

Olá, pessoal!
Regressões constituem uma ferramenta importantíssima em ciência de dados. O objetivo principal do estudo de regressões, em Estatística, é predizer o valor de uma ou mais variáveis em função de outras. Pretende-se prever, por exemplo, o faturamento de uma empresa baseado em seu histórico de investimentos em marketing, ou o consumo de combustível de um veículo em função do tempo. A modelagem matemática da relação entre duas ou mais variáveis é, portanto, a base do estudo de regressões.
Regressões e correlações são técnicas próximas entre si e que envolvem, via de regra, alguma forma de estimar valores futuros de variáveis. Basicamente, a análise de correlação retorna um valor que gradua o nível de relacionamento entre uma variável X e outra variável Y; a análise de regressão retorna um modelo matemático que descreve o relacionamento entre as variáveis X e Y e que usaremos para estimar valores futuros.
Os tipos de correlação e, por consequência, de regressão, podem ser representados didaticamente pela seguinte representação:
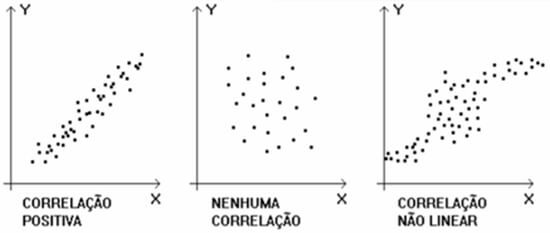
O primeiro exemplo mostra uma correlação entre variáveis em modelo linear. No segundo exemplo, temos uma caso onde não poderemos correlacionar duas variáveis e, portanto, não conseguiremos modelar matematicamente a relação entre elas. Por fim, no último exemplo, temos um caso mais complexo onde podemos visualizar que existe algum grau de correlação entre variáveis, porém o modelo matemático não é linear.
Neste artigo, veremos implementações em Python de regressões lineares apenas. Regressões não-lineares, que na prática constituem nosso ambiente de trabalho mais comum no mercado, serão abordadas em artigos posteriores. É importante ressaltar que não nos aprofundaremos com o devido rigor científico nos conceitos de regressões e correlações, pois nosso objetivo é focar nas implementações práticas destes tópicos usando Python.
O objetivo de uma análise linear, como vimos, é relacionar duas variáveis de modo que, a partir da correlação entre ambas, possamos predizer valores futuros. Desta forma, vamos estruturar uma pequena base de dados CSV em que relacionamos o consumo de combustível de um veículo (em km/l) versus tempo para nosso primeiro exemplo:
| Mês | Consumo |
| 1 | 14,5 |
| 2 | 13,2 |
| 3 | 12,4 |
| 4 | 11,8 |
| 5 | 10,7 |
| 6 | 10,1 |
Para esse dataset, vamos plotar um gráfico bidimensional:
from numpy import loadtxt, zeros, ones, array, linspace, logspace
from pylab import scatter, show, title, xlabel, ylabel, plot, contour
# carregamos o dataset
data = loadtxt('base.csv', delimiter=';')
# plotamos o gráfico
scatter(data[:, 0], data[:, 1], marker='o', c='b')
title('Consumo ao longo do tempo')
xlabel('Mes')
ylabel('Consumo')
show()
O script nos retorna:
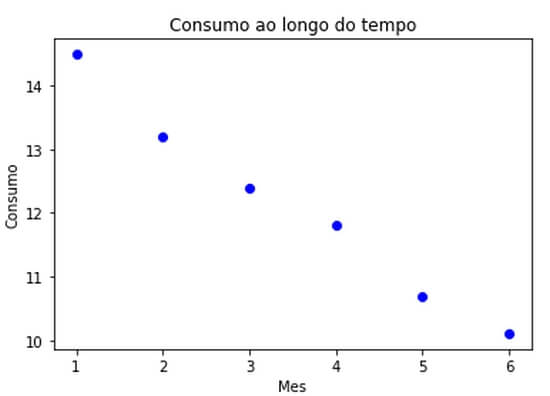
Observamos uma clara relação linear inversa entre tempo e consumo, ou seja, o consumo do veículo aumenta (ou, em raciocínio inverso, a performance diminui) à medida que o tempo passa.
Para uma análise mais aprofundada da aplicação de regressão linear, vamos usar alguns datasets conhecidos fornecidos pelo pacote sklearn. O uso de datasets didáticos é bastante útil quando estudamos conceitos estatísticos em Python. Podemos, inclusive, tratar o uso destes datasets já estruturados facilmente através de sklearn.datasets aplicando datasets.load.[dataset]().
Neste artigo, usaremos dois datasets bastante usados para fins didáticos: iris e diabetes.
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model from sklearn.cross_validation import train_test_split # carregamos os datasets dados = datasets.load_diabetes() # utilizamos um recurso x = dados.data[:, np.newaxis] x_temp = x[:, :, 2] y = dados.target # dividimos a base de dados entre treino e teste x_train, x_test, y_train, y_test = train_test_split(x_temp, y) # aplicamos o modelo de regressão linear usando LinearRegression() modelo = linear_model.LinearRegression() # treinamos o modelo usando os dados de treinamento modelo.fit(x_train, y_train) # coeficientes... modelo.coef_ # array([ 938.23786125]) # erro quadrático médio np.mean((modelo.predict(x_test) - y_test) ** 2) # 4039.98152578 # variância modelo.score(x_test, y_test) # 0.37048553047 # plotamos os resultados definindo algumas características do gráfico plt.scatter(x_test, y_test, color='black') plt.plot(x_test, modelo.predict(x_test), color='blue', linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()
O script acima nos retorna:
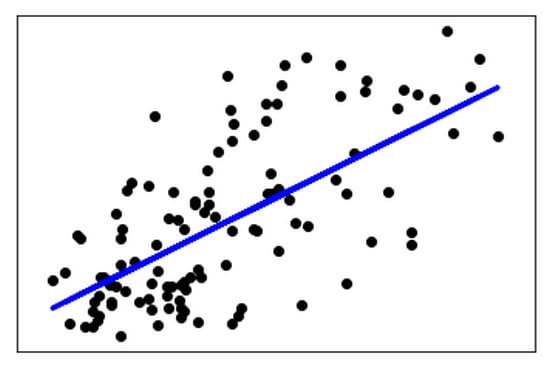
Podemos observar que esse é um caso clássico de correlação positiva, como vimos no início deste texto. Usamos LinearRegression() para aplicar a plotagem bidimensional do modelo de regressão linear. A função tenta desenhar uma linha reta com o objetivo de minimizar a soma residual de quadrados entre as respostas observadas no conjunto de dados e as respostas previstas na aproximação linear.
Podemos aproveitar a capacidade analítica dos datasets sobre os quais falamos anteriormente para verificarmos o resultado usando o conjunto de dados Iris:
dados = datasets.load_iris()
O resultado, neste caso, será:
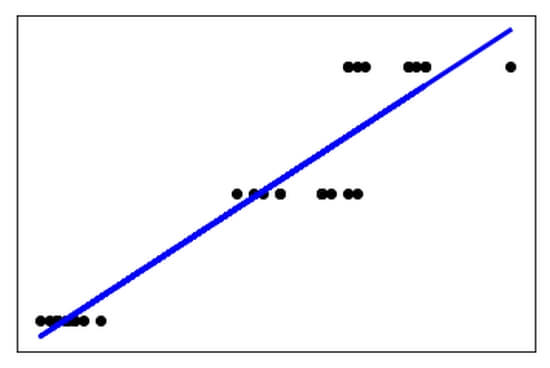
Novamente, o objetivo de LinearRegression() é encontrar um caminho linear para o modelo. Ao compararmos os dois gráficos, temos:
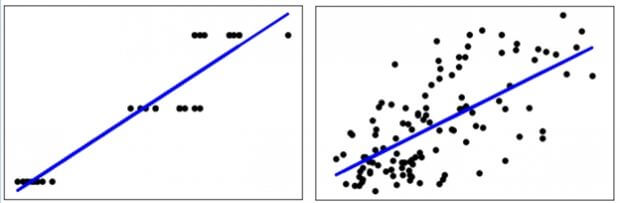
O dataset Iris possui universo de amostra mais reduzido. Observamos que o retorno do erro quadrático médio (MSE, Mean Square Error) em np.mean((modelo.predict(x_test) – y_test) ** 2) é da grandeza de 0.07 para Iris, enquanto o dataset Diabetes o mesmo retorno é da grandeza de 4039.98. Isso traduz exatamente a impressão visual que temos ao colocar lado a lado ambas as regressões e visualizarmos o residual das amostras.
O estudo de regressões é fundamental no campo da ciência de dados e Big Data. Os modelos matemáticos baseados em regressões constituem a forma mais tradicional de iniciar um projeto de data science e possuem uma infinidade de variações e abordagens. A base de aplicações de machine learning, conceito fundamental em Big Data e sobre o qual nos aprofundaremos nos próximos artigos, é a construção de um modelo matemático capaz de regular a relação entre variáveis de um universo de dados reais para que um algoritmo seja capaz de ensinar um sistema a tomar decisões futuras.
Em nossos próximos textos, seguiremos abordando novos tipos de regressões em exemplos práticos. Até lá!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?