

Neste artigo, falaremos sobre Web scraping com Python e como extrair páginas da web usando várias bibliotecas de extração do Python, como: Beautifulsoup, Selenium e algumas outras ferramentas mágicas, como o PhantomJS.
Você aprenderá a extrair páginas web estáticas, páginas dinâmicas (conteúdo carregado por Ajax), iframes, obter elementos HTML específicos, como lidar com cookies e muito mais coisas.
O que é o Python Web Scraping?
O Web Scraping geralmente é o processo de extração de dados da web, você pode analisar os dados e extrair informações úteis.
Além disso, você pode armazenar os dados extraídos em um banco de dados ou em qualquer tipo de formato tabular, como CSV, XLS, etc, para que você possa acessar essas informações facilmente.
Os dados extraídos podem ser passados para uma biblioteca como NLTK para processamento posterior para entender o que a página está falando.
Em suma, o web scraping está baixando os dados da web em um formato legível para humanos, para que você possa se beneficiar disso.
Benefícios da Scraping na Web
Você pode se perguntar: “Por que eu deveria raspar a web se eu tenho o Google?” Bem, não reinventamos a roda aqui. O web scraping não é apenas para criar mecanismos de pesquisa.
Você pode extrair as páginas da web do seu concorrente e analisar os dados e ver que tipo de produtos os seus clientes e concorrentes estão satisfeitos com suas respostas. Tudo isso GRATUITAMENTE.
Uma ferramenta de SEO bem-sucedida como o Moz que retalha e percorre toda a web e processa os dados para você, para que você possa ver o interesse das pessoas e como competir com outras pessoas em seu campo para estar no topo.
Estes são apenas alguns usos simples da raspagem na web. Os dados extraídos significam ganhar dinheiro.
Instalar Beautifulsoup
Eu suponho que você tenha alguma experiência em princípios básicos do Python, então vamos instalar nossa primeira biblioteca de web scraping do Python, que é o BeautifulSoup.
Para instalar o Beautifulsoup, você pode usar pip ou você pode instalá-lo a partir da fonte.
Eu vou instalá-lo usando pip como este:
$ pip install beautifulsoup4
Para verificar se está instalado ou não, abra o editor e digite o seguinte:
from bs4 import BeautifulSoup
Em seguida, execute:
$ python myfile.py
Se ele for executado sem erros, isso significa que o BeautifulSoup foi instalado com sucesso. Agora, vejamos como usar o Beautifulsoup.
Seu primeiro web scraper
Dê uma olhada neste exemplo simples, vamos extrair o título da página usando o BeautifulSoup:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.python.org/")
res = BeautifulSoup(html.read(),"html5lib");
print(res.title)
O resultado é:
Usamos a biblioteca urlopen para conectar-se à página da Web que queremos, então lemos o HTML retornado usando o método html.read ().
O HTML retornado é transformado em um objeto BeautifulSoup que possui uma estrutura hierática.
Isso significa que se você precisar extrair qualquer elemento HTML, basta saber as tags circundantes para obtê-lo como veremos mais adiante.
Manipulação de Exceções HTTP
Por qualquer motivo, urlopen pode retornar um erro. Poderia ser 404 se a página não for encontrada ou 500 se houver um erro no servidor interno, então precisamos evitar falhas no script usando o tratamento de exceções como este:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
if res.title is None:
print("Tag not found")
else:
print(res.title)
Ótimo, e se o servidor estiver inactivo ou digitar o domínio incorretamente?
Manipulação de Exceções de URL
Precisamos também lidar com esse tipo de exceções. Esta exceção é URLError, então nosso código será assim:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
print(res.titles)
Bem, a última coisa que precisamos verificar é a etiqueta retornada, você pode digitar uma tag incorreta ou tentar raspar uma tag que não seja encontrada na página extraída e isso retornará objeto Nenhum, então você precisa verificar o objeto Nenhum.
Isso pode ser feito usando uma simples instrução if como esta:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
if res.title is None:
print("Tag not found")
else:
print(res.title)
Ótimo, nosso raspador está fazendo um bom trabalho. Agora podemos recuperar a página inteira ou extrair uma marca específica.
E uma caça mais profunda?
Extraia tags HTML usando o atributo de classe
Agora, vamos tentar ser seletivos extraindo alguns elementos HTML com base em suas classes CSS.
O objeto Beautifulsoup tem uma função chamada findAll que extrai ou filtra elementos com base em seus atributos
Podemos filtrar todos os elementos h3 cuja classe é “post-title”, como esta:
tags = res.findAll(“h3”, {“class”: “post-title”})
Então, podemos usar o loop para iterar sobre eles e fazer o que quer que seja com eles.
Então nosso código será assim:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://likegeeks.com/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
tags = res.findAll("h3", {"class": "post-title"})
for tag in tags:
print(tag.getText()
Este código retorna todas as tags h3 com uma classe chamada post-title onde essas tags são os títulos de postagem da página inicial.
Usamos a função getText para imprimir apenas o conteúdo interno da tag, mas se você não usou o getText, você acabará com as tags com tudo dentro delas.
Verifique a diferença:
Isso quando usamos getText ():
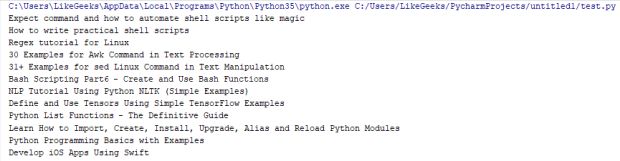
E isso sem usar getText ():

Raspe tags HTML usando findAll
Vimos como encontrar todas as funções de tags de filtros por classe, mas isso não é tudo.
Para filtrar uma lista de etiquetas, substitua a linha destacada do exemplo acima com a seguinte linha:
tags = res.findAll(“span”, “a” “img”)
Este código obtém todas as tags de extensão, âncora e imagem do HTML raspado.
Além disso, você pode extrair tags que possuem essas classes:
tags = res.findAll(“a”, {“class”: [“url”, “readmorebtn”]})
Este código extrai todas as tags de âncora que têm classe “readmorebtn” e “url”.
Você pode filtrar o conteúdo com base no próprio texto interno usando o argumento de texto como este:
tags = res.findAll(text=”Python Programming Basics with Examples”)
A função FindAll retorna todos os elementos que combinam os atributos especificados, mas se você quiser retornar apenas um elemento, você pode usar o parâmetro limite ou usar a função find que retorna o primeiro elemento.
Encontre nth Child Using Beautifulsoup
O objeto Beautifulsoup tem muitos recursos poderosos, você pode obter elementos para crianças diretamente assim:
tags = res.span.findAll(“a”)
Esta linha irá obter o primeiro elemento span no objeto Beautifulsoup e, em seguida, raspe todos os elementos âncora sob esse período.
E se você precisar pegar o nth-child?
Você pode usar a função de seleção como esta:
tag = res.find(“nav”, {“id”: “site-navigation”}).select(“a”)[3]
Esta linha obtém o elemento nav com id “site-navigation”, então pegamos a quarta marca de âncora desse elemento de navegação.
Localizar Tags usando o Regex
Em um tutorial anterior, falamos sobre expressões regulares e vimos o quão poderoso é usar o regex para identificar padrões comuns, como e-mails, URLs e muito mais.
Por sorte, Beautifulsoup tem esse recurso, você pode passar padrões regex para corresponder a tags específicas.
Imagine que você deseja raspar alguns links que combinam um padrão específico, como links internos ou links externos específicos ou raspar algumas imagens que residem em um caminho específico.
O motor Regex torna tão fácil a realização de tais trabalhos.
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})
Essas linhas irão extrair todas as imagens do PNG em ../uploads/ e começar com a foto_
Este é apenas um exemplo simples para mostrar o poder de expressões regulares combinadas com o Beautifulsoup.
Scraping JavaScript
Suponha que a página que você precisa para raspar tem outra página de carregamento que redireciona você para a página desejada e o URL não muda ou existem algumas peças de sua página raspada que carrega seu conteúdo usando o Ajax.
Nosso web scraper não carregará nenhum conteúdo, já que o scraper não executa o JavaScript necessário para carregar esse conteúdo.
Seu navegador executa JavaScript e carrega qualquer conteúdo normalmente e na verdade, o que faremos usando nossa segunda biblioteca de raspagem da web do Python chamada Selenium.
A biblioteca Selenium não inclui seu próprio navegador, você precisa instalar um navegador de terceiros (ou um driver da Web) para funcionar.
Você pode escolher entre o Chrome, Firefox, Safari ou Edge.
Se você instalar algum desses drivers, digamos que o Chrome, ele abrirá uma instância do navegador e carregará sua página, então você pode raspar ou interagir com sua página.
Usando o ChromeDriver com selênio
Primeiro, você deve instalar uma biblioteca de selênio como esta:
$ pip install selenium
Então você deve baixar o driver do Chrome a partir daqui e para o seu sistema PATH.
Agora você pode carregar sua página como esta:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/")
nav = browser.find_element_by_id("mainnav")
print(nav.text)
O resultado é assim:

Muito simples, certo?
Nós não interagimos com os elementos da página, então não vimos o poder do selênio ainda, apenas espere por isso.
Selenium Web Scraping
Você pode gostar de trabalhar com drivers de navegadores, mas há muito mais pessoas como executar código em segundo plano sem ver a execução em ação.
Para este propósito, existe uma ótima ferramenta chamada PhantomJS que carrega sua página e executa seu código sem abrir nenhum navegador.
O PhantomJS permite que você interaja com cookies de página extraídos e JavaScript sem dor de cabeça. Além disso, você pode usá-lo como Beautifulsoup para extrair páginas e elementos dentro dessas páginas.
Faça o download do PhantomJS a partir daqui e coloque-o no seu PATH para que possamos usá-lo como um driver web com selênio.
Agora, apliquemos o nosso trabalho de extração da web Python usando selênio com o PhantomJS da mesma maneira que fizemos com o driver da Web Chrome.
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
print(browser.find_element_by_class_name("introduction").text)
browser.close()
O resultado é:

Impressionante! Funciona muito bem. Você pode acessar elementos de várias formas, tais como:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")
Todas essas funções retornam apenas um elemento, você pode retornar vários elementos usando elementos como este:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")
Selenium page_source
Você pode usar o poder do BeautifulSoup no conteúdo retornado do selenium usando page_source como esta:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
O resultado é:
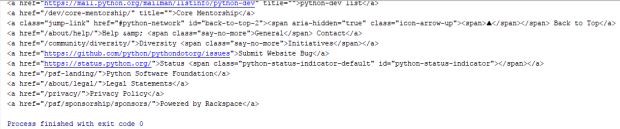
Como você pode ver, o PhantomJS torna super fácil ao executar a rascunho da Web Python para elementos HTML. Vamos ver mais.
Obter iframe conteúdo usando selênio
Sua página raspada pode conter um iframe que contenha dados.
Se você tenta arranhar uma página que contenha um iframe, você não receberá o conteúdo do iframe, você precisará extrair a fonte do iframe.
Você pode usar Selenium para raspar iframes ao mudar para a moldura que deseja extrair.
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe")
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL
O resultado é:
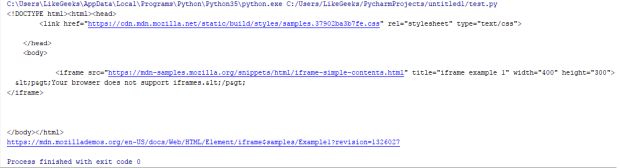
Verifique o URL atual, é o URL do iframe, e não a página original.
Obtenha o iframe Content usando o Beautifulsoup
Você pode obter o URL do iframe usando a função find, então você pode retirar esse URL.
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping
Impressionante! Aqui, usamos outra técnica de web scraping de Python, onde extrairemos o conteúdo do iframe de uma página.
Manusear chamadas do Ajax usando (Selenium+PhantomJS)
Você pode usar selênio para raspar o conteúdo depois de fazer suas chamadas no Ajax.
Como clicar em um botão que obtenha o conteúdo que você precisa para extrair. Verifique o seguinte exemplo:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp")
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()
O resultado é:
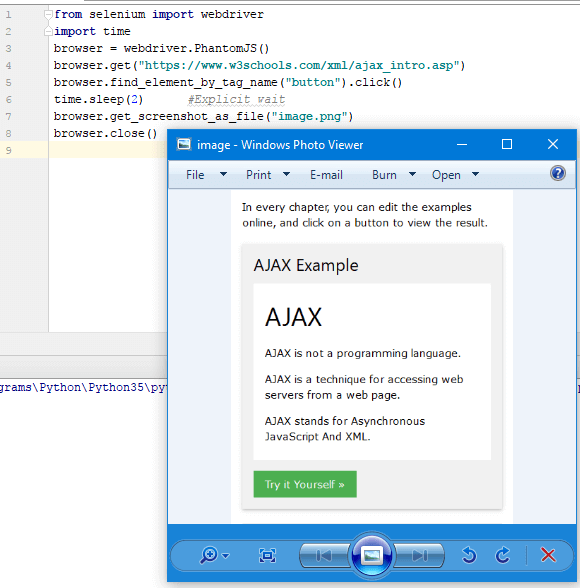
Aqui nós extraímos uma página que contém um botão e clicamos nesse botão, que faz o Ajax ligar e recebe o texto, e então salvamos uma captura de tela dessa página.
Há um detalhe aqui, é sobre o tempo de espera. Sabemos que o carregamento da página não pode exceder 2 segundos para carregar completamente, mas essa não é uma boa solução, o servidor pode demorar mais tempo ou sua conexão pode ser lenta, há muitos motivos.
Aguarde as chamadas do Ajax serem concluídas usando PhantomJS
A melhor solução é verificar a existência de um elemento HTML na página final, se existir, significa que a chamada Ajax foi concluída com sucesso.
Verifique este exemplo:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/")
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()
O resultado é:
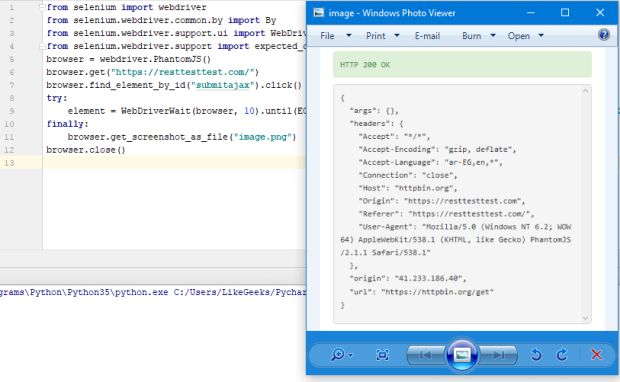
Aqui, clicamos em um botão Ajax que faz REST chamar e retorna o resultado JSON.
Verificamos o texto do elemento div se for “HTTP 200 OK” com 10 segundos de tempo limite, então salvamos a página de resultados como uma imagem como mostrado.
Você pode verificar por muitas coisas como:
Alteração de URL usando EC.url_changes()
Nova janela aberta usando EC.new_window_is_opened()
Alterações no título usando EC.title_is()
Se você tiver qualquer redirecionamento de página, você pode ver se há uma mudança de título ou URL para verificar isso.
Há muitas condições para verificar, nós apenas tomamos um exemplo para mostrar a quantidade de energia que você possui. Legal!
Manipulação de cookies
Às vezes, quando você escreve seu código web scraping no Python, é muito importante cuidar de cookies para o site que você está raspando. Talvez você precise excluir os cookies ou talvez você precise salvá-lo em um arquivo e usá-lo para conexões posteriores.
Muitos cenários lá fora, então vejamos como lidar com cookies. Para recuperar cookies para o site atualmente visitado, você pode chamar a função get_cookies () assim:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
print(browser.get_cookies())
O resultado é:

from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
browser.delete_all_cookies()
Para excluir cookies, você pode usar as funções delete_all_cookies () assim:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
browser.delete_all_cookies()
Web Scraping VS Web Crawling
Nós conversamos sobre a correção da web em Python e como analisar páginas da web, agora algumas pessoas ficam confusas sobre extração e rastreamento.
O Web Scraping é sobre a análise de páginas da web e extraindo dados dele para qualquer propósito, como vimos.
O rastreamento da Web é sobre a colheita de todos os links que você encontra e percorre todos eles sem uma escala, e isso com o objetivo de indexar, como o que o Google e outros mecanismos de busca fazem.
Python web scraping é muito divertido, mas antes de terminar nossa discussão, existem alguns pontos complicados que podem impedir que você extraia, como o Google ReCaptcha.
Google reCaptcha torna-se muito mais difícil agora, você não consegue encontrar uma boa solução para confiar.
Espero que tenha achado este artigo útil! Volte sempre!
Obrigado.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?