

O Cassandra é um banco de dados NoSQL que pertence à categoria de banco de dados da família da coluna NoSQL. Ele é um projeto Apache e possui uma versão Enterprise mantida pelo DataStax. O Cassandra é escrito em Java e é usado principalmente para dados de séries temporais, como métricas, IoT (Internet of Things), logs, mensagens de bate-papo, e assim por diante. Ele é capaz de lidar com uma enorme quantidade de gravações e lê e escala para milhares de nós. Vamos listar aqui algumas características importantes do Cassandra. Basicamente, o Cassandra …
- mistura ideias do Big Table do Google e do Dynamo da Amazon.
- é baseado em arquitetura peer-to-peer. Cada nó é igual (pode executar leituras e gravações), portanto, não há nó mestre ou escravo, ou seja, não há um único ponto mestre de falha.
- faz partição e replicação automáticas.
- tem gravação sintonizável e consistência de leitura para operações de leitura e gravação.
- é capaz de escalar horizontalmente mantendo a escalabilidade linear para leitura e gravação.
- lida com a comunicação inter-nó através do protocolo Gossip.
- lida com a comunicação do cliente através do CQL (Cassandra Query Language), que é muito semelhante ao SQL.
Coordenador
Quando uma solicitação é enviada para qualquer nó Cassandra, esse nó age como um proxy entre a aplicação (na verdade, o driver Cassandra) e os nós envolvidos no fluxo de solicitação. Esse nó proxy é chamado de coordenador. Ele é responsável por gerenciar todo o caminho da solicitação e responder de volta para o cliente.
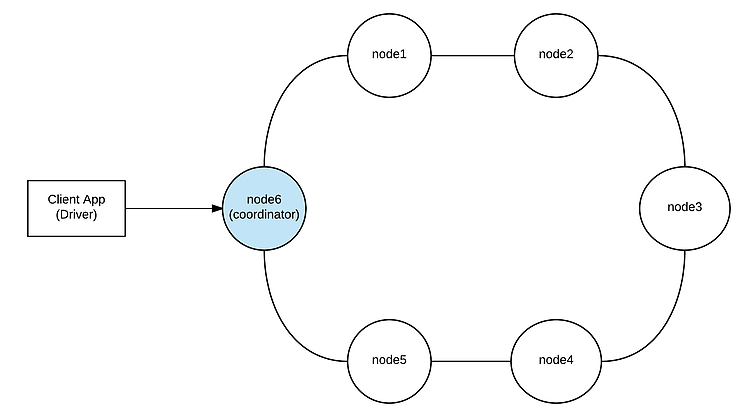
Figura 1 – Coordenador
Além disso, às vezes, quando o coordenador encaminha uma solicitação de gravação para os nós de réplica, eles podem estar indisponíveis naquele exato momento. Nesse caso, o coordenador desempenha um papel importante, implementando um mecanismo chamado Hinted Handoff, que será descrito em detalhes mais tarde.
Particionador
Basicamente, para cada nó no cluster Cassandra (anel Cassandra), é atribuída uma gama de tokens como mostrado na figura 2 para um cluster de 6 nós (com tokens imaginários, é claro).
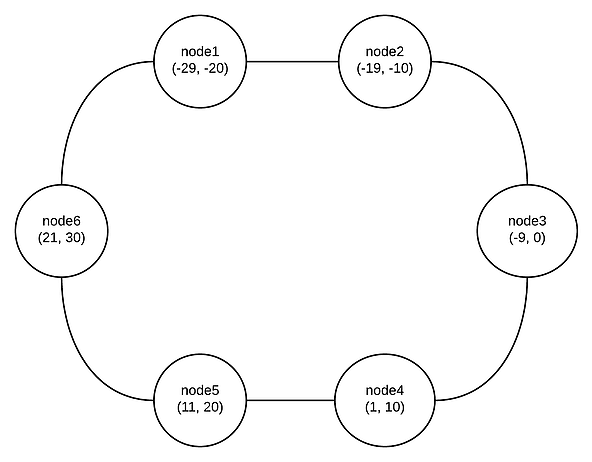
Figura 2 – Token Ranges
O Cassandra distribui dados no cluster usando um algoritmo consistente de Hashing e, a partir da versão 1.2, implementa também o conceito de nós virtuais (vnodes), em que cada nó possui uma grande quantidade de pequenos intervalos de token para melhorar a reorganização de token e evitar hotspots no cluster, isto é, alguns nós armazenando muito mais dados do que outros. Os nós virtuais também permitem adicionar e remover nós no cluster com mais facilidade e gerenciam automaticamente a atribuição de token para você, para que você possa desfrutar de um bom café ao adicionar ou remover um nó em vez de calcular e atribuir novos intervalos de token para cada nó (o que, por sinal, é uma operação muito propensa a erros).
Bem, dito isso, o particionador é o componente responsável por determinar como distribuir os dados através dos nós no cluster, dada a chave de partição de uma linha. Basicamente, é uma função hash para computar um token com a chave de partição.
Quando o particionador aplica a função hash à chave de partição e obtém o token, ele sabe exatamente qual nó irá lidar com a solicitação.
Consideremos um exemplo simples: suponha que uma solicitação seja emitida para node6 (ou seja, node6 é o coordenador para essa solicitação) com uma linha contendo a chave de partição “jorge_acetozi”. Suponha que o particionador aplique a função hash à chave de partição “jorge_acetozi” e obtenha o token -17. Como mostra a figura 3, os intervalos do token node2 incluem -17, então esse nó será aquele que lida com a solicitação.
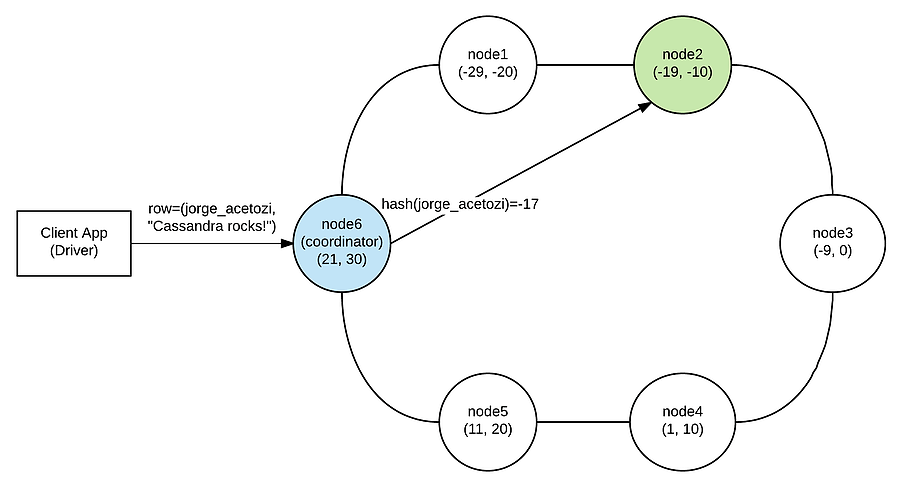
Figura 3: Particionador
O Cassandra oferece três tipos de particionadores: Murmur3Partitioner (que é o padrão), RandomPartitioner e ByteOrderedPartitioner.
Replicação
A vida seria muito mais fácil se…
- Nós nunca falhassem;
- Redes não tivessem latência;
- Pessoas não tropeçassem em cabos;
- A Amazon não tivesse reiniciado suas instâncias;
- Full GC significasse “Full Guitar Concert”.
E assim por diante. Infelizmente, essas coisas acontecem o tempo todo, e você já escolheu uma carreira de engenheiro de software (sua mãe costumava aconselhá-lo a estudar muito e se tornar um médico, mas você escolheu continuar jogando Counter-Strike em vez disso. Agora, você é um engenheiro de software, sabe o que significa AK-47 e tem que se preocupar com coisas assim).
Felizmente, o Cassandra oferece replicação automática de dados e mantém seus dados redundantes em diferentes nós no cluster. Isso significa que (em certos níveis) você pode até resistir a cenários de falha de nó, e seus dados ainda estarão seguros e disponíveis. Mas tudo tem um preço, e o preço de replicação é a consistência.
Estratégia de replicação
Basicamente, o coordenador usa a estratégia de replicação para descobrir quais nós serão os nós de réplica para uma determinada solicitação.
Há duas estratégias de replicação disponíveis:
SimpleStrategy: usada para a implementação um único de data center (não recomendada para ambientes de produção). Ela não considera a topologia da rede. Basicamente, apenas toma a decisão do particionador (ou seja, o nó que lida com a solicitação primeiro, com base no intervalo de token) e coloca as réplicas restantes no sentido horário em relação a esse nó. Por exemplo, na figura 3, se o fator de replicação da tabela fosse 3, quais nós teriam sido escolhidos pelo SimpleStrategy para atuar como réplicas (além do node2, que já havia sido escolhido pelo particionador)? Isso, node3 e node4! E se o fator de replicação fosse 4? Bem, então o node5 também seria incluído.
NetworkTopologyStrategy: usada para a implementação de múltiplos data centers (recomendada para ambientes de produção). Ela também toma a decisão do particionador e coloca as réplicas restantes no sentido horário, mas também leva em consideração a configuração do rack e dos data centers.
Fator de replicação
Quando você cria uma tabela (Column Family) no Cassandra, você especifica o fator de replicação. O fator de replicação é o número de réplicas que o Cassandra irá armazenar para essa tabela em nós diferentes. Se você especificar REPLICATION_FACTOR=3, seus dados serão replicados para 3 nós diferentes em todo o cluster. Isso fornece tolerância a falhas e resiliência, porque, mesmo que alguns nós falhem, seus dados ainda estarão seguros e disponíveis.
Nível de consistência de gravação
Você ainda lembra que, quando o cliente envia uma solicitação para um nó Cassandra, esse nó é chamado de coordenador e atua como um proxy entre o cliente e os nós de réplica?
Bem, quando você escreve uma tabela no Cassandra (inserindo dados, por exemplo), você pode especificar o nível de consistência de gravação. Trata-se do número de nós de réplica que devem reconhecer o coordenador que a inserção local foi bem sucedida (o sucesso aqui significa que os dados foram anexados ao log de commit e escritos no memtable). Assim que o coordenador obtiver confirmações de sucesso WRITE_CONSISTENCY_LEVEL dos nós de réplica, ele retorna com sucesso para o cliente e não espera que as réplicas restantes reconheçam o sucesso.
Por exemplo, se um aplicativo emitir uma solicitação de inserção com WRITE_CONSISTENCY_LEVEL =TWO para uma tabela configurada com REPLICATION_FACTOR=3, o coordenador somente retornará sucesso para a aplicação quando duas das três réplicas reconhecerem o sucesso. Claro, isso não significa que a terceira réplica também não vai gravar os dados; ela vai, mas, neste momento, o coordenador já teria enviado o sucesso de volta para cliente.
Existem muitos tipos diferentes de níveis de consistência de gravação que você pode especificar em sua solicitação de gravação. Do menos consistente para a consistência total: ANY, ONE, TWO, THREE, QUORUM, LOCAL_QUORUM, EACH_QUORUM, ALL.
Exemplo de fluxo de gravação
Por questões de simplicidade, suponha que uma solicitação de gravação seja emitida para um cluster Cassandra de 6 nós com as seguintes características:
WRITE_CONSISTENCY_LEVEL=TWO
TABLE_REPLICATION_FACTOR=3
REPLICATION_STRATEGY=SimpleStrategy
Primeiro, o cliente envia a solicitação de gravação para o cluster Cassandra usando o driver. Não discutimos o papel do driver neste artigo (talvez em outro), mas ele é muito importante. O driver é responsável por muitos recursos, como IO assíncrono, execução paralela, pipelining de solicitação, agrupamento de conexões, descoberta de nó automático, reconexão automática, reconhecimento de token, e assim por diante. Por exemplo, usando um driver que implementa uma política de reconhecimento de token, o driver reduz saltos de rede enviando solicitações diretamente para o nó que possui os dados em vez de enviá-lo para um coordenador “aleatório”.
Assim que o coordenador obtiver a solicitação de gravação, ele aplica a função hash do particionador à chave de partição e usa a estratégia de replicação configurada para determinar os nós de réplica TABLE_REPLICATION_FACTOR que realmente gravarão os dados (nesta frase, substitua TABLE_REPLICATION_FACTOR pelo número 3). A figura 4 mostra os nós de réplica (em verde) que irão lidar com a solicitação de gravação.
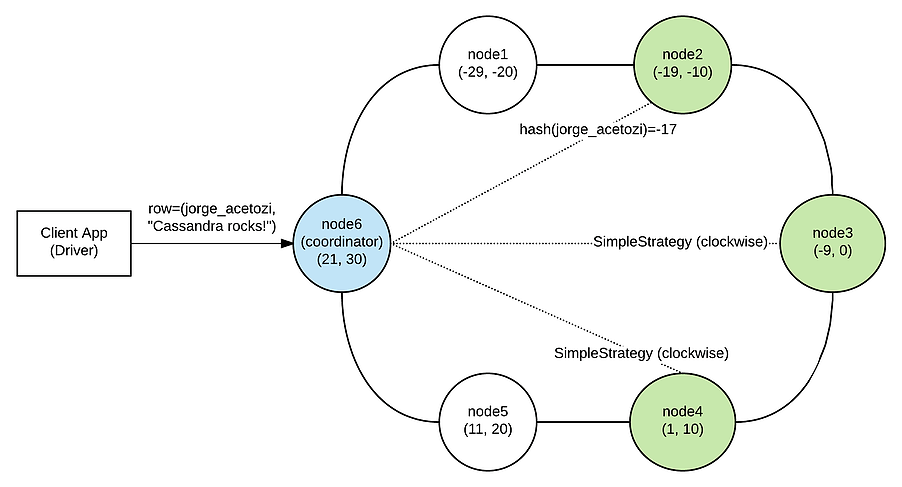
Figura 4 – Nós de réplica
Agora, antes que o coordenador encaminhe o pedido de gravação para todos os 3 nós de réplica, ele perguntará ao componente Failure Detector quantos desses nós de réplica estão realmente disponíveis e vai compará-los com WRITE_CONSISTENCY_LEVEL fornecido na solicitação. Se o número de nós de réplica disponíveis for menor do que o WRITE_CONSISTENCY_LEVEL fornecido, o Failure Detector lançará imediatamente uma Exceção.
Para o nosso exemplo, suponha que os 3 nós de réplica estejam disponíveis (ou seja, o Failure Detector permitirá que a solicitação continue) como mostrado na figura 5. Agora, o coordenador encaminhará de forma assíncrona a solicitação de gravação para todos os nós de réplica (nesses casos, os 3 nós de réplica que foram calculados na primeira etapa). Assim que os nós de réplica WRITE_CONSISTENCY_LEVEL reconhecem o sucesso (node2 e node4), o coordenador retorna sucesso para o driver.
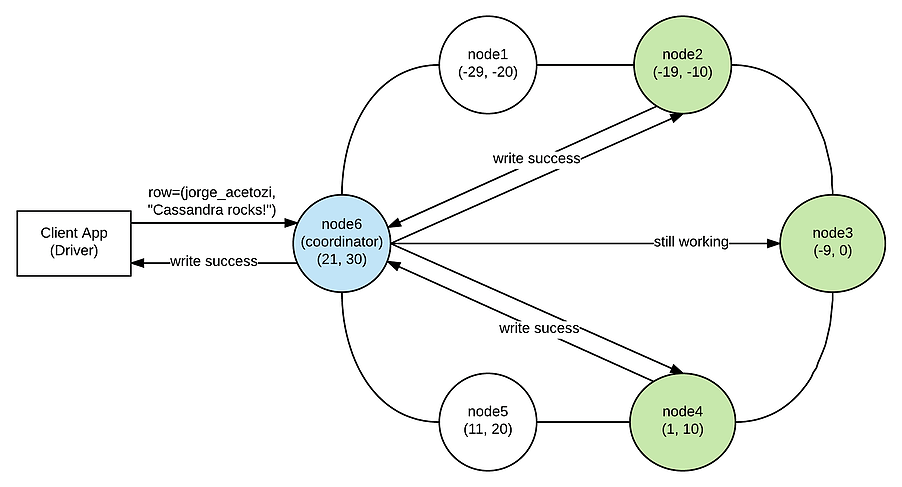
Figura 5 – Write Sucess
Se o WRITE_CONSISTENCY_LEVEL para esse pedido fosse TRÊS (ou TODOS), o coordenador teria que esperar até que o nó3 reconhecesse o sucesso também e, claro, essa solicitação de gravação seria mais lenta.
Então, basicamente…
- Você precisa de tolerância a falhas e alta disponibilidade? Use replicação;
- Tenha em mente que usar replicação significa que você pagará com consistência (para a maioria dos casos, isso não é um problema. A disponibilidade geralmente é mais importante do que a consistência);
- Se a consistência não é um problema para o seu domínio, perfeito. Se for, apenas aumente o nível de consistência, mas você pagará com maior latência;
- Se você quer tolerância a falhas e alta disponibilidade, consistência forte e baixa latência, então você deve ser o cliente, e não o engenheiro de software (Lol).
Hinted Handoff
Suponha que, no último exemplo, apenas 2 dos 3 nós de réplica estivessem disponíveis. Nesse caso, o Failure Detector ainda permitiria que a solicitação continuasse, pois o número de nós de réplica disponíveis não era menor que o WRITE_CONSISTENCY_LEVEL fornecido. Nesse caso, o coordenador se comportaria exatamente como descrito anteriormente, mas haveria uma etapa adicional. O coordenador gravaria a dica localmente (o blob de solicitação de gravação junto com alguns metadados) no disco (diretório de dicas) e manteria a dica por 3 horas (por padrão), esperando que o nó de réplica ficasse disponível novamente. Se o nó de réplica se recuperar dentro desse período, o coordenador enviará a dica ao nó de réplica para que ele possa se atualizar e se tornar consistente com as outras réplicas. Se o nó de réplica ficar offline por mais de 3 horas, será necessário um reparo de leitura. Esse processo é chamado de Hinted Handoff.
Write Internals – Últimas considerações?
Em suma, quando uma solicitação de escrita atinge um nó, duas coisas principalmente acontecem:
- A solicitação de gravação é anexada ao log de commit no disco. Isso garante a durabilidade dos dados (os dados da solicitação de gravação sobreviveriam permanentemente mesmo em um cenário de falha de nó);
- A solicitação de gravação é enviada para o memtable (uma estrutura armazenada na memória). Quando o memtable está cheio, os dados são descarregados para um SSTable no disco usando I/O sequencial, e os dados no log de confirmação são purgados.
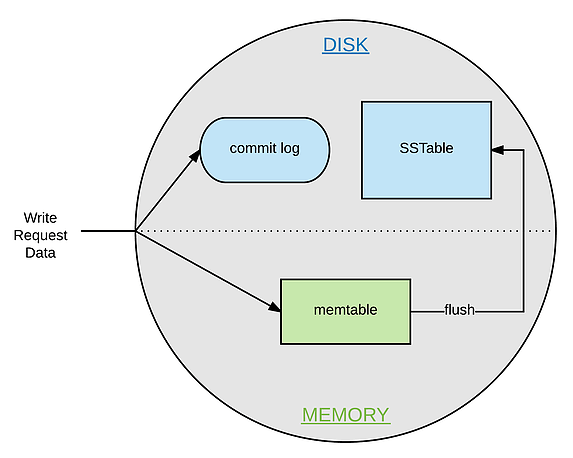
Figura 6 – Nós internos do Cassandra
Eu realmente espero que este artigo tenha sido útil para você. Se você gostou de lê-lo, avise-me se você gostaria de ler outro artigo sobre Read Request Path – ele é um pouco mais complicado, pois envolve Snitches, Bloom Filter, Indexes, e assim por diante, mas também é muito interessante.
Se você é um desenvolvedor de software interessado em usar Cassandra em um cenário realista, codificando um aplicativo de bate-papo em tempo real a partir do zero, veja o meu livro: Pro Java Clustering and Scalability: Building Real-Time Apps with Spring, Cassandra, Redis, WebSocket and RabbitMQ.
Muito obrigado.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?