

Nos últimos anos, o Uber experimentou um período de hipercrescimento, expandindo o serviço para mais de 550 cidades ao redor do mundo. Para acompanhar, nosso time móvel também precisou crescer. Em 2014, tínhamos pouco mais que uma dúzia de engenheiros de aplicativos móveis trabalhando em nosso app iOS. Hoje, nossa equipe tem centenas. Como resultado, nossas ferramentas para desenvolvimento móvel passaram por grandes mudanças para suprir as demandas dessa equipe maior e mais dinâmica.
Na conferência @Scale em setembro, nós apresentamos como a engenharia do Uber cresceu desde o início. Aqui, vamos focar de maneira mais profunda em por que tivemos que mudar para um repositório móvel monolítico simples (monorepo) – à primeira vista, aparentemente em contraste com nossa migração monolítica para uma arquitetura de infraestrutura de microserviços – e como isso mudou a engenharia móvel do Uber para melhor.
Antes do Monorepo
Vamos dar um passo atrás e examinar o estado do mundo do desenvolvimento iOS do Uber antes do Monorepo. No iOS, nós confiávamos completamente em uma ferramenta open source chamada CocoaPods para construir nossas aplicações. O CocoaPods é um gerenciador de pacotes, solucionador de dependências e ferramenta de integração, tudo em uma. Ele permite que os desenvolvedores integrem rapidamente outras bibliotecas às suas aplicações sem a necessidade de configurações complexas do projeto em Xcode. O CocoaPods também soluciona dependências utilizando como alvos os ciclos nos gráficos de dependências que possam levar a erros na hora da compilação. Como ele é o gerenciador de pacotes mais popular para o Cocoa, muitos frameworks de terceiros dos quais dependíamos estavam disponíveis apenas via CocoaPods. Além do mais, a popularidade do CocoaPods significava que os problemas com a ferramenta eram rapidamente corrigidos, ou reconhecidos rapidamente por seu time de colaboradores.
Enquanto nossa equipe e nossos projetos eram pequenos, o CocoaPods nos serviu bem. Nos primeiros anos do Uber, construímos a maioria das nossas aplicações com uma biblioteca simples compartilhada e algumas bibliotecas open source. Os gráficos de dependência normalmente eram pequenos, então o CocoaPods conseguia resolver nossas dependências rapidamente e com pouca dor para os desenvolvedores. Isso nos permitia focar na construção do produto.
Modularizando a base de código
No fim de 2014, a biblioteca compartilhada da engenharia do Uber tinha se tornado um depósito de códigos sem uma organização concreta. Por tudo estar potencialmente somente a um “Importar” de distância, nossa biblioteca compartilhada tinha o efeito de permitir que componentes e classes aparentemente independentes dependessem uns dos outros. Naquele ponto, havíamos reunido muitos anos de códigos de missão crítica sem testes unitários, e uma API que não envelheceu bem. Sabíamos que poderíamos fazer melhor, então embarcamos em um esforço para modularizar nossa base de código e simultaneamente reescrever as partes principais dos nossos aplicativos (como Networking, Analytics e outros).
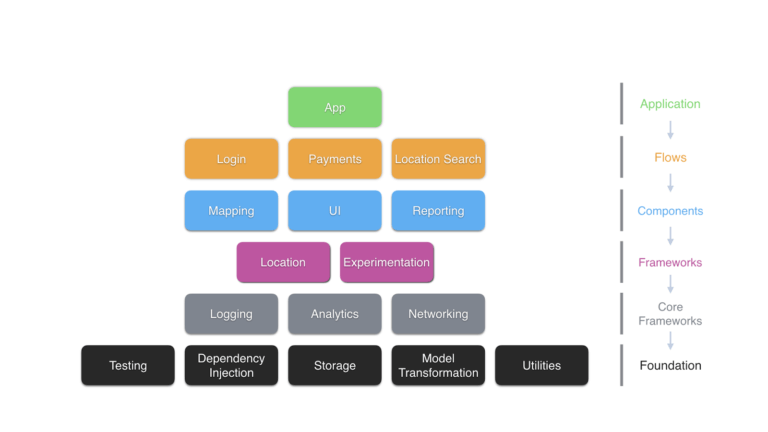
Para fazer isso, transformamos todas as partes críticas de nossos aplicativos em componentes como blocos de construção que qualquer aplicativo do Uber poderia utilizar. Nós chamamos esses frameworks de módulos, e cada módulo estava armazenado em seu próprio repositório. Essa modularização nos permitiu liberar protótipos de aplicativos quando precisamos, assim como alavancar a produção real de software. A propósito, quando decidimos lançar o UberEATS como um aplicativo separado no fim de 2015, a equipe do UberEATS teve uma pesada influência nos novos módulos que construímos. Os engenheiros puderam utilizar a maior parte do tempo trabalhando no produto, em vez de nos requisitos de plataforma. Por exemplo, construímos um conjunto de ferramentas de UI que implementou a tipografia, esquema de cores e elementos comuns de UI que os designers da empresa utilizaram em nossos aplicativos móveis.
No início de 2015, tínhamos cinco módulos. No início de 2017, temos mais de 40, que vão de bibliotecas em nível de framework (tais como networking e logging) para bibliotecas de produtos específicos (como mapeamento e pagamento), compartilhadas entre as aplicações. Os três aplicativos (Rider, Driver e EATS) são baseados nessa infraestrutura compartilhada. As correções de bugs e as melhorias de desempenho em nossos módulos são imediatamente refletidas nas aplicações que os utilizam – um grande benefício dessa configuração. No geral, nosso esforço para a modularização foi um grande sucesso.
Mas conforme crescemos de cinco para mais de 40 módulos, nos deparamos com alguns problemas. Percebemos que tivemos um período difícil para escalar o CocoaPods devido à quantidade de módulos que tinham suas interdependências. Ao mesmo tempo, mais de 150 engenheiros se juntaram ao nosso time de iOS, o que significava que nossas aplicações e módulos estavam em um estado de constante evolução.
Hora de mudança
Como a empresa continuou crescendo, nossa engenharia começou a mudar. Assim que começamos a integrar muitas bibliotecas a mais em nossas aplicações, nós rapidamente atingimos o limite das capacidades de resolução de dependências do CocoaPods. No início, o tempo de instalação de nossos pods estava abaixo de 10 segundos. Então, aumentou para minutos. Nosso gráfico de dependências era tão complexo que nossos engenheiros gastavam, coletivamente, horas todos os dias, esperando o CocoaPods solucionar o gráfico de dependências e integrar nossos módulos. Essa perda de tempo era ainda pior em nossa infraestrutura de integração contínua.
Também sentimos a pressão de uma abordagem de múltiplos repositórios. Cada módulo estava armazenado em seu próprio repositório, e qualquer módulo poderia depender de muitos outros módulos. No entanto, com uma mudança dentro de um módulo, era necessário atualizar o Podfile da aplicação antes que a mudança pudesse aparecer. Grandes problemas nas mudanças exigiam a atualização de todos os módulos que dependiam daquele em a mudança foi realizada.
Como precisávamos versionar todos esses módulos para integrá-los, adotamos a convenção de versionamento semântico para marcar nossos módulos. Enquanto o versionamento semântico é um conceito simples, o que constitui problema na mudança, na realidade, pode variar de acordo com as diferentes configurações do compilador.
Como resultado, uma mudança de código aparentemente inofensiva em um módulo pode causar erros (ou avisos, que são tratados como erros em CI) em outros módulos ou aplicações dependentes. Como um exemplo, considere o seguinte fragmento de código (alguns clichês removidos para facilitar):
[cod]
À primeira vista, pode parecer que adicionar uma nova propriedade ao KittenProtocol não deveria apresentar nenhum erro fora do seu módulo. Mas poderia, dependendo dos níveis de controle de acesso do protocolo. Qualquer um poderia se adaptar ao protocolo se o deixássemos publicamente acessível fora do módulo (vamos chamar esse módulo de “UberKittens” porque parece o apt). Adicionar uma nova propriedade, então, causaria um problema na mudança porque as propriedades de um protocolo devem ser implementadas em conformidade com a sua classe ou estrutura.
Mesmo adicionar um novo caso à enumeração do KittenType pode constituir um problema. Novamente, desde que tornamos a enumeração pública, qualquer declaração existente que a utilize apresentará um erro de compilação para o novo caso que não está sendo tratado.
Os problemas acima são mínimos e podem ser resolvidos facilmente por qualquer consumidor do módulo UberKittens. Mas a única maneira de tornar essas mudanças seguras no mundo do versionamento semântico é fazer o caminho conter uma versão acima. Temos centenas de engenheiros e centenas de mudanças acontecendo em certos dias. É impossível detectar todos os possíveis problemas nas mudanças. Adicionalmente, atualizar qualquer biblioteca da qual nossa biblioteca dependa poderia trazer dúzias de avisos no código, que você teria que resolver.
Nós realmente queríamos que nossos engenheiros pudessem ser mais rápidos e realizar as alterações necessárias sem terem que se preocupar com os números das versões. Resolver conflitos de versões era frustrante para os desenvolvedores e, como mencionado anteriormente, o CocoaPods tinha se tornado muito lento para resolver nossas, agora complicadas, dependências. Nós também não queríamos que nossos engenheiros passassem dias atualizando módulos no gráfico de dependências para ver suas mudanças nas aplicações que entregamos.
Os engenheiros deveriam poder fazer toda e qualquer mudança que eles precisassem, com o mínimo de envios possível.
A solução? Um repositório monolítico.
Planejando o Monorepo
É claro, os repositórios monolíticos não são uma ideia nova; muitas outras grandes empresas de tecnologia os adotaram com grande sucesso. Apesar de colocar todo seu código em um repositório possa ter seus pontos negativos (desempenho dos VCS, erros que afetem todos os alvos etc.), os pontos positivos podem ser grandes, dependendo do fluxo do desenvolvimento. Com o Monorepo, nossos engenheiros puderam fazer as mudanças que se espalham pelos módulos atomicamente, em somente um envio. Sem números de versão para se preocupar, resolver os gráficos de dependência seria muito mais simples. Como somos uma empresa com centenas de engenheiros em muitos times diversos, poderíamos centralizar todo nosso código para iOS em um único lugar, tornando mais fácil a descoberta.
Não poderíamos deixar passar esses benefícios, então sabíamos que precisávamos do Monorepo. No entanto, não tínhamos certeza sobre qual ferramenta utilizar para lidar com ele. Assim que iniciamos nosso esforço de modularização, consideramos construir o Monorepo com o CocoaPod. Mas isso teria significado ter que construir cada aplicação e cada módulo para cada mudança de código que um engenheiro pudesse colocar para revisão. Queríamos ser mais espertos sobre construir apenas o que mudasse, mas isso teria significado investir milhares de horas de engenharia em uma ferramenta que poderia, de maneira inteligente, reconstruir somente as partes que tivessem sido alteradas.
Com sorte, surgiu uma ferramenta que pode fazer isso (e mais), e ela é chamada de Buck.
Buck salva o dia
Buck é uma ferramenta construída para repositórios monolíticos que pode construir códigos, rodar testes unitários e distribuir os artefatos construídos para as máquinas para que outros desenvolvedores possam perder menos tempo compilando códigos antigos e mais tempo escrevendo códigos novos. O Buck foi construído para repositórios com módulos pequenos e reutilizáveis e tem como vantagem o fato de que todo o código está em um lugar para uma análise inteligente das mudanças do código e construir apenas o que for novo. Como é feito para velocidade, ele também aproveita as CPUs multi-core que nossos engenheiros têm em seus computadores, de forma que múltiplos módulos podem ser construídos ao mesmo tempo. O Buck pode até mesmo executar diferentes alvos de testes unitários ao mesmo tempo.
Tínhamos ouvido muitas coisas boas a respeito do Buck, mas não podíamos utilizá-lo até ele publicamente suportar projetos para iOS e em Objective-C. Quando o Facebook anunciou o suporte do Buck para iOS durante a conferência @Scale em 2015, ficamos empolgados para iniciar os testes do Buck em nossas aplicações.
Nossos testes iniciais mostraram que utilizar o Buck poderia melhorar bastante nossos tempos de desenvolvimento e testes no CI. Normalmente, quando utilizamos xcodebuild, a melhor abordagem é sempre limpar antes de construir e/ou testar. Qualquer host de CI poderia estar construindo os commits que estão no histórico do commit, o que significa que a cache sempre estará com fluxo. Por causa disso, a cache do xcodebuild pode ser instável (e a estabilidade do nosso CI tem alta prioridade). Mas se você tem que limpar antes de construir, os serviços do CI serão desnecessariamente lentos, uma vez que você não pode incrementalmente construir somente as novas mudanças. Então, nossos tempos de construção dispararam junto com nosso crescimento. Com centenas de engenheiros, as horas coletivas perdidas esperando o CI construir as mudanças dos códigos chegavam às centenas todos os dias.
Buck resolve esse problema com um cache confiável (e, opcionalmente, distribuído). Ele armazena agressivamente em cache artefatos da construção e também executará em tantos núcleos quantos estiverem disponíveis. Quando uma construção for concluída, não será reconstruída até que existam mudanças no código (ou em um dos módulos dos quais dependa). Isso significa que você pode determinar um repositório onde a ferramenta vai determinar de maneira inteligente o que precisa ser reconstruído e retestado, enquanto deixando todo o resto em cache.
Nossas máquinas de CI se beneficiam muito dessa arquitetura de cache. Hoje, quando um engenheiro realiza uma mudança de código que precisa ser reconstruída, aqueles artefatos de construção são distribuídos nas futuras construções naquela máquina e nas outras. Os engenheiros podem economizar ainda mais tempo utilizando os artefatos já construídos no CI localmente para suas construções também. Nós recentemente abrimos o código de uma implementação do Buck´s HTTP Cache API para utilização das equipes.
O Buck também oferece outros benefícios. Podemos remover uma causa comum de conflitos de combinações e a frustração dos desenvolvedores utilizando o Buck para gerar os arquivos Xcode do nosso projeto. Isso permite que cada aplicação iOS no Uber compartilhe um conjunto comum de configurações de projeto. Os engenheiros podem facilmente revisar o código e quaisquer alterações nas configurações, já que eles são arquivos de configuração de fácil leitura em vez de estarem enterrados em um arquivo de projeto Xcode.
Além disso, como o Buck é uma ferramenta totalmente madura, com suporte para construção e testes, nossos engenheiros podem verificar a validade de seus códigos sem nem abrir o Xcode. Os testes podem ser executados utilizando um comando, que executa os testes no xctool. Ainda melhor, se nossos engenheiros quiserem abandonar o Xcode completamente, eles podem abrir o Nuclide, que adiciona suporte para correções e a função de autocompletar ao editor de texto Atom.
A grande migração móvel
Como migramos para o Monorepo? A resposta é: com vários testes. Muito trabalho era repetido e determinístico, então escrevemos scripts para realizar o trabalho pesado para nós. Por exemplo, todos os nossos módulos consistiam em um arquivo podspec do CocoaPod. Nós publicamos esse podspec em um repositório interno e privado que o CocoaPod utilizava quando realizando as integrações. Esses podspecs podiam ser mapeados 1:1 em relação a um arquivo Buck (chamado “BUCK”), então escrevemos um script que gerava o arquivo BUCK e substituía o podspec.
Também criamos um Monorepo somente para testes que imitava a estrutura proposta de repositório utilizando links simbólicos. Isso nos permitiu testar facilmente a estrutura do Monorepo e a configuração, assim como atualizar os módulos conforme eles eram alterados.
No entanto, notamos que as mudanças nos módulos rapidamente deixavam o repositório de testes desatualizado. Tínhamos colocado os arquivos BUCK em todos os módulos, mas, enquanto isso, nossos engenheiros ainda precisavam utilizar os arquivos podspec. Então, precisávamos de uma maneira de manter os arquivos Buck e podspec sincronizados. Para fazer isso, nós carregávamos o repositório de testes para todos os módulos no CI e avisávamos nossos engenheiros quando suas mudanças causavam problemas em qualquer código ou módulo no repositório.
Essa estrutura ajudou os engenheiros a conhecerem o novo “Mundo Buck” que estava chegando enquanto também mantinha os arquivos BUCK atualizados. Na última semana antes da migração, nós fizemos isso para as aplicações também, para que os engenheiros soubessem que seus códigos quebraram as aplicações no universo Buck.
Construir o Monorepo real foi um esforço desafiador. Nós sabíamos que eventualmente teríamos que criá-lo, mas a questão era: quando? Originalmente, planejamos construí-lo no mesmo fim de semana em que fôssemos migrar toda a infraestrutura para a nova estrutura. Mas se pudéssemos fazer isso algumas semanas antes, nos pouparia o estresse adicional mais tarde. A migração era algo em que poderíamos utilizar scripts, já que os passos eram repetidos para todos os repositórios. Os passos comuns que seguimos para criar o monorepo foram:
1 – Clonar o repositório que seria combinado em um diretório temporário;
2 – Mover todos os arquivos desse repositório para o caminho correspondente no Monorepo;
3 – Submeter a mudança e movê-la para um ponto remoto com um nome específico;
4 – Entrar no Monorepo e adicionar o repositório a ser combinado como remoto;
5 – Combinar o ponto remoto ao Monorepo;
6 – Excluir o ponto remoto do repositório que foi combinado;
7 – Determinar a submissão que representa o cabeçalho do repositório que foi combinado. Submetê-lo para um arquivo oculto. Usaremos esse arquivo mais tarde, na hora de atualizar o Monorepo.
8 – Repetir os passos 1 ao 7 para o próximo repositório.
Assim que criamos o Monorepo, tivemos que descobrir como mantê-lo atualizado durante as próximas semanas. Fizemos isso utilizando o arquivo que criamos no passo 7. Como ele representava o HEAD de quando o Monorepo foi atualizado pela última vez de acordo com o repositório original, nós conseguíamos executar um script de hora em hora que criava uma anotação da última atualização no HEAD e então aplicava essa anotação no Monorepo no caminho correto.
A migração em si foi bem simples, e conseguimos realizá-la em um único fim de semana. Nós bloqueamos temporariamente todos os nossos repositórios na camada do git, mudamos todos os nossos serviços CI para executar os comandos Buck em vez do xcodebuild, e excluímos todos nossos arquivos Xcode e podspecs. Como passamos os últimos meses testando os projetos, nossos serviços CI e nosso canal de lançamento, nos sentimos confiantes quando lançamos o Monorepo em maio de 2016.
Os resultados: centralizando todo o código iOS
Com o Monorepo, nós centralizamos todo nosso código iOS em um único lugar. Organizamos nosso repositório nesta estrutura:
├── apps
│ ├── iphone-driver
│ ├── iphone-eats
│ ├── iphone-rider
├── libraries
│ ├── analytics
│ ├── …
│ └── utilities
└── vendor
├── fbsnapshottestcase
├── …
└── ocmock
Agora, uma mudança que cause problema em uma API no módulo analytics exigiria a atualização de todos os consumidores desse módulo na mesma execução. O Buck somente construirá e testará o analytics e módulos que dependam dele. Em contrapartida, não temos mais conflitos de versão, e sempre sabemos que o master está atualizado.
Os maiores benefícios do Buck, no entanto, vieram da mudança para o cache do Buck:
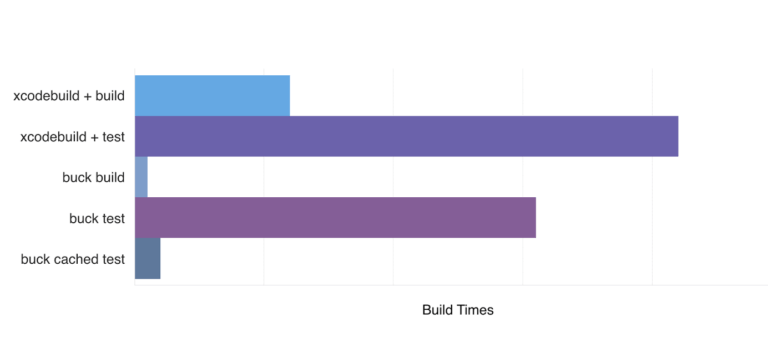
Deixe os programadores programarem. Nós reduzimos a tendência anterior de tempos cada vez maiores do xcodebuilder.
Comparando os passos do xcodebuilder com os do buck builder, vimos um grande ganho, pois não estamos mais limpando o cache antes de cada serviço CI. Mudando para uma ferramenta com um cache confiável, podemos compartilhar artefatos de construção entre os hospedeiros de CI também. O Buck também pode armazenar em cache os resultados dos testes, então se sabemos que um módulo já foi testado e não foi afetado um uma certa mudança do código, podemos pular esses testes.
No geral, nossa mudança foi um sucesso. No entanto, existiam alguns custos com a mudança para um Monorepo que inicialmente não pudemos evitar, tais como um reduzido desempenho do git e a realidade de que, quando o master tem problema, todo o código é afetado.
Por exemplo, começamos a ver que commits perfeitamente válidos passados para o CI falhariam quando havia tentativa de reposicioná-los acima do branch principal. Assim que lançamos o Monorepo, tínhamos que atenciosamente reverter envios que falhavam em todas as horas do dia. Nos piores dias, 10% dos envios tinham que ser revertidos, o que resultava em horas de desenvolvimento perdidas. Para resolver isso, introduzimos um sistema, chamado Submit Queue, entre o repositório e as operações de envio (que chamamos de “land” no Uber, pois utilizamos o Arcanist). Quando um engenheiro tenta enviar sua mudança, ele vai para a Submit Queue. Esse sistema trata um commit por vez, reposiciona-o em relação ao principal, constrói o código e executa os testes unitários. Se não apresentar nenhum erro, então ele é combinado ao principal. Com a Submit Queue funcionando, nossa taxa de sucesso saltou para 99%.
Conclusão
Mover para um novo conjunto de ferramentas nos forneceu os fundamentos para testar novas ideias para construir nossas aplicações de forma melhor e mais rápida. Recentemente, nossa equipe tem trabalhado com a equipe do Buck do Facebook para adicionar ao Buck suporte completo ao Swift, assim como suporte para macOS e iOS Dynamic Frameworks. Isso nos permitiu utilizar os benefícios do Buck enquanto movemos nossa base de códigos para a era Swift.
Mover nosso código para um único lugar e nossos aplicativos para o Buck foram somente alguns dos passos em nosso caminho para modernizar como desenvolvemos. Ao nosso lado, nossa equipe de desenvolvimento Android também adotou o Buck, e eles têm sido visto os benefícios das construções rápidas e reproduzíveis. Mas não estamos parando por aqui; nossa equipe está comprometida em adicionar mais funcionalidades ao suporte para iOS do Buck durante o ano, e também planejamos intensificar nossos esforços em relação ao open source para colaborar com a crescente comunidade móvel.
***
Este artigo é do Uber Engineering Team. Ele foi escrito por Alan Zeino. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/ios-monorepo/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?