

Flux, Redux, Mobx, State e outra sopa de letrinhas…
Se você não viveu dentro de uma bolha, uma caverna ou ilha deserta totalmente desconectado das notícias nos últimos 2 anos (pelo menos), com certeza deve ter notado que a todo momento é falado algo sobre Flux, Single Direction Data Flow, Redux, Mobx, gerenciamento de estado e assuntos similares, na comunidade front-end em geral – seja através de algum post, alguma palestra ou de alguma nova biblioteca JS que saiu por aí.
Mas será mesmo que é importante discutirmos sobre isso? Você consegue falar sobre as diferenças de Flux e Redux? São a mesma coisa? Será que posso utilizar nos meus projetos? Será que meus projetos necessitam disso? Esta série tem como objetivo responder a estas (e outras) perguntas.
Neste primeiro artigo da série, vamos entender por quê o Flux surgiu, os elementos da arquitetura e suas características.
Uma situação bem comum
Antes de explicar ou trazer qualquer conceito, queria apresentar algumas situações, que nós, desenvolvedores, passamos inúmeras vezes em nossas rotinas de trabalho, seja quando criamos novas soluções ou apenas dando manutenção em algum projeto já existente:
- Quando temos que realizar algum tipo de alteração em um projeto, perdemos boa parte do tempo entendendo como o fluxo da aplicação funciona, a arquitetura do projeto e toda a estrutura de código, do que de fato implementando a funcionalidade que queríamos fazer;
- Quando vamos corrigir algum bug e percebemos que, por alguma razão, aquela ação no sistema acaba gerando uma sequência de ações em cascata na aplicação;
- Quando vamos implantar alguma feature e não temos noção de que vamos gerar mudanças em outras partes do sistema.
Tenho certeza de que alguma destas situações já aconteceu (ou acontece) com você também. O caso ainda mais grave é quando ocorrem mudanças que acabam gerando um estado inconsistente na aplicação. Podemos acabar mostrando alguma informação errada, não concluir alguma ação que o usuário queria fazer, ou realizar uma ação diferente da que o usuário solicitou. São infinitas as possibilidades…
E será que precisa ser sempre assim? Como realizar alterações em nossa aplicação, sem produzir estados inconsistentes? Existe uma forma melhor para conseguirmos entender rapidamente a estrutura do projeto? É possível gerenciar os estados da aplicação e torná-los previsível?
Um fato inquestionável
Tudo isso sobre esta precaução em não gerar comportamentos indesejáveis, ou dificuldade em manutenção da aplicação, se explica muito porque desenvolvolver software é complexo. Seja ele um Hello World, ou um aplicativo de redes sociais, existem inúmeras variáveis e fatores em volta desta atividade: entendimento do problema a ser resolvido; planejar a estrutura de dados; criar uma estrutura de código que possibilite uma evolução do sistema; escalabilidade; performance; experiência do usuário; lidar com prazos e demandas; a própria complexidade da implementação, entre outros.
Toda essa complexidade, que antes era mais presente no back-end, também pode ser notada do lado do front-end. Com o advento das aplicações do tipo SPA e outras evoluções do HTML5, CSS e JS, temos muito mais coisas para nos preocupar em nossa aplicação: routing, interação do usuário com a aplicação, interação com API, prover dados offline e a posterior sincronização desses dados…
Tudo isso altera o estado da aplicação: o que ela vai apresentar ao usuário e como ela vai se comportar mediante alguma ação.
Padrões de software e arquitetura
Para manter uma aplicação com manutenção facilitada, com escabilidade, com códigos bem escritos e de fácil entendimento para todos os colegas do seu time, vamos pensar em muitos princípios de engenharia de software e padrões de arquitetura. Sem dúvida alguma, o padrão de arquitetura mais conhecido e utilizado em muitos projetos, é o MVC.
Tenho certeza que você já viu, tem noção ou trabalha em projetos que utilizam este modelo. O modelo MVC (Model-View-Controler) foi criado na década de 1970, com a proposta de separação da interface do usuário, com as regras de negócio do sistema. Repare que, nesta época, não existia tanta interação com a interface como temos hoje (nem preciso mencionar as interações do usuário via mobile neh?!), e ainda assim, já existia este grande conceito de separação das responsabilidades. Caso você nunca tenha tido contato com o MVC, ou não saiba o que é isso, este artigo vai te ajudar, mas, apenas para entendimento deste artigo, vou fazer uma breve explicação dos elementos do modelo:
- A camada Model: É a camada que possui todas as regras de negócio da aplicação, onde devem ficar todo o conjunto de regras de acesso aos dados da aplicação, representando, assim, às informações (ou dados) da aplicação. Ela não deve ter conhecimento de quais serão as interfaces que serão atualizadas (as views), ele apenas deve possuir acesso aos dados da aplicação e fornecer meios para que o Controller tenha acesso a eles;
- A camada View: É a camada de apresentação e quem deverá exibir os dados da camada Model, ao usuário final. É esta camada que possibilita a interação do usuário com todo o sistema, possibilitando a entrada e a saída de dados, permitindo a visualização das respostas geradas pelo sistema. A View deve ser reflexo do estado do modelo, então, caso ocorra alguma mudança nos dados do modelo, este deverá notificar as suas respectivas views de alguma forma, para que elas possam exibir os novos dados do modelo. As views não devem conter códigos relacionados à lógica de negócios. Elas somente devem se preocupar com a apresentação dos dados contidos no model;
- A camada Controler: É a camada de lógica, é quem faz a ligação da camada Model, com a camada View. É responsável por fazer as manipulações dos dados da camada model e enviá-los para a camada view. Sendo assim, ele gerencia o envio de requisições feitas entre a view e o model. Ela define todo o comportamento e funcionamento da aplicação, quem interpreta as ações feitas pelos usuários da aplicação.
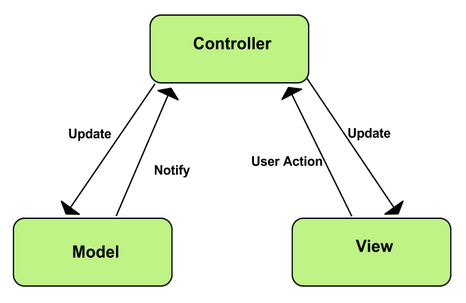
Mesmo tendo sido criado mesmo antes da popularização da Web, existem alguns fatores que o tornaram marcantes e fez este modelo ser tão consagrado. Alguns deles, por exemplo:
- Separação de responsibilidades: conceito este que utilizamos a todo momento, cada coisa deve ser responsável apenas por saber resolver aquela parte do problema.
- Altamente flexível: o modelo permite criar variações em sua estrutura, como podemos citar o MVP e o MVVM.
- Fácil implementação: todas as linguagens oferecem algum meio, seja nativamente ou por bibliotecas, para se trabalhar com ele.
- Desenvolvimento do software de forma paralela: por causa de sua estrutura, ele trouxe a possibilidade de uma parte da equipe trabalhar na parte de interface, enquanto outro membro cuidava da lógica e regras de negócio.
A medida com que as aplicações Front-End se tornaram mais complexas (devido ao advento das SPAs e da própria evolução do HTML5, CSS e JS), houve a necessidade de adotarmos padrões para melhor a organização do projeto, e a maioria das bibliotecas ou frameworks tornaram possível a utilização do MVC do lado do front-end (já que antes, só era possível em alguma linguagem server side). Podemos citar aqui como exemplo, o Angular JS, Backbone e o Ember JS.
Algumas diferenças no front-end
Contudo, existem algumas diferenças, em como a aplicação funcionava internamente com a arquitetura MVC. Algumas delas são:
- O tão famoso Two Way Data Binding (que é o efeito de você poder ver o valor atual de um elemento, a medida que o usuário digita o valor desejado), só funciona porque model acaba notificando a view sobre as mudanças daquele valor, ou seja, cria-se um caminho bidirecional, onde o model notifica a view e vice-versa.
- As ações na view podem acontecer por vários pontos, não existe um único ponto de entrada (como um router por exemplo), onde toda a ação dentro do sistema se inicia passando por aquele único local.
Além disso, um dos elementos mais notórios, em qualquer aplicação MVC, é que a medida que a aplicação cresce e mais camadas são adicionadas, demora-se muito tempo para se estabelecer um fluxo de uma determinada ação.
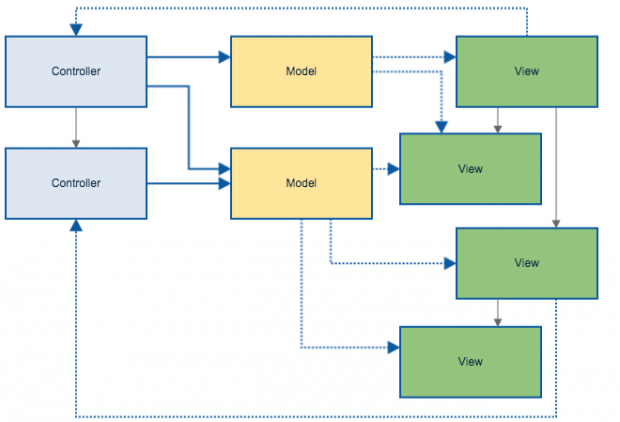
Tenho certeza de que você levou um certo tempo para entender como a aplicação da imagem acima funcionava. E isto se deve ao próprio funcionamento do modelo. Quanto mais a aplicação cresce, e mais camadas são adicionadas e demora-se um certo tempo para o entendimento do sistema.
Não somente isso: a medida que a aplicação cresce e fica mais complexa, temos a necessidade de adicionar mais camadas ao modelo. Como consequência, ao adicionar mais e mais camadas, torna-se difícil mapear as ações realizadas na aplicação. Imagine-se corrigindo algum bug cuja estrutura da aplicação seja como a imagem abaixo:
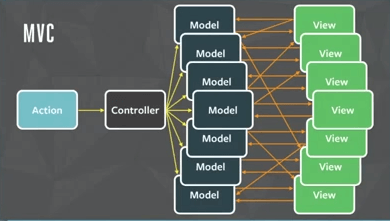
Como é difícil visualizar o fluxo da aplicação, e por consequência difícil mapear as ações realizadas na aplicação, é bastante complicado de se reproduzir alguns problemas e comportamentos. Principalmente quando existem ações que geram mudanças em cascata no seu projeto, ou seja, uma ação em algum ponto do sistema, acaba por atualizar e modificar diversos dados em outra parte do sistema, que gera uma nova visualização destes dados para o seu usuário. Neste contexto, é muito difícil prever como a aplicação irá se comportar mediante alguma ação realizada. Logo, a sua aplicação se torna imprevisível. Em uma aplicação assim, é difícil reproduzir comportamentos, testar, implantar novas funcionalidades e corrigir problemas. Então, como fazer para levar a aplicação ao “próximo nível”, tornando-a mais previsível?
Todas estas situações relatadas foram observadas pela comunidade, e o Facebook observou estes problemas em sua aplicação de chat: eles notificavam os seus usuários de que existiam novas mensagens, porém, quando o usuário clicava sobre o ícone de notificações, não existia nenhuma nova mensagem a ser lida.
Tendo identificado todos estes problemas, e com o mindset de que eles queriam que todas as aplicações fossem mais fácil de serem entendidas por seus desenvolvedores, para que eles pudessem criar features de uma forma mais rápida, e que o fluxo da aplicação fosse rapidamente entendido, decidiram apostar em um novo modelo de arquitetura, que tornasse a aplicação mais previsível. Nasce, então, o tão famoso Flux.
Neste vídeo, você verá a palestra apresenta pelo time de engenharia do Facebook reportando estes problemas e apresentando a arquitetura Flux, entre outras novidades.
Flux: o que é isso?
Apresentado por Jing Chen (considerada a criada do Flux), na conferência do time de engenharia do Facebook, a nova arquitetura era fundamenta no conceito de Single Direction Data Flow, que traduzindo para o português, fica Fluxo Único de Dados. Sua arquitetura é baseada nos seguintes elementos: Action, Dispatcher, Store e View.
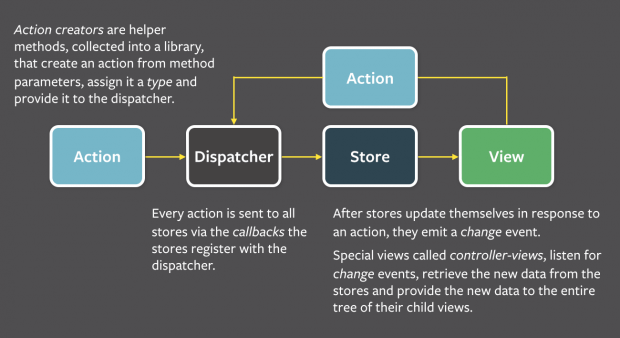
Apesar de fazerem parte da arquitetura, o Dispatcher, a Store e a View são partes totalmente independentes, que por sua vez trabalham com dados de entrada e saídas distintos. Para explicar cada um dos elementos, vamos imagine que queremos criar um contador: teremos na nossa interface o seu número (valor) e dois botões,um para adicionar valor ao contador e outro para retirar valor do contador.
- As Views são responsáveis por permitir a interação do usuário com a aplicação, e por mostrar a ele o estado atual de nossa aplicação (em nosso exemplo, nossa view irá exibir o valor do contador, que inicialmente pode ser o valor zero, e os dois botões, que irão adicionar e retirar valores do contador);
- As Actions são as ações que o usuário realiza na interface (Views). Quando é solicitada alguma ação, elas são representadas por objetos que apenas possuem as novas informações a serem salvas pela aplicação (no nosso exemplo, a action conteria o tipo da ação realizada: ADICIONAR_AO_CONTADOR ou RETIRAR_DO_CONTADOR, e o valor a ser adicionado, que neste exemplo, será sempre o valor 1);
- O dispatcher simplesmente se encarrega de enviar todas as ações para todas as Stores da aplicação. Ele não possui nenhum conhecimento sobre as regras de negócio e como atualizar o valor contido nas Stores;
- Cada Store é responsável por um domínio da aplicação e somente se atualizam mediante em resposta às actions. É nela que esta contida toda a lógica de implementação das actions (em nossa aplicação, aqui estará contida a lógica para adicionar um valor ao nosso contador, caso a action disparada seja do tipo ADICIONAR_AO_CONTADOR, como também a lógica de retirar um valor do contador, caso a action disparada seja do tipo RETIRAR_DO_CONTADOR). Após a realização dos algoritmos de cada ação, nossa aplicação passa a ter um novo estado. Este novo estado (que na nossa aplicação, seria o novo valor do contador) passa a ser então renderizado na view. Caso aconteça uma nova action na view (no nosso exemplo, adicionar ou retirar um elemento do contador), todo o fluxo se repete.
Sei o que você provavelmente esta pensando: aah Yan, mas este exemplo é simples. Se a aplicação crescer e eu adicionar novas views e novas stores, terei as mesmas situações permitidas pelo MVC
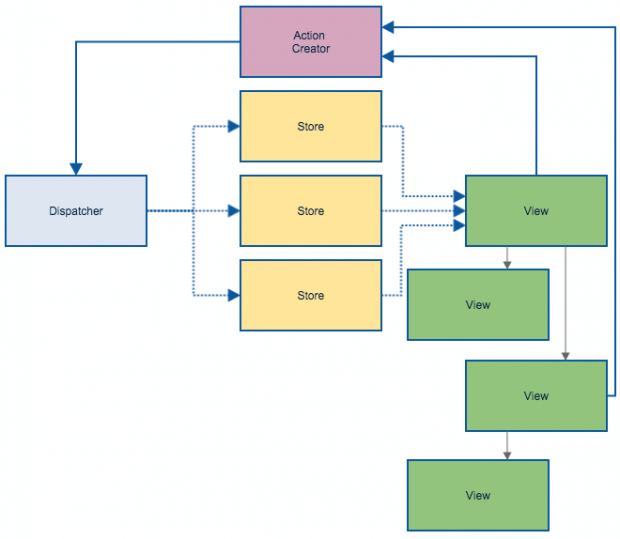
Ou seja, mesmo adicionando novos elementos, o princípio do Single Direction Data Flow se manteve. Como isso é possível? Algumas razões:
- O Dispatcher é único para toda a aplicação: só existe um único elemento responsável por receber as actions realizadas nas views e dispará-las para as stores da aplicação.
- Toda e qualquer mudança no estado da aplicação somente pode ser realizada através de uma action.
Algumas características
Além dos itens comentados acima, algumas características da arquitetura flux:
- Fluxo único de dados: é o maior princípio da arquitetura;
- Sem alterações em cascata: as actions são únicas, e a cada action realizada, é gerado um novo estado na aplicação.
- Previsível: é muito fácil saber qual será o estado da aplicação, mediante uma ação realizada. Basta colocarmos a aplicação em um estado “X”, realizar a ação desejada, e conferimos se ela levou a aplicação ao estado “Y”. Logo, a aplicação é muito mais fácil de ser testada.
- Ações mais semânticas e descritivas: como todas as actions possuem um tipo, é muito fácil identificar quando a action é chamada, e qual tipo de mudança ela causa no estado. O código fica muito mais explícito.
- Toda a lógica esta concentrada em um único local, nas stores (em nossa aplicação de contador, por exemplo, caso existisse algum bug ao adicionar valor ao contador, nos bastaria ir a Store cuja action ADICIONAR_AO_CONTADOR estivesse sido implementada).
- Pode ser usado em pequenas e grandes aplicações.
- View != REACT: Apesar de ter sido criado pelo Facebook e todos os exemplos da documentação serem em React, você pode usar qualquer outra biblioteca ou framework em sua view, como Angular, Polymer (que em breve teremos posts dele aqui no blog \o/), VueJS e outros.
Ufaa, muita coisa não? Este primeiro artigo acabando ficando um pouco extenso, mas acredito que avançamos bastante no entendimento deste novo conceito. Entender como a arquitetura Flux funciona é a base para se trabalhar com as bibliotecas que a implementam, seja o Redux, Mobx ou qualquer outra biblioteca de container de estados.
No próximo artigo da série, teremos um review de como a arquitetura Flux funciona e vamos ver uma aplicação utilizando a arquitetura. Também veremos como foi a adoção da comunidade a esta arquitetura e um exemplo da primeira biblioteca que foi bastante utilizada para gerenciamento de estados: o Alt JS.
Para finalizar, vou procurar sempre deixar alguma mensagem de incentivo, sobre algo que li e que achei útil em algum momento, seja um livro ou alguma frase de algum autor.
Não caia na Síndrome da Gabriela: eu nasci assim, eu cresci assim, eu vou ser sempre assim. Você tem o poder de controlar a sua vida. – Livro Geração de Valor, primeira edição.
Gostou do artigo? Falei alguma besteira? Deixe sua opinião nos comentários, ela é muito importante.
Compartilhe o artigo com seus amigos nas redes sociais, e com os coleguinhas do trabalho.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?