

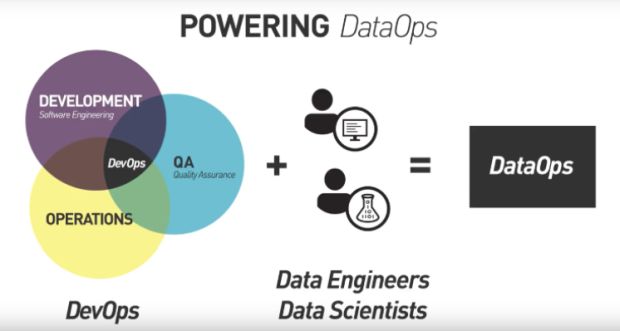
Sem maiores delongas, o DataOps é: o contexto da aquisição, armazenamento, processamento, monitoramento de qualidade e performance, melhoria, e entrega de informações ao usuário final, de forma contínua e confiável, naquela orquestração que dá gosto de ver!
A descrição inicial poderia até ser um pouco maior, mas, iniciemos com um baby step.
Sua inspiração parte do conceito de DevOps (Software Development and Software Operation), que pauta-se no princípio de que as equipes de desenvolvimento e a de infraestrutura devem ter meios de gerir seus produtos, a fim de que tudo corrobore para uma entrega contínua do software e uma disponibilidade perrene dos serviços.
Há um manifesto DataOps que exprime essa vontade da comunidade em extrair e refinar (ETL e Analytics!) o novo petróleo (os dados) e entregá-lo (relatórios/dashboards/análise preditiva) na bomba do posto (self service) a um preço camarada! Álcool ou gasolina? Relatório simples ou dashboard? Histórico ou predição?
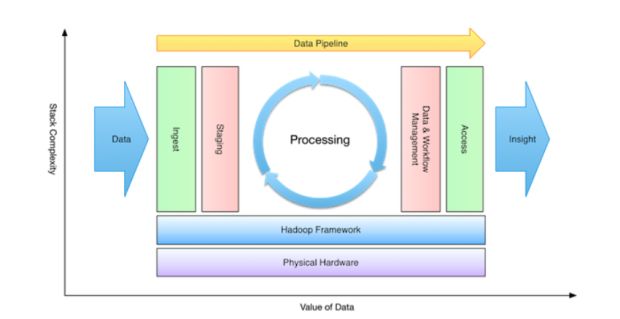
O primeiro e mais importante produto que o contexto DataOps deve gerar, segundo o manifesto, é – justamente – o de satisfazer a necessidade de nosso cliente continuamente. Não adianta utilizar-se das melhores ferramentas do ecossistema Hadoop, das ferramentas próprias das nuvens privadas, e não gerar valor para o cliente.
O pipeline DataOps é para gerar valor ao negócio do cliente!
Um dos 10 sinais de maturidade em Data Science, elencadas no livro Ten Signs of Data Science Maturity (Peter Guerra & Kirk Borne, O’Reilly), indica que uma delas é a cultura DataOps!
O DataOps é, de fato, orientar-se para a cultura dos dados, daí nesse contexto, o DevOps destina-se como uma subproduto utilizado pelo DataOps – ou melhor, equipes que trabalham juntas! – pois teremos a aquisição de dados por meio dos softwares internos de uma corporação – com toda a beleza da orquestração de testes e deploys automatizados – e depois, a esperteza DataOps em abarcar dados estruturados dos mesmos e outros não estruturados e gerar grandes insights ao usuário final.
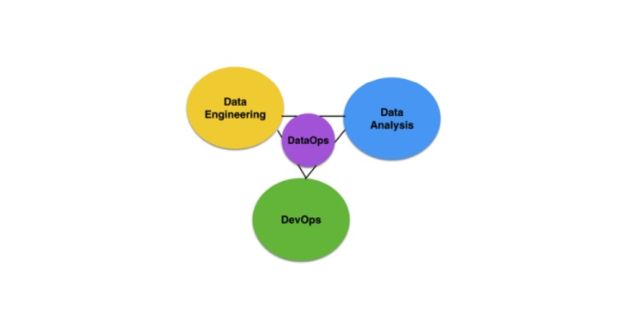
E há de perceber-se que o DataOps é um emaranhado de disciplinas: aquisição e transformação dos dados, governança, cultura orientada à dados, segurança, limpeza e qualidade, armazenamento, clusterização, disponibilidade, análise preditiva, controle de acesso, escalabilidade, entrega contínua, monitoramento, confiabilidade, consistência, backups, análise contínua de silos de dados, dentre diversos outros.
Em 2017, no último mês agora, em novembro, tivemos o DataOps Summit, em Boston, nos Estados Unidos, e a temática envolveu tecnologias, ferramentas e melhores práticas para a gestão dos dados. No Brasil, ainda não tivemos nenhum grande evento expressivo sobre o assunto.
E também, o sentido deste artigo é informar sobre essa nova nomenclatura e seu contexto. E até já existem vários outros “Ops”. Por hora, somente DataOps neste.
Deixo ainda como referência, a discussão sobre DataOps em um podcast do The New Stack Analysts, que entrevista Toph Whitmore, o principal analista da Blue Hill Research. Vale a pena conferir!
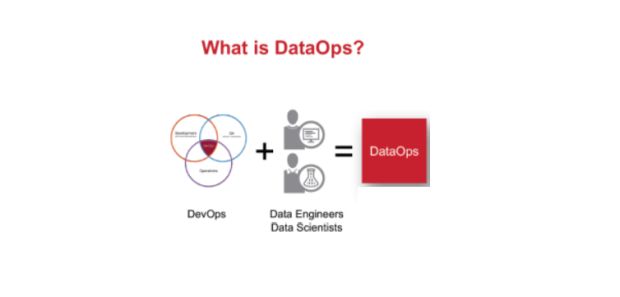
Portanto, os times de DevOps – com Jenkins, Chief, SaltStack, Docker e tutti quanti – e DataOps – com todo o poder do ecossistema Hadoop, por exemplo, e a infraestrutura em geral – trabalham juntos para fazer com que haja uma entrega contínua, não somente de artefatos ou de melhores tecnologias, mas de valor real agregado ao negócio.
Até mais! Hasta la vista, baby! Ou “dados à vista, baby!”

De 0 a 10, o quanto você recomendaria este artigo para um amigo?