

Na Uber, a previsão de eventos nos permite garantir que nossos serviços funcionarão no futuro, baseados na antecipação da demanda dos usuários. O objetivo é prever corretamente quando, onde e quantas solicitações de corridas o Uber vai receber em um período específico de tempo.
Eventos extremos – períodos de pico de corridas tais como feriados, shows, mau tempo, e eventos esportivos – somente aumentam a importância da projeção para o planejamento das operações.
Calcular a projeção da demanda em séries temporais durante eventos extremos é um componente crítico da detecção de anomalias, otimização da alocação dos recursos e do orçamento.
Embora a projeção de eventos extremos seja uma peça crucial para a operação da Uber, a escassez de dados torna a exatidão das projeções um desafio. Considere a véspera de ano novo, um dos dias mais ocupados para o Uber. Nós temos somente algumas informações sobre a véspera de ano novo, e cada instância pode ter um grupo diferente de usuários. Além dos dados históricos, a projeção de eventos extremos também depende de vários fatores externos, incluindo o clima, crescimento populacional e mudanças de mercado com os incentivos para os motoristas[1].
Uma combinação de modelos de séries temporais clássicos, tais como aqueles encontrados no pacote de projeções padrão R, e métodos de aprendizado de máquina geralmente são utilizados para projetar eventos especiais [2, 3]. Essas abordagens, no entanto, não são nem flexíveis nem escalonáveis suficientemente para a Uber.
Nesse artigo, nós apresentamos um modelo de projeções da Uber que combina dados históricos com fatores externos para prever mais precisamente eventos extremos, destacando sua nova arquitetura e como se compara ao nosso modelo anterior.
Criando o novo modelo de projeção de eventos extremos da Uber
Com o tempo, nós percebemos que para crescer em escala, precisávamos melhorar nosso modelo de projeção, para prever com maior precisão os eventos extremos no mercado do Uber.
Nós finalmente decidimos conduzir a modelagem de séries temporais baseado na arquitetura de Memória de Curto e Longo Prazo (MCLP), uma técnica que inclui modelagem de ponta a ponta, facilidade para incorporar variáveis externas e habilidades de extração automática de atributos [4].Fornecendo uma grande quantidade de dados nas numerosas dimensões, essa abordagem pode apresentar interações não lineares complexas.
Após escolher nossa arquitetura, avaliamos a quantidade de dados necessária para treinar nosso modelo, demonstrado abaixo:
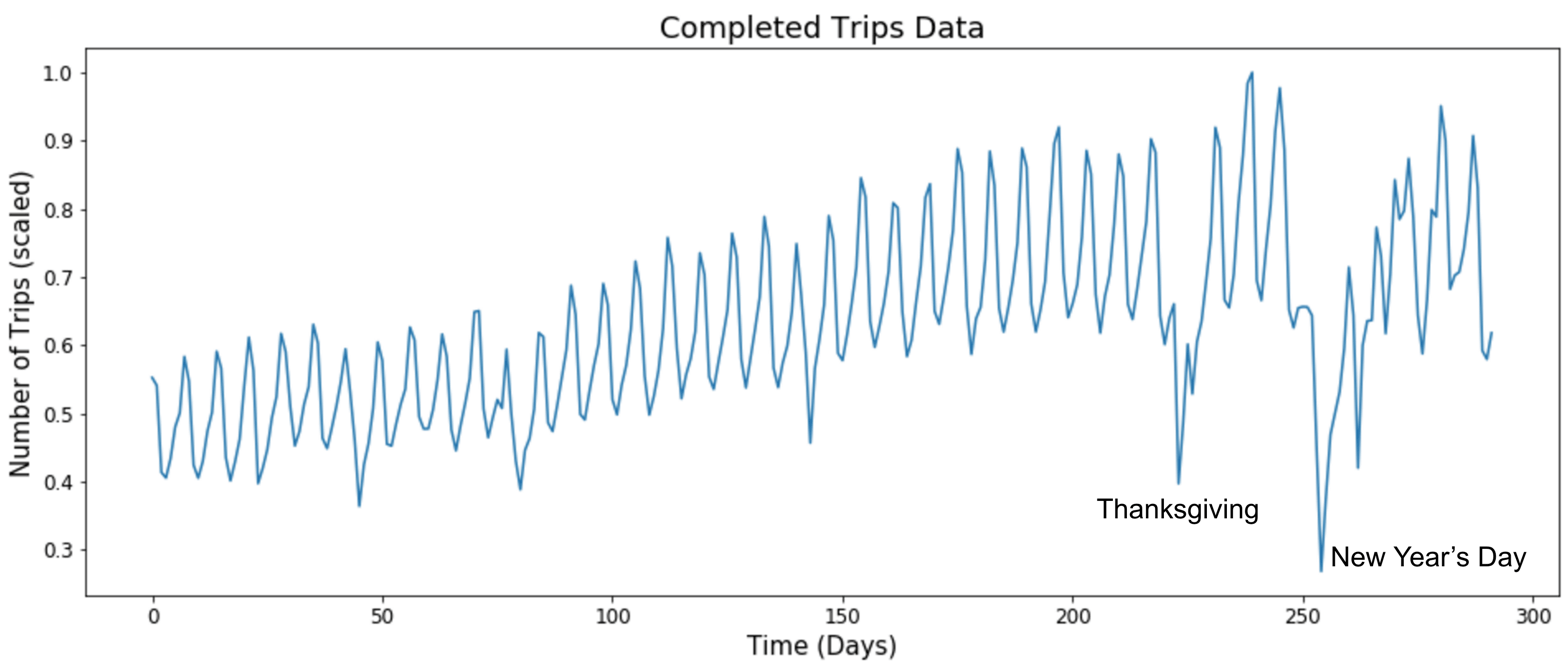
Projetar eventos extremos pode ser difícil devido à sua frequência. Para superar essa deficiência de dados, decidimos treinar uma única e flexível rede neural para apresentar os dados de muitas cidades de uma vez, o que aumentou bastante nossa precisão.
Construindo uma nova arquitetura com redes neurais
Nosso objetivo era desenvolver um modelo genérico de projeção de séries temporais, de ponta a ponta, que fosse escalável, preciso, e aplicável à series temporais heterogêneas. Para alcançar isso, usamos milhares de séries temporais para treinar uma rede neural multi-modular.
Nós medimos e rastreamos dados externos brutos para construir essa rede neural, demonstrados abaixo:
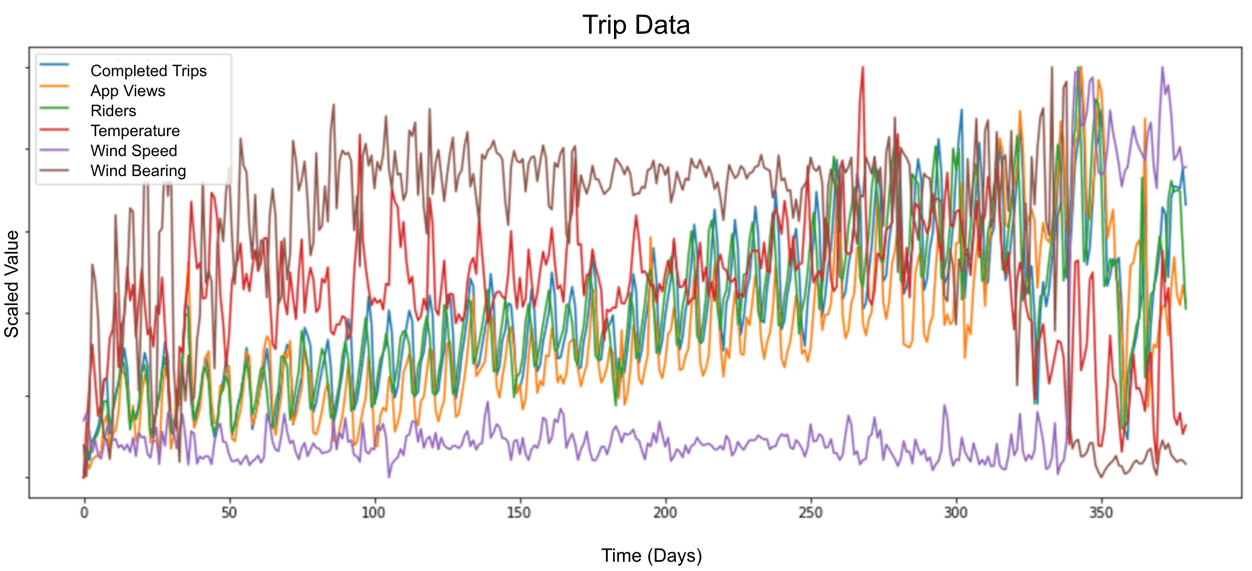
Esses dados brutos foram utilizados em nosso modelo de treinamento para realizar um pré-processamento simples, incluindo registrar as transformações, escalar e retirar aspectos que possam causar distorção.
Treinando com janelas deslizantes
O conjunto de dados de treinamento de nossa rede neural exigia janelas deslizantes X (entradas) e Y (saídas) para os dados desejados (ex.: tamanho das entradas), assim como um horizonte de projeção. Utilizando essas duas janelas, nós treinamos uma rede neural minimizando a função de perda, como Erro Quadrado Médio.
Ambas as janelas X e Y deslizam utilizando um incremento simples para gerar dados para o treinamento, conforme demonstrado abaixo:
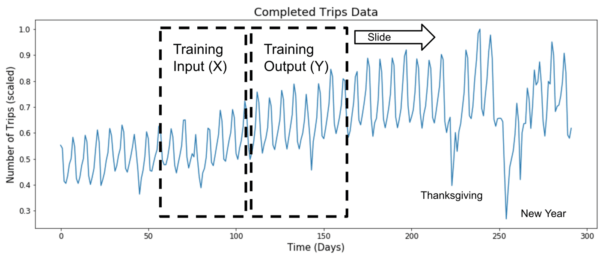
Em seguida, nós explicamos como utilizamos nossos dados de treinamento para projetar o modelo de memória de longo e curto prazo.
Adaptando nosso modelo de memória de curto e longo prazo
Durante os testes, nós determinamos que uma implementação sem personalizações do modelo de memória de longo e curto prazo não apresentava uma performance superior comparada com o modelo padrão, que incluía uma combinação de projeções invariáveis e elementos de aprendizagem de máquina. O modelo sem personalizações não poderia se adaptar a séries temporais com domínios com os quais ele não tinha sido treinado, o que levou a uma baixa performance quando utilizava uma única rede neural.
Não é prático treinar um modelo por série temporal para milhões de métricas; simplesmente não existem recursos suficientes disponíveis, sem contar horas no dia. Além disso, treinar um único modelo de memória de curto e longo prazo não produz resultados competitivos porque o modelo não consegue distinguir entre séries temporais diferentes. Mesmo que as séries temporais possam ser adicionadas manualmente, essa abordagem é entediante e sujeita a erros.
Para melhorar a precisão, nós incorporamos um modulo de extração automática de atributos em nosso modelo, descrito abaixo:
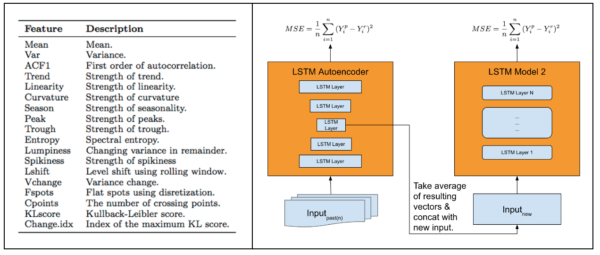
Durante os testes, nós pudemos atingir uma melhora de 14,09% na porcentagem absoluta de erro médio (EM) em relação à arquitetura MCLP e uma melhora de mais de 25% em relação ao modelo de série temporal clássico utilizado pelo Argos, ferramenta de monitoria em tempo real e análise exploratória de causa raiz.
Com nossa arquitetura desenvolvida com sucesso, personalizada e testada, era hora de utilizar nosso modelo em produção.
Utilizando o novo modelo de projeções
Assim que os pesos da rede neural estiverem calculados, eles podem ser exportados e implementados em qualquer linguagem de programação. Nosso fluxo atual primeiro treina offline a rede utilizando o Tensorflow e o Keras e então exporta os pesos para código nativo Go, como demonstrado abaixo.
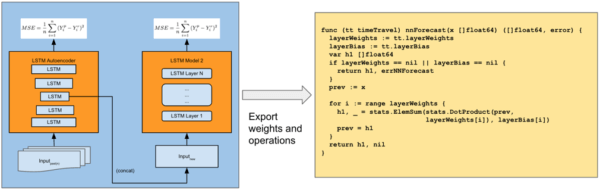
Para esse artigo, nós construímos um modelo utilizando o histórico diário completo de 5 anos de viagens completadas com o Uber nos Estados Unidos nos períodos de 7 dias antes, durante e depois de grandes feriados, como o Natal e o Ano Novo.
Nós fornecemos a média de EM para o exemplo acima, utilizando nosso modelo antigo e o novo:
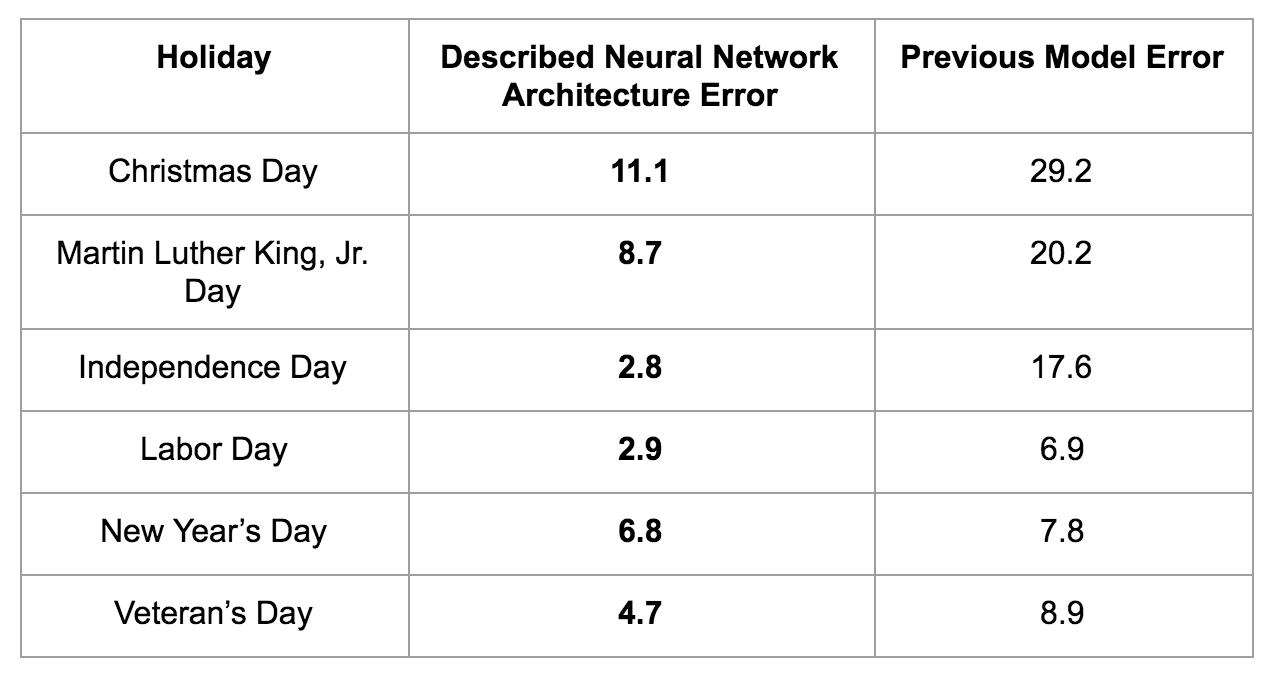
A propósito, nosso novo modelo descobriu que um dos feriados mais difíceis de fazer uma projeção é o Natal, que corresponde ao maior erro e incerteza na demanda por motoristas.
Nós apresentamos um gráfico de viagens projetadas e realizadas em um período de 200 dias em uma cidade, abaixo:
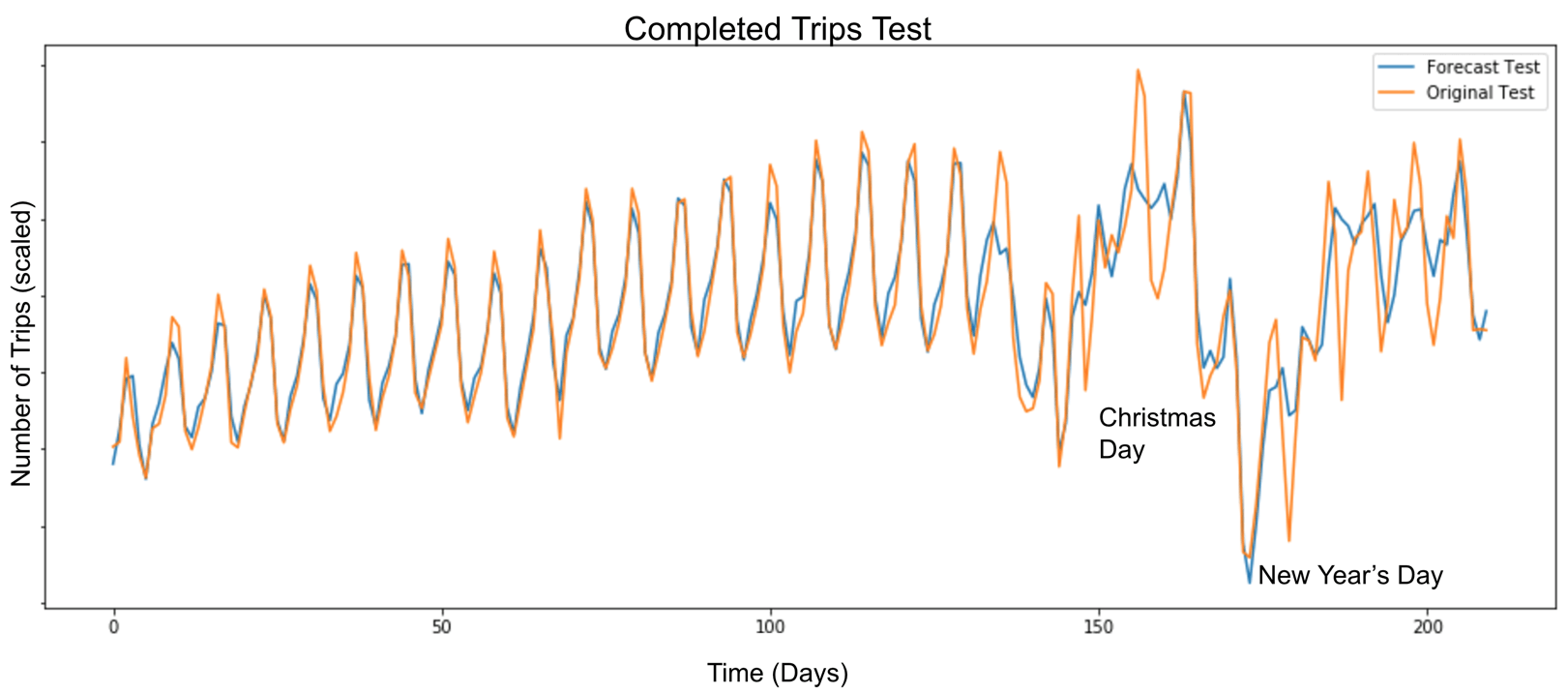
O resultado do nosso teste sugere um aumento da precisão entre 2 e 18% comparado com nosso modelo próprio.
Enquanto as redes neurais são benéficas para a Uber, esse método não é uma solução mágica. De nossa experiência, nós definimos três dimensões para decidir se o modelo de rede neural funciona para nossa necessidade: (a) número de séries temporais; (b) tamanho das séries temporais; (c) correlação entre as séries. Todas as três dimensões aumentam a possibilidade de a abordagem de rede neural terá projeções mais precisas em relação ao modelo de séries temporais clássicos.
Projeções no futuro
Pretendemos continuar trabalhando com redes neurais criando um modelo heterogêneo de projeções de séries temporais, ou como um modelo único de ponta a ponta ou como um bloco em um sistema de projeções automáticas maior.
Agradecimentos: Li Erran Li é um engenheiro de deep learning no Grupo de Tecnologias Avançadas da Uber. Jason Yosinski é um cientista pesquisados no Laboratório de Inteligencia Artificial da Uber
Notas:
- Horne, John D. and Manzenreiter, Wolfram. Accounting for mega-events. International Review for the Sociology of Sport, 39(2):187–203, 2004.
- Hyndman, Rob J and Khandakar, Yeasmin. Automatic time series forecasting: the forecast package for R. Journal of Statistical Software, 26(3):1–22, 2008
- Meinshausen, Nicolai. Quantile regression forests. Journal of Machine Learning Research, 7:983– 999, 2006
- Assaad, Mohammad, Bone, Romuald, and Cardot, Hubert. A new boosting algorithm for improved time-series forecasting with recurrent neural networks. Inf. Fusion, 9: 41-55, 2006
- Ogunmolu, Olalekan P., Gu, Xuejun, Jiang, Steve B., and Gans, Nicholas R. Nonlinear systems identification using deep dynamic neural networks. CoRR, 2016
- Rob J. Hyndman, Earo Wang, Nikolay Laptev: Large-Scale Unusual Time Series Detection. ICDM Workshops 2015
***
Este artigo é do Uber Engineering. Ele foi escrito por Nikolay Laptev, Santhosh Shanmugam e Slawek Smyl. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/neural-networks/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?