

Há três anos, a Uber Engineering adotou o Hadoop como a infraestrutura de armazenamento (HDFS) e computação (YARN) para a análise de Big Data da nossa organização. Essa análise capacita nossos serviços e permite a entrega de experiências de usuário mais fáceis e confiáveis.
Usamos o Hadoop para análises em lote e streaming em uma ampla gama de casos de uso, como detecção de fraude, machine learning e cálculo de ETA. Como os negócios da Uber cresceram nos últimos anos, nosso volume de dados e as cargas de acesso associadas aumentaram exponencialmente; somente em 2017, a quantidade de dados armazenados no HDFS cresceu mais de 400%.
Escalar nossa infraestrutura mantendo alto desempenho não foi tarefa fácil. Para conseguir isso, a equipe de Infraestrutura de Dados da Uber revisou maciçamente nossa abordagem para escalar nosso HDFS implementando vários novos ajustes e recursos, incluindo View File System (ViewFs), upgrades de versão frequente do HDFS, ajuste de coleta de lixo NameNode, limitando o número de arquivos pequenos que filtram através do sistema, um serviço de gerenciamento de carga HDFS e uma réplica NameNode somente de leitura. Continue lendo para saber como a Uber implementou essas melhorias para facilitar o crescimento, a estabilidade e a confiabilidade contínuos de nosso sistema de armazenamento.
Desafios scaling
O HDFS foi projetado como um sistema de arquivos distribuído escalável para suportar milhares de nós em um único cluster. Com hardware suficiente, o escalonamento para mais de 100 petabytes de capacidade bruta de armazenamento em um cluster pode ser facilmente – e rapidamente – alcançado.
Para a Uber, no entanto, o rápido crescimento de nossos negócios dificultou a escalabilidade de forma confiável sem desacelerar a análise de dados para nossos milhares de usuários que fazem milhões de consultas via Hive ou Presto a cada semana.
Atualmente, o Presto é responsável por mais da metade do acesso ao HDFS, e 90% das consultas via Presto levam aproximadamente 100 segundos para serem processadas. Se a nossa infraestrutura HDFS estiver sobrecarregada, as consultas do Presto na pilha se acumulam, resultando em atrasos na conclusão da consulta. Além disso, precisamos que os dados estejam disponíveis no HDFS o mais rápido possível.
Para nossa infraestrutura de armazenamento original, projetamos a extração, transformação e carregamento (ETL) para ocorrer nos mesmos clusters onde os usuários executam consultas para reduzir a latência de replicação. Os deveres duplos desses clusters resultam na geração de arquivos pequenos para acomodar gravações e atualizações frequentes, o que obstrui ainda mais a fila.
Além desses desafios, várias equipes exigem uma grande porcentagem de dados armazenados, impossibilitando a divisão de clusters por caso de uso ou organização sem duplicações, diminuindo a eficiência e aumentando os custos.
A raiz dessas lentidões – o principal gargalo de nossa capacidade de dimensionar nosso HDFS sem comprometer a UX – foram o desempenho e a taxa de transferência do NameNode, a árvore de diretórios de todos os arquivos no sistema que rastreia onde os arquivos de dados são mantidos. Como todos os metadados são armazenados no NameNode, as solicitações do cliente para um cluster HDFS devem primeiro passar por ele.
Para complicar ainda mais isso, um único ReadWriteLock no namespace NameNode limita a taxa de transferência máxima que o NameNode pode suportar, porque qualquer solicitação de gravação manterá exclusivamente o bloqueio de gravação e forçará qualquer outro pedido a aguardar na fila.
No final de 2016, começamos a ter um alto tempo de fila de chamada de procedimento remoto (RPC) de NameNode como resultado dessa combinação. Às vezes, o tempo de fila do NameNode podia exceder 500 milissegundos por solicitação (com o menor tempo de fila atingindo quase um segundo), o que significa que cada solicitação do HDFS aguardava pelo menos meio segundo na fila – uma desaceleração brusca comparada ao tempo normal do processo de menos de 10 milissegundos.
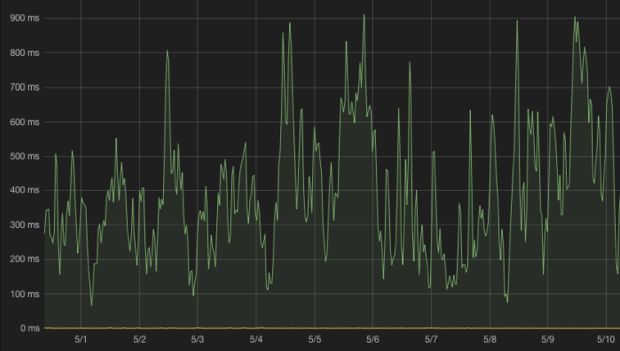
Ativando o escalonamento e melhorando o desempenho
Garantir o alto desempenho de nossas operações de HDFS, continuando a escalar, nos levou a desenvolver várias soluções em paralelo para evitar interrupções a curto prazo. Ao mesmo tempo, essas soluções nos permitem construir um sistema mais confiável e extensível capaz de suportar o crescimento futuro em longo prazo.
Abaixo, descrevemos algumas das melhorias que nos permitiram expandir a infraestrutura do HDFS em mais de 400% e, ao mesmo tempo, melhorar o desempenho geral do sistema:
Escalando com ViewFs
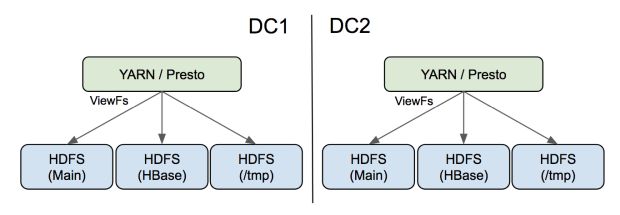
Inspirados por um esforço semelhante no Twitter, utilizamos o View File System (ViewFs) para dividir nosso HDFS em vários namespaces físicos e usamos os pontos de montagem do ViewFs para apresentar um único namespace virtual aos usuários.
Para conseguir isso, separamos nosso HBase do mesmo cluster HDFS de nossas operações YARN e Presto. Esse ajuste não apenas reduziu muito a carga no cluster principal, mas também tornou o HBase muito mais estável, reduzindo o reinício do cluster HBase de horas para minutos.
Também criamos um cluster HDFS dedicado para logs de aplicação YARN agregados. O YARN-3269 é necessário para fazer com que a agregação de logs suporte ViewFs. Nosso diretório scratch do Hive também foi movido para esse cluster. Os resultados dessa funcionalidade adicional foram muito satisfatórios; atualmente, o novo cluster atende a cerca de 40% do total de solicitações de gravação, e a maioria dos arquivos é pequena, e eles também aliviam a pressão de contagem de arquivos no cluster principal. Como não foram necessárias alterações no lado do cliente para aplicativos de usuários existentes, essa transição foi muito suave.
E, finalmente, implementamos clusters HDFS separados por trás do ViewFs em vez da Federação HDFS da infraestrutura. Com essa configuração, as atualizações do HDFS podem ser gradualmente implementadas para minimizar o risco de interrupções em larga escala; além disso, o isolamento completo ajuda a melhorar a confiabilidade do sistema. Uma desvantagem dessa correção, no entanto, é que a manutenção de clusters HDFS separados leva a custos operacionais ligeiramente mais altos.
Atualizações do HDFS
Uma segunda solução para nossos desafios de escalonamento foi atualizar nosso HDFS para acompanhar as versões mais recentes. Instalamos dois upgrades importantes em um ano, primeiro do CDH 5.7.2 (HDFS 2.6.0 com muitos patches) para o Apache 2.7.3 e depois para 2.8.2. Para executar isso, também tivemos que reconstruir nosso framework de implementação sobre o Puppet e o Jenkins para substituir as ferramentas de gerenciamento de cluster de terceiros.
Os upgrades nos trouxeram melhorias críticas de escalabilidade, incluindo HDFS-9710, HDFS-9198 e HDFS-9412. Por exemplo, após a atualização para o Apache 2.7.3, a quantidade de relatórios de bloqueio incremental diminuiu, levando a uma redução na carga do NameNode.
A atualização do HDFS pode ser arriscada, pois pode causar tempo de inatividade, degradação do desempenho ou perda de dados. Para combater esses possíveis problemas, passamos vários meses validando o 2.8.2 antes de implementá-lo na produção. No entanto, ainda havia um bug (HDFS-12800) que nos pegou de surpresa enquanto estávamos atualizando nosso maior cluster de produção. Embora tenhamos percebido isso tarde, ter clusters isolados, um processo de atualização em etapas e planos de reversão de contingência nos ajudaram a mitigar seus efeitos.
A capacidade de rodar diferentes versões do YARN e do HDFS nos mesmos servidores ao mesmo tempo também se mostrou muito crítica para nossos esforços de escalonamento. Como o YARN e o HDFS fazem parte do Hadoop, eles normalmente são atualizados juntos. No entanto, as principais atualizações do YARN demoram muito mais para serem totalmente validadas e implementadas, pois algumas aplicações de produção em execução no YARN podem precisar ser atualizadas devido a alterações na API do YARN ou conflitos de dependência JAR entre o YARN e essas aplicações.
Embora a escalabilidade do YARN não tenha sido um problema em nosso ambiente, não queremos que as atualizações críticas do HDFS sejam bloqueadas pelas atualizações do YARN. Para evitar possíveis bloqueios, atualmente executamos uma versão anterior do YARN em vez do HDFS, o que funciona bem para nosso caso de uso (entretanto, essa estratégia pode não funcionar quando adotamos recursos como o Erasure Coding por causa das alterações necessárias no lado do cliente).
Ajuste da coleta de lixo do NameNode
O ajuste da coleta de lixo (garbage collection – GC, em inglês) também desempenhou um papel importante em nossa otimização e nos proporcionou um espaço respiratório muito necessário à medida que continuamos a expandir nossa infraestrutura de armazenamento.
Evitamos longas pausas de GC, forçando os coletores Concurrent Mark Sweep (CMS) a fazerem coleções de geração antigas mais agressivas, ajustando parâmetros do CMS, como CMSInitiatingOccupancyFraction, UseCMSInitiatingOccupancyOnly e CMSParallelRemarkEnabled. Embora isso aumente a utilização da CPU, temos a sorte de ter ciclos de CPU suficientes para suportar essa funcionalidade.
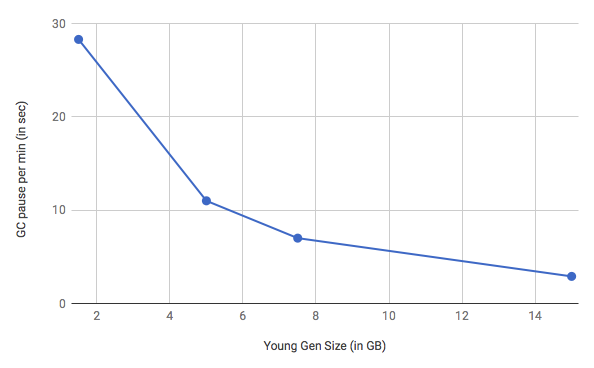
Durante carregamentos pesados de Remote Procedure Call (RPC), um grande número de objetos de vida curta é criado na geração mais jovem, o que força o coletor de geração jovem a executar a coleta de parada do mundo com frequência. Aumentando o tamanho da geração jovem de 1,5 GB para 16 GB e ajustando o valor de ParGCCardsPerStrideChunk (definido em 32.768), o tempo total que a produção NameNode gastou na pausa da GC diminuiu de 13% para 1,7%, aumentando a taxa em mais de 10%. Resultados de benchmark (Figura 3) mostram melhorias adicionais em cenários apenas de leitura.
Para referência, nossos argumentos Java Virtual Machine (JVM) relacionados a GC customizada para o NameNode com tamanho de heap de 160 GB são:
- XX:+UnlockDiagnosticVMOptions
- XX:ParGCCardsPerStrideChunk=32768 -XX:+UseParNewGC
- XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled
- XX:CMSInitiatingOccupancyFraction=40
- XX:+UseCMSInitiatingOccupancyOnly
- XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark
- XX:+DisableExplicitGC
Também estamos no processo de avaliar se devemos ou não integrar o Garbage-First Garbage Collector (G1GC) ao nosso sistema. Embora não tenhamos visto vantagens no uso de G1GC no passado, novas versões da JVM trazem melhorias adicionais no desempenho do coletor de lixo, portanto, revisitar a escolha de nosso coletor e configuração é ocasionalmente necessário.
Controlando o número de arquivos pequenos
Como o NameNode carrega todos os metadados do arquivo na memória, o armazenamento de arquivos pequenos aumenta a pressão da memória no NameNode. Além disso, arquivos pequenos levam a um aumento de chamadas RPC de leitura para acessar a mesma quantidade de dados quando os clientes estão lendo os arquivos, bem como um aumento nas chamadas RPC quando os arquivos são gerados. Para reduzir o número de arquivos pequenos em nosso armazenamento, utilizamos duas abordagens principais.
Primeiro, nossa equipe do Hadoop Data Platform construiu novos pipelines de processamento baseados em nossa biblioteca Hoodie, que gera arquivos muito maiores do que aqueles criados por nossos pipelines de dados originais. Como uma solução provisória antes que eles estivessem disponíveis, no entanto, também criamos uma ferramenta (referida internamente como um “costureiro”) que mescla pequenos arquivos com arquivos maiores, a maioria com mais de 1 GB.
Segundo, definimos uma cota estrita de namespace nos bancos de dados e diretórios de aplicação no Hive. Para reforçar isso, criamos uma ferramenta de autoatendimento para os usuários gerenciarem cotas dentro de suas organizações. A cota é alocada na proporção de 256 MB por arquivo para incentivar os usuários a otimizarem o tamanho do arquivo de saída.
As equipes do Hadoop também fornecem guias de otimização e ferramentas de mesclagem de arquivos para ajudar os usuários a adotarem essas práticas recomendadas. Por exemplo, ativar a mesclagem automática no Hive e ajustar o número de redutores pode reduzir bastante o número de arquivos gerados pelas consultas de inserção/sobregravação do Hive.
Serviço de gerenciamento de carga HDFS
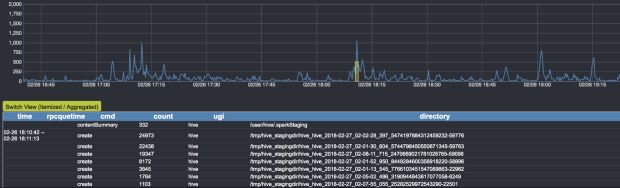
Um dos maiores desafios de executar uma infraestrutura grande de vários usuários, como o HDFS, é detectar quais aplicações estão causando cargas muito grandes e, a partir daí, tomar medidas rápidas para corrigi-las. Construímos um serviço interno de gerenciamento de carga HDFS, conhecido como Spotlight, para essa finalidade.
Em nossa implementação atual do Spotlight, um log de auditoria é transmitido do NameNode ativo e processado em tempo real por meio de um backend baseado no Flink e no Kafka. A saída da análise é mostrada em um painel e usada para desativar automaticamente as contas ou interromper os fluxos de trabalho que estão causando a lentidão do HDFS.
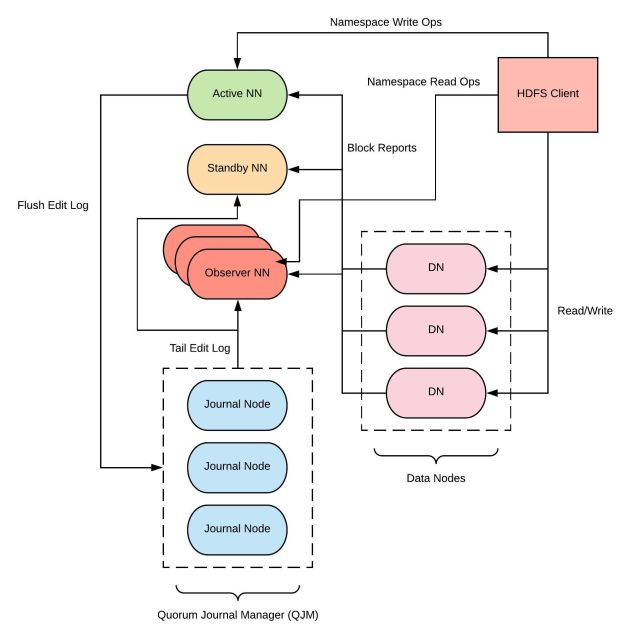
Observer NameNode
Estamos trabalhando no desenvolvimento do Observer NameNode (HDFS-12975), um novo recurso HDFS projetado como uma réplica NameNode apenas de leitura com o objetivo de reduzir a carga no cluster NameNode ativo. Como mais da metade do volume e do crescimento de RPC do HDFS vem de consultas Presto apenas de leitura, esperamos que o Observer NameNodes nos ajude a escalar a taxa de transferência geral do NameNode em quase 100% na primeira versão. Nós terminamos a validação dessa ferramenta e estamos no processo de colocá-la em produção.
Principais tópicos
Conforme escalamos nossa infraestrutura HDFS, selecionamos algumas práticas recomendadas que podem ser valiosas para outras organizações que enfrentam problemas semelhantes, descritas abaixo:
- Camada de suas soluções: implementar grandes melhorias de escalabilidade, como o Observer NameNode ou dividir o HDFS em mais clusters, exige um esforço significativo. Medidas de curto prazo, como o ajuste do GC e a fusão de arquivos menores em arquivos maiores por meio do nosso costureiro, nos deram muito espaço para desenvolver soluções de longo prazo.
- Maior é melhor: como arquivos pequenos são uma ameaça ao HDFS, é melhor lidar com eles mais cedo do que tarde. Fornecer ferramentas, documentos e treinamento aos usuários são abordagens muito eficazes para ajudar a aplicar as melhores práticas essenciais à execução de uma infraestrutura HDFS com vários inquilinos.
- Participe da comunidade: o Hadoop existe há mais de 10 anos e sua comunidade está mais ativa do que nunca, levando a melhorias de escalabilidade e funcionalidade introduzidas em praticamente todos os lançamentos. Participar da comunidade do Hadoop contribuindo com suas próprias descobertas e ferramentas é muito importante para o escalonamento contínuo de sua infraestrutura.
Seguindo em frente
Embora tenhamos feito grandes progressos nos últimos dois anos, sempre há mais a ser feito para melhorar ainda mais a nossa infraestrutura HDFS.
Por exemplo, em um futuro próximo, planejamos integrar vários novos serviços em nosso sistema de armazenamento, como mostrado na Figura 6. Essas adições nos permitirão expandir ainda mais nossa infraestrutura e tornar o ecossistema de armazenamento do Uber mais eficiente e fácil de usar.
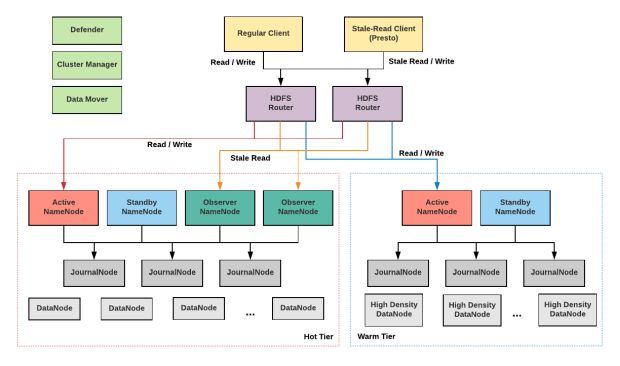
Abaixo, destacamos o que está reservado para dois de nossos principais projetos, uma federação HFDS baseada em roteador e armazenamento em camadas:
Federação HFDS baseada em roteador
Atualmente, utilizamos ViewFs para escalar o HDFS quando os subclusters ficam sobrecarregados. O principal problema com essa abordagem é que as alterações na configuração do cliente são necessárias toda vez que adicionamos ou substituímos um novo ponto de montagem no ViewFs, e é muito difícil distribuir esses ajustes sem afetar os fluxos de trabalho de produção. Essa situação é um dos principais motivos pelos quais atualmente apenas dividimos os dados que não exigem alterações do lado do cliente em larga escala, por exemplo, agregação de log do YARN.
A nova iniciativa da Microsoft e a implementação da Federação baseada em roteador (HDFS-10467, HDFS-12615), atualmente incluída na versão 2.9 do HDFS, é uma extensão natural de uma federação particionada baseada em ViewFs. Essa federação adiciona uma camada de software capaz de centralizar os namespaces do HDFS. Ao oferecer a mesma interface (uma combinação de RPC e WebHDFS), sua camada extra oferece aos usuários acesso transparente a qualquer subcluster e permite que os subclusters gerenciem seus dados de forma independente.
Ao fornecer uma ferramenta de rebalanceamento, a camada de federação também suportaria a movimentação transparente de dados entre os subclusters para balanceamento de cargas de trabalho e implementação de armazenamento hierárquico. A camada de federação mantém o estado do namespace global em um armazenamento de estado centralizado e permite que vários roteadores ativos sejam ativados enquanto direcionam solicitações de usuários para os subclusters corretos.
Estamos trabalhando ativamente para levar a Federação HDFS baseada em roteador à produção na Uber, enquanto colaboramos de perto com a comunidade do Hadoop em outras melhorias open source, incluindo o suporte ao WebHDFS.
Armazenamento em camadas
À medida que a escala da nossa infraestrutura aumenta, também aumenta a importância de reduzir os custos de armazenamento. Pesquisas conduzidas entre nossas equipes técnicas mostram que os usuários acessam dados recentes (dados “quentes”) com mais frequência do que dados antigos (dados “mornos”). Mover dados antigos para um nível separado, que consome menos recursos, reduzirá significativamente nossos custos de armazenamento.
Erasure Coding HDFS, federação baseada em roteador, hardware de alta densidade (mais de 250 TB) e um serviço movimentador de dados (para manipular dados em movimento entre clusters de camada “quentes” e clusters de camada “mornas”) são componentes-chave do nosso próximo projeto de armazenamento hierárquico. Planejamos compartilhar nossa experiência em nossa implementação de armazenamento em camadas em um artigo futuro.
Se você estiver interessado em escalar sistemas distribuídos em grande escala, considere a possibilidade de se candidatar a um cargo em nossa equipe!
***
Este artigo é do Uber Engineering. Ele foi escrito por Ang Zhang e Wei Yan. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/scaling-hdfs/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?