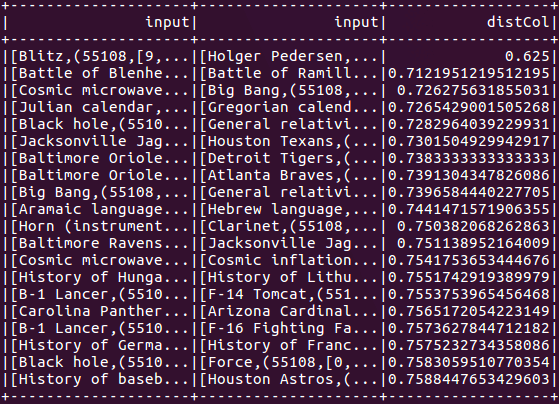 Figura 5: Uma junção de similaridade aproximada lista artigos Wikipedia semelhantes, definindo o número de tabelas hash.
Figura 5: Uma junção de similaridade aproximada lista artigos Wikipedia semelhantes, definindo o número de tabelas hash.
A Figura 5 demonstra como definir o número de tabelas hash. Para o comando aproximado do semelhante mais próximo e uma junção aproximada de similaridade, o número de tabelas hash pode ser usado para trocar entre tempo de execução e taxa de falso positivo. Adicionar mais tabelas hash irá aumentar a precisão (uma positiva), mas também o custo de comunicação do programa e tempo de execução. Por padrão, o número de tabelas hash é definido como um.
Para obter prática adicional usando LSH no Spark 2.1, você também pode executar exemplos menores na distribuição Spark para BucketRandomProjectionLSH e MinHashLSH.
Testes de desempenho
A fim de avaliar o desempenho, nós então padronizamos nossas implementações de MinHashLSH sobre o conjunto de dados WEX. Usando uma nuvem AWS, nós incumbimos 16 executores (instâncias m3.xlarge) com a realização de uma pesquisa aproximada de semelhante mais próximo e junção de similaridade aproximada em uma amostra de conjuntos de dados WEX.
Nas tabelas abaixo, podemos ver que o semelhante aproximado mais próximo executou 2x mais rápido do que a varredura completa com o número de tabelas hash definido como cinco, enquanto que a junção de similaridade aproximada executou 3x-5x mais rápido dependendo do número de linhas de saída e tabelas hash:
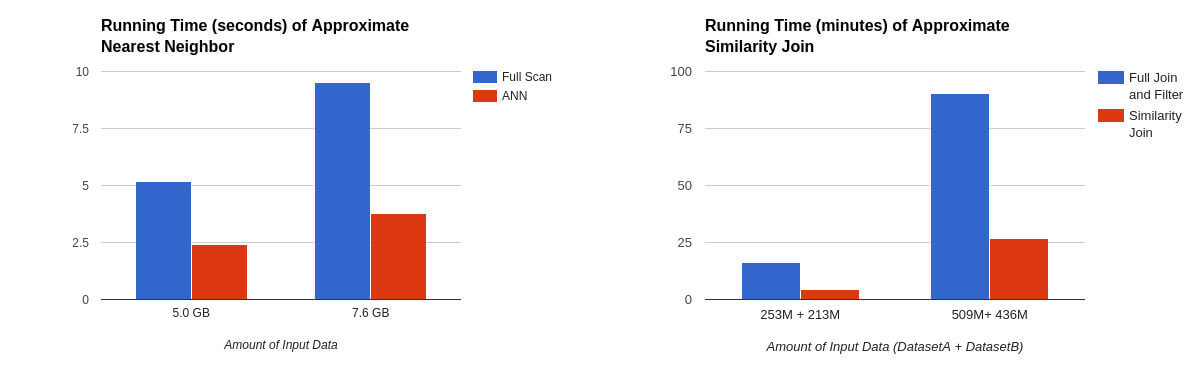 Figura 6: Com numHashTables=5, o semelhante aproximado mais próximo executou 2x mais rápido que a varredura completa (como mostrado à direita). Com numHashTables=3, a junção de similaridade aproximada executou 3x-5x mais rapidamente do que a junção e o filtro cheios (como mostrado na esquerda).
Figura 6: Com numHashTables=5, o semelhante aproximado mais próximo executou 2x mais rápido que a varredura completa (como mostrado à direita). Com numHashTables=3, a junção de similaridade aproximada executou 3x-5x mais rapidamente do que a junção e o filtro cheios (como mostrado na esquerda).
Nosso experimento também mostra que, apesar de seu curto tempo de execução, os algoritmos alcançaram alta precisão em comparação com os resultados de métodos de força bruta como valor de referência. Enquanto isso, a pesquisa aproximada de semelhante mais próximo obteve 85% de precisão para as 40 linhas retornadas, enquanto nossa junção de similaridade aproximada encontrou com sucesso 93% dos pares de linhas semelhantes. Essa compensação de precisão de velocidade fez do LSH uma ferramenta poderosa na detecção de viagens fraudulentas diárias de meros terabytes de dados.
Próximos passos
Embora nosso modelo de LSH tenha ajudado a identificar a atividade do motorista fraudulento, nosso trabalho está longe de ter acabado. Durante nossa implementação inicial do LSH, planejamos vários recursos para implementar em lançamentos futuros. Os recursos de alta prioridade incluem:
- SPARK-18450: Além de especificar o número de tabelas hash necessárias para concluir a pesquisa, esse novo recurso usa o LSH para definir o número de funções hash em cada tabela hash. Essa alteração também proporcionará suporte total para a amplificação do composto AND/OR.
- SPARK-18082 & SPARK-18083: Há outras famílias de LSH que queremos implementar. Essas duas atualizações permitirão a amostragem de bits para a distância de Hamming entre dois pontos de dados e sinais de projeção aleatória para a distância do cosseno que são comumente usados em tarefas de aprendizado de máquina.
- SPARK-18454: Um terceiro recurso melhorará a API da pesquisa aproximada de semelhante mais próximo. Essa nova pesquisa de similaridade de multi-sonda pode melhorar a qualidade de pesquisa sem a necessidade de um grande número de tabelas hash.
Ficaremos felizes com o seu feedback, à medida que continuamos a desenvolver e escalar nosso projeto para incorporar os recursos acima – e muitos outros.
***
Este artigo é do Uber Engineering. Ele foi escrito por Yun Ni, Kelvin Chul e Joseph Bradley. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/lsh/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?