

Navegando pelo tech blog do Facebook, mais precisamente na área voltada para aplicações web, encontrei um artigo muito interessante sobre React e Open Source.
 No final de fevereiro, Isaac Salier-Hellendag, engenheiro de user interfaces no Facebook, publicou este artigo sobre como o Facebook e a comunidade estão lidando com a abertura do código do framework DraftJs.
No final de fevereiro, Isaac Salier-Hellendag, engenheiro de user interfaces no Facebook, publicou este artigo sobre como o Facebook e a comunidade estão lidando com a abertura do código do framework DraftJs.
No artigo, Sallier diz que 400 engenheiros da comunidade React reuniram-se para a React.js Conf em San Francisco, uma conferência de dois dias dedicada a discutir as tendências do desenvolvimento React. Além disso, a conferência aborda os desafios comuns para melhoraria da experiência, tanto para o desenvolvedor quanto para o usuário.
O autor afirma que um dos destaques do evento veio da sua própria equipe de infraestrutura de produto no Facebook. Eles abriram o código Draft.js, um framework baseado em React de um editor de rich text que tem estado em desenvolvimento desde o verão de 2013. Ele declara que essa é uma nova área para eles, porque o Facebook nunca tinha aberto um código de um framework rich text, mas eles ficaram entusiasmados em ver que nas primeiras horas sendo open source no GitHub, o Draft.js recebeu mais de 1.000 estrelas. Em fevereiro, foi compartilhado que eles tem cerca de 4.000 estrelas.

Por que rich text?
Rich text é uma parte essencial dos produtos do Facebook. Por exemplo, dentro de um comentário, você pode citar pessoas e adicionar hashtags. Você pode ver as características destacadas abaixo.
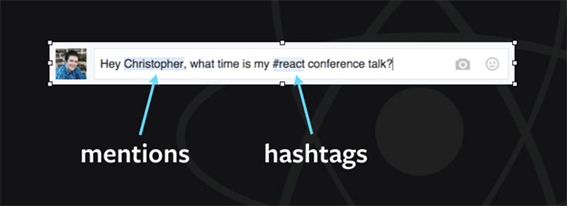
No passado, eles já abordaram esse formato utilizando <textarea> e o fundo destacado com tags <div>. No entanto, essa solução levou a uma experiência ruim para o desenvolvedor, com muitos hacks DOM necessários para medir o texto para o crescimento automático do textarea, manter os marcadores posicionados corretamente, e acompanhar posições do cursor com caracteres Unicode invisíveis. Havia também um desafio com a sincronização de Estado e DOM, uma vez que o texto original não continha informações sobre os dados de menção estruturados. Essas questões levaram os usuários a experiências pobres, com fundos desalinhados e entradas quebradas. Não só isso, mas <textarea> suporta apenas texto simples, sendo assim, o Facebook nunca poderia ampliar seu conjunto de recursos para incluir estilos mais ricos ou conteúdos incorporados.
Rich text e React
Para resolver os desafios acima, eles decidiram desenvolver o seu próprio editor de rich text e tornar a entrada de rich text mais personalizável. Além disso, quando começaram a construir mais interfaces com React, eles queriam construir um framework que integrasse React nas aplicações.
Precisavam também identificar a abordagem certa para renderizar o seu editor, por isso consideraram algumas opções. Uma solução proposta pelos engenheiros foi chamar todos os conteúdos manualmente, proporcionando assim um suporte completo para o estilo e as características incorporadas. Porém, um dos principais problemas com essa abordagem é a necessidade de definir manualmente um cursor falso ou uma seleção, o que exigiria ainda mais medições DOM ou hacks. Outra possibilidade considerada foi usar ContentEditable, um widget de navegador que muitas vezes constitui a base para editores de Rich na web. O problema é que ContentEditable muitas vezes é considerado confuso, imprevisível e difícil de usar, e viola diretamente a filosofia de manter o estado do aplicativo separado do DOM.
No entanto, foi observado que ele ofereceu muitos atributos positivos:
- Funciona em todos os navegadores;
- Cursor nativo e comportamento de seleção;
- Eventos de entrada nativo (por exemplo, eventos-chave, Input Method Editor [IME]);
- Quaisquer recursos de rich text que quiséssemos;
- Auto-Growing automático – sem DOM hacks ou medições necessários;
- Acessibilidade.
Dado o conjunto de recursos padrão, eles decidiram construir um componente controlled React ContentEditable, seguindo o mesmo padrão de controle do controlled React DOM inputs. Para esse fim, criaram uma estrutura que iria realizar o seguinte:
- Controle estrito de conteúdos renderizados com React;
- Controle estrito de cursor e seleção com Native Selection API;
- Uma declarativa e incompreensível API;
- Suporte para Input Method Editor (IME), cut/copy/paste, e verificação ortográfica;
- Suporte para rich text arbitrário;
Com o controle completo sobre o DOM renderizado, eles tiveram janela para controlar o cursor. Adquiriram conhecimento de toda a estrutura DOM, a qualquer momento, para que pudessem mapear o seu modelo de seleção diretamente para uma posição no DOM. Após renderizar conteúdos atualizados, seria possível usar esse conhecimento para instruir a API de seleção imperativa nativa para colocar o cursor no local correto. Essa abordagem também permitiu observar as alterações de seleção dentro do editor e mapeá-los de volta para o modelo conhecido.
Um modelo imutável
O framework precisava de um modelo para representar o conteúdo completo e o estado do cursor em qualquer ponto no tempo. Além disso, como eles estavam tomando o controle da ContentEditable DOM, já não podiam depender do navegador para manter o estado undo/redo, e seria necessário representá-lo por eles mesmos.
A abordagem ideal foi usar uma estruturas de dados imutáveis para representar o editor, com um único objeto imutável de alto nível que serviria como um snapshot do estado inteiro. Assim, cada snapshot deveria conter o conteúdo, cursor, desfazer/refazer, pilhas e outros valores necessários para representar o editor. Isso permitiu fornecer uma simples API de nível superior, com um valor para representar o estado e um manipulador para receber atualizações de estado de dentro do componente de edição, refletindo a API de entrada controlada do DOM.
Eles também fizeram uso pesado de persistência de dados em todos os próprios snapshots imutáveis. Quando um parágrafo dentro de um editor mudava, todos os outros parágrafos permaneciam intocados. Isso também significava que, dentro dos seus snapshots de conteúdo, eles poderiam continuar fazendo referência à memória usada para os parágrafos inalterados em vez de usar uma nova memória de conteúdo inalterado.

Ao persistir dados dessa forma, mesmo criando muitos snapshots de estado de conteúdo, a pegada de memória poderia permanecer mínima.
Estado de transição com imutabilidade
Com o gerenciamento de undo/redo, imutabilidade e persistência de dados tornam-se ainda mais úteis. Se você imaginar digitar uma sequência de texto em uma entrada nativa típica e, em seguida, executar uma ação de desfazer, você vai notar que a perda não significa a remoção de um caractere de cada vez. Em vez disso, toda a cadeia digitada é removida. Executar uma ação de desfazer seria tão simples como apenas reproduzir o estado limite anterior.
Ao identificar regras e heurísticas comuns para detectar esses estados de fronteira, é possível acompanhar o que muda para saltar durante o comportamento undo/redo. Isso significava que qualquer snapshot entre os estados de fronteira se tornaria irrelevante e poderia simplesmente ser descartado e coletado pelo lixo. Todo o histórico de edição, então, poderia ser representado como uma pilha de snapshots muito menores do que o conjunto completo de alterações feitas durante a vida útil do editor, e cada snapshot persistiria o máximo de dados possível entre eles.

Um benefício adicional de imutabilidade é a ênfase na realização de atualizações de estado através de meios puramente funcionais. Qualquer operação de edição complexa pode ser expressa como uma composição de operações menores, facilmente testáveis, sem efeitos secundários ou mutações. Uma função poderia aceitar um snapshot do estado, criar snapshots intermediários, e retornar um snapshot final com todas as alterações aplicadas. Os snapshots intermediários podem então ser imediatamente descartados, já que apenas a saída seria necessária para renderizar a seguinte, novamente minimizando a nossa pegada de memória.
Open source
Quando eles construíram esse framework, o objetivo era ajudar a resolver os desafios de composição de rich text no Facebook e equipar os engenheiros com ferramentas para criar novas e interessantes experiências dentro de suas aplicações React. O editor agora é usado mais amplamente em produtos do Facebook, incluindo entradas de comentário e atualização de status, chat, Facebook Notes, e muito mais.
Para os engenheiros do Facebook, essa solução tem funcionado bem para os produtos, por isso tiveram a ideia de compartilhar o projeto com a comunidade open source. Isaac anunciou o lançamento de Draft.js no final da sua palestra na React.js Conf, e confessa que ficou espantado e encorajado pela resposta de outros engenheiros na conferência e na comunidade.
Assinatura da receita de biscoitos de açúcar de Sara Sodine, exibida no Facebook Notes
Conclusão
O objetivo dos engenheiros do Facebook com o desenvolvimento Draft.js era fornecer os blocos de construção para a criação de grandes experiências de rich text. Ele fornece a flexibilidade de personalizar a interface do usuário do seu editor e o comportamento para atender a seu caso de uso, além de uma API projetada para ajudar a focalizar a sua aplicação em dados e renderizar, não em HTML e DOM.
Assim, eles querem simplificar o processo de criação de interfaces para apoiar o rich text, quer seja para alguns estilos de texto em linha ou um editor complexo para compor artigos de formato longo com rich media incorporados.
Os engenheiros contam que estão realmente animados para ver que tipo de interfaces a comunidade criará na sequência. Bora participar do projeto?
Link do artigo original: https://code.facebook.com/posts/1684092755205505/facebook-open-sources-rich-text-editor-

De 0 a 10, o quanto você recomendaria este artigo para um amigo?