

Artigo do Google Developers Brazil e foi escrito por Brendan McMahan e Daniel Ramage.
***
A abordagem do aprendizado de máquina padrão exige centralização dos dados de treinamento em uma máquina ou em um datacenter. Por isso, o Google criou uma das infraestruturas de nuvem mais seguras e sólidas para processar esses dados e melhorar nossos serviços. Agora, para modelos treinados a partir da interação do usuário com dispositivos móveis, estamos apresentando uma nova abordagem: o aprendizado unificado.
O aprendizado unificado permite que celulares assimilem um modelo de previsão compartilhado de forma colaborativa e, ao mesmo tempo, mantem todos os dados de treinamento no dispositivo, desvinculando a capacidade de usar o aprendizado de máquina da necessidade de armazenar os dados na nuvem. Isso vai além do uso de modelos locais que fazem previsões em dispositivos móveis (como a Mobile Vision API e o On-Device Smart Reply) porque traz o treinamento-modelo para o dispositivo.
Funciona mais ou menos assim: seu dispositivo baixa o modelo atual, melhora-o assimilando dados do seu celular e resume as mudanças em uma atualização direcionada pequena. Somente essa atualização do modelo é enviada para a nuvem, com comunicação criptografada, e lá ele se mistura com outras atualizações do usuário para melhorar o modelo compartilhado. Todos os dados de treinamento continuam no dispositivo, e nenhuma atualização individual é armazenada na nuvem.
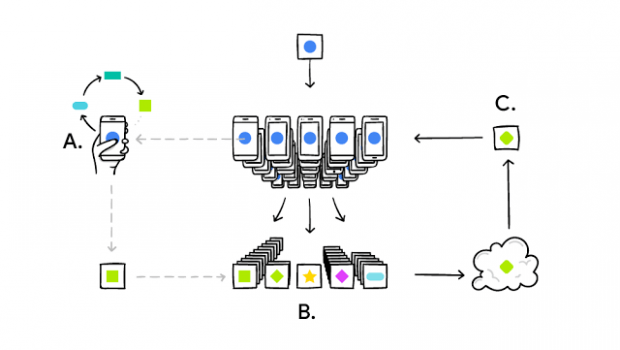
O aprendizado unificado possibilita modelos mais inteligentes, menor latência e menos consumo de energia, sem comprometer a privacidade. Essa abordagem ainda tem outro benefício imediato: além de fornecer uma atualização ao modelo compartilhado, o modelo melhorado do seu celular também pode ser usado imediatamente, amparando experiências personalizadas pela forma com que você usa o celular.
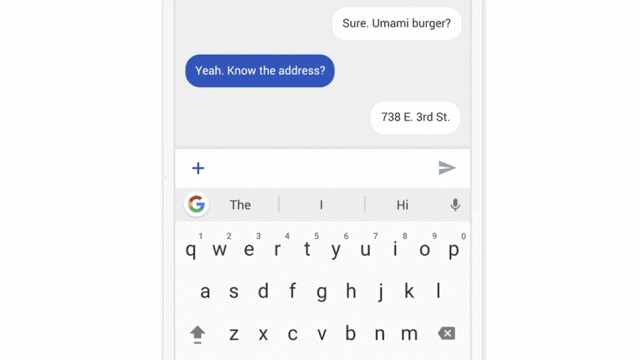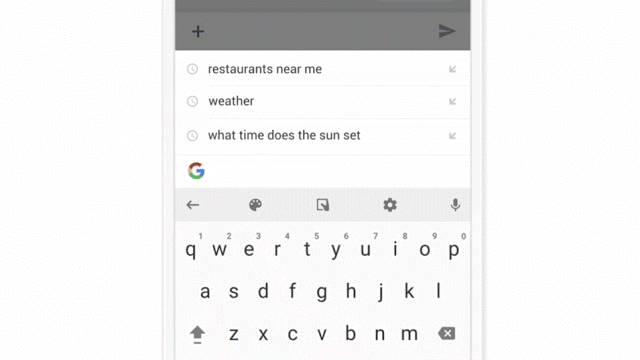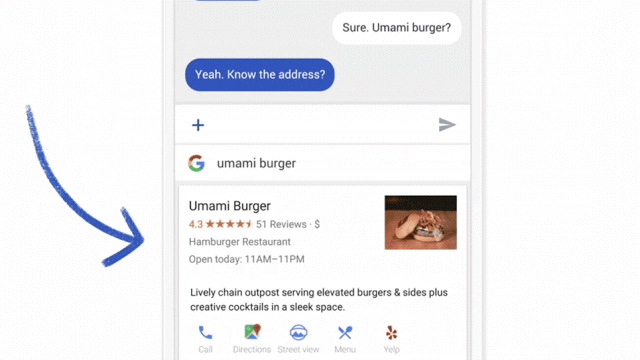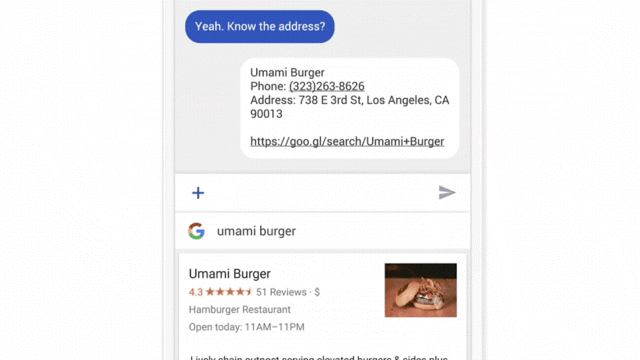
Ainda estamos testando o aprendizado unificado no Gboard on Android, o Teclado do Google. Quando o Gboard mostra uma consulta sugerida, seu celular armazena localmente as informações sobre o contexto atual e se você clicou na sugestão. O aprendizado unificado processa esse histórico no dispositivo para sugerir melhorias à próxima iteração do modelo de sugestão de consulta do Gboard.
Para tornar o aprendizado unificado possível, tivemos que superar muitos obstáculos algorítmicos e técnicos. Em um sistema de aprendizado de máquina comum, um algoritmo de otimização, como o Stochastic Gradient Descent (SGD) usa um conjunto de dados grande dividido em partes iguais entre os servidores em nuvem. Esses algoritmos de alta capacidade de iteração precisam de conexões de baixa latência e alta taxa de transferência para os dados de treinamento. Mas, com o aprendizado unificado, os dados são distribuídos em milhões de dispositivos de uma maneira extremamente desigual. Além disso, esses dispositivos têm conexões de latência muito maior e menor taxa de transferência, além de estarem disponíveis para o treinamento de forma inconstante.
Essas limitações de largura de banda e latência dão força ao nosso algoritmo de média unificada, que pode treinar grandes redes usando de 10 a 100 vezes menos comunicação se comparado com uma versão simplesmente unificada do SGD. A ideia central é usar os poderosos processadores dos dispositivos móveis modernos para computar atualizações de maior qualidade em vez de etapas graduais simples. Como é preciso de algumas iterações de atualizações de alta qualidade para produzir um bom modelo, o treinamento pode usar muito menos comunicação. Já que a velocidade de upload normalmente é muito menor que a de download, desenvolvemos uma nova maneira de reduzir os custos da comunicação de upload mais 100 vezes comprimindo atualizações com rotações e quantização aleatórias. Embora essas abordagens se concentrem em grandes redes de treinamento, também projetamos algoritmos para modelos convexos esparsos de alta dimensão que são perfeitos para problemas como previsão de taxa de clique.
Implementar essa tecnologia em milhões de celulares diferentes que usam o Gboard exige uma base tecnológica sofisticada. O treinamento em dispositivos usa uma versão miniaturizada do TensorFlow. O agendamento cuidadoso garante que o treinamento aconteça somente quando o dispositivo está ocioso, conectado fisicamente e conectado a uma rede sem fio gratuita para que não haja impacto no seu desempenho.
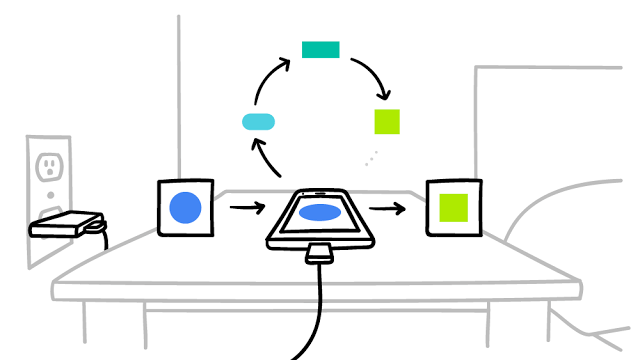
Depois disso, o sistema precisa se comunicar e agregar as atualizações do modelo de uma forma segura, eficiente, escalonável e tolerante a falhas. Somente a combinação de pesquisa e essa infraestrutura que tornam possíveis os benefícios do aprendizado unificado.
Esse aprendizado funciona sem precisar armazenar dados do usuário na nuvem, mas isso não é tudo. Estamos desenvolvendo um protocolo de agregação segura que usa técnicas de criptografia para que um servidor de coordenação só possa descriptografar a atualização média se centenas ou milhares de usuários tiverem participado — não é possível inspecionar nenhuma atualização de um celular antes de misturá-la às outras e determinar a média. Esse é o primeiro protocolo desse tipo que é prático para os problemas de redes extensas e as restrições de conectividade do mundo real. Desenvolvemos a Média unificada para que o servidor de coordenação só precise da atualização média, o que permite usar a agregação segura. Porém, o protocolo é geral e também pode ser aplicado a outros problemas. Estamos trabalhando pesado em uma implementação de produção desse protocolo e esperamos lançá-la para aplicativos de aprendizado unificado em breve.
Nosso trabalho é uma gota em um copo cheio (de possibilidades). O aprendizado unificado não consegue resolver todos os problemas do aprendizado de máquina (por exemplo, aprender a reconhecer raças diferentes de cachorro com treinamento em exemplos cuidadosamente identificados) e, para muitos outros modelos, os dados de treinamento necessários já estão na nuvem (como treinar filtros de mensagens indesejadas no Gmail). A Google vai continuar impulsionando a inovação no AM baseado em nuvem, mas sempre comprometida com a pesquisa contínua para ampliar os tipos e níveis de problemas que podem ser resolvidos com o aprendizado unificado. Além das sugestões de consulta do Gboard, por exemplo, esperamos melhorar os modelos de idioma que compõem o seu teclado com base no que você realmente digita no celular (que pode ter um estilo próprio) e classificações de foto baseadas em que tipo de foto as pessoas veem, compartilham e excluem.
Para aplicar o aprendizado unificado, os praticantes de aprendizado de máquina precisam adotar novas ferramentas e uma nova forma de pensar: desenvolvimento de modelos, treinamento e avaliação, sem nenhum acesso direto a dados brutos, nem identificação deles, considerando o custo de comunicação um fator limitante. Acreditamos que os benefícios do aprendizado unificado aos usuários ajudam a enfrentar os obstáculos técnicos, e nosso trabalho está sendo publicado com a esperança de uma conversa ampla na comunidade de aprendizado de máquina.
Menções
Esta postagem reflete o trabalho de muitos colaboradores do Google Research, são eles: Blaise Agüera y Arcas, Galen Andrew, Dave Bacon, Keith Bonawitz, Chris Brumme, Arlie Davis, Jac de Haan, Hubert Eichner, Wolfgang Grieskamp, Wei Huang, Vladimir Ivanov, Chloé Kiddon, Jakub Konečný, Nicholas Kong, Ben Kreuter, Alison Lentz, Stefano Mazzocchi, Sarvar Patel, Martin Pelikan, Aaron Segal, Karn Seth, Ananda Theertha Suresh, Iulia Turc, Felix Yu e os nossos parceiros da equipe do Gboard.
***
Artigo do Google Developers Brazil e foi escrito por Brendan McMahan e Daniel Ramage. Você pode acessar o original em: https://desenvolvedores.googleblog.com/2017/05/aprendizado-unificado-aprendizado-de.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?