

Acreditamos que o LinkedIn pode oferecer insights personalizados para oportunidades de trabalho de uma forma que nenhum outro site pode. Em nossas novas páginas de Detalhes da Vaga, podemos mostrar aos membros informações valiosas, como quem eles podem conhecer na empresa, o que poderia dar a eles uma vantagem sobre os outros candidatos ou fazer um determinado trabalho se destacar sobre os outros. O maior problema que enfrentamos, no entanto, é conseguir membros para essa página de Detalhes da Vaga; o trabalho pode ser perfeito para um candidato, mas se ele nunca olhar a página, ele perde uma grande oportunidade.
O que precisávamos era uma maneira de despertar o interesse de um candidato a emprego e responder à pergunta: “O que é a coisa mais interessante dessa vaga para essa pessoa?”. Inicialmente, o LinkedIn tinha listas simples de postos de trabalho, como uma lista de resultados de pesquisa, ou uma lista de trabalhos recomendados. Não havia nada para fazer um trabalho se destacar, além do cargo ou nome da empresa. O que quisemos fazer na versão mais recente dessa experiência foi trazer à tona todos os “sabores” do que faz a vaga ser especial – por exemplo, se o membro conhece funcionários de trabalhos anteriores ou da escola, ou se o trabalho representa um salto no salário – a fim de ajudar os candidatos a emprego a limitar as opções e encontrar o melhor trabalho para eles. Neste artigo, vamos falar sobre a infraestrutura que construímos para mostrar os tipos de vagas para os nossos membros.
Requisitos
Quando fizemos a primeira concepção desse sistema, tivemos três requisitos:
- Baixa latência: Muitas partes do LinkedIn onde gostaríamos de mostrar diferentes vagas têm requisitos de latência rigorosos, como o feed ou a de procura de emprego. Depois de conversar com as partes interessadas, determinamos que poderíamos ir até 50ms em um percentual de 95 (ou seja, 95% das chamadas devem acontecer em menos de 50ms).
- Escalável: Era necessário construir o sistema de uma forma que escalasse, tanto em termos do tamanho dos dados (uma visão única para os nossos mais de 450 milhões de membros, multiplicado por mais de 15 milhões de postos de trabalho), bem como ser capaz de suportar um grande número de diversidade. A fim de mostrarmos a diversidade em todos os lugares que mostram trabalhos, teríamos que suportar pelo menos 5.000 consultas por segundo (QPS), com 10.000 QPS em horários de pico de tráfego. Também necessitaríamos de muito espaço para crescer além disso, já que temos visto um aumento de 75% em visitas de todas as páginas de vagas desde o ano passado.
- Extensivo: Adicionar novas variedades (ou removendo as antigas) deve ser fácil de fazer. Nós queríamos que isso fosse uma parte essencial da experiência do candidato a emprego procurar no LinkedIn, e que fosse simples para novos desenvolvedores pegar e manter. Adicionar novas variedades não deve exigir o conhecimento de qualquer outra variedade que veio antes, nem conhecimento de todas as peças móveis (tracking, construção dos modelos, classificação etc).
Visão geral da arquitetura
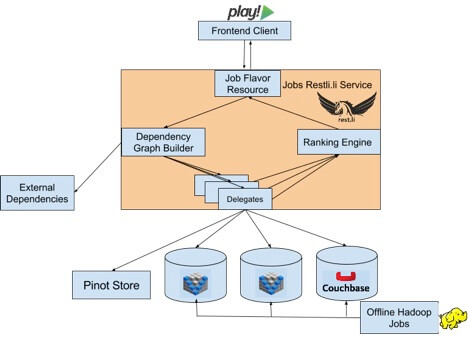
O ecossistema de características de vagas é feito de dois componentes principais: a camada stateless Rest.li, e um conjunto de armazenamentos de dados acessados pela camada Rest.li em cada chamada. Usando Rest.li + D2, podemos escalar infinitamente essa camada intermediária, mantendo a tolerância a falhas e o balanceamento de carga (ok, talvez não infinitamente, mas praticamente para todos os efeitos práticos). Clientes no frontend fazem pedidos a nossa camada intermediária com uma lista de características, um membro, e um conjunto de diversas vagas para verificar. Os clientes são explicitamente obrigados a solicitar as características que eles querem; de outra forma, sempre que uma nova característica é adicionada, podemos de repente começar a enviar para eles e o cliente não saberá como exibi-la.
Em seguida, para cada característica solicitada, a lista de empregos é enviada para um correspondente “variedades delegate” que busca os metadados da variedade necessária para esse membro. Cada delegate implementa uma interface simples com duas funções: 1) devolver informações sobre a característica com que ela lida, e 2) dado um pedido, devolve se a sua característica é válida e retorna quaisquer metadados adicionais relacionados com a característica.
Isso deixa a implementação atual com total liberdade de buscar as informações de características. Como as diferentes equipes no LinkedIn aparecem com novas ideias para características, nós não desejamos restringir as tecnologias ou os sistemas de informação utilizados. Como consequência, isso força o sistema a ser altamente desacoplado, e os delegates devem ser capazes de operar independentemente de quaisquer outros. Cada delegate conhece suas próprias dependências e não precisa contar com detalhes de implementação de outros delegates. Dito isso, alguns delegates têm dependências comuns, e seria bom evitar fazer chamadas duplicadas quando poderíamos fazer chamadas de lote para um serviço de downstream e depois dividir as informações de volta para cada delegate que a solicitou. Por exemplo, uma característica pode precisar de informações da escola atual do membro, enquanto outra necessita de informação da empresa atual, ambas podem ser buscadas através de uma chamada para o serviço de perfil. Felizmente, podemos simplesmente incorporar parseq-batching ao fazer solicitações para os serviços downstream, e ele vai ser inteligente o suficiente e fundir os pedidos sobrepostos. Delegates não precisam fazer nada para fazer isso funcionar. Eles simplesmente usam o cliente normalmente e recebem tratamento por lotes eficiente com o resto dos delegates gratuitamente.
Uma vez que todas as dependências para um delegate são obtidas, o delegate fará uma chamada para um armazenamento de dados para buscar informações sobre a sua característica de vaga. Como cada delegate termina (ou o tempo limite como medida de precaução para os delegates com mau comportamento), as características de vagas válidas são alimentadas em um mecanismo de classificação e seleção. Usamos duas heurísticas para marcar e classificar características para uma determinada vaga: afinidade com o membro e afinidade com a característica da vaga. Afinidade com o membro é como esse membro tem historicamente reagido a cada característica. Características pelas quais o membro mostrou interesse no passado irão ser melhores classificadas do que as que foram ignoradas ou não selecionadas. Afinidade com a característica da vaga é o quão forte a características é para essa vaga: uma empresa que contrata dezenas de pessoas da empresa atual de um membro, por exemplo, pode ser mais atraente do que se o membro tem uma única conexão na empresa. Uma vez que cada tupla (membro, vaga, variedade) tenha sido marcada e classificada, a variedade mais alta no ranking é selecionada e retornada na resposta. Ambos os clientes e o servidor emitem eventos de rastreamento que são usados para continuar construindo esses modelos. Quando novas características são adicionadas, eles irão se fundir automaticamente para nesse ciclo de vida de dados e não requerem a modificação por parte do desenvolvedor que acrescentou a nova característica no delegate.
Detalhes de implementação
Quando o framework foi construído, tudo o que nos restava era descobrir a melhor maneira para buscar esses insights. Em primeiro lugar, chamamos a equipe gráfica: essa equipa gere a API para acessar todo o gráfico social do LinkedIn. O gráfico é atualizado em tempo real e permite aos clientes fazer consultas incrivelmente complexas para atingir exatamente o que precisam. No entanto, isso vem com um preço; enquanto os nossos requisitos iniciais para escalabilidade e extensibilidade são cumpridos, a velocidade não – essas operações computacionalmente intensivas levam tempo, especialmente para grandes cruzamentos de subgráficos, o que pode se estender para centenas de milissegundos. Por exemplo, determinar todos os que nunca foram para a escola na Universidade do Estado do Arizona e que agora trabalham na IBM exige uma intersecção de dois gráficos, cada um com aproximadamente 400.000 membros que só resultam em mais ou menos 500 pessoas.
O que percebemos é que, embora o aspecto em tempo real seja bom, nós realmente não precisamos dele para a maioria das características, já que as pessoas não estão mudando de escolas e empresas todos os dias. Também é muito mais barato verificar a veracidade do que fazer a descoberta on-the-fly. Se pudermos precomputar esses insights que requerem cruzamentos maciços através de um trabalho Hadoop diário e armazená-los para pesquisa rápida, podemos verificar se a informação que nós recuperamos ainda está correta, em uma pesquisa rápida. Por exemplo, em Voldemort (nosso armazenamento distribuído de key-value), podemos armazenar conexão de um membro que trabalha em alguma empresa e podemos verificar se essa informação não está desatualizada com uma pesquisa de membro rápida. Isso é em ordem de grandeza mais rápido do que fazer os cruzamentos gráficos em tempo real, normalmente exigindo apenas alguns milissegundos no total. Alguns insights (como vagas que têm um pequeno número de candidatos) inerentemente exigem dados em tempo real, e para eles usamos Pinot, que se destaca em percepções de análise relacionadas e tem uma latência relativamente baixa (dezenas de milissegundos).
Resultados e próximos passos
No momento, estamos usando esse sistema para decorar vagas de trabalho em uma variedade de lugares, como os nossos e-mails de vagas, a página de busca de emprego, a home page Jobs, atualizações de empresa patrocinadoras e recomendações no feed. Num futuro próximo, vamos integrar isso a outras ofertas de publicidade, inMails de recrutamentos, e muito mais. Após incrementar esse recurso, vimos resultados extremamente encorajadores, incluindo um aumento de 15% em view vindas de feeds e e-mails, um aumento de 5% nas inscrições de trabalho e mensagens enviadas entre membros quando provenientes de procura de emprego, e até mesmo um aumento de receita de empresas patrocinadoras.
Atualmente, a plataforma Job Flavors suporta quatro características:
- Quantas pessoas a empresa contratou da sua escola
- Quantas pessoas a empresa contratou da sua empresa
- Quantas conexões você tem nessa empresa
- Se a vaga tem atualmente menos de dez candidatos
Enquanto nós temos muitos mais características sendo construídas (incluindo aquelas aplicáveis aos visitantes e outros exclusivos para membros com assinaturas premium), nosso trabalho principal no futuro será integrar características de vagas mais profundamente a pesquisa e recomendações. Estamos atualmente trabalhando para permitir buscas de vagas que possam ser filtradas por características, e categorizar totalmente as nossas recomendações de emprego no “estilo Netflix”. Estamos pensando em tornar o sistema mais robusto, colocando alertas automáticos em tempo real para detectar quaisquer pontos anormais e quantas vezes as características são exibidas ou clicadas.
Agradecimentos
Uma enorme obrigado a Kunal Cholera, Jiuling Wang e Kaushik Rangadurai por sua ajuda no planejamento e design de arquitetura inicial, bem como a todos os nossos parceiros em feed, empresas, jobs, mensagens e pesquisas para trazer esse grande recurso para a vanguarda do LinkedIn. Se você estiver interessado em construir grandes produtos como esse e impactar a vida das pessoas todos os dias, estamos sempre à procura de engenheiros e cientistas de dados talentos para contratar. Vá para a página de carreiras para saber mais.
***
Artigo publicado originalmente no LinkedIn. A tradução foi feita pela Redação iMasters. Você pode ver o original em https://engineering.linkedin.com/blog/2016/08/job-flavors-at-linkedin–part-i.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?