

Com a evolução de formatos de armazenamento como Apache Parquet, Apache ORC e mecanismos de consulta como Presto e Apache Impala, o ecossistema Hadoop tem potencial para se tornar uma camada de serviço unificada e de propósito geral para cargas de trabalho que podem tolerar latências de alguns minutos. Contudo, para conseguir isso, ele requer uma ingestão de dados de latência baixa e eficiente e preparação de dados no Hadoop Distributed File System (HDFS).
Para resolver isso na Uber, criamos o Hoodie, um framework de processamento incremental para alimentar todos os pipelines de dados críticos de negócios em baixa latência e alta eficiência. De fato, recentemente abrimos o código para que outros usassem e construíssem. Mas, antes de mergulhar no Hoodie, vamos dar um passo para trás e discutir por que é uma boa ideia pensar em Hadoop como a camada de serviço unificada.
Motivação
A arquitetura Lambda é uma arquitetura de processamento de dados comum que propõe o cálculo duplo com streaming e camada de lote. Uma vez a cada poucas horas, um processo em batch é iniciado para calcular o estado de negócios preciso e a atualização em batch é carregada em massa na camada de serviço. Enquanto isso, uma camada de processamento de streaming calcula e serve o mesmo estado para contornar a latência de várias horas acima. No entanto, esse estado é apenas aproximado, até que seja substituído pelo estado mais preciso do lote computado. Como os estados são ligeiramente diferentes, é necessário que haja diferentes camadas de serviço para batch e stream, unindo em uma abstração na parte superior, ou um sistema de serviço bastante complexo (como o Druid) que executa razoavelmente bem para atualizações de nível de registro e lotes de carga em massa.
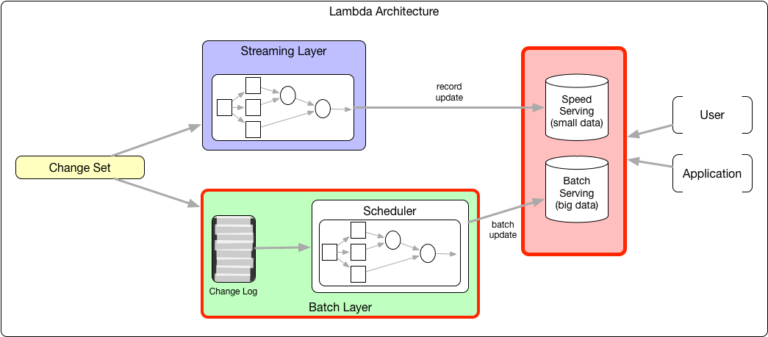
Figura 1: A arquitetura Lambda requer dupla computação e duplo serviço.
Questionando a necessidade de uma camada de batch separada, a arquitetura Kappa argumenta que um mecanismo de processamento de stream poderia ser uma solução de uso geral para computações. Em um sentido genérico, todos os cálculos podem ser descritos como operadores que produzem um fluxo de tupla e os consumidores iterando sobre múltiplos fluxos de tupla de entrada (isto é, o modelo Volcano Iterator). Essa funcionalidade permitiria que a camada de streaming gerenciasse o reprocessamento de estados de negócios ao reproduzir a computação com maior paralelismo e recursos. Com sistemas que podem eficientemente verificar e armazenar grandes quantidades de estado de streaming, o estado do negócio na camada de streaming não é mais uma aproximação; esse modelo ganhou alguma tração com muitos pipelines ingeridos. Ainda assim, mesmo que a camada de lote seja eliminada nesse modelo, o problema de ter duas camadas de serviço diferentes permanece.
Muitos sistemas de processamento de stream verdadeiros operam hoje em nível de registro, de modo que os sistemas de fornecimento de velocidade devem ser otimizados para atualizações em nível de registro. Normalmente, esses sistemas não podem ser otimizados para verificações analíticas também, a menos que o sistema tenha um grande pedaço de seus dados em memória (como Memsql) ou índices agressivos (como ElasticSearch). Esses sistemas de serviço de velocidade sacrificam a escalabilidade e o custo para otimizar o desempenho de ingestão e varredura. Por essa razão, a retenção de dados nesses sistemas de serviço é tipicamente limitada, o que significa que podem durar de 30 a 90 dias ou armazenar até alguns TB de dados. Análises em dados históricos mais antigos são frequentemente redirecionados para mecanismos de pesquisa em HDFS, onde a latência de dados não é um problema.
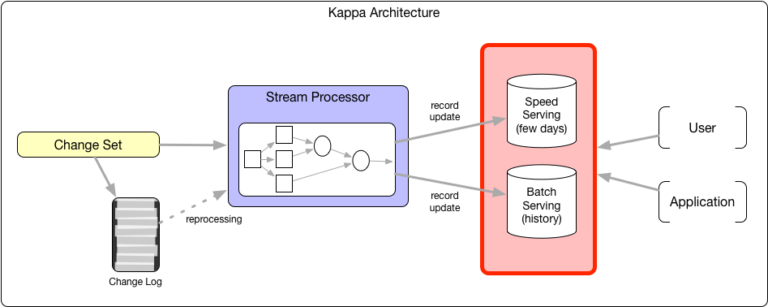
Figura 2: A arquitetura Kappa simplifica a computação unificando o processamento, mas a complexidade de serviço ainda existe.
Essa compensação fundamental entre latência de ingestão de dados, desempenho de varredura, recursos de computação e complexidade operacional é inevitável. Mas para cargas de trabalho que podem tolerar latências de cerca de 10 minutos, não há necessidade de uma camada se serviço de “velocidade” separada se houver uma maneira mais rápida de ingerir e preparar dados em HDFS. Isso unifica a camada de serviço e reduz significativamente a complexidade geral e o uso de recursos.
No entanto, para que o HDFS se torne a camada de serviço unificada, ele precisa não apenas armazenar um log de conjuntos de alterações (um sistema de registro), mas também suportar estados de negócios compactados e de-duplicados divididos por uma métrica empresarial significativa. Os seguintes recursos são necessários para esse tipo de camada de serviço unificada:
- Capacidade de rapidamente aplicar mutações em grandes conjuntos de dados HDFS
- Opções de armazenamento de dados que são otimizadas para varreduras analíticas (formatos de arquivo em colunas)
- Capacidade de encadear e propagar atualizações de forma eficiente para conjuntos de dados modelados
O estado de negócios compactado geralmente não pode evitar mutações, mesmo se o campo de partição de negócios for o momento em que o evento ocorreu. A ingestão pode ainda resultar em atualizações para muitas partições mais antigas por causa dos dados de chegada tardia e da diferença entre os tempos de evento e de processamento. Mesmo se a chave de partição for o tempo de processamento, ele ainda pode precisar ser atualizado devido à demanda de destruir dados para adequação da auditoria ou razões de segurança.
Introduzindo o Hoodie: Hi, Hoodie!
Entra o Hoodie, um framework incremental que suporta os requisitos descritos na seção anterior. Em resumo, Hoodie (Hadoop Upsert Delete e Incremental) é uma análise, otimizada para o armazenamento de dados de abstração que permite a aplicação de mutações de dados no HDFS na ordem de poucos minutos e encadeamento de processamento incremental.
Os conjuntos de dados do Hoodie se integram com o ecossistema Hadoop atual (incluindo Apache Hive, Apache Parquet, Presto e Apache Spark) através de um InputFormat personalizado, tornando o framework perfeito para o usuário final.
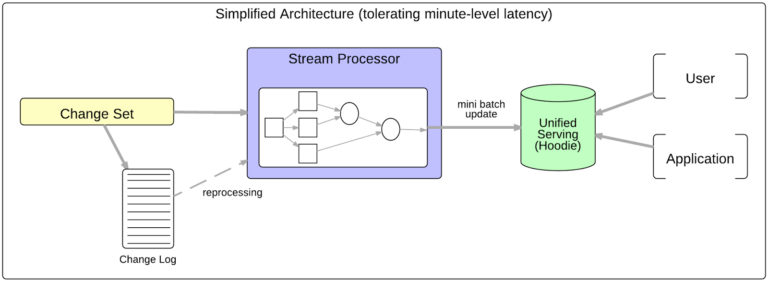
Figura 3: Hoodie simplifica o serviço para cargas de trabalho que toleram latência de minutos.
O modelo DataFlow caracteriza os pipelines de dados com base em suas garantias de latência e completude. A Figura 4, abaixo, demonstra como os pipelines da Uber Engineering são distribuídos através desse espectro e quais estilos de processamento são normalmente aplicados para cada um deles:
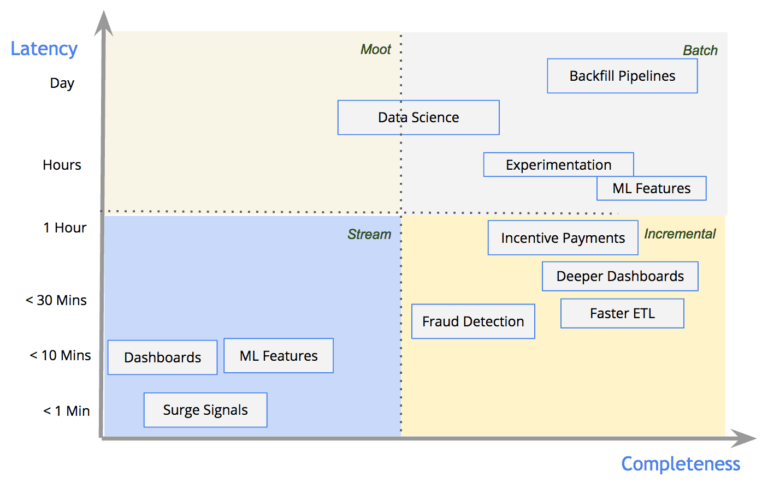
Figura 4: O diagrama acima demonstra a distribuição de casos de uso em diferentes latências e níveis de completude na Uber.
Para os poucos casos de uso realmente precisando de latências de 1 minuto e dashboards com métricas de negócios simples, contamos com processamento de stream em nível de registro. Para casos de uso em batches tradicionais, como machine learning e a análise da eficácia de experimentos, contamos com processamento em batch que se destaca em cálculos mais pesados. Para casos de uso em que joins complexas ou trituração de dados significativos são necessários em latências em tempo real, contamos com o Hoodie e seus primitivos de processamento incremental para obter o melhor dos dois mundos. Para saber mais sobre os casos de uso suportados pelo Hoodie, você pode verificar nossa documentação no GitHub.
Armazenamento
O Hoodie organiza um conjunto de dados em uma estrutura de diretório particionado sob um basepath, semelhante a uma tabela tradicional Hive. O conjunto de dados é dividido em partições, que são diretórios contendo arquivos de dados para essa partição. Cada partição é identificada exclusivamente pelo seu partitionpath em relação ao basepath. Dentro de cada partição, os registros são distribuídos em vários arquivos de dados. Cada arquivo de dados é identificado por um único fileId e o commit que produziu o arquivo. No caso de atualizações, vários arquivos de dados podem compartilhar o mesmo fileld gravado em diferentes commits.
Cada registro é identificado exclusivamente por uma chave de registro e mapeado para um fileId. Esse mapeamento entre a chave de registro e fileId é permanente, uma vez que a primeira versão de um registro foi gravada em um arquivo. Em suma, o fileId identifica um grupo de arquivos que contêm todas as versões de um grupo de registros.
O armazenamento Hoodie consiste em três partes distintas:
- Metadados: o Hoodie mantém os metadados de toda a atividade realizada no conjunto de dados como uma linha do tempo, que permite visualizações instantâneas do conjunto de dados. Isso é armazenado em um diretório de metadados no basepath. Abaixo, descrevemos os tipos de ações na linha do tempo:
- Commits: Um único commit captura informações sobre uma gravação atômica de um lote de registros em um conjunto de dados. Os commits são identificados por um timestamp monotonicamente crescente, denotando o início da operação de gravação.
- Limpa: Atividade em segundo plano que se livra de versões mais antigas de arquivos no conjunto de dados que não serão mais usados em uma consulta em execução.
- Compactações: Atividade em segundo plano para reconciliar estruturas de dados diferenciadas dentro do Hoodie (por exemplo, movendo atualizações de arquivos de log baseados em linhas para formatos em colunas).
- Index: o Hoodie mantém um índice para mapear rapidamente uma chave de registro de entrada para um fileId se a chave de registro já estiver presente. Implementação de índice é plugável, e estas são as opções atualmente disponíveis:
- Filtro Bloom armazenado em cada rodapé do arquivo de dados: A opção padrão preferida, uma vez que não há dependência em qualquer sistema externo. Os dados e o índice são sempre consistentes uns com os outros.
- Apache HBase: Pesquisa eficiente para um pequeno lote de chaves. Esta opção é susceptível de raspar alguns segundos durante a marcação de índice.
- Dados: o Hoodie armazena todos os dados ingeridos em dois formatos de armazenamento diferentes. Os formatos reais usados são plugáveis, mas requerem fundamentalmente as seguintes características:
- Formato de armazenamento em coluna otimizado para varredura (ROFormat). O padrão é o Apache Parquet.
- Formato de armazenamento baseado em filas, otimizado para gravação (WOFormat). O padrão é Apache Avro.
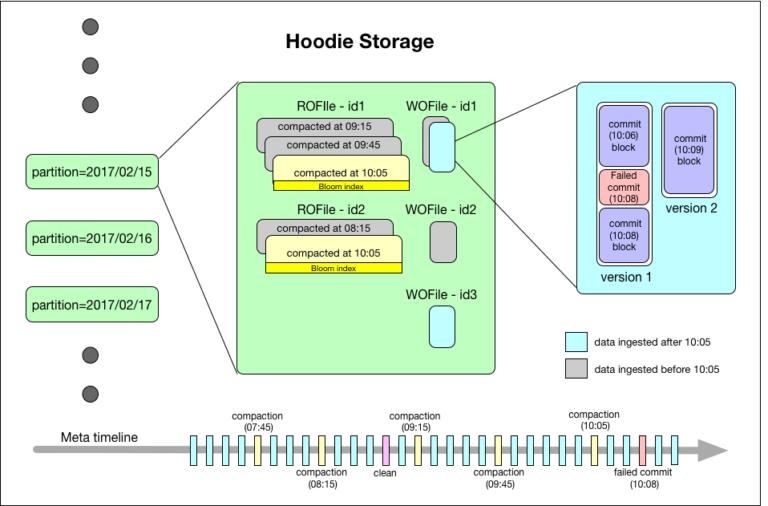
Figura 5: Interior do Armazenamento Hoodie. O diagrama de armazenamento Hoodie acima descreve um tempo de commit no formato YYYYMMDDHHMISS e pode ser simplificado como HH: SS.
Otimização
O armazenamento Hoodie é otimizado para padrões de uso do HDFS. A compactação é a operação crítica para converter dados de um formato de otimização de gravação para um formato otimizado para verificação. Uma vez que a unidade fundamental de paralelismo para uma compactação é reescrever um único fileId, o Hoodie garante que todos os arquivos de dados sejam escritos como arquivos de tamanho de bloco HDFS para equilibrar o paralelismo de compactação, o paralelismo de verificação de consulta e o número total de arquivos no HDFS. Compactação também é plugável, que pode ser estendido para suturar arquivos de dados mais velhos, menos frequentemente atualizados para reduzir ainda mais o número total de arquivos.
Caminho de ingestão
O Hoodie é uma biblioteca Spark que se destina a ser executada como um trabalho de ingestão de streaming, e ingerir dados como mini-lotes (normalmente na ordem de um a dois minutos). No entanto, dependendo dos requisitos de latência e do tempo de negociação de recursos, os trabalhos de ingestão também podem ser executados como tarefas agendadas usando Apache Oozie ou Apache Airflow.
O que está a seguir é o caminho de gravação para uma ingestão Hoodie com a configuração padrão:
- Hoodie carrega o índice de filtro Bloom de todos os arquivos de parquet nas partições envolvidas (ou seja, partições espalhadas a partir do batch de entrada) e marca o registro como uma atualização ou insere mapeando as chaves de entrada para arquivos existentes para atualizações. A junção aqui poderia inclinar-se no tamanho do batch de entrada, partições ou número de arquivos em uma partição. Ele é suportado automaticamente fazendo um particionamento de intervalo em uma chave unida e sub-particionado para evitar o notório limite de 2GB para um bloco de shuffle remoto no Spark.
- O Hoodie agrupa inserções por partição, atribui um novo fileId e anexa ao arquivo de log correspondente até que o arquivo de log alcance o tamanho do bloco HDFS. Uma vez atingido o tamanho do bloco, o Hoodie cria outro fileld e repete esse processo para todas as inserções nessa partição.
- Um processo de compactação limitado por tempo é iniciado por um agendador a cada poucos minutos, o que gera uma lista priorizada de compactações e compacta todos os arquivos avro para um fileld com o arquivo de parquet atual para criar a próxima versão desse arquivo de parquet.
- A compactação é executada de forma assíncrona, bloqueando versões de log específicas sendo compactadas e gravando novas atualizações para esse fileld em uma nova versão de log. Os bloqueios são obtidos no Zookeeper.
- As compactações são priorizadas com base no tamanho dos dados de registro sendo compactados e são plugáveis com uma estratégia de compactação. Em cada iteração de compactação, os arquivos com a maior quantidade de logs são compactados primeiro, enquanto pequenos arquivos de log são compactados por último, uma vez que o custo de reescrever o arquivo parquet não é amortizado no número de atualizações do arquivo.
- Hoodie acrescenta atualizações para um fileId para seu arquivo de log correspondente, se existir algum ou cria um arquivo de log se não existir.
- Se o trabalho de ingestão for bem-sucedido, um commit é registrado na linha do tempo meta do Hoodie, que renomeia atomicamente um arquivo inflight para um arquivo commit e grava detalhes sobre partições e a versão fileId
Otimização
Como discutido anteriormente, o Hoodie se esforça para alinhar o tamanho do arquivo com o tamanho do bloco subjacente. Dependendo da eficiência da compressão em colunas e do volume de dados em uma partição para compactar, a compactação ainda pode criar pequenos arquivos de parquet. Isso é eventualmente corrigido automaticamente nas iterações seguintes da ingestão, já que as inserções para uma partição são compactadas como atualizações para arquivos pequenos existentes. Eventualmente, os tamanhos de arquivo crescerão para alcançar o tamanho de bloco subjacente na compactação.
Recuperação de falhas
Se um trabalho de ingestão falhar devido a um erro intermitente, Spark repetirá a computação do RDD e resolverá automaticamente. Se o número de falhas exceder maxRetries no Spark, então o trabalho de ingestão falhará e a próxima iteração voltará a ingerir o mesmo lote novamente. Duas distinções importantes são observadas abaixo:
- A ingestão que falhou pode escrever blocos avro parciais no arquivo de log. Isso é tratado armazenando metadados sobre o deslocamento inicial para um bloco e versão de arquivo de log nos metadados de commit. Ao ler o log, os blocos de commit irrelevantes, às vezes parcialmente escritos, são ignorados e o local de busca é definido apropriadamente no arquivo avro.
- Falha de compactação poderia escrever arquivos de parquet parciais. Isso é tratado pela camada de consulta, que filtra as versões de arquivo com base nos metadados de commit. A camada de consulta apenas selecionará arquivos para a última compactação concluída. A iteração de compactação seguinte reverterá a compactação que falhou e tentará novamente.
Caminho de consulta
A linha de tempo meta de commit permite tanto uma visualização otimizada para leitura como uma visualização em tempo real dos mesmos dados em HDFS; essas visualizações permitem que o cliente escolha entre latência de dados e tempo de execução da consulta. O Hoodie fornece essas visualizações com um InputFormat personalizado e inclui um módulo de registro Hive que registra essas duas visualizações como tabelas do metastoreHive. Ambos os formatos de entrada compreendem fileId e tempo de commit e filtram os arquivos para escolher apenas os arquivos mais recentemente confirmados. Em seguida, o Hoodie gera divisões nesses arquivos de dados para executar o plano de consulta. Os detalhes do InputFormat são descritos abaixo:
- HoodieReadOptimizedInputFormat: Fornece uma visualização de varredura otimizada que filtra todos os arquivos de log e apenas escolhe as versões mais recentes de arquivos de parquet compactados.
- HoodieRealtimeInputFormat: Fornece uma visualização mais em tempo real que, além de escolher as versões mais recentes de arquivos de parquet compactados e fornecer um RecordReader para mesclar os arquivos de log com seus arquivos de parquet correspondentes durante uma varredura.
Ambos InputFormats estendem MapredParquetInputFormat e VectorizedParquetRecordReader, portanto todas as otimizações feitas para ler arquivos de parquet ainda se aplicam. Presto e SparkSQL funcionam fora da caixa nas tabelas do metastore do Hive, desde que a biblioteca hoodie-hadoop-mr necessária esteja em classpath.
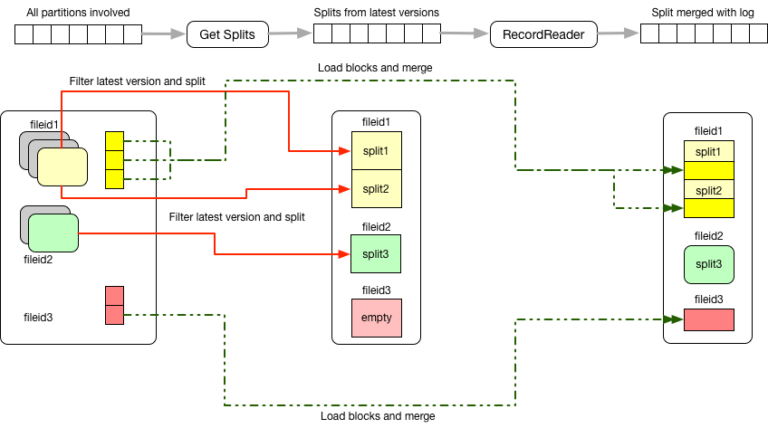
Figura 6: Conjuntos de dados Hoodie filtram as últimas versões e as mescla com o log antes de servir registros.
Processamento incremental
Como mencionado anteriormente, as tabelas modeladas precisam ser processadas e servidas no HDFS para HDFS para se tornrarem a camada de serviço unificada. Construir tabelas modeladas de baixa latência requer a capacidade de encadear o processamento incremental de conjuntos de dados HDFS. Uma vez que o Hoodie mantém metadados sobre tempos de commit e versões de arquivos criados para cada commit, o changeset incremental pode ser extraído de um conjunto de dados específico do Hoodie dentro de um timestamp de início e um timestamp de fim.
Esse processo funciona de modo bastante similar ao de uma consulta normal, exceto que as versões de arquivo específicas que estão dentro do intervalo de tempo de consulta são escolhidas em vez de apenas a versão mais recente, e um predicado adicional sobre o tempo de commit é empurrado para a varredura de arquivo para recuperar somente os registros que foram alterados na duração solicitada. A duração para a qual os conjuntos de alterações podem ser obtidos é determinada pelo número de versões de arquivos de dados que podem ser deixadas por limpar.
Isso permite joins stream-to-stream com watermarks e associações stream-to-dataset para calcular e o upsert de tabelas modeladas no HDFS.
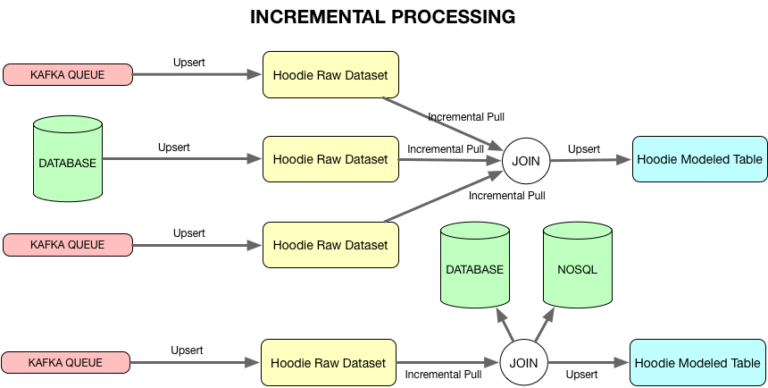
Figura 7: Hoodie permite encadeamento de computações para que tabelas modeladas possam ser servidas no Hadoop.
Qual o próximo passo no armazenamento?
A maioria da tecnologia descrita neste artigo refere-se à geração atual (denominada Merge-on-Read) do Hoodie, que ainda está em desenvolvimento ativo. Nos próximos meses, o Hoodie está programado para substituir a geração anterior (denominada Copy-on-Write) de armazenamento usado na Uber. A geração anterior simplifica a arquitetura eliminando os arquivos de log e recebendo um impacto na latência. Isso vem alimentando a ingestão de dados da Uber e tabelas modeladas há vários meses.
Como o Hoodie continua a empurrar os limites de latência para tornar a ingestão em HDFS mais rápida, haverá inevitavelmente algumas iterações sobre a identificação de gargalos enquanto escalonamos. Alguns dos gargalos potenciais que pretendemos trabalhar estão relacionados com a aceleração da indexação com um índice imutável incorporado global e projetando um formato de armazenamento de log indexável personalizado para otimizar com a procura do disco em mesclagem. Assim, nós damos boas-vindas a feedbacks, e incentivamos você a fazer colaborações em nosso projeto.
***
Este artigo é do Uber Engineering Team. Ele foi escrito por Prasanna Rajaperumal e Vinoth Chandar. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em:https://eng.uber.com/hoodie/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?