

O Uber facilita experiências de usuários perfeitas e mais divertidas ao canalizar dados de uma variedade de fontes de tempo real. Essas ideias variam de condições de tráfego no momento que fornecem orientação sobre rotas de viagem para o Tempo de Entrega Estimado (ETD) de um pedido UberEATS – e cada métrica no meio.
O completo crescimento do negócio da Uber exigia uma infraestrutura de análise de dados capaz de transmitir uma ampla gama de ideias capturadas de todo o mundo e em todos os momentos, como condições de mercado específicas da cidade para estimativas financeiras globais. Com mais de um trilhão de mensagens em tempo real passando por nossa infraestrutura Kafka todos os dias, a plataforma precisava ser:
- Facilmente navegável por todos os usuários, independentemente da experiência técnica
- Escalável e eficiente o suficiente para analisar eventos em tempo real
- Robusta o suficiente para suportar continuamente centenas, senão milhares de trabalhos críticos
Nós construímos e abrimos AthenaX em código aberto, nossa plataforma de análise de transmissão interna, para satisfazer essas necessidades e oferecer análises de transmissão acessíveis a todos. A AthenaX capacita nossos usuários, tanto técnicos como não técnicos, para executar análises de transmissão compreensíveis e de qualidade de produção usando o Structured Query Language/Linguagem de Consulta Estruturada (SQL). O SQL facilita o processamento de transmissão de eventos – o SQL descreve quais dados devem ser analisados e a AthenaX determina como analisar os dados (por exemplo, localizando ou escalando seus cálculos). Nossa experiência no mundo real mostra que a AthenaX permite aos usuários trazerem carga de trabalho analítica de transmissão em larga escala na produção em questão de horas em comparação com semanas.
Neste artigo, discutimos por que construímos o AthenaX, descrevemos sua infraestrutura e detalhamos os vários recursos de sua plataforma que contribuímos como retorno para a comunidade de código aberto.
A evolução da plataforma de análise de transmissão da Uber
Para melhor servir nossos usuários com insights acionáveis, a Uber deve ser capaz de avaliar a atividade do aplicativo e os vários fatores externos (por exemplo, tráfego, clima e eventos principais) que o afetam. Em 2013, construímos nosso pipeline de análise de transmissão de primeira geração no topo do Apache Storm. Embora efetivo, este pipeline apenas computou conjuntos específicos de métricas; em um nível muito alto, esta solução consumiu eventos em tempo real, agregou os resultados para múltiplas dimensões (por exemplo, região geográfica, intervalo de tempo) e publicou-os em uma página da Web.
À medida que expandimos nossas ofertas, nossa necessidade de transmitir análises de forma rápida e efetiva tornou-se cada vez mais importante. No caso da UberEATS, as métricas em tempo real, como as taxas de satisfação do cliente e as vendas, permitem que os restaurantes melhor compreendam a saúde de seus negócios e a satisfação de seus clientes, o que lhes permite otimizar os ganhos potenciais. Para calcular essas métricas, nossos engenheiros implementaram seus aplicativos de análise de transmissão no topo do do Apache Storm ou Apache Samza. Mais especificamente, os aplicativos projetaram, filtraram ou juntaram vários tópicos da Kafka juntos para calcular resultados, com a capacidade de escalar até centenas de contêineres.
Essas soluções, no entanto, ainda não eram ideais. Os usuários foram forçados a implementar, gerenciar e monitorar seus próprios aplicativos de análise de transmissão, ou foram limitados a buscar respostas para um conjunto de perguntas pré-definido.
AthenaX se propõe a abordar este dilema e traz o melhor de ambos os mundos, permitindo que os usuários criem análises de transmissão personalizadas e preparadas para produção usando o SQL. Para atender às necessidades da escala da Uber, o AthenaX compila e otimiza consultas SQL para aplicativos de transmissão distribuídos que podem processar até vários milhões de mensagens por segundo usando apenas oito contêineres YARN. O AthenaX também gerencia os aplicativos de ponta a ponta, incluindo o monitoramento contínuo de sua saúde, dimensionando-os automaticamente com base no tamanho das entradas e recuperando-os graciosamente de falhas de node ou falhas de centro de dados.
Na próxima seção, detalhamos como construímos a arquitetura robusta, mas flexível da AthenaX.
Criando aplicativos analíticos de transmissão com SQL
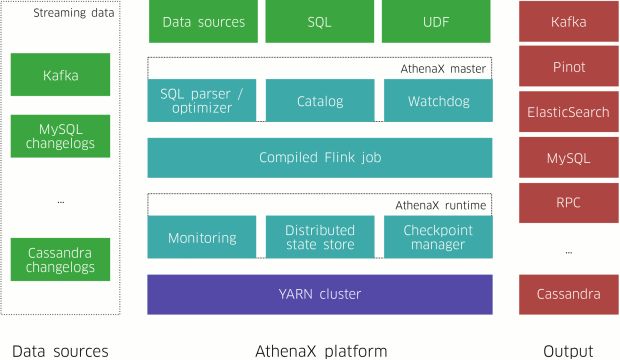
As lições que aprendemos nesta evolução nos levaram a AthenaX, a geração atual da plataforma analítica de transmissão da Uber. A principal característica do AthenaX é que os usuários podem especificar suas análises de transmissão usando apenas SQL e, então, o AthenaX as executa de forma eficiente. O AthenaX compila consultas para aplicativos confiáveis, eficientes e distribuídos e gerencia o ciclo de vida completo do aplicativo, permitindo que os usuários se concentrem exclusivamente na lógica de negócios. Como resultado, os usuários de todos os níveis técnicos podem executar seus aplicativos de análise de transmissão em produção em um intervalo de poucas horas, independentemente da escala.
Conforme ilustrado na Figura 1, acima, um trabalho AthenaX considera várias fontes de dados como entrada, executa o processamento e a análise necessários e produz saídas para diferentes tipos de endpoints. O fluxo de trabalho do AthenaX segue os passos abaixo:
- Os usuários especificam um trabalho em SQL e enviam-no para o mestre AthenaX.
- O mestre AthenaX valida a consulta e compila-a para um trabalho Flink.
- O AthenaX mestre empacota, implanta e executa o trabalho no cluster YARN. O mestre também recupera os trabalhos em caso de falha.
- O trabalho começa a processar os dados e produz resultados em sistemas externos (por exemplo, Kafka).
Na nossa experiência, o SQL é bastante expressivo para especificar aplicativos de transmissão. Pegue o Gerenciador de Restaurantes, por exemplo; neste caso de uso, a seguinte consulta conta o número de pedidos recebidos por um restaurante nos 15 minutos anteriores, descritos abaixo:
SELECT HOP_START(rowtime, INTERVAL ‘1’ MINUTE, INTERVAL ’15’ MINUTE) AS window_start, restaurant_uuid, COUNT(*) AS total_order FROM ubereats_workflow WHERE state = ’CREATED’ GROUP BY restaurant_uuid, HOP(rowtime, INTERVAL ‘1’ MINUTE, INTERVAL ’15’ MINUTE)
Essencialmente, a consulta verifica o tópico Kafka ubereats_workflow, filtra eventos irrelevantes e agrega o número de eventos em uma janela deslizante de 15 minutos a uma frequência de um minuto.
AthenaX também suporta funções definidas pelo usuário (UDFs) nas consultas, enriquecendo suas funcionalidades. Por exemplo, a seguinte consulta que exibe viagens para um aeroporto específico usa a UDF para converter as longitudes e latitudes na ID do aeroporto, descrita abaixo:
CREATE FUNCTION AirportCode AS …; SELECT AirportCode(location.lng,location.lat) AS airport driver_id AS driver_id, … FROM event_user_driver_app WHERE NAME =‘trip_start’
Um exemplo mais complicado é calcular os ganhos potenciais de um determinado restaurante, como exemplificado por Restaurant Manager:
SELECT w.created_timestamp, w.datestr, w.restaurant_uuid, w.order_job_uuid, o.price, o.currency, FROM ubereats_workflow_etd_summary w JOIN ubereats_order_state_changes o ON o.job_uuid = w.order_job_uuid WHERE w.status IN (‘CANCELED_BY_EATER’, ‘UNFULFILLED’) AND w.proctime BETWEEN o.proctime – INTERVAL ’60’ SECOND AND o.proctime + INTERVAL ’60’ SECOND
A consulta junta os eventos em tempo real que compõem o status de um pedido e seus detalhes para calcular ganhos potenciais.
Nossa experiência mostrou que mais de 70% dos aplicativos de transmissão na produção podem ser expressos em SQL. Os aplicativos AthenaX também podem exibir diferentes níveis de garantia de consistência de dados – um trabalho AthenaX pode processar eventos em tempo real no máximo uma vez, pelo menos uma vez ou exatamente uma vez.
Em seguida, discutimos o fluxo de trabalho da compilação da consulta AthenaX.
Compilando consultas para programas de fluxo de dados distribuídos
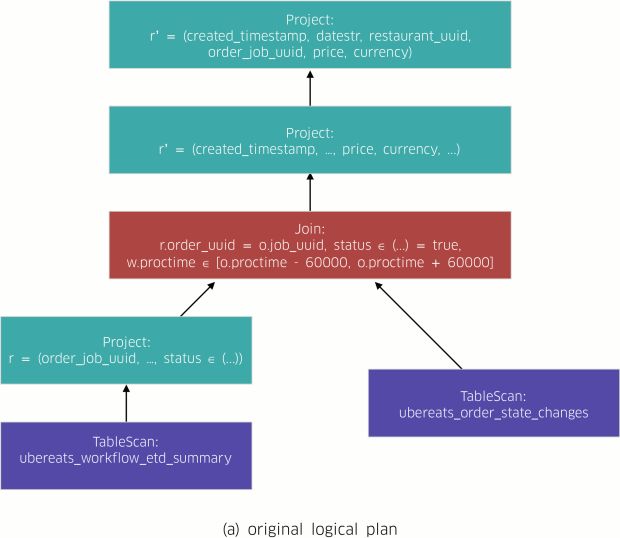
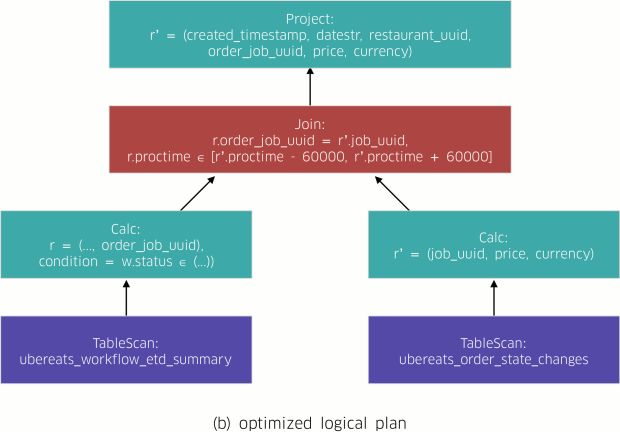
AthenaX alavanca o Apache Flink para implementar a abordagem clássica Volcano para compilar consultas, até os programas de fluxo de dados distribuídos. A Figura 2, abaixo, descreve o fluxo de trabalho do processo de compilação do Restaurant Manager:
- AthenaX analisa a consulta e converte-a em um plano lógico (Figura 2 (a)). Um plano lógico é um gráfico acíclico direto (DAG) que descreve a semântica da consulta.
- AthenaX otimiza o plano lógico (Figura 2 (b)). Neste exemplo, o otimizador agrupa a projeção e a filtragem com as tarefas de digitalização dos fluxos. Dessa forma, minimiza a quantidade de dados necessários para se juntar.
- O plano lógico é traduzido para o plano físico correspondente. Um plano físico é um DAG que consiste em detalhes como localidade e paralelismo. Esses detalhes descrevem como a consulta deve ser executada em máquinas físicas. Com essa informação, o plano físico é diretamente mapeado para o programa de fluxo de dados distribuído final (Figura 2 (c)).
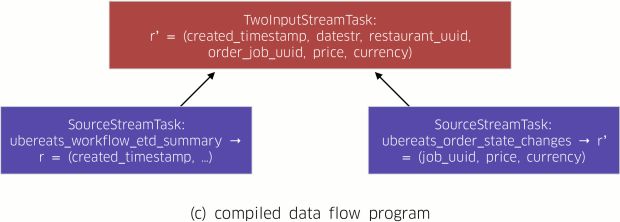
Uma vez que o processo de compilação esteja completo, o AthenaX executa o programa de fluxo de dados compilado em um cluster Flink. Os aplicativos podem processar até vários milhões de mensagens por segundo usando oito contêineres YARN na produção. A velocidade e o alcance das capacidades de processamento da AthenaX garantem que as informações mais atualizadas são obtidas, facilitando assim experiências melhores para nossos usuários.
Usando AthenaX na produção na Uber
Na produção há seis meses, a versão atual do AthenaX executa mais de 220 aplicativos em vários centros de dados, processando bilhões de mensagens por dia. AthenaX atende múltiplas plataformas e produtos, incluindo Michelangelo, Restaurant Manager da UberEATS e UberPOOL.
Também implementamos os seguintes recursos para dimensionar melhor a plataforma:
- Estimativa de recursos e dimensionamento automático. AthenaX estima o número de vcores e memória com base na consulta e a taxa de transferência de dados de entrada. Observamos também que as cargas dos trabalhos variam durante o horário de pico e fora de pico. Para maximizar a utilização do cluster, o mestre do AthenaX monitora continuamente as marcas de água e as estatísticas de coleta de lixo de cada trabalho e reinicia-os, se necessário. O modelo de tolerância a falhas do Flink garante que os trabalhos ainda produzam os resultados corretos.
- Monitoramento e recuperação automática de falhas. Muitos trabalhos do AthenaX servem como blocos de construção críticos do pipeline e, como resultado, requerem disponibilidade de 99,99%. O mestre de AthenaX monitora continuamente a saúde de todos os trabalhos do AthenaX e os recupera graciosamente em caso de falhas de node, falhas de rede ou mesmo falhas de centro de dados.
Avançando: uma maneira simplificada de transmitir as análises

Ao usar o SQL como abstração, o AthenaX simplifica as tarefas de análise de transmissão e permite que os usuários tragam aplicativos de análise de transmissão em larga escala para a produção rapidamente.
Para capacitar outros a construir suas próprias plataformas de transmissão de dados, abrimos AthenaX em GitHub em código aberto, bem como fornecemos vários recursos principais de volta às comunidades Apache Flink e Apache Calcite. Como parte do lançamento do Flink 1.3, por exemplo, contribuímos com o grupo windows e suporte para tipo de dados complexos, e pretendemos compartilhar um coletor de tabela JDBC no próximo lançamento.
Se o desenvolvimento de soluções escaláveis de análise de dados atrai para você, considere candidatar-se a um cargo em nossa equipe.
Haohui Mai e Bill Liu são engenheiros de software na equipe de Análise de Transmissão da Uber. Naveen Cherukuri é um gerente de engenharia, também na equipe de Análise de Transmissão da Uber.
Crédito do cabeçalho da foto: “Antílope saltando sobre o fluxo de zonas húmidas” por Conor Myhrvold, Delta do Okavango, Botswana.
***
Este artigo é do Uber Engineering. Ele foi escrito por Haohui Mai, Bill Liu e Naveen Cherukuri. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/athenax/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?