

Uma rede neural recorrente (RNN) é uma classe de redes neurais que inclui conexões ponderadas dentro de uma camada (em comparação com as redes de feed-forward tradicionais, onde conecta alimentação apenas para camadas subsequentes). Como as RNNs incluem loops, elas podem armazenar informações ao processar novas entradas. Essa memória os torna ideais para tarefas de processamento onde as entradas anteriores devem ser consideradas (como dados da série temporal). Por esta razão, as redes de deep learning atuais são baseadas em RNNs. Este tutorial explora as ideias por trás das RNNs e implementa uma a partir do zero para a previsão de dados em série.
As redes neurais são estruturas computacionais que mapeiam uma entrada para uma saída com base em uma rede de elementos de processamento altamente conectados (neurônios). Para um guia rápido em redes neurais, você pode ler outro dos meus tutoriais, “Um mergulho profundo nas redes neurais“, que analisou os perceptrons (os blocos de construção das redes neurais) e perceptrons multicamadas com aprendizado de propagação posterior.
No tutorial anterior, explorei a topologia de rede de feed-forward. Nesta topologia, mostrada na figura a seguir, você alimenta um vetor de entrada para a rede através das camadas ocultas e, eventualmente, isso resulta em uma saída. Nesta rede, os mapas de entrada para a saída (toda vez que a entrada é aplicada) de forma determinística.
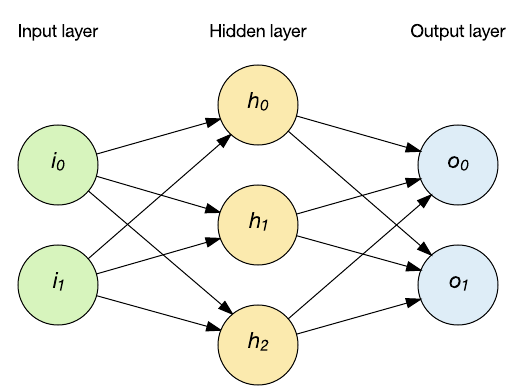
Mas, digamos que você está lidando com dados da série temporal. Um único ponto de dados isoladamente não é inteiramente útil porque ele carece de atributos importantes (por exemplo, a série de dados está mudando? Crescendo? Encolhendo?). Considere um aplicativo de processamento de linguagem natural em que letras ou palavras representam a entrada de rede. Quando você considera entender as palavras, as letras são importantes no contexto. Essas entradas não são úteis isoladamente, mas apenas no contexto do que ocorreu antes delas.
As aplicações de dados de série temporal exigem um novo tipo de topologia que possa considerar o histórico da entrada. Aqui é onde você pode aplicar RNNs. Uma RNN inclui a capacidade de manter a memória interna com feedback e, portanto, suportar o comportamento temporal. No exemplo a seguir, a saída da camada oculta é aplicada de volta para a camada oculta. A rede permanece feed-forward (as entradas são aplicadas na camada oculta e, em seguida, na camada de saída), mas o RNN mantém o estado interno através dos nodes de contexto (que influenciam a camada oculta nas entradas subsequentes).
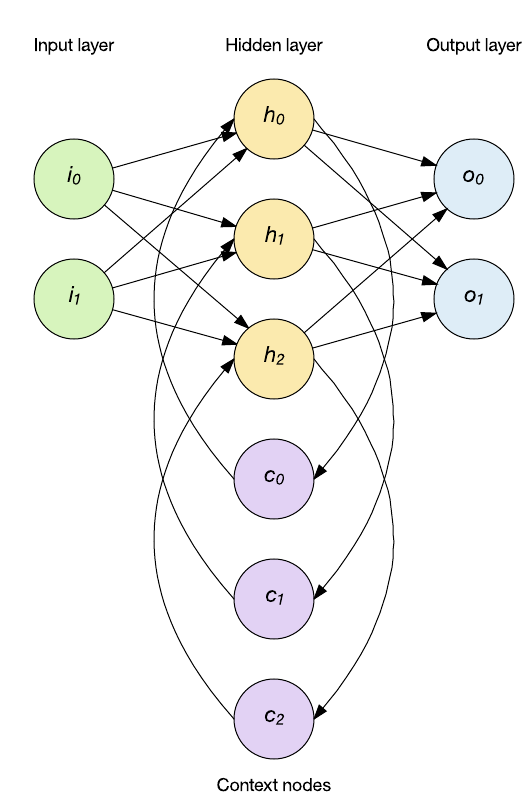
RNNs não são uma única classe de rede, mas sim uma coleção de topologias que se aplicam a diferentes problemas. Um aspecto interessante das redes recorrentes é que com camadas e nodes suficientes, elas são totalmente Turing, o que significa que elas podem implementar qualquer função computável.
Arquiteturas de RNNs
As RNNs foram introduzidas na década de 1980 e sua capacidade de manter a memória de entradas passadas abriu novos domínios de problemas para redes neurais. Vamos explorar algumas das arquiteturas que você pode usar.
Hopfield
A rede Hopfield é uma memória associativa. Dado um padrão de entrada, ela recupera o padrão mais semelhante para a entrada. Essa associação (conexão entre a entrada e a saída) imita a operação do cérebro humano. Os seres humanos são capazes de recordar completamente uma memória dados os aspectos parciais dela, e a rede Hopfield opera de forma semelhante.
As redes Hopfield são de natureza binária, com neurônios individuais ligados (em disparo) ou desligados (sem disparo). Cada neurônio se conecta a todos os outros neurônios através de uma conexão ponderada (veja a imagem seguinte). Cada neurônio serve como entrada e saída. Na inicialização, a rede é carregada com um padrão parcial e, em seguida, cada neurônio é atualizado até a rede convergir (o que é garantido). A saída é fornecida na convergência (o estado dos neurônios).
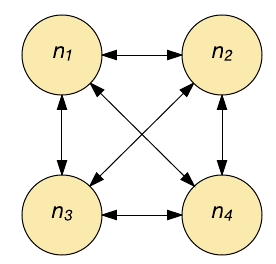
As redes Hopfield são capazes de aprender (através do aprendizado Hebbian) múltiplos padrões e convergem para recuperar o padrão mais próximo dada a presença de ruído nas entradas. As redes Hopfield não são adequadas para problemas no domínio do tempo, mas são de natureza recorrente.
Redes recorrentes simples
As redes recorrentes simples são uma classe popular de redes recorrentes que inclui uma camada de estado para introduzir o estado na rede. A camada de estado influencia a próxima etapa de entrada e, portanto, pode ser aplicada em padrões de dados que variam no tempo.
Você pode aplicar dinamicidade de várias maneiras, mas duas abordagens populares são as redes Elman e Jordan (veja a imagem seguinte). No caso da rede Elman, a camada oculta alimenta uma camada de estado de nodes de contexto que retém memória de entradas passadas. Conforme mostrado na figura a seguir, existe um único conjunto de nodes de contexto que mantém a memória do resultado anterior da camada oculta. Outra topologia popular é a rede Jordan. As redes Jordan diferem em que, ao invés de manter o histórico da camada oculta, elas armazenam a camada de saída na camada de estado.
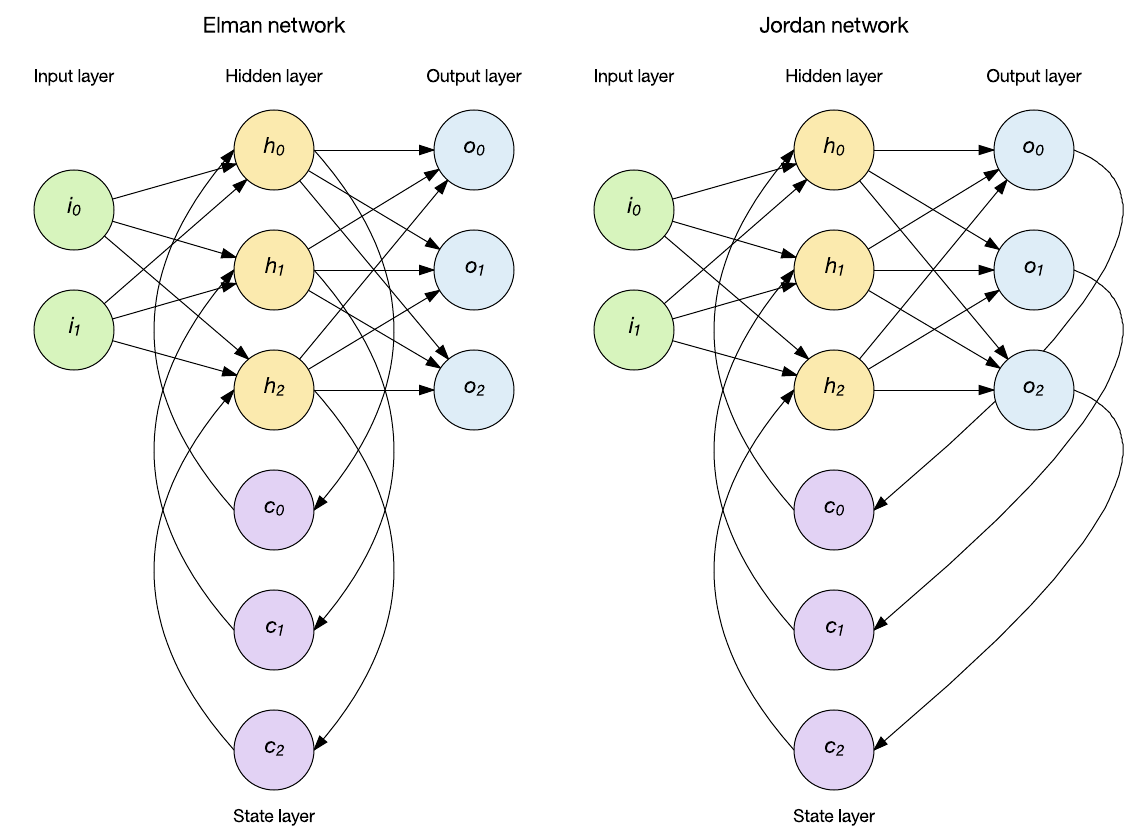
As redes Elman e Jordan podem ser treinadas através de propagação posterior padrão e cada uma foi aplicada ao reconhecimento de sequências e ao processamento de linguagem natural. Observe aqui que uma única camada de estado foi introduzida, mas é fácil ver que você poderia adicionar camadas de estado onde a saída da camada de estado atua como entrada para uma camada de estado subsequente. Eu exploro essa ideia no contexto da rede Elman mais adiante neste tutorial.
Outras redes
O trabalho em redes de estilo recorrente não foi interrompido, e hoje as arquiteturas recorrentes estão definindo o padrão para operar em dados de séries temporais. A abordagem da memória de curto e longo prazo (LSTM) em aprendizagem profunda, tem sido usada com redes convolutivas para descrever em linguagem gerada, o conteúdo de imagens e vídeos. A LSTM inclui um portão de esquecimento/forget-gate que permite que você “treine” os neurônios individuais sobre o que é importante e quanto tempo ele permanecerá importante. A LSTM pode operar em dados onde eventos importantes podem ser separados por longos períodos de tempo.
Outra arquitetura recente é chamada de gated recurrent unit (GRU). A GRU é uma otimização da LSTM que requer menos parâmetros e recursos.
Algoritmos de treino da RNN
As RNNs possuem algoritmos de treino exclusivos devido à sua natureza de incorporar informações históricas no tempo ou na sequência. Os algoritmos de descida de gradiente foram aplicados com sucesso na otimização de ponderação da RNN (para minimizar o erro ajustando o peso na proporção da derivada do erro desse peso). Uma técnica popular é a posterior propagação através do tempo (BPTT), que aplica atualizações de peso somando as atualizações de peso de erros acumulados para cada elemento em uma sequência, e depois atualizando os pesos no final. Para grandes sequências de entrada, esse comportamento pode fazer com que os pesos desapareçam ou explodam (chamado de problema de gradiente de desaparecimento ou explosão). Para combater este problema, as abordagens híbridas são comumente usadas, em que a BPTT é combinada com outros algoritmos, como a aprendizagem recorrente em tempo real.
Outros métodos de treinamento também podem ser aplicados com sucesso em RNNs em evolução. Podem ser aplicados algoritmos evolutivos (como algoritmos genéticos ou recozimento simulado) para evoluir as populações de RNNs candidatas e, em seguida, recombiná-las como função de sua aptidão (ou seja, a capacidade delas em resolver o dado problema). Embora não sejam garantidos para convergir em uma solução, eles podem ser aplicados com sucesso em uma série de problemas, incluindo a evolução da RNN.
Uma aplicação útil de RNNs é a previsão de sequências. No exemplo a seguir, eu crio uma RNN que posso usar para prever a última letra de uma palavra dado um pequeno vocabulário. Vou alimentar a palavra na RNN, uma letra por vez e a saída da rede representará a próxima letra prevista.
Fluxo do algoritmo genético
Antes de saltar para o exemplo da RNN, vejamos o processo por trás dos algoritmos genéticos. O algoritmo genético é uma técnica de otimização que se inspira no processo de seleção natural. Conforme mostrado na figura a seguir, o algoritmo cria uma população aleatória de soluções candidatas (chamadas cromossomos) que codificam os parâmetros da solução que está sendo buscada. Depois de serem criados, cada membro da população é testado contra o problema e um valor de aptidão atribuído. Os pais são, então, identificados a partir da população (com a maior aptidão sendo preferida) e um cromossomo criança criado para a próxima geração. Durante a geração da criança, os operadores genéticos são aplicados (como tirar elementos de cada pai [chamado crossover] e introduzir mudanças aleatórias na criança [chamada mutação]). O processo, então, começa novamente com a nova população até encontrar uma solução candidata adequada.

Representando redes neurais em uma população de cromossomos
Um cromossomo é definido como o membro individual da população e contém uma codificação para o problema específico a ser resolvido. No contexto da evolução de uma RNN, o cromossomo é constituído pelos pesos da RNN, conforme mostrado na figura a seguir.
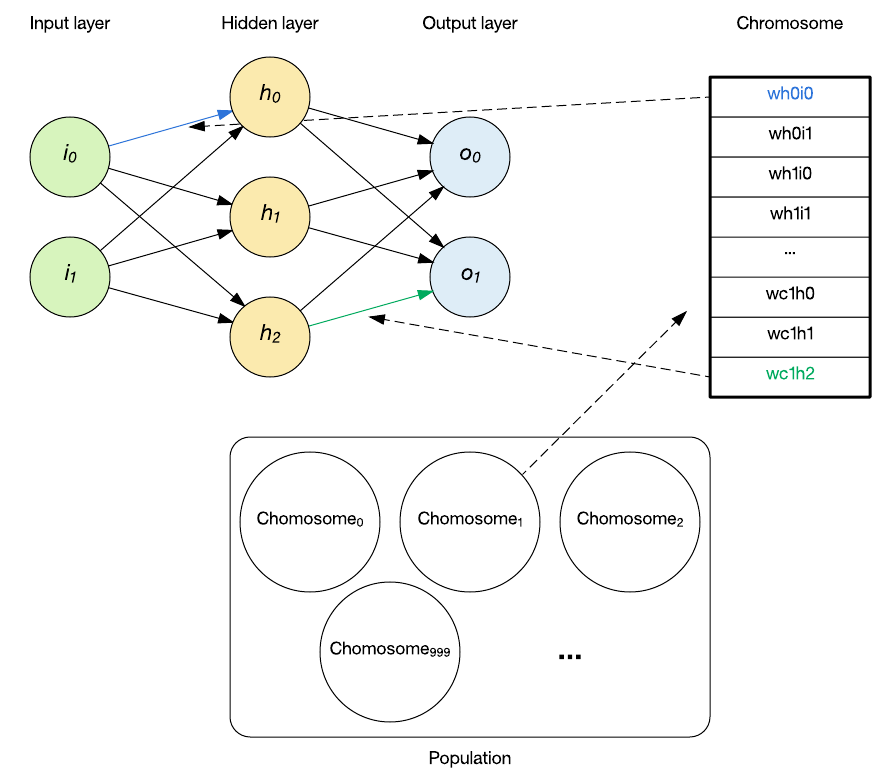
Cada cromossomo contém um valor de 16 bits por peso. O valor, no intervalo 0 – 65535, é convertido em um peso ao subtrair a metade do intervalo e, em seguida, multiplicando-o por 0.001. Isso significa que a codificação pode representar valores no intervalo de -32.767 a 32.768 em incrementos de 0.001.
O processo de tirar um cromossomo da população e gerar uma RNN é simplesmente definido como inicializar os pesos da rede com os pesos traduzidos do cromossomo. Neste exemplo, isso representa 233 pesos individuais.
Previsão de letras com RNNs
Agora, vamos explorar a aplicação de letras a uma rede neural. As redes neurais operam em valores numéricos, de modo que é necessária alguma representação para alimentar uma letra em uma rede. Para este exemplo, uso uma codificação one-hot. A codificação one-hot converte uma letra em um vetor, sendo que um único elemento do vetor é definido. Esta codificação cria uma característica distinta que pode ser usada matematicamente – por exemplo, cada letra representada obtém seu próprio peso aplicado na rede. Enquanto nessa implementação, eu represento letras através de one-hot; os aplicativos de processamento de linguagem natural representam palavras da mesma forma. A figura a seguir ilustra os vetores one-hot usados neste exemplo e o vocabulário usado para testar.

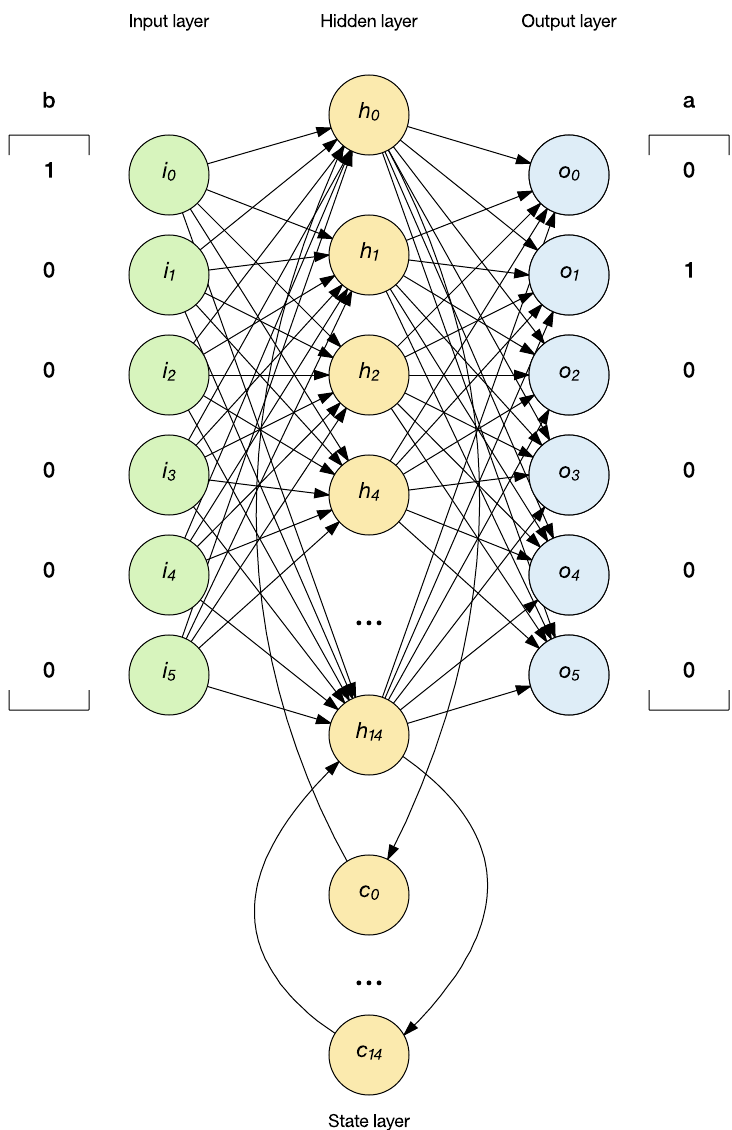
Então, agora eu tenho uma codificação que permitirá que minha RNN funcione com letras. Agora, vejamos como isso funciona no contexto da RNN. A figura a seguir ilustra a RNN estilo Elman no contexto da predição de letras (alimentando o vetor one-hot que representa a letra b). Para cada letra na palavra de teste, eu codifico a letra como um one-hot e, em seguida, alimento como a entrada para a rede. A rede é, então, executada de forma feed-forward e a saída é analisada de modo “a vencedora leva tudo” para determinar o elemento vencedor que define o vetor one-hot (neste exemplo, a letra a). Nesta implementação, apenas a última letra da palavra está marcada; outras letras são ignoradas de serem validadas, nem fazem parte do cálculo da aptidão.
Implementação simples de RNN estilo Elman
Vejamos a implementação da amostra de uma RNN estilo Elman treinada através de um algoritmo genético. Você pode encontrar o código-fonte do Linux para esta implementação no GitHub. A implementação é composta por três arquivos:
- main.c, que fornece o loop principal e uma função para testar e derivar a aptidão de uma população;
- ga.c, que implementa as funções do algoritmo genético;
- rnn.c, que implementa a RNN real;
Eu me concentro em duas funções principais: o processo de algoritmo genético e a função de avaliação da RNN
O cerne da RNN é encontrado na função RNN_feed_forward, que implementa a execução da rede RNN (veja o código seguinte). Esta função é dividida em três estágios e reflete a rede mostrada na imagem anterior. Na primeira etapa, calculo as saídas da camada oculta, que incorpora a camada de entrada e a camada de contexto (cada uma com seu próprio conjunto de pesos). Os nodes de contexto são inicializados para zero antes de testar uma determinada palavra. Na segunda etapa, calculo as saídas da camada de saída. Esta etapa incorpora cada neurônio da camada oculta com seus próprios pesos distintos. Finalmente, na terceira etapa, eu propago o primeiro neurônio da camada de contexto para o segundo neurônio da camada de contexto e a saída da camada oculta para o primeiro node do contexto. Esta etapa implementa as duas camadas de memória dentro da rede.
Observe que na camada oculta, uso a função tan como minha função de ativação e a função sigmoid como função de ativação na camada de saída. A função tan é útil na camada oculta porque tem o intervalo -1 a 1 (permitindo saídas positivas e negativas da camada oculta). Na camada de saída, onde eu estou interessado no maior valor para ativar o vetor one-hot, eu uso o sigmoid porque seu intervalo é 0 a 1.
void RNN_feed_forward( void )
{
int i, j, k;
// Stage 1: Calculate hidden layer outputs
for ( i = 0 ; i < HIDDEN_NEURONS ; i++ )
{
hidden[ i ] = 0.0;
// Incorporate the input.
for ( j = 0 ; j < INPUT_NEURONS+1 ; j++ )
{
hidden[ i ] += w_h_i[ i ][ j ] * inputs[ j ];
}
// Incorporate the recurrent hidden.
hidden[ i ] += w_h_c1[ i ] * context1[ i ];
hidden[ i ] += w_h_c2[ i ] * context2[ i ];
// apply tanh activation function.
hidden[ i ] = tanh( hidden[ i ] );
}
// Stage 2: Calculate output layer outputs
for ( i = 0 ; i < OUTPUT_NEURONS ; i++ )
{
outputs[ i ] = 0.0;
for ( j = 0 ; j < HIDDEN_NEURONS+1 ; j++ )
{
outputs[ i ] += ( w_o_h[ i ][ j ] * hidden[ j ] );
}
// apply sigmoid activation function.
outputs[ i ] = sigmoid( outputs[ i ] );
}
// Stage 3: Save the context hidden value
for ( k = 0 ; k < HIDDEN_NEURONS+1 ; k++ )
{
context2[ k ] = context1[ k ];
context1[ k ] = hidden[ k ];
}
return;
}
Eu implemento meu algoritmo genético no seguinte exemplo de código. Você pode visualizar este código em três partes. A primeira parte calcula a aptidão total da população (utilizada no processo de seleção) e também o cromossomo mais apto na população. O cromossomo mais apto é usado na segunda parte, que simplesmente copia esse cromossomo para a próxima população. Esta é uma forma de seleção elitista, na qual eu mantenho o cromossomo mais apto até a próxima população. A população é constituída por 2.000 cromossomos.
Na parte final do algoritmo genético, seleciono aleatoriamente dois pais da população e crio uma criança deles para a nova população. O algoritmo de seleção é baseado na chamada seleção de roda de roleta, na qual os cromossomos são selecionados aleatoriamente, mas os pais mais aptos são selecionados a uma taxa maior. Depois que dois pais foram selecionados, eles são recombinados em um cromossomo criança para a próxima população. Este processo inclui o potencial para crossover (onde um dos genes dos pais são selecionados para propagação) e também mutação (na qual um peso pode ser redefinido aleatoriamente). Este processo ocorre com baixa probabilidade (uma mutação por recombinação e um pouco menos para crossover).
void GA_process_population( unsigned int pop )
{
double sum = 0.0;
double max = 0.0;
int best;
int i, child;
best = 0;
sum = max = population[ pop ][ best ].fitness;
// Calculate the total population fitness
for ( i = 1 ; i < POP_SIZE ; i++ )
{
sum += population[ pop ][ i ].fitness;
if ( population[ pop ][ i ].fitness > max )
{
best = i;
max = population[ pop ][ i ].fitness;
}
}
// Elitist -- keep the best performing chromosome.
recombine( pop, best, best, 0, 0.0, 0.0 );
// Generate the next generation.
for ( child = 1 ; child < POP_SIZE ; child++ )
{
unsigned int parent1 = select_parent( pop, sum );
unsigned int parent2 = select_parent( pop, sum );
recombine( pop, parent1, parent2, child, MUTATE_PROB, CROSS_PROB );
}
return;
}
Você pode criar o código fonte da amostra no GitHub no Linux simplesmente digitando make e, em seguida, executando com ./rnn. Após a execução, a população é criada aleatoriamente e, em seguida, a seleção natural ocorre ao longo de algumas gerações até encontrar uma solução que preveja com precisão o último caractere de todo o vocabulário de teste ou que a simulação falhe na conversão em uma solução corretamente. Sucesso ou falha é determinado pela média de aptidão; se atinge 80% da aptidão máxima, então a população não possui diversidade suficiente para encontrar uma solução e vai sair.
Se uma solução for encontrada, o código emitirá todo o vocabulário de teste e mostrará a previsão de cada palavra. Note que a aptidão cromossômica baseia-se apenas na letra final de uma palavra, de modo que as letras internas não estão previstas. O código a seguir fornece uma amostra da saída bem-sucedida.
$ ./rnn
Solution found.
Testing based
Fed b, got s
Fed a, got b
Fed s, got e
Fed e, got d
Testing baned
Fed b, got s
Fed a, got b
Fed n, got d
Fed e, got d
Testing sedan
Fed s, got s
Fed e, got d
Fed d, got s
Fed a, got n
...
Testing den
Fed d, got d
Fed e, got n
Testing abs
Fed a, got d
Fed b, got s
Testing sad
Fed s, got s
Fed a, got d
O gráfico da aptidão média e máxima é mostrado na figura a seguir. Observe que cada gráfico começa em um nível de aptidão de ~13. Doze das palavras terminam em d, então uma rede simplesmente emitindo d para qualquer sequência de letras tem esse nível de sucesso. No entanto, avançar os pesos deve evoluir para considerar letras anteriores para prever com precisão o vocabulário fornecido. Como mostrado, mais de metade das gerações são necessárias para prever o último caso de teste na corrida bem-sucedida.
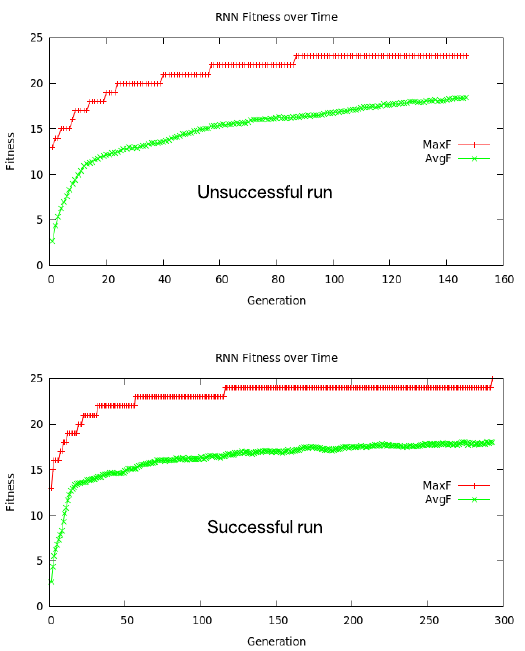
Uma observação interessante é que cada gráfico demonstra uma teoria na biologia evolutiva chamada equilíbrio pontuado, um fenômeno caracterizado por longos períodos de estase (estabilidade geral) pontuado por uma ruptura de mudança evolutiva. Em um caso, resultou em ficar preso em um mínimo local; no outro, a evolução foi bem sucedida (máximo global).
Indo além
As redes neurais tradicionais fornecem a capacidade de mapear um vetor de entrada para um vetor de saída de forma determinista. Para um grande conjunto de problemas, isso é ideal, mas quando as sequências ou os dados da série temporal devem ser considerados, a introdução da memória interna em uma rede pode permitir que se considere os dados anteriores ao tomar uma decisão sobre sua saída. As RNNs introduzem feedback nas redes tradicionais de feed-forward para que elas incluam um ou mais níveis de memória. As RNNs representam uma arquitetura fundamental para o futuro e podem ser encontradas nas tecnologias mais avançadas de deep learning, como LSTM e GRU.
Recursos para download
***
M. Tim Jones faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://www.ibm.com/developerworks/library/cc-cognitive-recurrent-neural-networks/index.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?