

Em junho de 2016, um servidor de Sistema de Nome de Domínio (DNS) de terceiros, não responsivo, causou uma interrupção de um serviço de login legado, afetando passageiros e motoristas que tentavam acessar o aplicativo da Uber. Enquanto o problema foi mitigado em minutos, descobrir por que isso aconteceu foi muito mais desafiador.
Como parte do compromisso da Uber, como arquitetar soluções de transporte estáveis e confiáveis, nossas equipes de engenharia trabalham arduamente para prevenir, responder e mitigar interrupções que impedem uma experiência de usuário perfeita.
Neste artigo, nos esforçamos para responder a pergunta: como um serviço de terceiros pode degradar a conectividade do centro de dados local (ou mesmo host-local) de um serviço da Web? Embora este serviço de login tenha sido obsoleto, nossa experiência nos levou a criar uma nova solução para identificar e prevenir esses tipos de interrupções. Leia mais para saber como uma interação do servidor Node.js-DNS não responsivo causou uma interrupção do serviço. Percorra um breve histórico de tratamento de requisição e conheça a Denial by DNS, nossa solução de código aberto para evitar a negação de serviço (DOS) não intencional por interrupções de DNS.
Contexto técnico: DNS
A maioria dos engenheiros associa DoS por DNS com ataques cibernéticos, mas alguns tempos de execução também são vulneráveis ao esgotamento dos recursos na presença de desacelerações do DNS. Mais especificamente, o uso de APIs externas pode afetar as chamadas internas críticas de um serviço.
Abaixo, oferecemos algum contexto sobre a resolução de nomes de domínio no Linux, o sistema operacional de infraestrutura atual da Uber e os modelos de threading para servidores web para contextualizar o nosso caso de uso.
Usando o DNS no Linux
Em um nível alto, o DNS é responsável pela resolução de nomes de domínio para endereços de IP compreensíveis pela máquina. Estes podem ser de toda a internet (como uber.com), rede local (por exemplo, openwrt.lan pode resolver para um roteador na rede doméstica atual), ou host-local (como localhost poderia resolver para ::1 ou 127.0 .0.1).
Resolver um domínio externo requer chamar servidores DNS externos, o que pode levar muito mais tempo do que resolver o localhost. No entanto, a interface no Linux é a mesma para resolver uber.com e chamada localhost: libc getaddrinfo(3). Sua assinatura é:
int getaddrinfo(const char *node, const char *service,
const struct addrinfo *hints,
struct addrinfo **res);
Como se pode ver, a partir da assinatura da função e do manual, a chamada é síncrona: não há como pedir ao DNS para “resolver esse nome e voltar para mim quando completo”.
Tratamento de requisição com processos e threads
Agora que entendemos como as consultas de DNS são resolvidas em uma implementação baseada em libc, vamos discutir os três tipos de modelos de threading para entender melhor como a interação entre Node.js (o tempo de execução com o qual construímos nosso serviço de login) e um serviço de terceiros causou uma interrupção.
Modelo CGI
No início da década de 1990, as requisições web recebidas foram tratadas através de um processo infantil. O conteúdo dinâmico (ou seja, o conteúdo não estático) foi tratado através da interface de gateway comum (CGI), conforme descrito na Figura 1 abaixo:
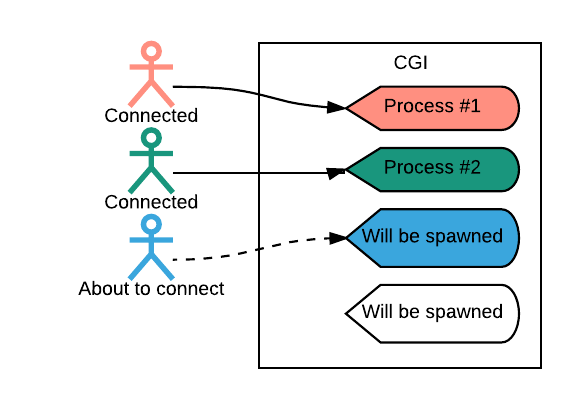
Este modelo claramente separou o código do aplicativo (por exemplo, em Tcl, Perl ou C) do código do servidor web (como o Apache), com uma interface fácil de entender entre os dois. Como resultado, esse modelo foi atraente para os desenvolvedores. O CGI funcionou bem, já que menos pessoas usavam a Internet e as linguagens de programação não precisavam de suporte de primeira classe para Protocolo de Transferência de Hipertexto/Hypertext Transfer Protocol (HTTP), que oferecia mais opções de linguagens para a construção de aplicativos da web.
No entanto, à medida em que a Internet cresceu em popularidade, os engenheiros perceberam que iniciar e desligar processos com rapidez consumia muita memória e era intensivo em CPU para ser sustentável. Para economizar recursos de hardware e eletricidade, a indústria teve que desenvolver melhores maneiras de lidar com requisições de usuários recebidas.
Modelo de Thread pool (ou 1: M)
Dado que a parte cara de gerenciar requisições recebidas é o processo de geração, a solução intuitiva é reutilizar processos para múltiplos usuários. Isso significa que, em qualquer momento, um número fixo de processos aguarda para lidar com a requisição.
Enquanto o pooling de processos é efetivo, a maioria dos tempos de execução escolhe implementar thread pools.
Um thread pool é um número fixo de threads que processam a requisição do usuário do começo ao fim, como mostrado na Figura 2 abaixo:
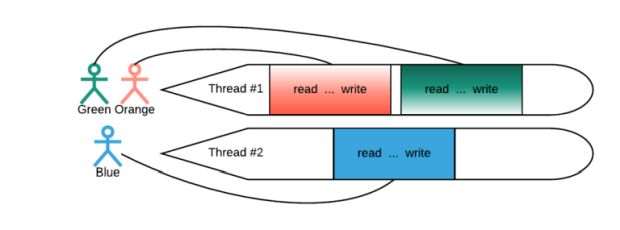
Para atender uma requisição, o aplicativo precisa ler (ler a consulta do usuário recebida), executar a lógica comercial (como retratado pelos três pontos na Figura 2) e escrever o resultado de volta para o usuário. Um exemplo de agendamento com três usuários e dois threads é destacado na Figura 2, acima, no qual um usuário “possui” o thread ao longo do processo de requisição. Com um thread servindo clientes M por vez, o modelo é chamado de 1:M.
Agora que entendemos o modelo thread pool, como podemos realmente configurá-lo? Um núcleo de CPU pode executar um único thread por vez, por isso, é comum ter pelo menos N threads no thread pool, onde N é o número de núcleos disponíveis.
O modelo 1:M ainda é uma abordagem popular nas modernas tecnologias da web. No entanto, para espremer os últimos ciclos de CPU do servidor, nós nos voltamos para outra abordagem de tratamento de requisição: o modelo M:N.
Modelo M:N
Para entregar a requisição de um usuário, os serviços frequentemente requerem informações adicionais de uma rede ou disco local. Por exemplo, no antigo serviço de login da Uber, cada requisição gerou uma nova requisição ao usuário ou a um serviço de terceiros. Durante esse período, o thread que gerencia a requisição aguarda uma resposta da rede antes de atuar. Este foi exatamente o caso do nosso serviço de login; a computação foi mínima e a maior parte do tempo foi gasta à espera de uma resposta de outros serviços.
Uma vez que um núcleo de CPU pode executar apenas um thread de cada vez, é comum a subscrição de threads. Dessa forma, os threads que aguardam uma resposta externa são retirados (remarcados por) da CPU, e apenas os threads que estão fazendo o trabalho são agendados. Em aplicativos padrão da web que usam thread pools, uma parcela significativa de tempo é gasta à espera de requisições externas. Para manter a CPU ocupada, é necessário que haja um número muito maior de threads do que de núcleos.
O contexto muda – em outras palavras, remarcando o thread de um núcleo de CPU e agendando um novo – pode ser caro. (Para mais informações sobre este tópico, confira “Quanto tempo leva para fazer uma mudança de contexto?“). À escala, as mudanças de contexto são tão intensivas em recursos que os engenheiros inventaram uma abordagem completamente diferente: agendamento M:N, descrita abaixo:
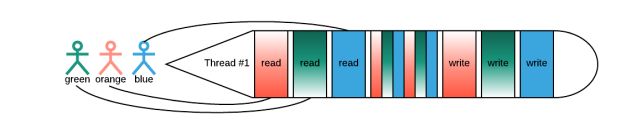
Conforme ilustrado na Figura 3, o thread precisa ler a requisição do usuário, então executar algum processamento (representado na figura acima por listras estreitas de cor) e, finalmente, escrever. Com o agendamento M:N, o thread faz um pouco de trabalho para cada usuário simultaneamente, ao contrário de tratar um de cada vez.
No modelo de threading M:N, o thread processa a requisição do usuário cuja entrada está prontamente disponível no momento. Uma vez que a informação para um segundo (terceiro, quarto e assim por diante) usuário é obtida da rede ou do disco, a entrada do usuário fornecida é agendada de volta ao thread e continua até outra chamada externa ou conclusão (gravação).
Nesse cenário, pode haver threads M que tratem pequenas explosões de computação do usuário e núcleos N nos quais estes estão agendados, emprestando o nome de M:N. Como os núcleos da CPU não estão bloqueados para chamadas externas, é comum para M = N.
Uma vez que os threads não são bloqueados pela entrada do usuário, os núcleos da CPU estão sempre fazendo o trabalho, mas como não há muitos threads, mudanças de contexto são raras.
Para o serviço de login da Uber, o modelo M:N funcionou bem até que começássemos a experimentar interações negativas entre o DNS e o agendamento M:N no Node.js.
DNS no agendamento M: N
O modelo M: N funciona apenas quando o código do aplicativo pode afirmar claramente “Estou esperando por uma resposta de rede agora mesmo, sinta-se livre para remarcar-me”. Nos bastidores, isso se traduz em um select(2) (ou equivalente) em sockets múltiplos. Contudo, as chamadas assíncronas de I/O e DNS geralmente não exibem um comportamento rápido e confiável.
Uma chamada síncrona com intensidade de tempo bloqueará o thread e manifestará o mesmo problema que os thread pools de 1:M acima: um thread interrompido esperando por uma resposta de uma entidade externa sem trabalho.
Para evitar isso, é possível despachar as chamadas do sistema síncrono para um thread pool separado:
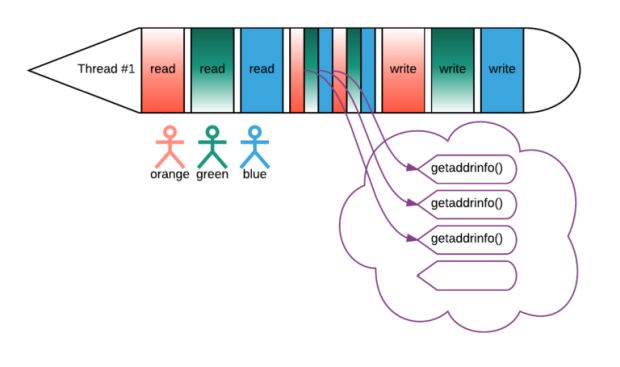
Nesse cenário, as chamadas do sistema síncrono que executam em threads dedicados já não bloqueiam os principais. Normalmente, o DNS e as I/O não ocorrem com frequência como chamar serviços externos, então o custo por requisição da mudança de contexto diminui.
De muitas maneiras, o agendamento M:N com thread pools dedicados ofereceu a solução ideal para o serviço de login da Uber, pois os thread principais estão sempre fazendo o trabalho e não competem por CPUs. Em contraste, um thread pool para chamadas síncronas caras descarrega operações lentas nos threads principais.
Com o conhecimento da resolução de DNS em Linux, thread pools, agendamento M:N e chamadas de sistema síncrono guardado em nossos bolsos, vamos agora discutir como essa combinação técnica levou a uma interrupção do serviço de login.
Analisando nossa interrupção do serviço de login
No verão de 2016, um servidor DNS de terceiros não responsivo causou uma interrupção do serviço de login da Uber que afetou alguns passageiros e motoristas tentando fazer logon no aplicativo. Por um período muito curto de tempo, uma grande parte dos nossos usuários não conseguiu fazer login com um provedor externo ou inserir manualmente suas combinações de nome de usuário e senha.
Nosso serviço de login se comunicou com outros serviços usando o cliente HTTP do Node.js padrão. Para se comunicar com outros serviços dentro do mesmo centro de dados, o serviço de login se conectou a um agente de roteador haproxy no localhost (também conhecido como padrão sidecar). O agente do roteador, em seguida, proxied a requisição para uma dependência apropriada (no nosso caso, um serviço de senha).
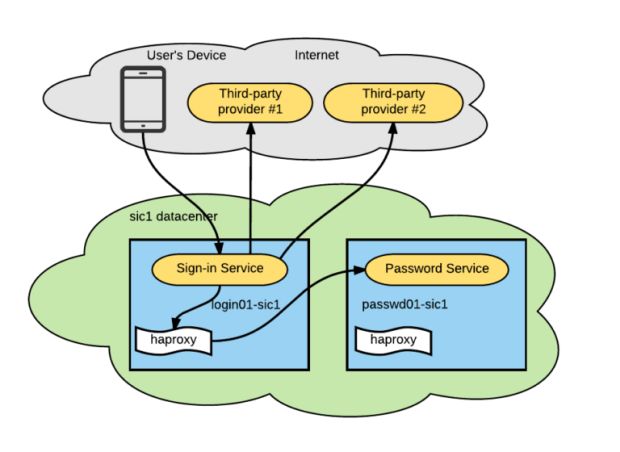
A arquitetura do serviço foi composta por:A arquitetura do serviço foi composta por:
- Um serviço de início de sessão (no HTTP) responsável por aceitar uma combinação de nome de usuário/ senha e retornar um token de sessão.
- Um serviço de senha que determina se o par de credenciais está correto.
- Um provedor de terceiros que permite métodos de login adicionais.
A combinação dessas três peças levou à nossa interrupção. Descrevemos a sua progressão abaixo:
- As consultas de DNS para o provedor de terceiros começaram a demorar mais do que o normal. Inicialmente, assumimos que isso foi por causa de um servidor DNS externo mal configurado fora do controle da Uber.
- Em seguida, o serviço de login não conseguiu alcançar não apenas esses provedores, mas também o serviço de senha interno e todos os serviços dentro da rede, mesmo no localhost.
- Ao mesmo tempo, confirmamos uma interrupção de um de nossos provedores. Uma consulta de DNS para o seu endpoint confirmou que os tempos de resposta do DNS aumentaram de dezenas de milissegundos para dezenas de segundos.
Durante a interrupção, percebemos que o login em um dos nossos centros de dados não foi afetado e conseguimos mitigar a interrupção em minutos, movendo o tráfego do cliente para um centro de dados não afetado. No entanto, ainda ficamos confusos quanto ao motivo pelo qual a interrupção ocorreu em primeiro lugar.
Análise de causa raiz
Resolver localhost para ::1 (que é necessário para se conectar ao sidecar local) envolve chamar um getaddrinfo(3) síncrono. Essa operação é feita em um thread pool dedicado (com um padrão de tamanho 4 no Node.js).
Descobrimos que essas longas respostas de DNS tornaram impossível que o thread pool servisse rapidamente as conversões localhost para :: 1. Como resultado, nenhuma das nossas consultas de DNS passou (mesmo para o localhost), o que significa que nosso serviço de login não conseguiu se comunicar com o sidecar local para testar combinações de nome de usuário e senha, nem chamar outros provedores. Do ponto de vista do aplicativo da Uber, nenhum dos métodos de login funcionou e o usuário não conseguiu acessar o aplicativo.
Para evitar que isso aconteça no futuro na Uber e em outros lugares, criamos uma solução de código aberto para testar se a linguagem de um serviço é ou não é afetado por esse tipo de interação de DNS, além de montar uma série de medidas cautelares para evitar esse tipo de interrupção, ambos apresentados na nossa próxima seção.
Nossa solução: Denial by DNS
Depois de realizar pesquisas sobre a forma como o nosso agendamento de DNS causou essa interrupção, nós decidimos contribuir com algumas de nossas descobertas para a comunidade de código aberto por meio do Denial by DNS, nossa solução para testar se a linguagem do seu serviço é ou não suscetível a uma DoS por interrupção de DNS. Para testar se a sua linguagem é afetada, escreva um programa que siga estas simples etapas:
- Chame http://localhost:8080. Esta chamada deve sempre funcionar; a falha de fazer isso significa que há um erro no teste.
- Chame http://example.org N vezes em paralelo; não espere o resultado. N geralmente é um pouco mais do que o tamanho padrão do thread pool.
- Aguarde alguns segundos para garantir que todas as chamadas estejam programadas.
- Chame http://localhost:8080. Essa chamada será bem sucedida se o aplicativo não for vulnerável.
Scripts verificam o número de vezes que http://localhost:8080 é chamado:
- 0: há um erro com a configuração, pois o script deve ter sucesso pelo menos uma vez.
- 1: o aplicativo é vulnerável, em outras palavras, a primeira invocação foi bem sucedida enquanto a segunda falhava.
- 2: o aplicativo não é vulnerável.
Como parte deste exercício, testamos os serviços nos ambientes erlang, Go, Node.js e Tornado para determinar se o agendamento M: N é “seguro” (ou seja, não causa problemas de confiabilidade do DNS) durante esses tempos de execução:
| Nome | Comentário | Segurança |
| erlang-httpc | Erlang 20 com inets httpc | inseguro |
| golang-http | Golang 1.9 com ‘net / http’ do stdlib | seguro |
| nodejs-http | Node 8.5 com ‘http’ do stdlib | inseguro |
| python3-tornado | Python 3.5.3 com Tornado 4.4.3 | inseguro |
Com a nossa nova ferramenta, tudo o que você precisa é executar um teste simples para determinar se o seu tempo de execução é ou não afetado pelo agendamento M:N. Além de usar o Denial by DNS, existem algumas outras táticas que podem ser tomadas para evitar interações de linguagem de DNS potencialmente precárias.
Evite as chamadas de sistema getaddrinfo() inteiramente
Para evitar o bloqueio do tempo de execução com getaddrinfo(3), pode-se resolver endereços DNS evitando a chamada inteiramente. Por exemplo, node-dns é um resolvedor de DNS escrito em JavaScript puro, o que evita esse problema. Observe que as implementações não-libc podem retornar resultados diferentes do que chamadas nativas.
Substitua domínios bem conhecidos por endereços IP
Para manter o serviço conectado a sistemas locais (por exemplo, através de um sidecar no localhost), pode-se substituir localhost por ::1 ou 127.0.0.1. Esta mudança facilita os sintomas de exaustão de recursos; enquanto o tráfego externo de saída que depende do DNS será bloqueado, os endpoints internos pré-configurados continuarão funcionando. Ainda assim, esta não é uma solução completa para o problema; isso só ajuda quando o subconjunto das chamadas de saída (no nosso caso, dentro do mesmo centro de dados) não depende do DNS.
Use uma linguagem não afetada
Durante nossa pesquisa post-mortem, testamos alguns tempos de execução com agendamento M:N e verificamos que alguns deles não são afetados. Embora a reescrita de serviços existentes a um tempo de execução não afetado possa ser uma solicitação pesada para prevenir esse problema, pode ser útil considerar antes de desenvolver um novo sistema que irá se conectar com serviços de terceiros.
Outras conclusões
Embora a mitigação de incidentes tenha sido rápida e bem sucedida, a falha do centro de dados é considerada o último recurso. Após nossa análise da interrupção, adicionamos uma técnica de atenuação mais leve se isso acontecer novamente: um sinalizador de configuração de tempo de execução para desativar a funcionalidade que depende de serviços externos. Com alguns cliques, podemos desativar qualquer um dos nossos provedores de terceiros e mitigar o problema para o restante dos usuários sem mover todo o nosso tráfego para outro centro de dados.
Próximos passos
Bancando o detetive para descobrir a causa raiz de uma DoS pela interrupção de DNS nos permitiu criar um ambiente mais estável para facilitar experiências melhores nos aplicativos da Uber, independentemente de como os usuários escolham acessá-los. Esperamos que você considere nosso teste (e conselho) útil para lidar com esse tipo de interrupção em seus próprios projetos!
Se você estiver usando um tempo de execução com agendamento M:N, nós encorajamos você a aplicar o nosso teste para determinar se o seu tempo de execução está ou não afetado e enviar um pedido de extração para o nosso repositório, para que outros também possam se beneficiar.
Se a solução de problemas dos serviços da Web em escala atrai você, considere candidatar-se a um cargo em nossa equipe.
No momento da interrupção, Motiejus Jakštys era engenheiro de software na Uber’s Marketplace team, o grupo que mantém o Ringpop. Atualmente, é engenheiro de software na Uber’s Foundations Platform, com sede em Vilnius, na Lituânia.
***
Este artigo é do Uber Engineering. Ele foi escrito por Motiejus Jakštys. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/denial-by-dns/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?