

A Uber Engineering está empenhada em desenvolver tecnologias que criem experiências contínuas e impactantes para nossos clientes. Estamos investindo cada vez mais em inteligência artificial (IA) e em machine learning (ML) para cumprir essa visão. Na Uber, nossa colaboração para isso é o Michelangelo, uma plataforma interna de ML-as-a-service que democratiza o machine learning e faz com que a escala de IA atenda às necessidades do negócio de forma tão fácil como pedir um Uber.
O Michelangelo permite que equipes internas comprem, implementem e apliquem soluções de machine learning na escala da Uber de forma contínua. Ele é projetado para cobrir o fluxo de trabalho de ML de ponta a ponta: gerenciar dados, treinar, avaliar e implementar modelos, fazer previsões e monitorar previsões. O sistema também suporta modelos tradicionais de ML, previsão de séries temporais e deep learning.
Ele vem atendendo aos casos de uso de produção na Uber por cerca de um ano e se tornou o sistema de-facto para machine learning para nossos engenheiros e cientistas de dados, com dezenas de equipes construindo e implementando modelos. Na verdade, ele é implementado em vários datacenters da Uber, aproveita o hardware especializado e serve previsões para os maiores serviços online carregados da empresa.
Neste artigo, apresentamos o Michelangelo, discutimos os casos de uso do produto e percorremos o fluxo de trabalho deste poderoso novo sistema de ML-as-a-service.
A motivação por trás do Michelangelo
Antes do Michelangelo, enfrentamos uma série de desafios com a construção e implementação de modelos de machine learning na Uber relacionados ao tamanho e à escala de nossas operações. Enquanto os cientistas de dados usavam uma grande variedade de ferramentas para criar modelos preditivos (R, scikit-learn, algoritmos personalizados etc.), as equipes de engenharia separadas também estavam construindo sistemas one-off personalizados para usar esses modelos na produção. Como resultado, o impacto de ML na Uber foi limitado ao que alguns cientistas e engenheiros de dados poderiam construir em um curto período de tempo com ferramentas, em sua grande parte, open source.
Especificamente, não havia sistemas para criar pipelines confiáveis, uniformes e reprodutíveis para criar e gerenciar dados de treinamento e predição em escala. Antes do Michelangelo, não era possível treinar modelos maiores do que aqueles que caberiam nos desktops dos cientistas de dados, e não havia um lugar padrão para armazenar os resultados de experimentos de treinamento, nem uma maneira fácil de comparar uma experiência com a outra. Mais importante ainda: não havia um caminho estabelecido para a implementação de um modelo em produção – na maioria dos casos, a equipe de engenharia precisava criar um container de serviço personalizado específico para o projeto em mãos. Ao mesmo tempo, estávamos começando a ver sinais de muitos dos antipadrões de ML documentados por Scully et al.
O Michelangelo é projetado para resolver essas lacunas ao padronizar os fluxos de trabalho e as ferramentas em todas as equipes, apesar de ser um sistema de ponta a ponta que permite aos usuários em toda a empresa criar e operar facilmente sistemas de machine learning em escala. Nosso objetivo não era apenas resolver esses problemas imediatos, mas também criar um sistema que cresceria com o negócio.
Quando iniciamos a construção do Michelangelo, no início de 2016, começamos por abordar os desafios em torno do modelo de treinamento e implementação escalável para produção que serve containers. Então, nos concentramos em construir melhores sistemas para gerenciar e compartilhar pipelines de recursos. Mais recentemente, o foco mudou para a produtividade do desenvolvedor – como acelerar o caminho da ideia para o primeiro modelo de produção e as iterações rápidas que se seguem.
Na próxima seção, analisamos um exemplo de aplicação para entender como o Michelangelo foi usado para construir e implementar modelos para resolver problemas específicos na Uber. Enquanto destacamos um caso de uso específico para a UberEATS, a plataforma gerencia dezenas de modelos similares em toda a empresa para uma variedade de casos de uso de previsão.
Caso de uso: tempo estimado da UberEATS de modelo de entrega
A UberEATS tem vários modelos em execução no Michelangelo, abrangendo previsões de tempo de entrega de refeições, rankings de pesquisa, pesquisa de autocompletar e rankings de restaurantes. Os modelos de tempo de entrega preveem quanto tempo uma refeição levará para ser preparada e ser entregue antes da emissão da ordem e novamente em cada etapa do processo de entrega.
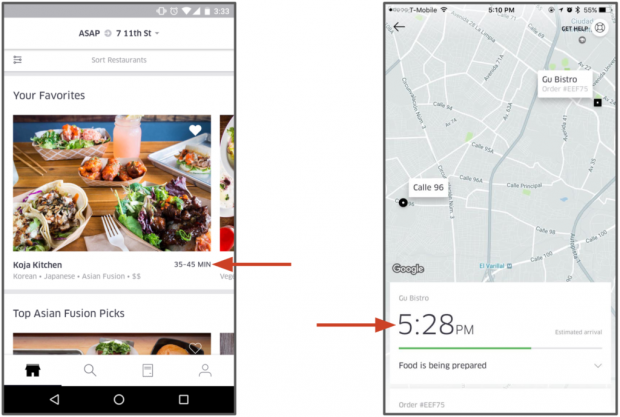
O tempo estimado de entrega previsto (estimated time of delivery – ETD) não é simples. Quando um cliente UberEATS faz uma encomenda, o pedido é enviado ao restaurante para processamento. O restaurante, então, precisa reconhecer o pedido e preparar a refeição, o que levará tempo, dependendo da complexidade do pedido e da ocupação do restaurante. Quando a refeição está perto de ficar pronta, um parceiro de entrega da Uber é despachado para pegar a refeição. Em seguida, esse parceiro precisa chegar ao restaurante, encontrar estacionamento, entrar para pegar a comida, depois voltar ao carro, dirigir para a localização do cliente (que depende da rota, do trânsito e de outros fatores), encontrar estacionamento e caminhar até a porta do cliente para completar a entrega. O objetivo é prever a duração total desse complexo processo multiestágio, bem como recalcular essas previsões de tempo para entrega em cada etapa do processo.
Na plataforma Michelangelo, os cientistas de dados da UberEATS usam modelos de regressão de árvore de decisão com gradiente para prever esse tempo de entrega de ponta a ponta. As características do modelo incluem informações do pedido (por exemplo, hora do dia, local de entrega), características do histórico (por exemplo, tempo médio de preparação de refeições nos últimos sete dias) e recursos calculados quase em tempo real (por exemplo, tempo médio de preparação de refeição para a última hora). Os modelos são implementados nos datacenters da Uber para os containers de serviço do modelo Michelangelo e são invocados através de solicitações de rede pelos microsserviços da UberEATS. Essas previsões são exibidas para os clientes da UberEATS antes do pedido de um restaurante e à medida que a refeição está sendo preparada e entregue.
Arquitetura do sistema
O Michelangelo consiste em uma mistura de sistemas open source e componentes construídos internamente. Os principais componentes open source usados são HDFS, Spark, Samza, Cassandra, MLLib, XGBoost e TensorFlow. Geralmente, preferimos usar opções open source maduras sempre que possível, e vamos fazer fork, personalizar e colaborar de volta, conforme necessário – embora às vezes construamos sistemas quando as soluções open source não são ideais para o nosso caso de uso.
O Michelangelo é construído sobre os dados da Uber e calcula a infraestrutura, fornecendo um lago de dados que armazena todos os dados transacionais e registrados da Uber, brokers da Kafka que agregam mensagens registradas de todos os serviços da Uber, um motor de computação de transmissão Samza, clusters Cassandra gerenciados e ferramentas de provisionamento e implantação de serviços in-house da Uber.
Na próxima seção, caminhamos pelas camadas do sistema usando os modelos UberEATS ETD como estudo de caso para ilustrar os detalhes técnicos do Michelangelo.
Fluxo de trabalho de machine learning
O mesmo fluxo de trabalho geral existe em quase todos os casos de uso de machine learning na Uber, independentemente do desafio em questão, incluindo classificação e regressão, bem como a previsão de séries temporais. O fluxo de trabalho geralmente é agnóstico de implementação, facilmente expandido para suportar novos tipos de algoritmos e frameworks, como novos frameworks de deep learning. Ele também se aplica a diferentes modos de implementação, como casos de uso de previsão online e offline (no carro e no telefone).
Projetamos o Michelangelo especificamente para fornecer ferramentas escaláveis, confiáveis, reprodutíveis, fáceis de usar e automatizadas para abordar o seguinte fluxo de trabalho:
- Gerenciar dados
- Treinar modelos
- Avaliar modelos
- Implementar modelos
- Fazer previsões
- Monitorar previsões
Em seguida, entraremos em detalhes sobre como a arquitetura do Michelangelo facilita cada etapa desse fluxo de trabalho, mas isso, só na segunda parte do artigo.
Gerenciar dados
Encontrar boas funcionalidades, muitas vezes, é a parte mais difícil do machine learning, e descobrimos que a construção e o gerenciamento de pipelines de dados são geralmente as peças mais dispendiosas de uma solução completa de machine learning.
Uma plataforma deve fornecer ferramentas padrão para a construção de pipelines de dados para gerar recursos e conjuntos de dados de etiquetas para conjuntos de dados de treinamento (e re-treinamento) e de feature-only para previsão. Essas ferramentas devem ter uma profunda integração com o lago ou armazéns de dados da empresa e com os sistemas de serviço de dados online. Os pipelines precisam ser escaláveis e ter grande rendimento, incorporar monitoramento integrado para o fluxo de dados e a qualidade dos dados, e apoiar o treinamento e a previsão online e offline. Idealmente, eles também devem gerar os recursos de forma compartilhada entre as equipes para reduzir o trabalho duplicado e aumentar a qualidade dos dados. Eles também devem fornecer fortes trilhos de proteção e controles para incentivar e capacitar os usuários a adotarem as melhores práticas (por exemplo, facilitando a garantia de que o mesmo processo de geração/ preparação de dados seja usado no tempo de treinamento e no tempo de previsão).
Os componentes de gerenciamento de dados do Michelangelo são divididos entre pipelines online e offline. Atualmente, os pipelines offline são usados para alimentar o treinamento do modelo em lote e os trabalhos de previsão de lotes, e os pipelines online alimentam previsões online de baixa latência (e em um futuro próximo, sistemas de aprendizado online).
Além disso, adicionamos uma camada de gerenciamento de dados, uma loja de recursos que permite que as equipes compartilhem, descubram e usem um conjunto de recursos altamente com curadoria para seus problemas de machine learning. Descobrimos que muitos problemas de modelagem na Uber usam características idênticas ou similares, e há um valor substancial em permitir que as equipes compartilhem recursos entre seus próprios projetos e com equipes em diferentes organizações para compartilhar recursos entre si.
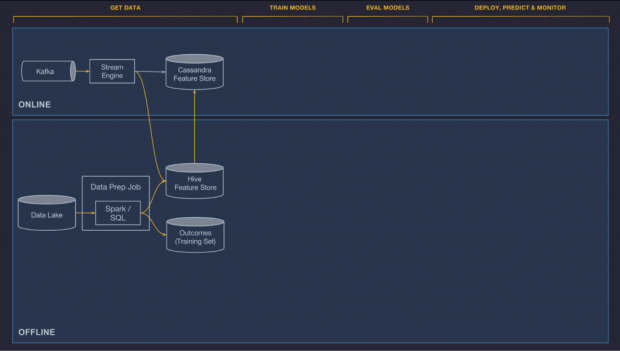
Offline
Os dados transacionais e de log da Uber circulam em um lago de dados HDFS e são facilmente acessíveis através de trabalhos de computação Spark e Hive SQL. Nós fornecemos containers e agendamentos para executar trabalhos regulares para calcular recursos que podem ser considerados privados para um projeto ou publicados na Feature Store (veja abaixo) e compartilhados entre equipes, enquanto trabalhos em lote são executados em um cronograma ou um gatilho e são integrados com dados de ferramentas de monitoramento de qualidade para detectar rapidamente regressões no pipeline – seja devido a problemas de código ou de dados locais ou upstream.
Online
Os modelos que são implementados online não podem acessar os dados armazenados no HDFS e, muitas vezes, é difícil calcular alguns recursos de uma forma de grande rendimento diretamente dos bancos de dados online que suportam os serviços de produção da Uber (por exemplo, não é possível consultar diretamente o serviço de pedidos UberEATS para calcular o tempo médio de preparação de refeições para um restaurante durante um período específico de tempo). Em vez disso, permitimos que os recursos necessários para os modelos online sejam previamente computados e armazenados no Cassandra, onde podem ser lidos em baixa latência no tempo de predição.
Nós suportamos duas opções para computar esses recursos com atendimento online, pré-computação em lote e computação em tempo quase real, descritas abaixo:
- Pré-computação em lote. A primeira opção para computação é realizar pré-computação em massa e carregar características históricas do HDFS no Cassandra regularmente. Isso é simples e eficiente, e geralmente funciona bem para recursos históricos, onde é aceitável que os recursos sejam atualizados apenas a cada poucas horas ou uma vez por dia. Este sistema garante que o mesmo pipeline de dados e de lote seja usado tanto para treinamento, quanto para atendimento. A UberEATS usa este sistema para recursos como o tempo médio de preparação de refeições do restaurante nos últimos sete dias.
- Computação em tempo quase real. A segunda opção é publicar métricas relevantes no Kafka e depois executar trabalhos de computação de streaming baseados em Samza para gerar recursos agregados em baixa latência. Esses recursos são, então, escritos diretamente no Cassandra para atendimento e log no HDFS para futuros treinamentos. Como o sistema de lote, o cálculo de tempo quase real garante que os mesmos dados sejam usados para treinar e servir. Para evitar um início “frio”, fornecemos uma ferramenta para “preencher” esses dados e gerar dados de treinamento executando um trabalho em lote contra registros históricos. A UberEATS usa esse pipeline em tempo quase real para recursos como o tempo médio de preparação de refeições do restaurante durante a última hora.
Feature Store compartilhada
Encontramos grande valor na construção de uma Feature Store centralizada, na qual equipes da Uber podem criar e gerenciar recursos canônicos para serem usados por suas equipes e compartilhados com outras pessoas. Em um nível alto, ela realiza duas coisas:
- Permite que os usuários adicionem facilmente recursos que eles construíram em uma feature store, exigindo apenas uma pequena quantidade de metadados adicionais (proprietário, descrição, SLA etc.) em cima do que seria necessário para um recurso gerado para uso particular ou específico do projeto.
- Uma vez que os recursos estão na Feature Store, eles são muito fáceis de consumir, tanto online como offline, fazendo referência ao nome canônico simples de um recurso na configuração do modelo. Equipado com essa informação, o sistema lida com os conjuntos de dados HDFS corretos para o treinamento do modelo ou a previsão em lote e obtendo o valor certo do Cassandra para previsões online.
No momento, temos aproximadamente 10 mil recursos na Feature Store que são usados para acelerar projetos de machine learning, e equipes em toda a empresa estão adicionando novos o tempo todo. Os recursos da Feature Store são automaticamente calculados e atualizados diariamente.
No futuro, pretendemos explorar a possibilidade de construir um sistema automatizado para pesquisar através da Feature Store e identificar os recursos mais úteis e importantes para resolver um determinado problema de previsão.
Hoje, vamos ficando por aqui. Na segunda parte do artigo, continuares a explorar os demais pontos desse fluxo de trabalho e entraremos em detalhes sobre como a arquitetura do Michelangelo facilita cada etapa desse fluxo.
***
Este artigo é do Uber Engineering. Ele foi escrito por Jeremy Hermann e Mike Del Balso. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/michelangelo/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?