
Hoje em dia, é muito comum utilizarmos a internet para uma infinidade de coisas, como fazer uma compra, acessar bancos, ver notícias, acessar as redes sociais, entre outros. Atualmente, é a comunicação mais rápida e mais utilizada por nós, pois está muito mais acessível do que em 1992, onde o número de computadores conectados era muito menor, sendo utilizada somente para fins acadêmicos e militares.
E durante esse desenvolvimento, surgiu a Web 2.0, que ampliou o envolvimento do usuário na web, trazendo conteúdos ricos e dinâmicos. De uma forma geral, Paul Miller descreve: “Estamos vendo o surgimento de serviços baseados na Web que extraem dados de uma ampla gama de sistemas back-end para oferecer valor aos usuários, quando, onde e na forma que eles exigem. Estamos vendo relações ad hoc sendo formadas por e para esses serviços no ponto de necessidade, em vez da criação humana e custosa de contratos ou acordos de nível de serviço. Estamos vendo desagregação de conteúdo e serviços em componentes que são muito mais significativos para o usuário (e potencialmente muito mais valioso para o provedor), juntamente com a desintermediação dos Gate Keepers a favor do acesso direto aos recursos visíveis na Web. Estamos vendo recipientes passivamente passivos de conteúdo que começam a se envolver e combinar e recombinar o que eles são dados de maneiras novas e interessantes” (artigo Ariadne.ac.uk).
Em seu artigo, ele referencia algumas palavras sobre a Web 2.0 do ponto de vista do pai da web, Tim Banners Lee: “A Web 2.0 é a rede como plataforma, abrangendo todos os dispositivos conectados; As aplicações da Web 2.0 são aquelas que aproveitam ao máximo as vantagens intrínsecas dessa plataforma: entregar o software como um serviço continuamente atualizado que melhora quanto mais às pessoas o usam, consumindo e remixando dados de várias fontes, incluindo usuários individuais, ao mesmo tempo em que fornecem os seus próprios dados e serviços em uma forma que permite a remixação por outros, criando efeitos de rede através de uma ‘arquitetura de participação’ e indo além da metáfora da página da Web 1.0 para fornecer experiências de usuário ricas”.
O crescimento da Web proporcionou uma mudança muito significativa no comportamento das pessoas, mudamos a maneira como nos comunicamos, compramos, vendemos, e tudo se tornou mais fácil e rápido quando o assunto é internet. Houve um aumento significativo no ramo corporativo, onde milhares de serviços e produtos foram sido criados. E quanto mais a web vem crescendo, muita mão de obra vem sendo necessitada, e nós, como desenvolvedores, temos a obrigação de saber como as coisas funcionam por trás de tudo isso, e como podemos achar melhores soluções para tais problemas.
Mas por debaixo de tudo isso, como a internet realmente é? Para qualquer desenvolvedor de aplicações web ou até mesmo móbile, é importante saber como tudo isso funciona por debaixo dos panos. Para começar, vamos conhecer e entender melhor os protocolos.
O que é HTTP?
Hypertext Transfer Protocol (Protocolo de Transferência de Hypertexto) é um protocolo de comunicação que permite enviar e receber informações na web. A troca de informações entre um browser (navegador) e um servidor web, é toda feita através desse protocolo, que foi criado especificamente para a World Wide Web (www).
Quando utilizamos um browser para acessar algum site, o navegador representa o (cliente) e o site que nos apresenta a informação o (servidor), trata-se de uma comunicação client-server, onde o cliente faz uma solicitação ao servidor e o servidor retorna a resposta ao cliente.
“O HTTP funciona como um protocolo de requisição-resposta no modelo computacional cliente-servidor. Um navegador web, por exemplo, pode ser o cliente e uma aplicação em um computador que hospeda um sítio da web pode ser o servidor. O cliente submete uma mensagem de requisição HTTP para o servidor. O servidor, que fornece os recursos, como arquivos HTML e outros conteúdos, ou realiza outras funções de interesse do cliente, retorna uma mensagem resposta para o cliente. A resposta contém informações de estado completas sobre a requisição e pode também conter o conteúdo solicitado no corpo de sua mensagem” (Wikipédia).
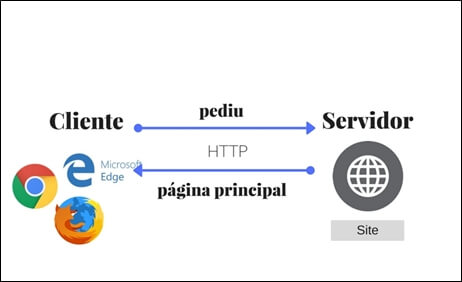
Como pode ser visto no modelo acima, o protocolo HTTP funciona como um protocolo de requisição e resposta no modelo computacional entre cliente e servidor. O cliente faz uma solicitação ao servidor e o servidor nos traz a página com a resposta.
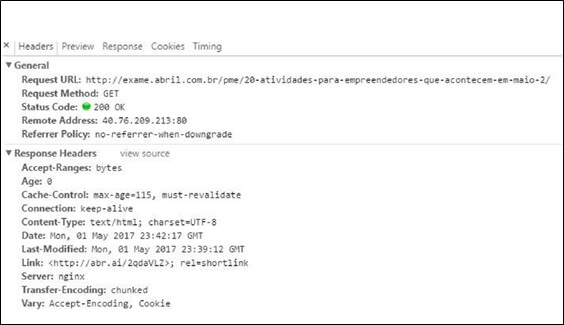
As requisições recebem um código de status e é a partir deste código que conseguimos identificar se o status desta solicitação foi bem sucedido ou se houve algum erro ao retornar uma resposta do servidor. Exemplo: quando o servidor não localizou determinada página, ou apenas um status de informação que a solicitação foi bem realizada com sucesso.
Listas de códigos HTTP:
| Comando | Descrição |
| Get | Pedido do recurso situado no URL especificado |
| Head | Pedido do cabeçalho do recurso situado na URL especificada |
| Post | Envio de dados ao programa situado na URL especificada |
| Put | Envio de dados à URL especificada |
| Delete | Remoção do recurso situado na URL especificada |
Códigos de erros:
| Código | Mensagem | Descrição |
| 100 | Continuar | Isso significa que o servidor recebeu os cabeçalhos da solicitação, e que o cliente deve proceder para enviar o corpo do pedido (no caso de haver um pedido, um corpo deve ser enviado, por exemplo, um POST pedido). Para ter um cheque do servidor se o pedido pode ser aceito com base no pedido de cabeçalhos sozinho, o cliente deve enviar Esperar: 100-continue como um cabeçalho no seu pedido inicial e verifique se a 100 Continuar código de status é recebido em resposta antes de permanente (ou receber 417 Falha na expectativa e não continuar). |
| 101 | Mudando protocolos | Isso significa que o servidor recebeu os cabeçalhos da solicitação, e que o cliente deve proceder para enviar o corpo do pedido (no caso de haver um pedido, um corpo deve ser enviado, por exemplo, um POST pedido). É ineficiente enviar um corpo grande para o servidor se o pedido já foi rejeitado com base na inadequação do cabeçalho. É possível fazer com que o servidor valide o pedido baseado no cabeçalho. Para isso o cliente deve enviar wait: 100- continue como cabeçalho no seu pedido inicial e verificar se o código de status 100 continue é recebido (ou se recebe falha 417). |
| 200 | OK | Padrão de resposta para solicitações HTTP sucesso |
| 201 | CREATED | O pedido foi cumprido e resultou em um novo recurso que está sendo criado. |
| 202 | ACCEPTED | O pedido foi aceito para processamento, mas o tratamento não foi concluído. O pedido poderá, ou não, ser posto em prática, pois pode ser anulado quando o processamento ocorre realmente. |
| 203 | PARTIAL INFORMATION | O servidor processou a solicitação com sucesso, mas está retornando informações que podem ser de outra fonte. |
| 204 | NO RESPONSE | O servidor processou a solicitação com sucesso, mas não é necessária nenhuma resposta. |
| 205 | RESET CONTENT | O servidor processou a solicitação com sucesso, mas não está retornando nenhum conteúdo. Ao contrário das 204, esta resposta exige que o solicitante redefina a exibição de documento. |
| 206 | PARTIAL CONTENT | Trata-se de uma resposta a um pedido que comporta o cabeçalho range. O servidor deve indicar o cabeçalho content-range. |
| 30x | Redirecionamento | Estes códigos indicam que o recurso não está mais no lugar indicado. |
| 301 | MOVED | Os dados pedidos foram transferidos para um novo endereço. |
| 302 | FOUND | Os dados pedidos são de uma nova URL, mas talvez tenham sido deslocados desde então. |
| 303 | METHOD | Isto implica que o cliente deve tentar um novo endereço, tentando outro método além do GET. |
| 304 | NOT MODIFIED | Se o cliente efetuou um comando GET condicional (perguntando se o documento foi alterado desde a última vez) e se o documento não tiver sido alterado, ele devolve este código. |
| 40x | Erro devido ao cliente | Estes códigos indicam que o pedido está incorreto. |
| 400 | BAD REQUEST | A sintaxe do pedido está mal formulada ou impossível de validar. |
| 401 | UNAUTHORIZED | O parâmetro da mensagem dá as especificações das formas de autorização aceitáveis. O cliente deve reformular o seu pedido com os dados de autorização corretos. |
| 402 | PAYMENT REQUIRED | O cliente deve reformular o seu pedido com os dados de pagamento corretos. |
| 403 | FORBIDDEN | O acesso ao recurso foi recusado. |
| 404 | NOT FOUND | O recurso requisitado não foi encontrado, mas pode ser disponibilizado novamente no futuro. As solicitações subsequentes pelo cliente são permitidas. |
| 405 | METHOD NOT ALLOW | Foi feita uma solicitação de um recurso usando um método de pedido que não é compatível com esse recurso, por exemplo, usando GET em um formulário, que exige que os dados a serem apresentados vissem POST, PUT ou usassem um recurso somente de leitura. |
| 50x | Erro devido ao servidor | Estes códigos indicam que houve um erro interno no servidor. |
| 500 | INTERNAL ERROR | O servidor encontrou uma condição inesperada que o impediu de satisfazer o pedido. |
| 501 | NOT IMPLEMENTED | O servidor não suporta o serviço pedido. |
| 502 | BAD GATEWAY | O servidor recebeu uma resposta inválida por parte do servidor que tentava acessar agindo como uma passarela ou um Proxy. |
| 503 | SERVICE UNAVAILABLE | O servidor não pode responder no momento, pois o tráfego está muito denso (todas as linhas do seu correspondente estão ocupadas, tente novamente). |
| 504 | GATEWAY TIMEOUT | A resposta do servidor demorou muito em relação ao que o gateway foi preparado para recebê-la (o tempo que lhe estava destinado esgotou-se). |
Segurança na Web HTTPs
A internet tornou mais prático à rotina das pessoas e com esse aumento significado da rede, nesse contexto é preciso estar atento a segurança dos sistemas web. Por que a segurança na web é tão importante? Porque muitos ataques e cybercrimes vêm ocorrendo com muita frequência. Logo, é importante estarmos atentos a todas as informações de segurança e sabermos como usar a web de forma segura.
HTTPs
HTTPS (Hyper Text Transfer Protocol Secure – protocolo de transferência de hipertexto seguro) é uma implementação do protocolo HTTP sobre uma camada adicional de segurança, que utiliza o protocolo SSL/TLS. Essa camada adicional permite que as informações sejam transmitidas através de uma conexão segura (criptografada).
Em seu artigo, Pastore expõe uma definição melhor sobre o que é o protocolo HTTPs. “HTTPs é a combinação do protocolo HTTP com o SSL (Secure Sockets Layer). É a maneira mais comum, atualmente, de trafegar documentos via HTTP de maneira segura. Provê encriptação de dados, autenticação de servidor, integridade de mensagem e autenticação de cliente. Um site seguro, que usa o HTTPs, deve possuir três componentes essenciais para a comunicação segura: o servidor, o software seguro (que faz o trabalho de criptografia) e o certificado de assinatura (assinatura digital). (Pablo Pastore)”.
- SSL – Protocolo de Camadas de sockets segura
- TLS – Protocolo de Segurança da camada de transporte
Certificado digital
É um arquivo de computador usado para identificar e autenticar e sites e serviços eletrônicos, que contém um conjunto de informações referentes à entidade para qual o certificado foi emitido (seja uma empresa, pessoa física ou um computador), mais a chave pública referente à chave privada que se acredita ser de posse unicamente da entidade especificada no certificado. Quando você acessa o site do seu banco ou faz alguma compra pela internet, o que torna o site seguro e confiável é o certificado digital e HTTPs no canto da página.
Em um artigo feito pela IBM em seu site, “um certificado digital assinado é um método padrão de mercado para verificação da autenticidade de uma entidade, como um servidor, um cliente ou um aplicativo. Para assegurar a segurança máxima, uma autoridade de certificação de terceiros fornece um certificado. Um certificado contém as seguintes informações para verificação da identidade de uma entidade:
- Informações organizacionais – Esta seção do certificado contém informações que identificam, de forma exclusiva, o proprietário do certificado, como nome e endereço organizacionais. Essas informações são fornecidas ao gerar um certificado com um utilitário de gerenciamento de certificado.
- Chave pública – O receptor do certificado usa a chave pública para decifrar o texto criptografado que é enviado pelo proprietário do certificado para verificar sua identidade. Uma chave pública possui uma chave privada correspondente que criptografa o texto.
- Nome distinto da autoridade de certificação – O emissor do certificado se identifica com essas informações.
- Assinatura digital – O emissor do certificado o assina com uma assinatura digital para verificar sua autenticidade. O certificado de autoridade de certificação correspondente compara a assinatura para verificar se a origem do certificado é uma autoridade de certificado confiável.” (IBM Security Identity Manager).
Segurança digital: chaves públicas e chaves privadas
Na criptografia de chave pública, duas chaves diferentes são usadas para criptografar e descriptografar informações. A chave privada é uma chave conhecida apenas por seu proprietário, enquanto a chave pública pode ser disponibilizada a outras entidades na rede.
A chave pública é usada, por exemplo, para encriptar puro texto ou para verificar uma assinatura digital, já a chave privada é utilizada para o oposto disso – nesse exemplo para descriptar um texto ou para criar uma assinatura digital. O termo assimétrico vem do uso de diferentes chaves para realizar essas funções opostas, cada uma dependente da outra.
Solicitação entre Cliente e Servidor
Quando acessamos a web para fazer alguma compra, acessar um site de banco, comprar passagens aéreas ou até simplesmente clicar em algum link de notícia, estamos fazendo uma solicitação ao servidor. Foi como dito logo acima, uma comunicação feita entre cliente e servidor (sendo cliente, o navegador e o servidor, o site). Agora que já sabemos como funciona o protocolo HTTP, vamos entender melhor o que são as requisições.
A comunicação feita em cliente e servidor é baseada em requisição ou, por assim dizer, (request) e respostas (responses). Vejamos:
Conteúdo de uma solicitação:
- Método HTTP;
- Página que será acessada;
- Parâmetros do formulário.
Conteúdo da resposta:
- Código de status (informa se a solicitação foi realizada com sucesso ou não);
- Tipo de Conteúdo (HTML, imagem, textos etc);
- Conteúdo (HTML, real, imagem etc).
Como vimos na (Figura 2), a requisição do cliente é composta pelos seguintes campos:
- Uma linha inicial: (Request-Line);
- Linhas do cabeçalho: (Request-header);
- Uma linha em branco obrigatória e um corpo de mensagem opcional;
- A linha inicial de uma requisição é composta por três partes separadas por espaços: método (Method), a identificação do URI (Request-URL) e a versão do HTTP (HTTP-Version).
Métodos HTTP
GET – Solicita ao servidor um recurso chamado na URI. No momento em que chamamos a primeira vez, a página ou até mesmo quando clicamos em links ou digitamos o endereço no navegador, estamos pegando informações do servidor, ou seja, o método utilizado é o GET. Vejamos alguns exemplos: listar produtos, visualizar um produto, chamar um recurso ou uma página.
POST – Este método é chamado para submeter dados, ou seja, quando preenchemos um formulário de cadastro, os dados são enviados parâmetro no corpo da solicitação onde já são codificados. Ex: adicionar um produto, adicionar informações a um recurso ou criar um novo recurso.
HEAD – Semelhante ao método GET, o servidor apenas retorna a linha de resposta e os cabeçalhos de resposta, sem ter que retornar todo o conteúdo.
PUT – Este método adiciona ou (modifica) um recurso da URI passada. Ex: para atualizar um produto, há uma diferença entre o POST e o PUT. Em POST, a URI significa o lugar em que serão tratadas às informações; já no PUT significa o lugar onde a informação será adicionada.
DELETE – Este método apaga um arquivo do servidor. Ex: remover um produto.
OPTIONS – Este método recupera os métodos HTTP que o servidor aceita.
TRACE – Este método permite depurar as requisições.
Tipos de Protocolo HTTP
- FTP – File Transfer Protocol é utilizado para transmissão e envio de arquivos (upload e download).
- SMTP – Simple Message Transfer Protocol permite o envio de mensagens a um servidor de e-mail.
- POP – Post Office Protocol permite que o cliente acesse e manipule mensagens de e-mail de um servidor para outro.
- IMAP – Internet Message Access Protocol permite que o cliente acesse e manipule mensagem de e-mail de um servidor para outro, ou mesmo processo do protocolo POP, mas com algumas configurações diferentes.
Serviços na Web com Rest
REST – (Representation State Transfer ) é um design de arquitetura construído para servir aplicações em rede. A aplicação mais comum de REST é a própria World Wide Web. Os serviços da Web compatíveis com REST permitem que os sistemas solicitantes acessem e manipulem representações textuais de recursos Web usando um conjunto uniforme e predefinido de operações em estado (stateless). A REST tem sido aplicada para descrever a arquitetura web desejada, identificar problemas existentes, comparar soluções alternativas e garantir que extensões de protocolo não violem as principais restrições que fazem da Web um sucesso. – Fonte: (Wikipédia)
O REST consiste em retornar todas as informações necessárias na resposta para o cliente, e essa forma de retorno pode ser um formato JSON ou XML.
JSON
De acordo com (Mauricio Silva p.176), “Trata-se de uma técnica Java Script que usa sintaxe leve e simples para armazenar dados. Tal como XML, JSON está estruturado de modo a ser facilmente lido, interpretado e processado por máquinas”. Para (Bem Smith p.66), “O JSON é conhecido como padrão para troca de dados, o que implica que ele pode ser usado como formato para dados sempre que houver uma troca, que pode ocorrer entre o navegador e o servidor, e até mesmo entre um servidor e outro, se for o caso. É claro que esses são os únicos meios para troca de JSON, e limitar essa troca a esses dois casos seria excessivamente restrutivo”.
Em outras palavras, JSON é um modelo para armazenamento e transmissão de informações no formato texto. Apesar de ser muito simples, tem sido bastante utilizado em aplicações web devido a sua capacidade de estruturar informações de uma forma bem mais compacta seguida de modelo XML.
Exemplo de retorno json:
{
aluno: “Jéssica Nathany”,
ativo: “true”,
curso: “tecnologia”,
sexo: “Feminino”,
Idade: “27”
}
XML
XML – (Extended Markup Language) é um padrão para formatação de dados, ou seja, uma maneira de organizar informações. O XML e suas tecnologias relacionadas oferecem uma arquitetura robusta para integração, manipulação, intercâmbio e apresentação de documentos. Seu propósito principal é a facilidade de compartilhamento de informações através da internet.
HTTP/2
HTTP/2 é a nova versão do HTTP 1.1, que foi criado com o objetivo de deixar sua aplicação mais rápida e corrigindo eventuais erros do protocolo HTTP1.1. O HTTP/2 foi criado baseado no SPDY, um protocolo experimental desenvolvido pelo Google e anunciado no meio de 2009, com objetivo de tentar reduzir a latência no carregamento das páginas deixando o carregamento 50% mais rápido e também tornar o desenvolvimento deste protocolo em código aberto.
“Alterações primárias de HTTP / 2 do foco HTTP / 1.1 no desempenho melhorado. Alguns recursos principais, como multiplexação, compactação de cabeçalho, priorização e negociação de protocolos, evoluíram a partir do trabalho feito em um protocolo aberto anterior, mas não padrão, chamado SPDY. O Chrome suportou o SPDY desde o Chrome 6, mas como a maioria dos benefícios está presente no HTTP / 2, é hora de dizer adeus. Planejamos remover o suporte para o SPDY no início de 2016 e também remover o suporte para a extensão TLS chamada NPN em favor do ALPN no Chrome ao mesmo tempo. Os desenvolvedores de servidores são fortemente encorajados a mudar para HTTP / 2 e ALPN.
Estamos felizes por ter contribuído para o processo de padrões abertos que levaram ao HTTP / 2, e esperamos ver ampla adoção, dado o amplo envolvimento da indústria em padronização e implementação. Também esperamos novos avanços em protocolos fundamentais da internet que levem a uma internet mais rápida e segura para todos.” (Blog Chromium).
O HTTP/1.1 por ser muito eficiente, está tendo dificuldades e lentidão ao processar as aplicações, devido a estas aplicações consumirem muitos recursos, ou seja, devido às grandes mudanças e da maneira como usamos a web hoje, o protocolo HTTP/1.1 já não atende da mesma forma e com a mesma rapidez como antes.
Foi pensando nesta questão que vem se estudando uma maneira mais rápida para atender nossas necessidades, tanto dispositivos móveis, computadores e até mesmo IOT (Internet das Coisas).
Referências
- Wikipedia
- Artigo Ariadne.ac.uk
- Lista de código de status HTTP
- Pablo Pastore
- IBM Security Identity Manager
- Mauricio Silva Ajax Com JQuery (2009 – Editora Novatec)
- Bem Smith (2015 – Editora Novatec)
- Developers Google
- Blog Chromium

De 0 a 10, o quanto você recomendaria este artigo para um amigo?