

Artigo do TensorFlow Team, publicado originalmente pelo Google Developers Blog. A tradução foi feita pela Redação iMasters com autorização.
***
Bem-vindo à Parte 2 de uma série que apresenta Conjuntos de Dados e Estimadores do TensorFlow. Estamos dedicando este artigo à colunas de características – uma estrutura de dados que descreve as características que um Estimador requer para treinamento e inferência. Como você verá, as colunas de característica são muito ricas, permitindo que você represente uma gama diversificada de dados.
Na Parte 1, utilizamos o Estimador pré-fabricado DNNClassifier para treinar um modelo para prever diferentes tipos de Flores de Íris a partir de quatro características de entrada. Esse exemplo criou apenas colunas de características numéricas (do tipo tf.feature_column.numeric_column). Embora essas colunas de característica fossem suficientes para modelar os comprimentos de pétalas e sépalas, os conjuntos de dados do mundo real contêm todos os tipos de características não numéricas. Por exemplo:
Como podemos representar tipos de características não numéricas? É exatamente sobre isso esse artigo do site.
Entrada para uma Rede Neural Profunda
Vamos começar perguntando que tipo de dados podemos realmente alimentar em uma rede neural profunda? A resposta é, claro, números (por exemplo, tf.float32). Afinal, todo neurônio em uma rede neural realiza operações de multiplicação e adição em pesos e dados de entrada. Os dados de entrada da vida real, no entanto, geralmente contêm dados não numéricos (categóricos). Por exemplo, considere uma característica product_class que pode conter os seguintes três valores não numéricos:
- kitchenware
- electronics
- sports
Os modelos ML geralmente representam valores categóricos como vetores simples, nos quais 1 representa a presença de um valor e 0 representa a ausência de um valor. Por exemplo, quando product_class está configurado para sports, um modelo ML geralmente representaria product_class como [0, 0, 1], o que significa:
- 0: kitchenware está ausente
- 0: eletronics está ausente
- 1: sports: está presente
Assim, embora os dados brutos possam ser numéricos ou categóricos, um modelo ML representa todas as características como um número ou um vetor de números.
Apresentando as Colunas de Características
Como mostra a Figura 2, você especifica a entrada para um modelo através do argumento feature_columns de um Estimador (DNNClassifier para Íris). Colunas de Características atravessam dados de entrada (como retornado por input_fn) com seu modelo.
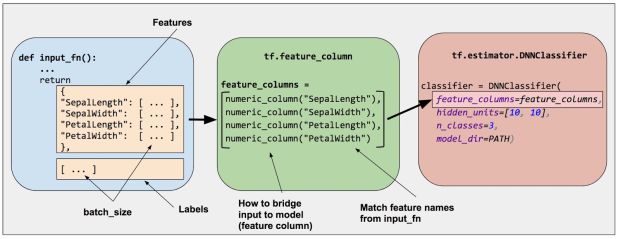
Para representar as características como uma coluna de característica, as funções de chamada do pacote tf.feature_column. Este artigo explica nove das funções neste pacote. Como mostra a Figura 3, todas as nove funções retornam uma Coluna Categórica ou um objeto Coluna-Compacta, exceto bucketized_column que herda de ambas as classes:
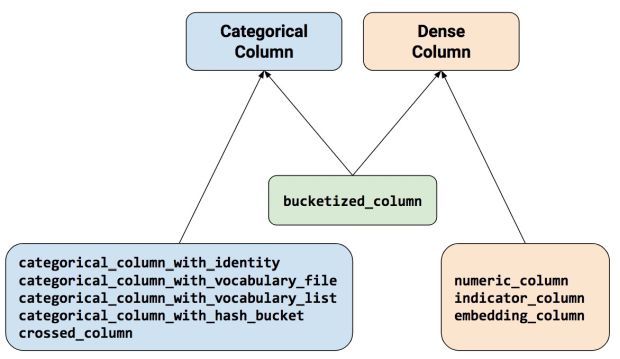
Vejamos mais detalhadamente essas funções.
Coluna Numérica
O classificador Íris chamado tf.numeric_column() para todas as características de entrada: SepalLength, SepalWidth, PetalLength, PetalWidth. Embora tf.numeric_column() forneça argumentos opcionais, chamar a função sem argumentos é uma maneira perfeitamente fácil de especificar um valor numérico com o tipo de dados padrão (tf.float32) como entrada para o seu modelo. Por exemplo:
# Defaults to a tf.float32 scalar. numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength")
Use o argumento dtype para especificar um tipo de dado numérico não padrão. Por exemplo:
# Represent a tf.float64 scalar.
numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength",
dtype=tf.float64)
Por padrão, uma coluna numérica cria um valor único (escalar). Use o argumento shape para especificar outra forma. Por exemplo:
# Represent a 10-element vector in which each cell contains a tf.float32.
vector_feature_column = tf.feature_column.numeric_column(key="Bowling",
shape=10)
# Represent a 10x5 matrix in which each cell contains a tf.float32.
matrix_feature_column = tf.feature_column.numeric_column(key="MyMatrix",
shape=[10,5])
Coluna Bucketized
Muitas vezes, você não quer alimentar um número diretamente no modelo, mas dividir seu valor em diferentes categorias com base em intervalos numéricos. Para fazer isso, crie uma coluna bucketized. Por exemplo, considere dados brutos que representem o ano em que uma casa foi construída. Em vez de representar esse ano como uma coluna numérica escalar, poderíamos dividir o ano nos seguintes quatro buckets:
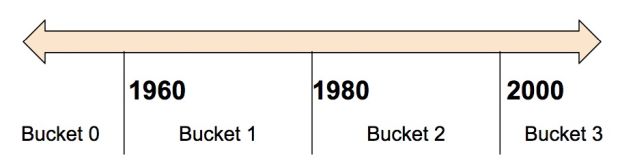
O modelo representará os reservatórios da seguinte forma:
| Date Range | Represented as |
| < 1960 | [1, 0, 0, 0] |
| >= 1960 but < 1980 | [0, 1, 0, 0] |
| >= 1980 but < 2000 | [0, 0, 1, 0] |
| > 2000 | [0, 0, 0, 1] |
Por que você desejaria dividir um número – uma entrada perfeitamente válida para o nosso modelo – em um valor categórico como esse? Bem, note que a categorização divide um único número de entrada em um vetor de quatro elementos. Portanto, o modelo agora pode aprender quatro pesos individuais em vez de apenas um. Quatro pesos criam um modelo mais rico do que um. Mais importante ainda, a técnica de bucketizing permite que o modelo distinga claramente entre as diferentes categorias do ano, já que apenas um dos elementos está definido (1) e os outros três elementos estão desmarcados (0). Quando usamos apenas um único número (um ano) como entrada, o modelo não pode distinguir as categorias. Assim, o bucketing fornece o modelo com informações importantes adicionais que pode usar para aprender.
O código a seguir demonstra como criar um recurso bucketized:
# A numeric column for the raw input.
numeric_feature_column = tf.feature_column.numeric_column("Year")
# Bucketize the numeric column on the years 1960, 1980, and 2000
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = numeric_feature_column,
boundaries = [1960, 1980, 2000])
Observe o seguinte:
- Antes de criar a coluna de bucketized, primeiro criamos uma coluna numérica para representar o ano bruto.
- Passamos a coluna numérica como o primeiro argumento para tf.feature_column.bucketized_column().
- Especificar um vetor boundaries de três elementos cria um vetor bucketized de quatro elementos.
Coluna de identidade categórica
As colunas de identidade categóricas são um caso especial de colunas bucketized. Em colunas bucketized tradicionais, cada reservatório representa uma gama de valores (por exemplo, de 1960 a 1979). Em uma coluna de identidade categórica, cada reservatório representa um único número inteiro exclusivo. Por exemplo, digamos que você deseja representar o intervalo inteiro [0, 4). (Ou seja, você quer representar os números inteiros 0, 1, 2 ou 3.) Neste caso, o mapeamento de identidade categórica se parece com isso:
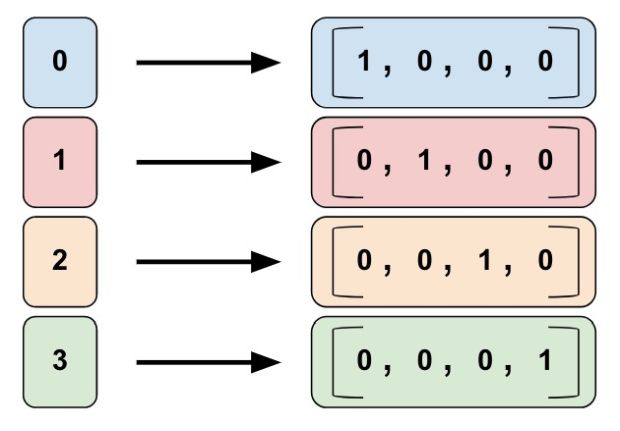
Então, por que você iria querer representar valores como colunas de identidade categórica? Tal como acontece com colunas bucketized, um modelo pode aprender um peso separado para cada classe em uma coluna de identidade categórica. Por exemplo, em vez de usar uma string para representar o product_class, vamos representar cada classe com um valor de número inteiro único. Isso é:
- 0 = “kitchenware”
- 1 = “eletronics”
- 2 = “sport”
Chame tf.feature_column.categorical_column_with_identity() para implementar uma coluna de identidade categórica. Por exemplo:
# Create a categorical output for input "feature_name_from_input_fn",
# which must be of integer type. Value is expected to be >= 0 and < num_buckets
identity_feature_column = tf.feature_column.categorical_column_with_identity(
key='feature_name_from_input_fn',
num_buckets=4) # Values [0, 4)
# The 'feature_name_from_input_fn' above needs to match an integer key that is
# returned from input_fn (see below). So for this case, 'Integer_1' or
# 'Integer_2' would be valid strings instead of 'feature_name_from_input_fn'.
# For more information, please check out Part 1 of this blog series.
def input_fn():
...<code>...
return ({ 'Integer_1':[values], ..<etc>.., 'Integer_2':[values] },
[Label_values])
Coluna de vocabulário categórico
Não podemos inserir strings diretamente em um modelo. Em vez disso, primeiro devemos mapear strings para valores numéricos ou categóricos. As colunas de vocabulário categórico fornecem uma boa maneira de representar strings como um vetor único. Por exemplo:
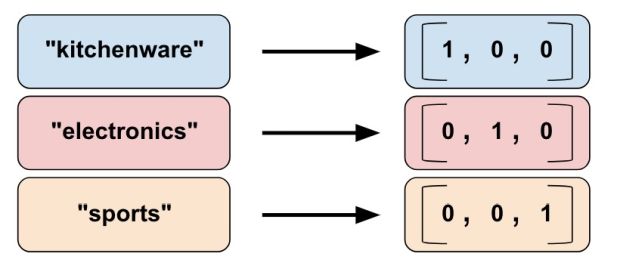
Como você pode ver, colunas de vocabulário categórico são uma espécie de versão enum de colunas de identidade categórica. TensorFlow fornece duas funções diferentes para criar colunas de vocabulário categórico:
- tf.feature_column.categorical_column_with_vocabulary_list()
- tf.feature_column.categorical_column_with_vocabulary_file()
A função tf.feature_column.categorical_column_with_vocabulary_list () mapeia cada string para um número inteiro com base em uma lista de vocabulário explícita. Por exemplo:
# Given input "feature_name_from_input_fn" which is a string,
# create a categorical feature to our model by mapping the input to one of
# the elements in the vocabulary list.
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_list(
key="feature_name_from_input_fn",
vocabulary_list=["kitchenware", "electronics", "sports"])
A função anterior tem uma desvantagem significativa; ou seja, há muita tipagem/digitação quando a lista de vocabulário é longa. Para esses casos, chame tf.feature_column.categorical_column_with_vocabulary_file() em vez disso, o que permite que você coloque as palavras do vocabulário em um arquivo separado. Por exemplo:
# Given input "feature_name_from_input_fn" which is a string,
# create a categorical feature to our model by mapping the input to one of
# the elements in the vocabulary file
vocabulary_feature_column =
tf.feature_column.categorical_column_with_vocabulary_file(
key="feature_name_from_input_fn",
vocabulary_file="product_class.txt",
vocabulary_size=3)
# product_class.txt should have one line for vocabulary element, in our case:
kitchenware
electronics
sports
Usando reservatórios hash para limitar categorias
Até agora, trabalhamos com um número de categorias ingenuamente pequeno. Por exemplo, nosso exemplo product_class tem apenas três categorias. Muitas vezes, porém, o número de categorias pode ser tão grande que não é possível ter categorias individuais para cada palavra de vocabulário ou número inteiro porque isso consumiria muita memória. Para esses casos, podemos, em vez disso, revirar a questão e perguntar: “Quantas categorias eu estou disposta a ter para minha entrada?” Na verdade, a função tf.feature_column.categorical_column_with_hash_buckets() permite que você especifique o número de categorias. Por exemplo, o código a seguir mostra como esta função calcula um valor de hash da entrada e, em seguida, coloca-o em uma das categorias hash_bucket_size usando o operador do módulo:
# Create categorical output for input "feature_name_from_input_fn".
# Category becomes: hash_value("feature_name_from_input_fn") % hash_bucket_size
hashed_feature_column =
tf.feature_column.categorical_column_with_hash_bucket(
key = "feature_name_from_input_fn",
hash_buckets_size = 100) # The number of categories
Neste ponto, você pode legitimamente pensar: “Isso é loucura!” Afinal, estamos forçando os diferentes valores de entrada a um conjunto menor de categorias. Isso significa que duas entradas, provavelmente, completamente não relacionadas, serão mapeadas para a mesma categoria e, consequentemente, significam a mesma coisa para a rede neural. A Figura 7 ilustra este dilema, mostrando que kitchenware e sports são atribuídos à categoria (reservatório hash) 12:
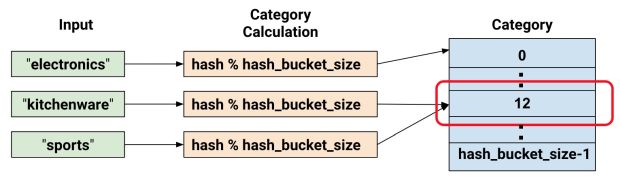
Tal como acontece com muitos fenômenos contra intuitivos na aprendizagem de máquina, verifica-se que o hashing muitas vezes funciona bem na prática. Isso porque as categorias hash fornecem o modelo com alguma separação. O modelo pode usar características adicionais para separar kitchenware de sports.
Cruzamentos de características
A última coluna categórica que abordaremos nos permite combinar várias características de entrada em uma única. A combinação de características, mais conhecida como cruzamento de características, permite ao modelo aprender pesos separados especificamente para o que quer que a combinação de características signifique.
Mais concretamente, suponha que queremos que nosso modelo calcule os preços dos imóveis em Atlanta, G.A.
Os preços imobiliários nesta cidade variam muito dependendo da localização. Representando latitude e longitude como características separadas não é muito útil na identificação de dependências de localização imobiliária; no entanto, cruzar a latitude e a longitude em uma única característica pode identificar os locais.
Suponhamos que representemos Atlanta como uma grade de seções retangulares 100×100, identificando cada uma das 10.000 seções por uma cruz de sua latitude e longitude. Esta cruz permite que o modelo adote as condições de preços relacionadas a cada seção individual, que é um sinal muito mais forte do que a latitude e a longitude sozinhas.
A Figura 8 mostra nosso plano, com os valores de latitude e longitude para os cantos da cidade:
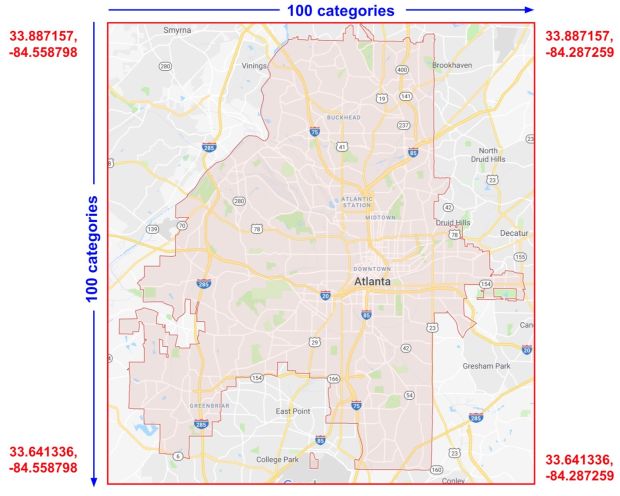
Para a solução, usamos uma combinação de algumas colunas de características que examinamos antes, bem como a função tf.feature_columns.crossed_column().
# In our input_fn, we convert input longitude and latitude to integer values
# in the range [0, 100)
def input_fn():
# Using Datasets, read the input values for longitude and latitude
latitude = ... # A tf.float32 value
longitude = ... # A tf.float32 value
# In our example we just return our lat_int, long_int features.
# The dictionary of a complete program would probably have more keys.
return { "latitude": latitude, "longitude": longitude, ...}, labels
# As can be see from the map, we want to split the latitude range
# [33.641336, 33.887157] into 100 buckets. To do this we use np.linspace
# to get a list of 99 numbers between min and max of this range.
# Using this list we can bucketize latitude into 100 buckets.
latitude_buckets = list(np.linspace(33.641336, 33.887157, 99))
latitude_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('latitude'),
latitude_buckets)
# Do the same bucketization for longitude as done for latitude.
longitude_buckets = list(np.linspace(-84.558798, -84.287259, 99))
longitude_fc = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column('longitude'), longitude_buckets)
# Create a feature cross of fc_longitude x fc_latitude.
fc_san_francisco_boxed = tf.feature_column.crossed_column(
keys=[latitude_fc, longitude_fc],
hash_bucket_size=1000) # No precise rule, maybe 1000 buckets will be good?
Você pode criar um cruzamento de características de qualquer um dos seguintes:
- Nomes de características; isto é, nomes do dict retornado de input_fn.
- Qualquer Coluna Categórica (veja a Figura 3), exceto categorical_column_with_hash_bucket.
Quando as colunas de características latitude_fc e longitude_fc são cruzadas, o TensorFlow criará 10.000 combinações de (latitude_fc, longitude_fc) organizadas da seguinte maneira:
(0,0),(0,1)... (0,99) (1,0),(1,1)... (1,99) …, …, ... (99,0),(99,1)...(99, 99)
A função tf.feature_column.crossed_column executa um cálculo de hash nessas combinações e, em seguida, abre o resultado em uma categoria executando uma operação de módulo com hash_bucket_size. Conforme discutido anteriormente, executar hash e a função módulo, provavelmente resultará em colisões de categoria; isto é, múltiplos cruzamentos de características (latitude e longitude) acabarão no mesmo reservatório hash. No entanto, na prática, executar o cruzamento de características ainda fornece um valor significativo para a capacidade de aprendizagem de seus modelos.
Um pouco contra a intuição, ao criar cruzamentos de características, você normalmente deve incluir as características originais (não cruzadas) em seu modelo. Por exemplo, forneça não só o cruzamento de característica (latitude, longitude), mas também a latitude e longitude como características separadas. As características de latitude e longitude separadas ajudam o modelo a separar os conteúdos de reservatórios hash contendo diferentes cruzamentos de características.
Veja este link para um exemplo de código completo para isso. Além disso, a seção de referência no final desta publicação para muitos mais exemplos de cruzamento de características.
Indicador e colunas de incorporação
As colunas de indicadores e as colunas de incorporação nunca funcionam diretamente nas características, mas, em vez disso, tomam as colunas categóricas como entrada.
Ao usar uma coluna de indicadores, estamos dizendo ao TensorFlow que faça exatamente o que vimos no nosso exemplo categórico de product_class. Ou seja, uma coluna de indicadores trata cada categoria como um elemento em um único vetor, onde a categoria de correspondência tem o valor 1 e o resto tem 0s:
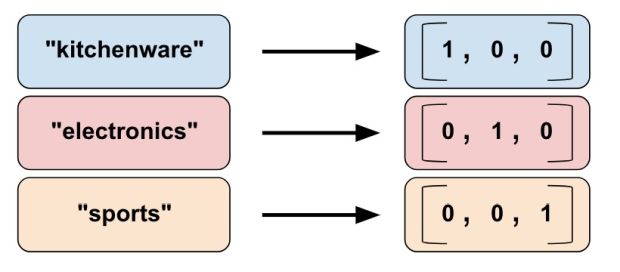
Veja como você cria uma coluna de indicadores:
categorical_column = ... # Create any type of categorical column, see Figure 3 # Represent the categorical column as an indicator column. # This means creating a one-hot vector with one element for each category. indicator_column = tf.feature_column.indicator_column(categorical_column)
Agora, suponha que em vez de ter apenas três classes possíveis, temos um milhão. Ou talvez um bilhão. Por uma série de razões (muito técnicas para abordar aqui), à medida que o número de categorias cresce, torna-se inviável treinar uma rede neural usando colunas de indicadores.
Podemos usar uma coluna de incorporação para superar essa limitação. Em vez de representar os dados como um vetor único de várias dimensões, uma coluna de incorporação representa esses dados como um vetor ordinário de menor dimensão, em que cada célula pode conter qualquer número, não apenas 0 ou 1. Ao permitir uma paleta mais rica de números para cada célula, uma coluna de incorporação contém muito menos células do que uma coluna de indicador.
Vejamos um exemplo comparando colunas de indicador e de incorporação. Suponha que nossos exemplos de entrada consistam em palavras diferentes de uma paleta limitada de apenas 81 palavras. Suponha ainda que o conjunto de dados forneça as seguintes palavras de entrada em 4 exemplos distintos:
- “dog”
- “spoon”
- “scissors”
- “guitar”
Nesse caso, a Figura 10 ilustra o caminho de processamento para colunas de incorporação ou colunas de indicadores.
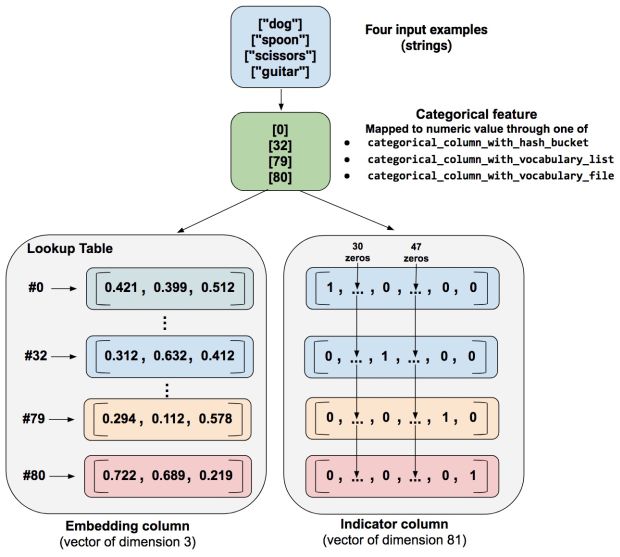
Quando um exemplo é processado, uma das funções categorical_column_with… mapeia a string de exemplo para um valor categórico numérico. Por exemplo, uma função mapeia “spoon” para [32]. (O 32 vem da nossa imaginação – os valores reais dependem da função de mapeamento.) Você pode, então, representar esses valores categóricos numéricos de uma das duas maneiras a seguir:
- Como uma coluna de indicadores. Uma função converte cada valor categórico numérico em um vetor de 81 elementos (porque nossa paleta consiste em 81 palavras), colocando um 1 no índice do valor categórico (0, 32, 79, 80) e um 0 em todas as outras posições .
- Como uma coluna de incorporação. Uma função usa os valores categóricos numéricos (0, 32, 79, 80) como índices para uma tabela de pesquisa. Cada slot/abertura naquela tabela de pesquisa contém um vetor de 3 elementos.
Como os valores nos vetores de incorporação são magicamente atribuídos? Na verdade, as tarefas acontecem durante o treinamento. Ou seja, o modelo aprende a melhor maneira de mapear seus valores categóricos numéricos de entrada para o valor do vetor de incorporação para resolver seu problema. As colunas de incorporação aumentam as capacidades do seu modelo, uma vez que um vetor de incorporação aprende novos relacionamentos entre categorias a partir dos dados de treinamento.
Por que o vetor de incorporação tamanho 3 está em nosso exemplo? Bem, a seguinte “fórmula” fornece uma regra geral sobre o número de dimensões de incorporação:
embedding_dimensions = number_of_categories**0.25
Ou seja, a dimensão do vetor de incorporação deve ser a 4ª raiz do número de categorias. Como nosso tamanho de vocabulário neste exemplo é 81, o número recomendado de dimensões é 3:
3 = 81**0.25
Observe que esta é apenas uma orientação geral; você pode definir o número de dimensões de incorporação conforme seu desejo.
Chame tf.feature_column.embedding_column para criar uma coluna de incorporação. A dimensão do vetor de incorporação depende do problema em questão como descrito acima, mas os valores comuns vão de tão baixos quanto 3 até 300 ou mesmo além:
categorical_column = ... # Create any categorical column shown in Figure 3.
# Represent the categorical column as an embedding column.
# This means creating a one-hot vector with one element for each category.
embedding_column = tf.feature_column.embedding_column(
categorical_column=categorical_column,
dimension=dimension_of_embedding_vector)
Incorporações é um grande tópico na aprendizagem de máquina. Esta informação foi apenas para você começar a usá-las como colunas de características. Por favor, veja o final desta postagem para obter mais informações.
Passando as colunas de características aos Estimadores
Ainda está aí? Espero que sim, porque só temos mais um pedacinho restante antes de você se formar nos conceitos básicos das colunas de características.
Como vimos na Figura 1, as colunas de características mapeiam seus dados de entrada (descritos pelo dicionário de características retornado de input_fn) para os valores alimentados ao seu modelo. Você especifica as colunas de características como uma lista para um argumento feature_columns de um estimador. Observe que o(s) argumento(s) feature_columns variam dependendo do Estimador:
- LinearClassifier e LinearRegressor:
- Aceita todos os tipos de coluna de características.
- DNNClassifier e DNNRegressor:
- Apenas aceita colunas densas, veja a Figura 3. Outros tipos de coluna devem ser envolvidas em uma indicator_column ou em uma embedding_column como descrito anteriormente.
- DNNLinearCombinedClassifier e DNNLinearCombinedRegressor:
- O argumento linear_feature_columns pode aceitar qualquer tipo de coluna, como o LinearClassifier e LinearRegressor acima.
- O argumento dnn_feature_columns no entanto está limitado a colunas densas, como DNNClassifier e DNNRegressor acima.
O motivo das regras acima está além do escopo desta postagem introdutória, mas nós nos certificaremos de cobri-lo em uma futura postagem do blog.
Resumo
Use as colunas de característica para mapear seus dados de entrada para as representações que você alimenta seu modelo. Nós usamos apenas numeric_column na Parte 1 desta série, mas trabalhando com as outras funções descritas nesta postagem, você pode criar facilmente outras colunas de características.
Para obter mais detalhes sobre colunas de características, certifique-se de verificar:
- Vídeo de Josh Gordon sobre Engenharia de Características
- E do mesmo autor, um caderno Jupyter
- O TensorFlow – Tutorial Amplo e Profundo
- Exemplos de DNNs e modelos lineares que usam colunas de características
Se você quiser saber mais sobre incorporações:
- Deep Learning, PNL e representações (o blog de Colah)
- E confira o Projetor de Incorporações do TensorFlow
***
Este artigo é do Google Developers Blog. Ele foi escrito pelo TensorFlow Team. A tradução foi feita pela Redação iMasters com autorização. Você pode acessar o original em: https://developers.googleblog.com/2017/11/introducing-tensorflow-feature-columns.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?