

Este artigo é a terceira parte de uma série sobre o básico necessário para usar o Kubernetes; caso você não tenha lido o artigo anterior, recomendo fazê-lo e depois voltar aqui para não ficar perdido.
Como comentei no artigo anterior, existem alguns problemas no ambiente que construí, e o principal deles é que os Pods não totalmente efêmeros, ou seja, se eu adicionar novos dados nele, no momento que o Pod fosse destruído, os dados iriam junto e sem backup!
E agora iremos tratar esse primeiro problema. Caso não tenha mais os fontes até o estado do artigo anterior, ou prefira acompanhar o meu andamento, pode pode pegá-los aqui: https://github.com/lucassabreu/openshift-next-gen/tree/v1; ou executar:
git clone -b v1 \
https://github.com/lucassabreu/openshift-next-gen.git
Volumes persistentes
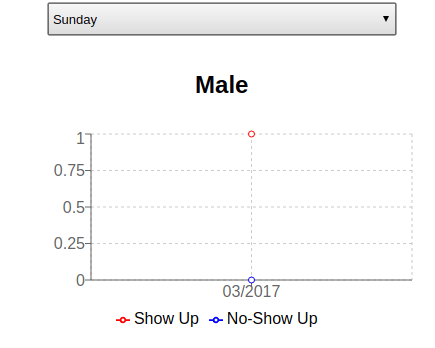
Podemos testar esse problema conectando no Pod e adicionando alguns dados e, então, destruindo-o para ver o efeito. Vou adicionar um registro sobre para Homens no Sábado, pois é um dia sem nenhuma informação e facilita a visualização.
Para acessar o Pod, usa-se o comando oc rsh <pod-name>, e para encontrar o nome do Pod, posso usar o comando oc get pods -l <selector>, então, é só acessar o MySQL e inserir os dados:
$ oc get pods -l name=db-pod NAME READY STATUS RESTARTS AGE db-deployment-3618823556-zrje2 1/1 Running 0 14m $ oc rsh db-deployment-3618823556-zrje2 bash <dentro contêiner>:/$ mysql -u$MYSQL_USER -p$MYSQL_PASSWORD appointments mysql> insert into appointments values(21, 'M', '2017-03-05', 'Sunday', 1, null); Query OK, 1 row affected (0.00 sec)
Entrando novamente na aplicação e indo em “Sunday”, tenho um gráfico com dados para os Homens:
Para concluir o teste, basta apagar o Pod com oc delete pods -l name=db-pod ou oc delete pod db-deployment-xyz, esperar o Pod ser recriado e, então, ver que as alterações nos dados se foram:
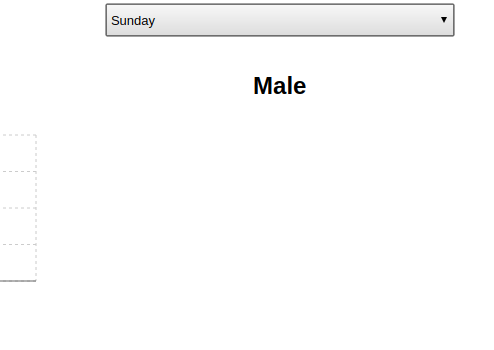
Para resolver esse problema, o Kubernetes possui os Persistent Volume Claims (PVC) que permitem definir volumes que existem fora do ciclo de vida de um Pod, ou seja, mesmo que todos os Pods sejam destruídos, o PVC irá manter os dados em si.
Podemos utilizar vários tipos de volumes em um PVC para armazenar os dados. No caso do OpenShift, o padrão é EBS, que são volumes armazenados dentro do AWS da Amazon, mas existe a opção de usar volumes do Google Cloud, do Azure, Locais, etc; no Kubernetes.
Mas no momento o OpenShift está ofertando apenas o EBS. Abaixo esta a definição do PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Depois de um momento, o OpenShift irá criar um volume e disponibilizá-lo. Agora, é preciso vinculá-lo com os db-pods. Para isso, basta alterar os volumes no db-deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: "db-deployment"
spec:
replicas: 1
template:
metadata:
labels:
name: "db-pod"
spec:
containers:
- name: "db"
image: "lucassabreu/openshift-mysql-test"
ports:
- name: "mysql-port"
containerPort: 3306
env:
- name: MYSQL_DATABASE
value: appointments
- name: MYSQL_ROOT_PASSWORD
value: "root"
- name: MYSQL_USER
value: "appoint"
- name: MYSQL_PASSWORD
value: "123"
volumeMounts:
- name: "mysql-persistent-volume" # mudou aqui
mountPath: "/var/lib/mysql"
volumes:
- name: "mysql-persistent-volume" # e aqui
persistentVolumeClaim:
claimName: mysql-pv-claim
Duas coisas foram alteradas no db-deployment:
- O nome do volume mudou. Isso é necessário porque estamos fazendo uma mudança de tipo de volume, e o Deployment não consegue alterar o tipo, mas se temos um novo, então, tudo bem.
- Adicionei a tag persistentVolumeClaim no volume novo e apontei para o PVC que criei agora há pouco.
Executo o comando oc apply -f db-deployment.yml e o Deployment irá destruir os Pods antigos e criar novos usando o PVC.
Agora, se replicarmos os comandos para incluir registros e destruir o Pod do MySQL, quando o Deployment recriar o Pod, ele manterá os dados.
Outro ponto que está desconfortável no meu ambiente é o fato das senhas e usuários estarem expostas diretamente nas configurações. Mas Kubernetes oferece uma solução para esse problema, que irei abordar no próximo artigo.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?