

Watson Knowledge Studio é uma aplicação oferecida pela IBM Cloud que permite o treinamento de modelos de machine learning customizados para a extração de dados valiosos de documentos de texto de acordo as necessidades do usuário e do cenário.
Através do Knowledge Studio é possível treinar o Watson para identificar dados significativos de textos dentro das especificidades de um determinado tema escolhido. Por exemplo identificar o autor de um artigo, a data do artigo, o assunto abordado e até mesmo a carga emocional do texto.
Como funciona
Basicamente, o Watson utiliza as estruturas semânticas, contextos e terminologias dos documentos inseridos como dataset de treinamento para identificar padrões semânticos, contextos e terminologias semelhantes em novos documentos submetidos a ele após a publicação do seu modelo customizado. Através da análise de contexto, ele consegue localizar as entidades presentes nos novos documentos e extrair os valores relacionados a essas entidades.
- Entidade: Pessoa
- Valor: Rodrigo
Para treinar um modelo customizado e extrair valor de um texto, seguimos uma esteira básica de atividades:
- Importar um dataset de documentos para treino que respeitem o cenário específico que o watson deve entender. Exemplo: um conjunto de artigos
- Analisar as estruturas, os objetos que queremos extrair desse tipo de texto. O watson utiliza a terminologia entidade. Exemplos de entidades: Pessoa, Autor, Cliente, Fornecedor, Quantidade, etc.
- Catalogar as entidades a serem identificadas e extraídas dos documentos.
- Treinar o Watson a reconhecer essas entidades nos textos através de marcações. O Knowledge Studio se refere a essas marcações como “Anotações ou Human Annotators”. Nada mais é do que apontar o Watson para um cachorro, e falar: “Isso é uma espécie de cachorro, Watson. É muito importante para mim que você identifique espécies deste animal”.
Busca Knowledge Studio no Catálogo
Logado no IBM Cloud, busque por Knowledge Studio no Catálogo e clique nele.
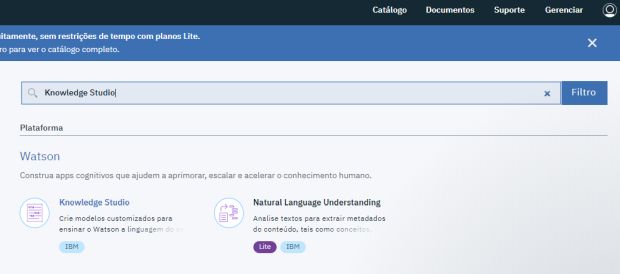
Para ter acesso aos recursos do Knowledge Studio, você precisará informar o número do seu cartão, mas você não irá ser cobrado enquanto não extrapolar o limite do plano free de acordo com o sistema de pagamento Pay-as-you-go.
Clique em atualizar e preencha as informações.
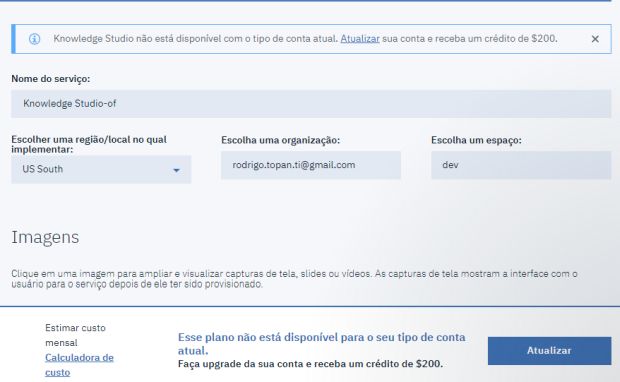
Ao realizar o upgrade, você terá acesso ao Knowledge Studio. Verifique o local, organização e espaço e instancie seu Knowledge Studio, clicando em ‘Criar’.
Clique em launch para ter acesso à plataforma. Você será redirecionado para o gateway e possivelmente irá demorar um pouco até a plataforma abrir.

Desenvolvimento do modelo customizado
Nessa etapa, iremos desenvolver nosso próprio modelo de machine-learning para extração de dados de textos não estruturados.
Create Workspace: Clique em create workspace, nomeie o seu workspace, escolha a linguagem dos documentos com o qual o Watson irá trabalhar e clique em create.
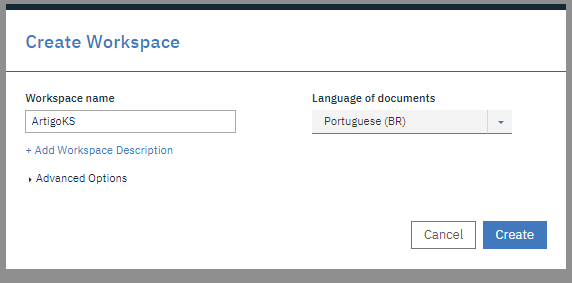
Importar Dataset para treino: Já dentro do seu workspace, no menu lateral dentro de Assets e Tools, clique em documents e em documents, clique em Upload Documents Sets.
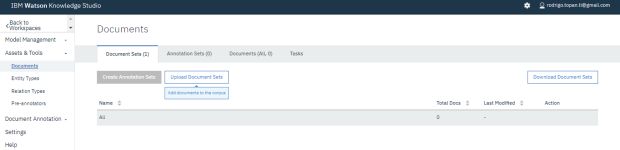
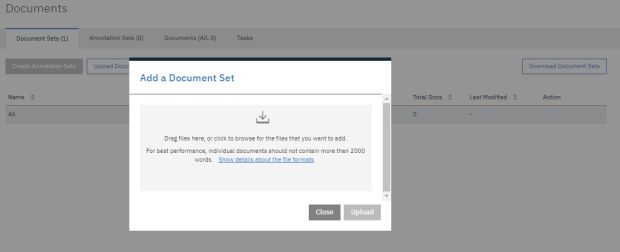
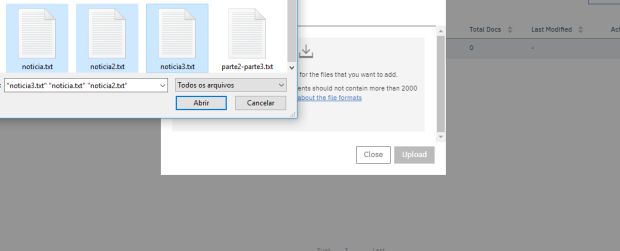
Clique no ícone no centro do modal e selecione os arquivos do seu computador que servirão de treinamento para o nosso modelo de machine learning ou arraste e solte os arquivos do dataset para o centro do modal. Para o meu dataset de treino, importei textos de notícias do canaltech. Os arquivos texto devem possuir codificação UTF-8.
Após isso, clique em upload.
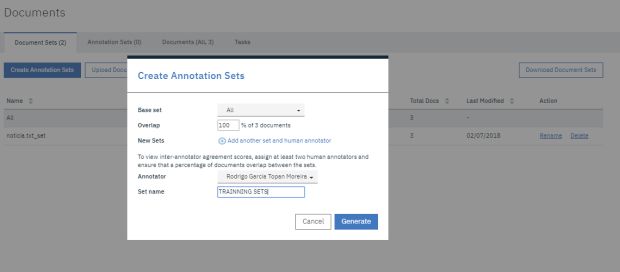
Create Annotation Sets: Clique em ‘Create Annotation Sets’ para apontarmos os documentos que poderão ser usados pelo modelo do Watson.
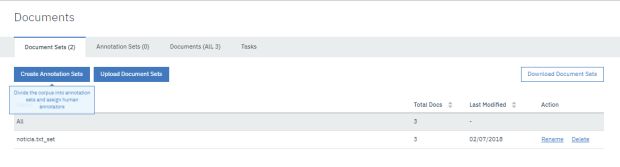
Após clicar em ‘Create Annotation Sets’ precisaremos configurar o usuário que terá permissão para fazer as anotações (marcações) nos documentos. Os annotations sets são grupos de marcação de documentos para o treinamento do modelo. Clique em generate para gerar o conjunto de anotações.
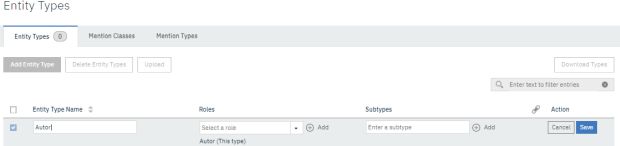
Criar Entities: Dentro de Assets e Tools, no menu lateral e embaixo de documents, clique em entity types para a criação das entidades que deverão ser identificadas pelo modelo de machine learning. No meu modelo, identificarei autores, título e data de notícias.
Clique em new entities, informe o nome para o nosso modelo, salve a entidade sem subtype e as roles ficarão com o mesmo nome da entidade, clique em save.
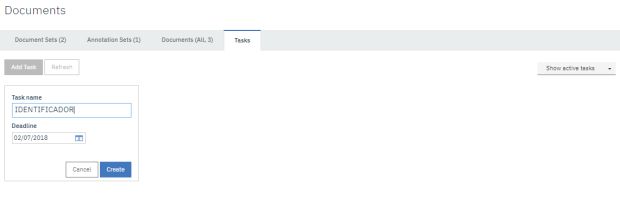
Task – Identificação (Human Annotation) de entidades: Agora, devemos criar a task. A tarefa que o nosso modelo deverá executar. No caso, a identificação das nossas entidades.
Para começar, clique em ‘Add Task’, nomeie a tarefa e aponte uma data no futuro em deadline para adicionar uma nova tarefa que será o nosso identificador de entidades em documentos de textos não estruturados.
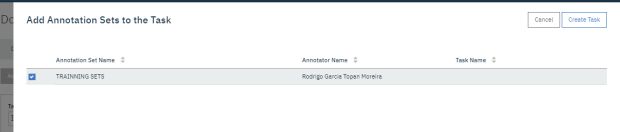
Precisamos relacionar agora, o conjunto de documentos de um annotation set a uma tarefa (task) para que esta treine em cima destes documentos do set. Selecione o seu annotation set e clique em ‘create task’.
Realizando Marcações: com a nossa tarefa (task) criada, iremos configurar as marcações de cada documento. Selecione a task.
Clique em ‘Annotate’ do lado direito da tabela na coluna ‘Action’.
Selecione o documento que você deseja realizar as marcações.
Selecionado um dos documentos, selecione então uma entidade e relacione ela ao seu respectivo valor através das marcações. É muito importante que todas marcações sejam relacionadas corretamente com os seus respectivos valores para que o nosso modelo realize interpretações corretas após treinado. Espaço = Marcar, Del = Remover Marcação. Ao fim, clique em save para salvar o progresso de marcação do usuário. Repita esse processo para todos os documentos.
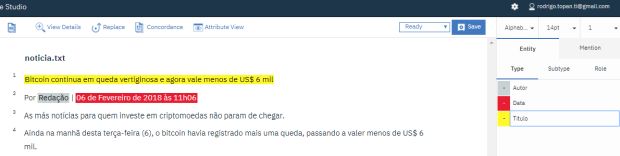
ATENÇÃO: Revise todas as suas marcações e de todos os documentos. Tendo certeza, clique em ‘Submit All Documents’. As marcações terão seu status alterados para ‘Completed’. Uma vez neste status, a plataforma NÃO permite alterações. Tenha muita atenção. O erro nesta etapa resulta na necessidade de deleção da task e o processo de marcações deverá ser refeito.
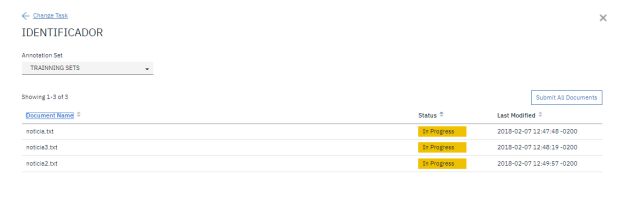
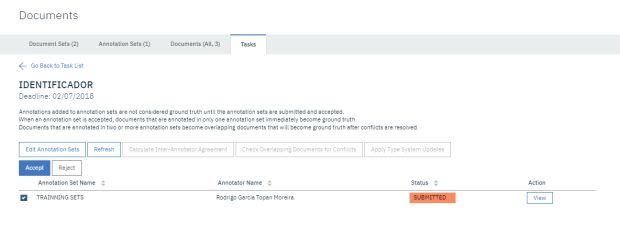
ATENÇÃO: Dentro de Documents novamente, em Tasks, clique na sua Task, selecione o conjunto de arquivos já marcados e revise eles novamente se necessário ou aprove o conjunto clicando em Accept. O erro nessa etapa resulta na necessidade de que o modelo seja recriado inteiramente.
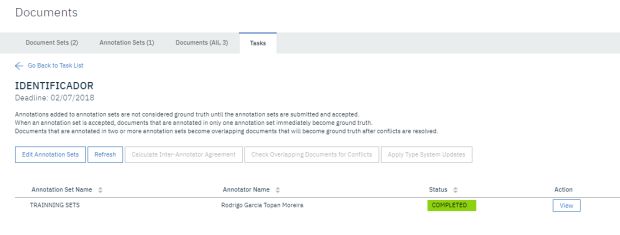
Se o status estiver como ‘Completed’, significa que você já possui todos os itens para realizar o treinamento de seu modelo.
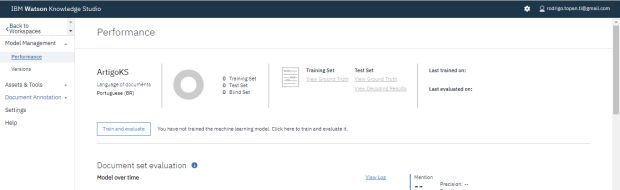
Treinamento de modelo
Dentro de ‘Model Management’, em Perfomance, clique em ‘Train and Evaluete’.
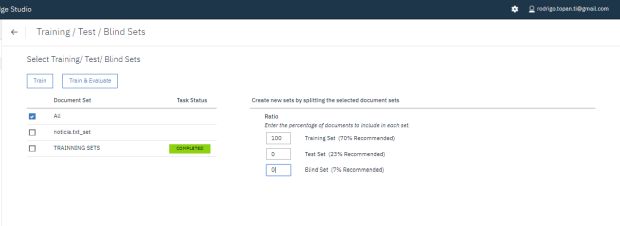
Ao clicar em ‘Train and Evaluete’, você deverá ter uma tela como essa abaixo. Nesta tela você diz ao Watson para realizar o treinamento com base em seus conjuntos de arquivos marcados. Além disso, como realizaremos o treinamento do nosso modelo com poucos arquivos, para obtermos melhores resultados, devemos disponibilizar nosso conjunto inteiramente para o treinamento e nenhum arquivo para os testes setando-os da seguinte forma:
Geralmente para treinamento e testes de modelos de machine learning, é recomendado 70% do conjunto de arquivos para treinamento e 30% do para os testes.
Trainning Set = 100
Test Set = 0
Blind Set = 0
Com tudo configurado corretamente, clique em Train e o processo de treinamento do nosso modelo customizado será processado pelo Watson. Esse processo deve demorar um pouco.
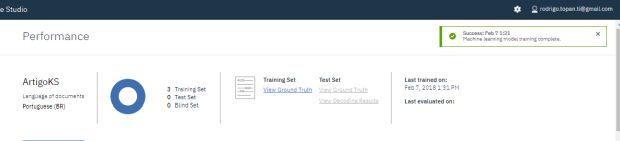
Se tudo ocorrer bem, você conseguirá visualizar uma mensagem verde ao canto superior direito da tela dizendo que o modelo foi treinado com sucesso. Se algo der errado, você receberá um erro e deve mapear todo o seu processo de criação do modelo, verifique se não esqueceu nada ao longo do processo, se todos os documentos foram marcados e se a barra de progresso da sua task se encontra em 100%.
Publicação/deploy
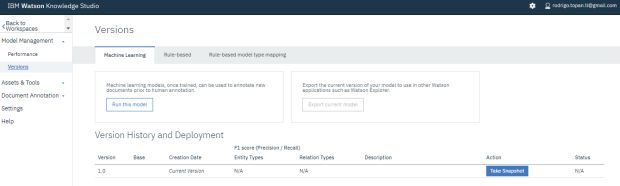
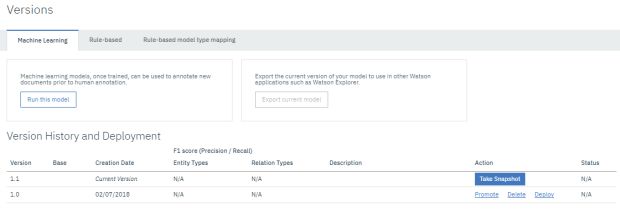
Na etapa final para publicação do nosso modelo, no menu lateral esquerdo, dentro de ‘Model Management’, em Versions, devemos clicar em take snapshot na tabela abaixo, na coluna ‘Action’.
Clicar em ‘OK’.
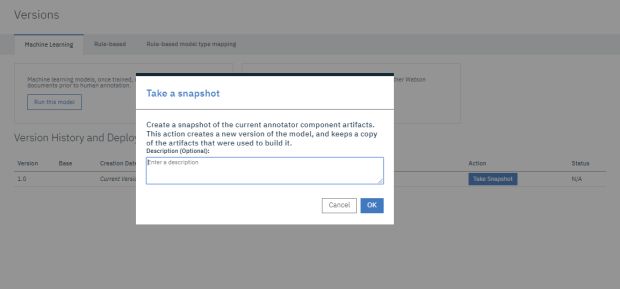
Agora devemos clicar em deploy em ‘Action’, na nova linha gerada proveniente do ‘Snapshot’.
O Watson então pergunta qual serviço iremos relacionar nosso modelo customizado já treinado. Mas isso é assunto para a parte 2 deste artigo, o qual explicarei como relacionar o seu modelo com o serviço Natural Language Understanding.
Próximos passos: Natural Language Processing/ Watson Api Explorer.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?