

Artigo publicado originalmente pelo The TensorFlow Team. A tradução foi feita pela Redação iMasters com autorização.
–
O TensorFlow 1.3 apresenta dois recursos importantes que você deve experimentar:
- Conjuntos de dados: uma maneira completamente nova de criar pipelines de entrada (ou seja, ler dados em seu programa).
- Avaliadores: uma maneira de alto nível de criar modelos TensorFlow. Os avaliadores incluem modelos pré-fabricados para tarefas comuns de aprendizagem de máquina, mas você também pode usá-los para criar seus próprios modelos personalizados.
Abaixo você pode ver como eles se encaixam na arquitetura TensorFlow. Combinados, eles oferecem uma maneira fácil de criar modelos TensorFlow e fornecer dados para eles:
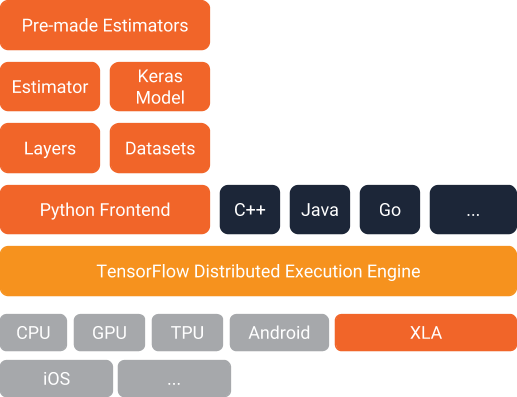
Nosso Modelo de Exemplo
Para explorar esses recursos, vamos construir um modelo e mostrar-lhe os trechos de código relevantes. O código completo está disponível aqui, incluindo instruções para obter os arquivos de treinamento e teste. Observe que o código foi escrito para demonstrar como Conjuntos de dados e Avaliadores funcionam de modo operacional e não foi otimizado para o máximo desempenho.
O modelo treinado categoriza Flores de íris com base em quatro características botânicas (comprimento da sépala, largura da sépala, comprimento da pétala e largura da pétala). Assim, durante a inferência, você pode fornecer valores para essas quatro características e o modelo irá prever que a flor é uma das seguintes três belas variedades:

Nós vamos treinar um Classificador de Rede Neural Profunda com a estrutura abaixo. Todos os valores de entrada e saída serão float32, e a soma dos valores de saída será 1 (como estamos prevendo a probabilidade para cada tipo de Iris individual):
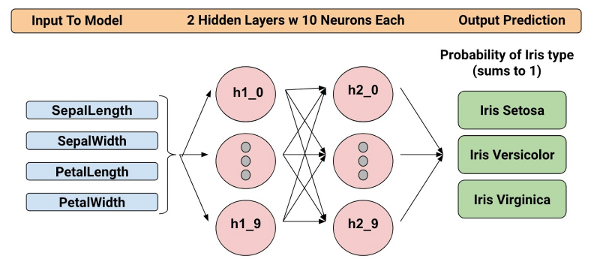
Por exemplo, um resultado de saída pode ser 0.05 para Iris Setosa, 0.9 para Iris Versicolor e 0.05 para Iris Virginica, o que indica uma probabilidade de 90% de que esta é um Iris Versicolor.
Ótimo! Agora que definimos o modelo, vejamos como podemos usar Conjuntos de dados e Avaliadores para treiná-lo e fazer previsões.
Apresentando os Conjuntos de Dados
Conjuntos de dados é uma nova maneira de criar pipelines de entrada para os modelos TensorFlow. Esta API é muito mais performática que usar o feed_dict ou as pipelines baseadas em filas, e é mais limpa e fácil de usar. Embora Conjuntos de dados ainda resida em tf.contrib.data em 1.3, esperamos mover esta API para o núcleo em 1.4. Então, é hora de levá-la para uma unidade de teste.
Em alto nível, os Conjuntos de dados consistem nas seguintes classes:
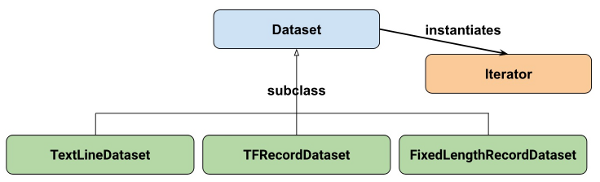
Onde:
- Conjunto de dados: Classe base contendo métodos para criar e transformar conjuntos de dados. Também permite inicializar um conjunto de dados a partir de dados na memória, ou de um gerador Python.
- TextLineDataset: Lê linhas de arquivos de texto.
- TFRecordDataset: Lê registros de arquivos TFRecord.
- FixedLengthRecordDataset: Lê registros de tamanho fixo de arquivos binários.
- Iterator: Fornece uma maneira de acessar um elemento do conjunto de dados por vez.
Nosso conjunto de dados
Para começar, vejamos primeiro o conjunto de dados que usaremos para alimentar nosso modelo. Leremos dados de um arquivo CSV, onde cada linha conterá cinco valores – os quatro valores de entrada, além do rótulo:

O rótulo será:
- 0 para Iris Setosa
- 1 para Versicolor
- 2 para Virginica.
Representando nosso conjunto de dados
Para descrever nosso conjunto de dados, primeiro criamos uma lista de nossos recursos:
feature_names = [ 'SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth']
Quando treinarmos nosso modelo, precisaremos de uma função que lê o arquivo de entrada e retorna o recurso e os dados do rótulo. Avaliadores requer que você crie uma função do seguinte formato:
def input_fn():
...<code>...
return ({ 'SepalLength':[values], ..<etc>.., 'PetalWidth':[values] },
[IrisFlowerType])
O valor de retorno deve ser um tuplo de dois elementos organizado da seguinte maneira:
- O primeiro elemento deve ser um dict em que cada recurso de entrada é uma chave e, em seguida, uma lista de valores para o lote de treinamento.
- O segundo elemento é uma lista de rótulos para o lote de treinamento.
Uma vez que estamos retornando um lote de recursos de entrada e rótulos de treinamento, isso significa que todas as listas na declaração de retorno terão comprimentos iguais. Tecnicamente falando, sempre que nos referimos à “lista” aqui, na verdade estamos falando de um tensor TensorFlow 1-d.
Para permitir a reutilização simples do input_fn, vamos adicionar alguns argumentos a ele. Isso nos permite construir funções de entrada com diferentes configurações. Os argumentos são bastante diretos:
- file_path: O arquivo de dados para ler.
- perform_shuffle: Se a ordem de registro deve ser aleatorizada.
- repeat_count: O número de vezes para iterar sobre os registros no conjunto de dados. Por exemplo, se especificarmos 1, cada registro será lido uma vez. Se especificarmos Nenhum, a iteração continuará para sempre.
Veja como podemos implementar esta função usando a API Dataset. Vamos embrulhá-la em uma “função de entrada” que é adequada ao alimentar nosso modelo Avaliador mais tarde em:
def my_input_fn(file_path, perform_shuffle=False, repeat_count=1): def decode_csv(line): parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]]) label = parsed_line[-1:] # Last element is the label del parsed_line[-1] # Delete last element features = parsed_line # Everything (but last element) are the features d = dict(zip(feature_names, features)), label return d dataset = (tf.contrib.data.TextLineDataset(file_path) # Read text file .skip(1) # Skip header row .map(decode_csv)) # Transform each elem by applying decode_csv fn if perform_shuffle: # Randomizes input using a window of 256 elements (read into memory) dataset = dataset.shuffle(buffer_size=256) dataset = dataset.repeat(repeat_count) # Repeats dataset this # times dataset = dataset.batch(32) # Batch size to use iterator = dataset.make_one_shot_iterator() batch_features, batch_labels = iterator.get_next() return batch_features, batch_labels
Observe o seguinte:
- TextLineDataset: A API Dataset fará muito gerenciamento de memória para você quando estiver usando seus conjuntos de dados baseados em arquivos. Você pode, por exemplo, ler em arquivos de conjunto de dados muito maiores que a memória ou ler em vários arquivos especificando uma lista como argumento.
- shuffle: Lê os registros buffer_size e, em seguida, embaralha (aleatoriza) a ordem deles.
- mapa: Chama a função decode_csv com cada elemento no conjunto de dados como um argumento (uma vez que estamos usando o TextLineDataset, cada elemento será uma linha de texto CSV). Então, aplicamos decode_csv a cada uma das linhas.
- decode_csv: Divide cada linha em campos, fornecendo os valores padrão, se necessário. Em seguida, retorna um dict com as chaves de campo e os valores de campo. A função mapa atualiza cada elem (linha) no conjunto de dados com o dict.
Essa é uma introdução aos Conjuntos de dados! Apenas por diversão, agora podemos usar essa função para imprimir o primeiro lote:
next_batch = my_input_fn(FILE, True) # Will return 32 random elements
# Now let's try it out, retrieving and printing one batch of data.
# Although this code looks strange, you don't need to understand
# the details.
with tf.Session() as sess:
first_batch = sess.run(next_batch)
print(first_batch)
# Output
({'SepalLength': array([ 5.4000001, ...<repeat to 32 elems>], dtype=float32),
'PetalWidth': array([ 0.40000001, ...<repeat to 32 elems>], dtype=float32),
...
},
[array([[2], ...<repeat to 32 elems>], dtype=int32) # Labels
)
Isso é realmente tudo o que precisamos da API Dataset para implementar nosso modelo. Os conjuntos de dados possuem muito mais recursos; por gentileza, veja o final desta publicação onde reunimos mais recursos.
Apresentando Avaliadores
Avaliadores é uma API de alto nível que reduz muito do código de referência que você precisava escrever ao treinar um modelo TensorFlow. Avaliadores também são muito flexíveis, permitindo que você substitua o comportamento padrão se você tiver requisitos específicos para o seu modelo.
Existem duas maneiras possíveis de construir seu modelo usando Avaliadores:
- Avaliador pré-fabricado – Estes são avaliadores predefinidos, criados para gerar um modelo específico de modelo. Nesta postagem no blog, usaremos o avaliador pré-fabricado DNNClassifier.
- Avaliador (classe base) – Oferece controle completo de como seu modelo deve ser criado usando uma função model_fn. Vamos abordar como fazer isso em uma postagem no blog separada.
Aqui está o diagrama de classes para Avaliadores:
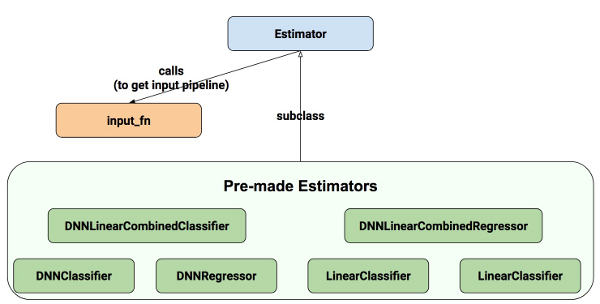
Esperamos adicionar mais Avaliadores pré-fabricados em lançamentos futuros.
Como você pode ver, todos os avaliadores utilizam input_fn que fornece ao avaliador dados de entrada. No nosso caso, vamos reutilizar my_input_fn, que definimos para esse propósito.
O código a seguir instancia o avaliador que prediz o tipo de Flor de Iris:
# Create the feature_columns, which specifies the input to our model. # All our input features are numeric, so use numeric_column for each one. feature_columns = [tf.feature_column.numeric_column(k) for k in feature_names] # Create a deep neural network regression classifier. # Use the DNNClassifier pre-made estimator classifier = tf.estimator.DNNClassifier( feature_columns=feature_columns, # The input features to our model hidden_units=[10, 10], # Two layers, each with 10 neurons n_classes=3, model_dir=PATH) # Path to where checkpoints etc are stored
Agora temos um avaliador que podemos começar a treinar.
Treinando o modelo
O treinamento é realizado usando uma única linha de código TensorFlow:
# Train our model, use the previously function my_input_fn # Input to training is a file with training example # Stop training after 8 iterations of train data (epochs) classifier.train( input_fn=lambda: my_input_fn(FILE_TRAIN, True, 8))
Mas espere um minuto… o que é essa coisa de “lambda: my_input_fn (FILE_TRAIN, True, 8)“? É aí que conectamos Conjuntos de Dados com os Avaliadores! Avaliadores precisa de dados para realizar treinamento, avaliação e previsão, e ele usa o input_fn para buscar os dados. Avaliadores requerem um input_fn sem argumentos, então criamos uma função sem argumentos usando lambda, que chama o nosso input_fn com os argumentos desejados: o file_path, a shuffle_setting e o repeat_count. No nosso caso, usamos o nosso my_input_fn, passando-o:
- FILE_TRAIN, que é o arquivo de dados de treino.
- True, que diz ao Avaliador para embaralhar os dados.
- 8, que diz ao Avaliador para repetir o conjunto de dados 8 vezes.
Avaliando o Nosso Modelo Treinado
Ok, então agora temos um modelo treinado. Como podemos avaliar o desempenho que está realizando? Felizmente, cada Avaliador contém um método evaluate:
# Evaluate our model using the examples contained in FILE_TEST
# Return value will contain evaluation_metrics such as: loss & average_loss
evaluate_result = estimator.evaluate(
input_fn=lambda: my_input_fn(FILE_TEST, False, 4)
print("Evaluation results")
for key in evaluate_result:
print(" {}, was: {}".format(key, evaluate_result[key]))
No nosso caso, atingimos uma precisão de aproximadamente 93%. Existem várias maneiras de melhorar essa precisão, é claro. Uma maneira é simplesmente executar o programa uma vez após a outra. Uma vez que o estado do modelo é persistido (no model_dir = PATH acima), o modelo melhorará quando mais iterações você treinar, até que ele se estabeleça. Outra maneira seria ajustar o número de camadas ocultas ou o número de nodes em cada camada oculta. Sinta-se livre para experimentar com isso; observe, no entanto, que quando você faz uma alteração, você precisa remover o diretório especificado em model_dir = PATH, uma vez que você está mudando a estrutura do DNNClassifier.
Fazendo Predições Usando Nosso Modelo Treinado
E é isso! Agora temos um modelo treinado, e se estamos felizes com os resultados da avaliação, podemos usá-lo para prever uma Flor de Iris com base em alguma entrada. Tal como acontece com o treinamento e avaliação, fazemos previsões usando uma única chamada de função:
# Predict the type of some Iris flowers.
# Let's predict the examples in FILE_TEST, repeat only once.
predict_results = classifier.predict(
input_fn=lambda: my_input_fn(FILE_TEST, False, 1))
print("Predictions on test file")
for prediction in predict_results:
# Will print the predicted class, i.e: 0, 1, or 2 if the prediction
# is Iris Sentosa, Vericolor, Virginica, respectively.
print prediction["class_ids"][0]
Fazendo Previsões em Dados na Memória
O código anterior especificou FILE_TEST para fazer previsões em dados armazenados em um arquivo, mas como podemos fazer previsões em dados que residem em outras fontes, por exemplo, na memória? Como você pode adivinhar, isso realmente não exige uma alteração na nossa ligação predict. Em vez disso, configuramos a API Dataset para usar uma estrutura de memória da seguinte maneira:
# Let create a memory dataset for prediction.
# We've taken the first 3 examples in FILE_TEST.
prediction_input = [[5.9, 3.0, 4.2, 1.5], # -> 1, Iris Versicolor
[6.9, 3.1, 5.4, 2.1], # -> 2, Iris Virginica
[5.1, 3.3, 1.7, 0.5]] # -> 0, Iris Sentosa
def new_input_fn():
def decode(x):
x = tf.split(x, 4) # Need to split into our 4 features
# When predicting, we don't need (or have) any labels
return dict(zip(feature_names, x)) # Then build a dict from them
# The from_tensor_slices function will use a memory structure as input
dataset = tf.contrib.data.Dataset.from_tensor_slices(prediction_input)
dataset = dataset.map(decode)
iterator = dataset.make_one_shot_iterator()
next_feature_batch = iterator.get_next()
return next_feature_batch, None # In prediction, we have no labels
# Predict all our prediction_input
predict_results = classifier.predict(input_fn=new_input_fn)
# Print results
print("Predictions on memory data")
for idx, prediction in enumerate(predict_results):
type = prediction["class_ids"][0] # Get the predicted class (index)
if type == 0:
print("I think: {}, is Iris Sentosa".format(prediction_input[idx]))
elif type == 1:
print("I think: {}, is Iris Versicolor".format(prediction_input[idx]))
else:
print("I think: {}, is Iris Virginica".format(prediction_input[idx])
Dataset.from_tensor_slides () é projetado para conjuntos de dados pequenos que se encaixam na memória. Ao usar o TextLineDataset como fizemos para treinamento e avaliação, você pode ter arquivos grandes arbitrariamente, desde que sua memória possa gerenciar o buffer aleatório e os tamanhos do lote.
Freebies
Usar um Avaliador pré-fabricado como DNNClassifier oferece muito valor. Além de serem fáceis de usar, os Avaliadores pré-fabricados também fornecem métricas de avaliação incorporadas e criam resumos que você pode ver no TensorBoard. Para ver esse relatório, inicie o TensorBoard a partir da sua linha de comando da seguinte maneira:
# Replace PATH with the actual path passed as model_dir argument when the # DNNRegressor estimator was created. tensorboard --logdir=PATH
Os diagramas a seguir mostram alguns dos dados que o TensorBoard fornecerá:
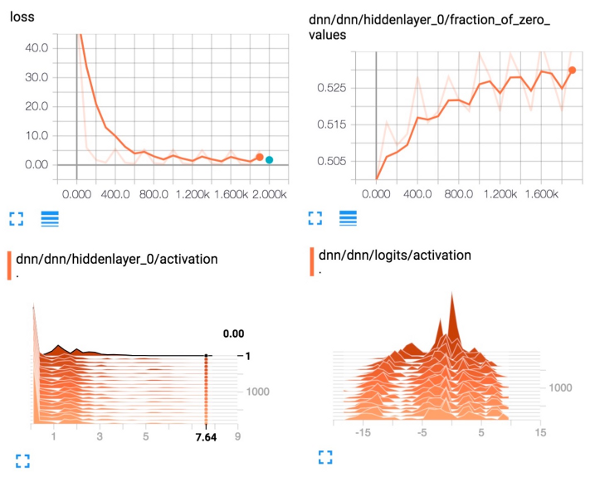
Resumo
Nessa postagem do blog, exploramos Conjuntos de dados e Avaliadores. Estas são APIs importantes para definir fluxos de dados de entrada e criar modelos. Então, investir tempo para aprendê-las é definitivamente valioso!
Para mais detalhes, certifique-se de verificar:
- O código-fonte completo usado nesta publicação do blog está disponível aqui.
- O excelente caderno de anotações Jupyter de Josh Gordon sobre o assunto. Usando esse caderno de anotações, você aprenderá como executar um exemplo mais extenso que possui muitos tipos diferentes de recursos (entradas). Como você se lembra do nosso modelo, usamos apenas recursos numéricos.
- Para Conjuntos de dados, veja um novo capítulo no Guia do programador e na documentação de referência.
- Para Avaliadores, veja um novo capítulo no Guia do Programador e na documentação de referência.
Mas não pára por aqui. Em breve, publicaremos mais postagens que descrevem como essas APIs funcionam. Então, fique atento!
Até lá, Feliz Codificação TensorFlow!
–
Este artigo é do The TensorFlow Team. A tradução foi feita pela Redação iMasters com autorização. Você pode acessar o original em: https://developers.googleblog.com/2017/09/introducing-tensorflow-datasets.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?