

Hoje vamos dar continuidade à primeira parte deste artigo, onde apresentamos o Michelangelo, alguns casos de uso do produto e o fluxo de trabalho deste poderoso novo sistema de ML-as-a-service. Para ler a Parte 01, clique aqui.
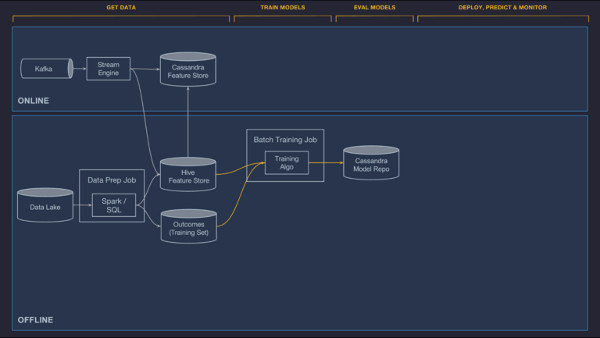
Domain specific language para seleção e transformação de recursos
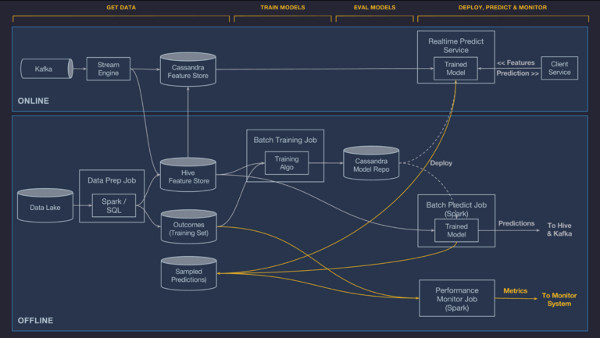
Muitas vezes, os recursos gerados por pipelines de dados ou enviados a partir de um serviço de cliente não estão no formato apropriado para o modelo, e valores que precisam ser preenchidos podem estar faltando. Além disso, o modelo pode apenas precisar de um subconjunto de recursos fornecidos. Em alguns casos, isso pode ser mais útil para o modelo transformar um timestamp em uma hora do dia ou dia da semana para melhor captura de padrões sazonais. Em outros casos, os valores dos recursos podem precisar ser normalizados (por exemplo, subtrair a média e dividir pelo desvio padrão).
Para resolver esses problemas, criamos um DSL (domain specific language – linguagem específica do domínio) que os modeladores usam para selecionar, transformar e combinar os recursos que são enviados para o modelo nos tempos de treinamento e de previsão. O DSL é implementado como subconjunto do Scala. É uma linguagem funcional pura com um conjunto completo de funções comumente usadas. Com esse DSL, nós também fornecemos a capacidade para equipes de clientes de adicionar suas próprias funções definidas pelo usuário. Existem funções de acessório que buscam valores de recursos do contexto atual (pipeline de dados, no caso de um modelo offline, ou solicitação atual do cliente, no caso de um modelo online) ou da Feature Store.
É importante notar que as expressões DSL fazem parte da configuração do modelo, e as mesmas expressões são aplicadas no tempo de treinamento e no tempo de previsão para garantir que o mesmo conjunto final de recursos seja gerado e enviado ao modelo em ambos os casos.
Modelos de treinamento
Atualmente, suportamos o treinamento distribuído offline em grande escala de árvores de decisão, modelos lineares e logísticos, modelos não supervisionados (k-means), modelos de séries temporais e redes neurais profundas. Nós regularmente adicionamos novos algoritmos em resposta à necessidade do cliente, e eles são desenvolvidos pelo AI Labs da Uber e outros pesquisadores internos. Além disso, permitimos que as equipes de clientes adicionem seus próprios tipos de modelo, fornecendo treinamento personalizado, avaliação e código de serviço. O sistema de treinamento de modelo distribuído escala para lidar com bilhões de amostras e até pequenos conjuntos de dados para iterações rápidas.
Uma configuração de modelo especifica o tipo de modelo, os hiper-parâmetros, a referência da fonte de dados e as expressões DSL de recursos, bem como os requisitos de recursos de computação (o número de máquinas, a quantidade de memória, o uso ou não de GPUs etc.). Ela é usada para configurar o trabalho de treinamento, que é executado em um cluster YARN ou Mesos.
Depois que o modelo é treinado, as métricas de desempenho (por exemplo, curva ROC e curva PR) são computadas e combinadas em um relatório de avaliação do modelo. No final do treinamento, a configuração original, os parâmetros aprendidos e o relatório de avaliação são salvos em nosso repositório modelo para análise e implementação.
Além de treinar modelos únicos, o Michelangelo é compatível com a pesquisa de hiper-parâmetros para todos os modelos, bem como modelos particionados. Com modelos particionados, partimos automaticamente os dados de treinamento com base na configuração do usuário e, em seguida, treinamos um modelo por partição, voltando a um modelo pai quando necessário (por exemplo, treinando um modelo por cidade e voltando para um modelo de nível de país quando um modelo de nível de cidade preciso não pode ser alcançado).
Os trabalhos de treinamento podem ser configurados e gerenciados através de uma UI da web ou uma API, muitas vezes através do notebook Jupyter. Muitas equipes usam a API e as ferramentas de fluxo de trabalho para agendar o re-treinamento regular de seus modelos.
Modelos de avaliação
Os modelos geralmente são treinados como parte de um processo de exploração metódica para identificar o conjunto de recursos, algoritmos e hiper-parâmetros que criam o melhor modelo para seu problema. Antes de chegar ao modelo ideal para um determinado caso de uso, não é incomum treinar centenas de modelos que acabam não servindo. Embora não sejam usados em última instância na produção, o desempenho desses modelos orienta os engenheiros para a configuração do modelo que resulta no melhor desempenho do modelo. Acompanhar esses modelos treinados (por exemplo, quem os treinou e quando, em que conjunto de dados, com quais hiper-parâmetros etc.), avaliá-los e compará-los entre si são geralmente grandes desafios ao lidar com tantos modelos e oportunidades presentes para que a plataforma adicione muito valor.
Para cada modelo treinado no Michelangelo, armazenamos um objeto versionado em nosso repositório modelo no Cassandra que contém um registro de:
- Quem treinou o modelo
- Início e término do trabalho de treinamento
- Configuração do modelo completo (recursos usados, valores de hiper-parâmetros etc.)
- Referência aos conjuntos de dados de treinamento e teste
- Distribuição e relativa importância de cada recurso
- Métricas de precisão do modelo
- Gráficos e gráficos padrão para cada tipo de modelo (por exemplo, curva ROC, curva PR e matriz de confusão para um classificador binário)
- Parâmetros completos aprendidos do modelo
- Estatísticas resumidas para a visualização do modelo
A informação é facilmente acessível ao usuário através de uma UI da web e programaticamente através de uma API, tanto para inspecionar os detalhes de um modelo individual quanto para comparar um ou mais modelos entre si.
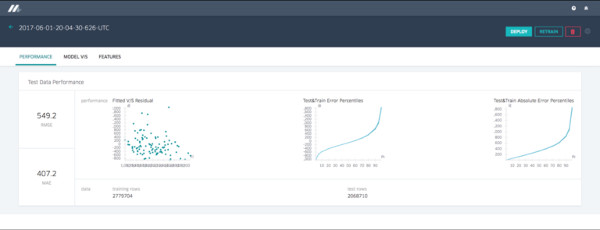
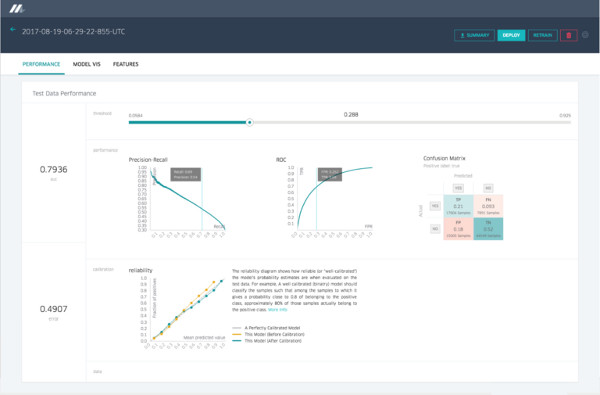
Relatório de precisão do modelo
O relatório de precisão do modelo para um modelo de regressão mostra métricas e gráficos de precisão padrão. Os modelos de classificação exibiriam um conjunto diferente, conforme descrito abaixo nas Figuras 4 e 5:
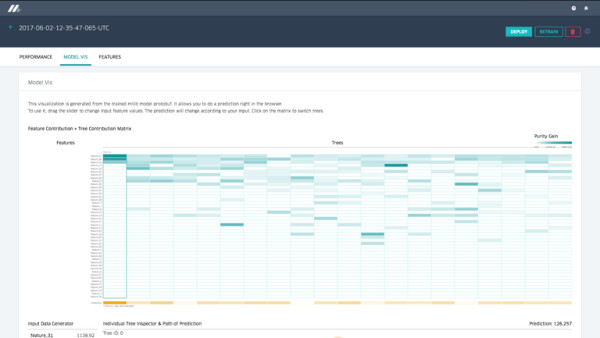
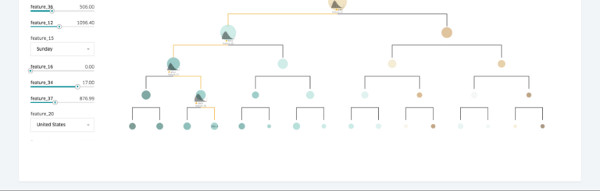
Visualização da árvore de decisão
Para tipos de modelos importantes, fornecemos ferramentas de visualização sofisticadas para ajudar os modeladores a entender por que um modelo se comporta de determinada maneira, além de ajudar a depurá-lo se necessário. No caso dos modelos de árvore de decisão, deixamos o usuário navegar através de cada uma das árvores individuais para ver sua importância relativa para o modelo geral, seus pontos de divisão, a importância de cada recurso para uma determinada árvore e a distribuição de dados em cada divisão, entre outras variáveis. O usuário pode especificar valores de recursos, e a visualização descreverá os caminhos desencadeados pelas árvores de decisão, a previsão por árvore e a previsão geral para o modelo, conforme ilustrado na Figura 6:
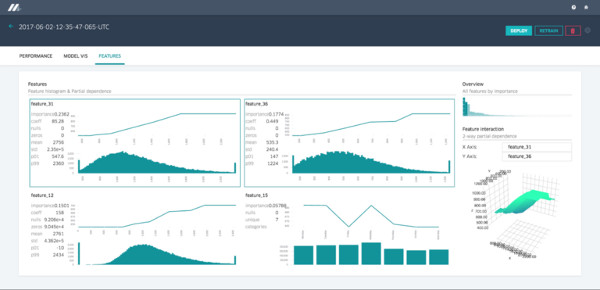
Relatório de recursos
O Michelangelo fornece um relatório de recursos que mostra cada recurso em ordem de importância para o modelo, juntamente com parcelas de dependência parcial e histogramas de distribuição. Selecionar dois recursos permite que o usuário compreenda as interações do recurso como um diagrama de dependência parcial de duas vias, conforme mostrado abaixo:
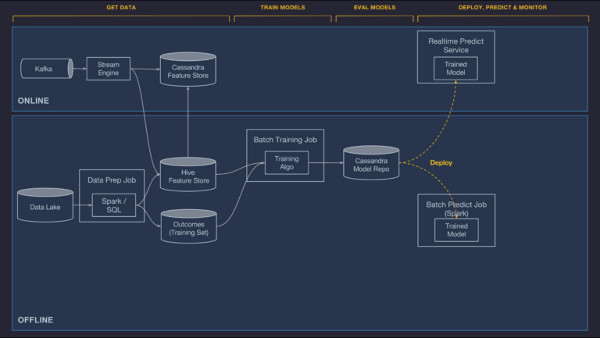
Modelos de implementação
O Michelangelo tem suporte de ponta a ponta para gerenciar a implementação do modelo via UI ou API e três modos nos quais um modelo pode ser implementado:
- Implementação offline. O modelo é implementado em um container offline e é executado em um trabalho Spark para gerar previsões em lote, tanto na demanda quanto em uma programação repetida.
- Implementação online. O modelo é implementado em um cluster de serviço de previsão online (geralmente contém centenas de máquinas por trás de um balanceador de carga), no qual os clientes podem enviar solicitações de previsão individuais ou em lote como chamadas RPC de rede.
- Implementação da biblioteca. Pretendemos lançar um modelo que é implementado em um container de serviço incorporado como uma biblioteca em outro serviço e invocado através de uma API Java (não é mostrado na Figura 8 abaixo, mas funciona de forma semelhante à implementação online).
Em todos os casos, os artefatos de modelo necessários (arquivos de metadados, arquivos de parâmetros do modelo e expressões DSL compiladas) são empacotados em um arquivo ZIP e copiados para hosts relevantes nos datacenters da Uber usando nossa infraestrutura de implementação de código padrão. Os containers de previsão carregam automaticamente os novos modelos a partir do disco e começam a lidar com os pedidos de previsão.
Muitas equipes possuem scripts de automação para agendar a reciclagem e a implementação do modelo regular através da API do Michelangelo. No caso dos modelos de tempo de entrega da UberEATS, o treinamento e a implementação são acionados manualmente por cientistas de dados e engenheiros através da UI da web.
Fazendo previsões
Uma vez que os modelos são implementados e carregados pelo container de serviço, eles são usados para fazer previsões com base em dados de recursos carregados a partir de um pipeline de dados ou diretamente de um serviço de cliente. Os recursos brutos são passados através das expressões DSL compiladas que podem modificar os recursos brutos e/ou buscar recursos adicionais da Feature Store. O vetor de recursos finais é construído e passado para o modelo de pontuação. No caso de modelos online, a previsão é devolvida ao serviço do cliente através da rede. No caso de modelos offline, as previsões são escritas de volta para o Hive, onde elas podem ser consumidas por trabalhos em lotes em downstream ou acessadas pelos usuários diretamente através de ferramentas de consulta baseadas em SQL, conforme descrito abaixo:
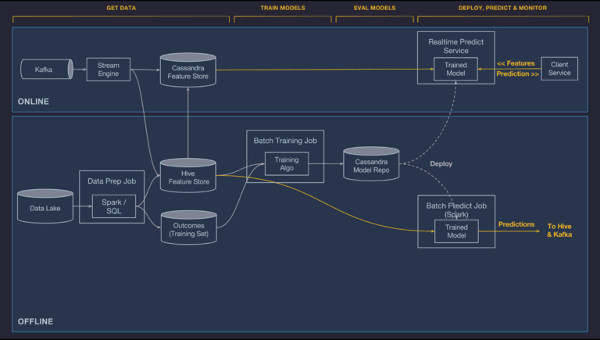
Modelos de referência
Mais de um modelo pode ser implementado ao mesmo tempo para um determinado container de serviço. Isso permite transições seguras de modelos antigos para novos modelos e testes A/B lado a lado de modelo. No momento da entrega, um modelo é identificado pelo seu UUID e uma tag opcional (ou alias) que é especificada durante a implementação. No caso de um modelo online, o serviço do cliente envia o vetor de recurso juntamente com o modelo UUID ou modelo de tag que deseja usar; no caso de uma tag, o container irá gerar a previsão usando o modelo mais recentemente implementado naquela tag. No caso de modelos em lote, todos os modelos implementados são usados para marcar cada conjunto de dados do lote, e os registros de previsão contêm o modelo UUID e a etiqueta opcional para que os consumidores possam filtrar, conforme seja apropriado.
Se ambos os modelos tiverem a mesma assinatura (ou seja, esperam o mesmo conjunto de recursos) ao implementar um novo modelo para substituir um modelo antigo, os usuários podem implementar o novo modelo na mesma tag do modelo antigo, e o container começará a usar o novo modelo imediatamente. Isso permite aos clientes atualizarem seus modelos sem exigir uma alteração no código do cliente. Os usuários também podem implementar o novo modelo usando apenas seu UUID e depois modificar uma configuração no cliente ou intermediar o serviço para alternar gradualmente o tráfego do modelo antigo UUID para o novo.
Para testes A/B de modelos, os usuários podem simplesmente implementar modelos concorrentes através de UUIDs ou tags e, em seguida, usar o framework de experimentação da Uber dentro do serviço do cliente para enviar porções do tráfego para cada modelo e acompanhar as métricas de desempenho.
Escala e latência
Como os modelos de machine learning são sem estado e não compartilham nada, eles são triviais para escalar, tanto nos modos de atendimento online como offline. No caso dos modelos online, podemos simplesmente adicionar mais hosts ao cluster de serviço de previsão e deixar o balanceador de carga espalhar a carga. No caso de previsões offline, podemos adicionar mais executores Spark e permitir que o Spark gerencie o paralelismo.
A latência de serviço online depende do tipo e da complexidade do modelo e se o modelo requer ou não recursos da Feature Store do Cassandra. No caso de um modelo que não precisa de recursos do Cassandra, normalmente vemos latência P95 de menos de 5 milissegundos (ms). No caso de modelos que requerem recursos do Cassandra, normalmente vemos latência P95 de menos de 10ms. Os modelos de tráfego mais altos estão servindo mais de 250 mil previsões por segundo.
Monitorando previsões
Quando um modelo é treinado e avaliado, os dados históricos sempre são usados. Para se certificar de que um modelo vai funcionar bem no futuro, é fundamental monitorar suas previsões para garantir que os pipelines de dados continuem enviando dados precisos e que o ambiente de produção não tenha mudado, de modo que o modelo não seja mais preciso.
Para abordar isso, o Michelangelo pode registrar automaticamente e, opcionalmente, conter uma porcentagem das previsões que faz e depois juntar essas previsões aos resultados (ou rótulos) observados gerados pelo pipeline de dados. Com essa informação, podemos gerar medições contínuas e ao vivo da precisão do modelo. No caso de um modelo de regressão, publicamos R-squared/coeficiente de determinação, erro logarítmico quadrado médio (RMSLE), erro quadrático médio (RMSE) e métricas de erro absoluto médio para os sistemas de monitoramento de séries temporais da Uber para que os usuários possam analisar os gráficos ao longo do tempo e definir alertas de limites, conforme descrito abaixo:
Plano de gerenciamento, API e UI da web
A última peça importante do sistema é uma API tier. Esse é o cérebro do sistema. Consiste em um aplicativo de gerenciamento que serve a UI da web, a API de rede e integrações com a infraestrutura de monitoramento e alerta do sistema da Uber. Essa camada também abriga o sistema de fluxo de trabalho que é usado para orquestar os pipelines de dados do lote, trabalhos de treinamento, trabalhos de previsão de lotes e a implementação de modelos tanto para lote quanto para containers online.
Os usuários do Michelangelo interagem diretamente com esses componentes através da UI da web, da API REST e das ferramentas de monitoramento e alerta.
Construindo na plataforma Michelangelo
Nos próximos meses, planejamos continuar escalando e endurecendo o sistema existente para suportar tanto o crescimento de nosso conjunto de equipes de clientes quanto o negócio geral da Uber. À medida que as camadas da plataforma amadurecem, planejamos investir em ferramentas e serviços de nível superior para impulsionar a democratização do machine learning e apoiar melhor as necessidades de nossos negócios:
- AutoML. Este será um sistema para procurar e descobrir automaticamente as configurações do modelo (algoritmo, conjuntos de recursos, valores de hiper-parâmetros etc.) que resultam nos modelos de melhor desempenho para determinados problemas de modelagem. O sistema também criaria automaticamente os pipelines de dados de produção para gerar os recursos e os rótulos necessários para alimentar os modelos. Já abordamos grandes pedaços disso com nossa Feature Store, nossos pipelines de dados unificados offline e online, e recurso de pesquisa de hiper-parâmetros. Planejamos acelerar o nosso trabalho anterior de ciência de dados através do AutoML. O sistema permitiria aos cientistas de dados especificarem um conjunto de rótulos e uma função objetiva e, em seguida, tornaria o uso dos dados da Uber mais seguro para encontrar o melhor modelo para o problema. O objetivo é ampliar a produtividade de cientistas de dados com ferramentas inteligentes que facilitam seu trabalho.
- Visualização do modelo. Os modelos de compreensão e depuração são cada vez mais importantes, especialmente para o deep learning. Embora tenhamos dado alguns primeiros passos importantes com ferramentas de visualização para modelos baseados em árvores, é necessário fazer muito mais para permitir que cientistas de dados compreendam, depurem e sintonizem seus modelos e que os usuários confiem nos resultados.
- Aprendizagem online. A maioria dos modelos de machine learning da Uber afeta diretamente o produto Uber em tempo real. Isso significa que eles operam no ambiente complexo e em constante mudança de mover coisas no mundo físico. Para manter nossos modelos precisos à medida que esse ambiente muda, nossos modelos precisam mudar com ele. Hoje, os times estão regularmente treinando seus modelos no Michelangelo. Uma solução de plataforma completa para esse caso de uso envolve tipos de modelo facilmente atualizáveis, treinamento e arquitetura de avaliação e pipelines mais rápidos, validação e implementação de modelos automatizados e sistemas sofisticados de monitoramento e alerta. Embora seja um grande projeto, os resultados iniciais sugerem potencial substancial ao fazer o aprendizado online.
- Deep learning distribuído. Um número crescente de sistemas de machine learning da Uber está implementando tecnologias de deep learning. O fluxo de trabalho do usuário de definir e iterar em modelos de deep learning é suficientemente diferente do fluxo de trabalho padrão, de modo que ele precisa de um suporte de plataforma exclusivo. Os casos de uso de deep learning geralmente lidam com uma maior quantidade de dados, e os diferentes requisitos de hardware (por exemplo, GPUs) motivam investimentos adicionais em aprendizagem distribuída e uma integração mais ampla com uma pilha flexível de gerenciamento de recursos.
Se você tem interesse em abordar desafios de machine learning que impulsionam os limites da escala, considere solicitar um papel em nossa equipe!
***
Este artigo é do Uber Engineering. Ele foi escrito por Jeremy Hermann e Mike Del Balso. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/michelangelo/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?