

Recentemente participei de um projeto envolvendo a criação de um bot em que usaríamos diversos serviços cognitivos do AZURE, incluindo o LUIS, que trata da compreensão de linguagem.
Ocorre que decidimos incluir uma espécie de “tratamento de erro” no nosso bot. Caso o LUIS não entendesse o que usuário pedia (isto é: se ele não estivesse treinado para compreender determinado tipo de solicitação), nós iríamos pesquisar nossa base de conhecimento para verificar se existia algum tópico que pudesse servir para “desambiguação” deste pedido.
Foi então que decidimos usar Azure Search, que eu apresento a seguir.
O que é o Azure Search
É um serviço de busca customizável disponível na plataforma Azure. Assim como grande parte dos serviços da plataforma, o Azure Search é bastante novo, mas seu uso vem crescendo muito rapidamente. Segundo o ranking mundial do site DB-Engine, há um ano ele ocupava a posição 82º no ranking dos “banco de dados” mais usados, mas subiu para a posição 57º no ranking de Abril/2018.
Como parte da plataforma Azure, ele é cobrado como um serviço, portanto, você paga pelo consumo que faz. É fácil imaginar uma aplicação que se beneficie de um serviço de busca. Basta imaginar, por exemplo, o cliente de um banco buscando alguma informação específica numa base de conhecimento de “perguntas frequentes”.
Esta tarefa pode ser um pesadelo para o usuário, dependendo do tamanho desta base de conhecimento. O Azure Search permite ao desenvolvedor criar listas de respostas possíveis que sejam mais próximas da solução que se espera encontrar.
Criando o Serviço
Para começar o trabalho, vou criar um serviço de busca no Azure, assim eu acesso o portal do Azure e faço meu login. Em seguida, clico no botão Create a resource e pesquiso pelo serviço de nome “SEARCH SERVICES”, como mostra a imagem a seguir:
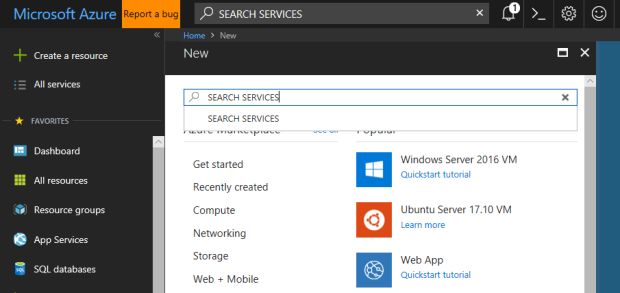
Em seguida, escolho o serviço Azure Search e clico no botão Create.
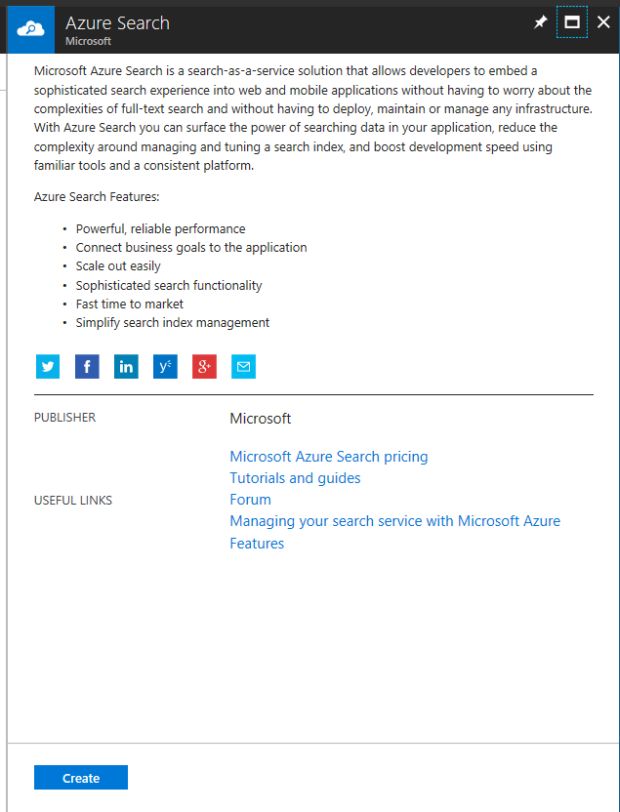
Agora defino as características do serviço que será criado. Para isso, é necessário informar:
- URL do serviço, conforme padrão adotado ([padrão].search.windows.net)
- Conta que será usada (“subscription”)
- O datacenter em que será criado (“location”): escolhi BRAZIL SOUTH
- O nível de preço contrato (“pricing tier”): escolhi FREE
- O recurso do AZURE que será usado (“resource group”)
Preenchidos os dados, clico no botão Create e já tenho um serviço pronto, como mostra a imagem a seguir.
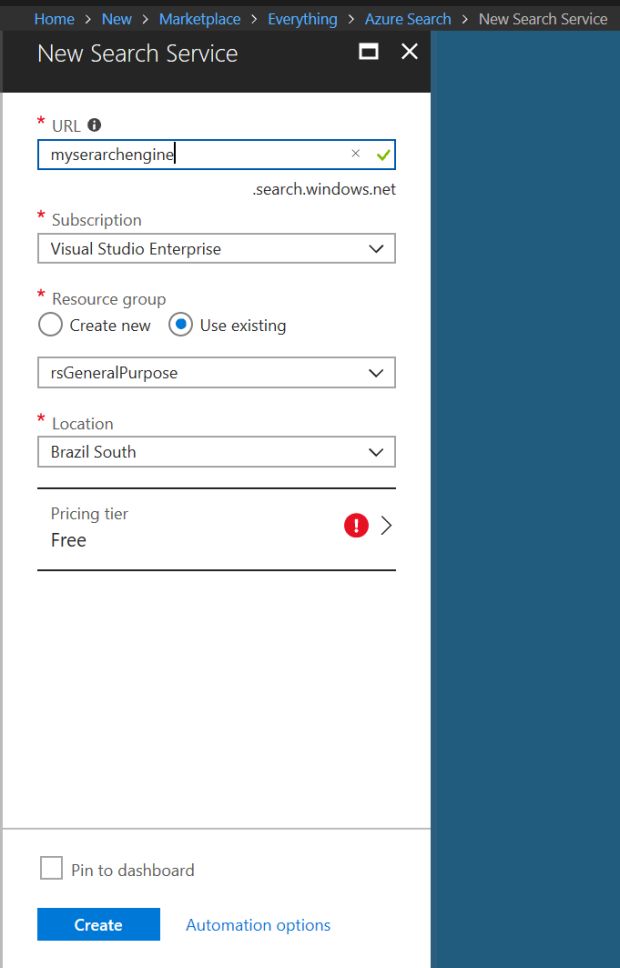
Agora que existe um serviço de busca criado, posso trabalhar nos índices que serão usados nas minhas buscas.
Criando um índice
A ideia de índice no Azure Search é diferente daquela que estamos habituados no mundo das bases de dados relacionais. Aqui, cada índice está associado a uma única base de conhecimento, que geralmente é uma coleção de documentos JSON.
Dependendo do nível do serviço contratado, pode-se chegar ao limite de um único serviço suportando 3 mil índices – cada um deles com 1 milhão de documentos de até 16Mb cada um.
Neste exemplo que apresento, eu criei uma base de conhecimento indexando minhas próprias publicações. São cerca de 200 documentos JSON, cada um com 10 campos cada um. O exemplo abaixo mostra a estrutura destes documentos.
{
"id" : "31"
, "MIDIA" : "iMasters"
, "LINGUA" : "Português"
, "AUTOR" : "Wagner Crivelini"
, "TITULO" : "Dicas e truques para importação de arquivos em formato texto"
, "TEMA" : "Tem inúmeras coisas no mundo de TI que nos são vendidas como se fossem mais fáceis que roubar doce "
, "DATA" : "03/12/2013"
, "LINK" : "https://imasters.com.br/banco-de-dados/dicas-e-truques-para-importacao-de-arquivos-em-formato-texto"
, "TAGS" : "arquivos texto"
}
Continuando a criação do índice, volto ao portal do Azure, abro o meu serviço de busca (que se chama wcrivelini-test1 – https://wcrivelini-test1.search.windows.net) e clico em Add Index. Dou o nome “publications” para este novo índice e clico em OK.
Finalmente, preciso definir os campos que serão indexados. Clico em Add/Edit Fields, e no painel que se abre à direita digito os nomes dos campos, os tipos de dados e as operações suportadas em cada campo (no caso, campos que são pesquisados, retornados, que servem de filtro ou de critério de ordenação). O campo ID é sempre obrigatório na criação dos índices.
Ao final, clico em Save para finalizar. O quadro a seguir mostra a estrutura do índice criado.
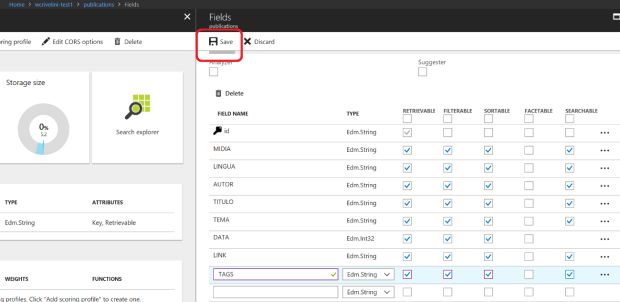
Carregando a Base de Conhecimento
Existem várias formas de se carregar documentos para um serviço do Azure Search. Se você não conhece a estrutura da sua base de conhecimento, o assistente disponível no portal do Azure irá ajudá-lo a mapear os campos do índice enquanto os documentos são carregados.
Como eu conheço a estrutura do meu índice e preciso apenas carregar os documentos, eu opto por usar a API de REST para fazer esta carga. Para simplificar meu trabalho, usarei o aplicativo POSTMAN. Com ele posso fazer todo tipo de consumo de serviço do Azure Search por chamadas REST, inclusive o gerenciamento dos documentos da base de conhecimento.
Como minha coleção tem menos de 1000 documentos JSON, consigo fazer a carga completa numa única operação. Preciso apenas configurar a API REST e adaptar meus documentos JSON para informar a ação a ser tomada, que é [“@search.action”: “upload”].
A tabela a seguir mostra as configurações necessárias.
| Endpoint do serviço de pesquisa | https://wcrivelini-test1.search.windows.net/ |
| Índice desejado | Publications |
| Api-version | 2016-09-01 |
| Endpoint completo para carga de arquivos | https://wcrivelini-test1.search.windows.net/indexes/publications/docs/index?api-version=2016-09-01 |
| Verbo | POST |
| Headers | Content-type: application/JSON
Api-Key: [chave de segurança do seu serviço] (voltaremos a este assunto no próximo artigo da série) |
| Authorization | “No Auth” |
| Body (raw) | {“value”: [
{“@search.action”: “upload”, “id” : “1”, “MIDIA” : “iMasters”, “LINGUA” : “Português” , “AUTOR” : “Wagner Crivelini”, “TITULO” : “Preparando sua Base de Dados para o Mundo”, “TEMA” : “Aproveitando que o mundo não acabou, aceitei o convite do iMasters e começo agora a escrever esta coluna. O assunto de hoje ainda não é comum no dia-a-dia da maioria dos DBAs brasileiros, mas a tendência é que isso mude bastante nos próximos anos. Vamos falar de bancos de dados com suporte para caracteres internacionais.”, “DATA” : “41303”, “LINK” : “https://imasters.com.br/banco-de-dados/preparando-sua-base-de-dados-para-o-mundo/?trace=1519021197&source=admin”, “TAGS” : “caracter internacional” } , {JSON2} , {JSON3} ….. ]} |
Após configurar a chamada, clico em Send e confiro o resultado observando o campo “status” (que deve mostrar o valor true).
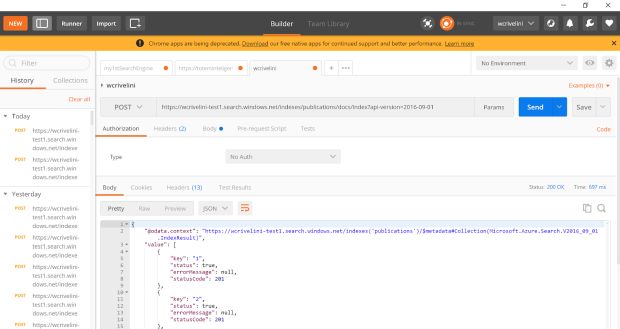
Finalmente tenho um serviço de pesquisa pronto para uso! O Azure Search oferece uma grande quantidade de recursos para pesquisa de dados. Por esta razão, eu apresentarei estes recursos na continuação deste artigo, onde o assunto será o consumo do serviço do AZURE SEARCH.
Até lá!
Leituras Sugeridas
- Azure Search Documentation por MICROSOFT.
- Adding Search Abilities to Your Apps with Azure Search por Chad Campbell, PLURALSIGHT.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?