

Os serviços da Uber dependem da precisão das ferramentas de previsão de eventos. Desde estimar a demanda do motorista em uma determinada data até prever quando uma ordem UberEATS chegará, a Uber usa algoritmos de previsão para melhorar as experiências do usuário (UX) em nosso portfólio de produtos.
Para arquitetar uma experiência de previsão precisa e facilmente interpretável para engenharia e operações, nós construímos um sistema de previsão personalizado, alavancando um mecanismo open source de pesquisa RESTful distribuído, composto pelo mecanismo de consulta Elasticsearch, o pipeline de indexação de dados Logstash e a ferramenta de visualização Kibana (ELK). Simples, mas poderosa, nossa arquitetura resultante é facilmente escalável e funciona em tempo real.
Neste artigo, nós discutimos por que e como construímos esse sistema e compartilhamos as melhores práticas e lições aprendidas com o trabalho com o Elasticsearch.
Projetando um sistema de previsão personalizado
A qualidade das nossas previsões é medida pela forma como elas correspondem aos resultados finais dos recursos de viagem, como a taxa de conrrespondencia do uberPOOL, a qualidade da correpondência etc.
Precisávamos criar uma arquitetura altamente personalizável para que nosso sistema de previsão pudesse se sincronizar com nossos produtos existentes porque:
- Alguns recursos de viagem só se aplicam a uberPOOL, por exemplo, taxa de correspondência e qualidade da correspondência.
- Características específicas de nossos produtos – uberPOOL, uberX, UberBLACK etc. – muitas vezes apresentam características de viagem de impacto. Por exemplo, pickup dinâmico e dropoff é um recurso que existe no uberPOOL, mas não no uberX ou no UberBLACK, e pode afetar a equação geral.
- O comportamento do motorista e do passageiro, como ir a uma rota diferente da sugerida pela Uber, pode afetar as previsões.
Para cumprir as especificações acima, definimos os requisitos de produto do nosso novo sistema de previsão como:
- Ser consciente do produto. Distinguir com precisão o produto que o motorista estava usando e alterar nossas previsões, se necessário, é fundamental para um UX contínuo.
- Garantir um erro médio baixo por produto. O erro médio de previsão de cada produto precisa ser o mais próximo possível de zero para manter a precisão geral de nossas previsões.
- Manter um erro absoluto médio baixo por produto. Além disso, o erro de previsão absoluta média de cada produto precisa ser o mais próximo possível do zero para garantir a precisão de tempo ou local.
Além de atender aos requisitos do produto, precisávamos cumprir padrões específicos de engenharia. Alta disponibilidade, baixa latência, escalabilidade e facilidade de operação são cruciais para o sucesso do nosso sistema de previsão, já que o modelo serviria para milhões de usuários em centenas de cidades e dezenas de países. Depois de definir essas diretrizes, apresentamos os planos para algoritmos que poderiam atender a esses benchmarks, avaliando os designs online e offline.
Arquitetando um algoritmo online
Na Uber, muitas vezes usamos uma combinação de dados de viagem no histórico e em tempo real para treinar nossos algoritmos de previsão de viagem. Embora possamos prever alguns padrões como a densidade da viagem e a taxa de conrrespondência, dependendo da localização, data, hora e outras variáveis estabelecidas, esses padrões se ajustam à medida que nossos sistemas avançam e as operações se expandem para novos mercados. Como resultado, capturar a dinâmica do sistema em tempo real ou em tempo quase real é fundamental para a precisão da previsão.
Em nosso esforço para maximizar a precisão, decidimos usar um algoritmo online que não requer muito treinamento e trabalho de manutenção de modelos. Escolhemos o algoritmo de vizinhos mais próximos (KNN), que encontra k vizinhos mais próximos (ou seja, viagens no histórico semelhantes durante um período de tempo) e, em seguida, executa uma regressão sobre elas para criar uma previsão. Esse algoritmo de dois passos funciona:
- Escolhendo k candidatos com base em nossa função de similaridade autodefinida derivada de recursos como: geolocalização, tempo etc.
- Calculando os pesos para cada candidato selecionado com base na função de similaridade e na média ponderada para cada variável de resposta como saída.
Enquanto a segunda parte desse algoritmo é principalmente computação local e apresenta pouco desafio de engenharia, a primeira parte é mais desafiadora. Essencialmente um problema de busca em larga escala, esta etapa requer uma função de similaridade relativamente complexa para classificar os candidatos e selecionar o K classificado como o melhor para a segunda parte do algoritmo. Nosso objetivo aqui é agrupar o histórico das viagens mais parecidas de uma grande quantidade de viagens. É muito difícil classificar todas as viagens usando a função de similaridade em um mecanismo de busca devido à diversidade e à quantidade de dados. Em vez disso, conseguimos isso em duas etapas:
- Reduzir o espaço de pesquisa aplicando uma lógica de filtragem de alto nível, por exemplo, filtragem de dados por cidade ou ID do produto.
- Executar um ranking baseado em similaridade no conjunto de dados reduzido e selecionar o K com o melhor ranking.
Embora seja poderoso, o KNN é um algoritmo desafiador para usar ao se lidar com dados em grande escala. Para utilizá-lo efetivamente, precisávamos de um armazenamento robusto e um mecanismo de busca capaz de lidar com milhares de consultas por segundo (QPS) e centenas de milhões de registros por vez. Também precisávamos de suporte para consulta geoespacial para auxiliar na filtragem de candidatos k.
Usando ELK como armazenamento de dados e mecanismo de pesquisa
Embora tenhamos observado brevemente outros bancos de dados que suportam consultas geoespaciais como o MySQL, nossas exigências de flexibilidade de esquema e requisitos de pesquisa facilitaram a decisão de usar uma solução ELK open source para alimentar nossa loja de dados e mecanismo de busca.
O ELK, construído com Elasticsearch, Logstash e Kibana, é uma solução integrada para pesquisar e analisar dados em tempo real. O Elasticsearch, peça central da solução, é um mecanismo de busca construído em cima do Apache Lucene. Ele fornece pesquisa distribuída e de texto completo com uma interface RESTful e documentos JSON schema-free. O Logstash é um mecanismo de coleta de dados e log-parsing, e o Kibana é um plugin de visualização de dados e analytics para o Elasticsearch.
O ELK foi uma escolha fácil para nós, porque ele oferece pesquisa de texto completo, consulta geoespacial, flexibilidade de esquema e um pipeline de dados fácil de montar (ele pode carregar dados em tempo quase real ingerindo tópicos da Kafka.) O ELK forneceu a flexibilidade necessária para atender às nossas diretrizes de engenharia e fornecer um sistema de previsão preciso e rápido para nossos passageiros.
Arquitetura do sistema
Em um nível básico, nossa arquitetura de previsão foi construída usando Kafka para streaming de dados, Hive como data warehouse para gerenciar consultas e analytics, e quatro serviços internos separados que usam a pilha ELK para criar um sistema de previsão robusto. Abaixo, descrevemos esses quatro serviços e a arquitetura geral:
- Serviço de previsão: entrega previsões em tempo real para usuários.
- Serviço de treinamento: treina parâmetros e pipelines de dados offline.
- Serviço de viagem: administra o estado das viagens através do seu ciclo de vida, desde o pedido até a conclusão.
- Serviço de configuração: armazena e serve parâmetros treinados para outros serviços.
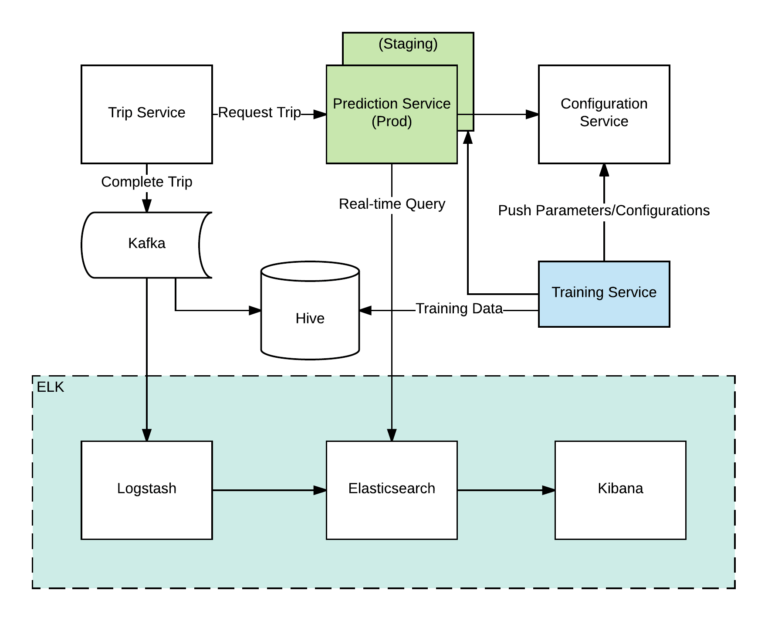
Legenda da imagem: A arquitetura completa do nosso sistema de previsão em tempo real é composta por pipelines de dados, treinamento e lógica de serviço.
Pipelines de dados
Nosso armazenamento de dados é composto de dados de viagem completos e métricas, como tempo de viagem, distância e custo. Para trabalhar de forma rápida e eficiente, nosso pipeline deve ser capaz de ingerir e entregar esses dados de viagem em tempo quase real. Nossa solução é publicar dados em um tópico Kafka no final de uma viagem. A partir daí, o Logstash ingeriu o tópico Kafka, transformando e indexando os dados no Elasticsearch. O pipeline de dados é configurado para consultas imediatas de dados, garantindo o melhor desempenho usando as viagens mais recentes. Também precisamos de uma loja primária para armazenamento e analytics; nós alavancamos o Hive como uma ferramenta de extrato, transformação e carga (ETL) para gerenciar dados processados pelo Kafka. Com esses dois pipelines de dados, usamos o ELK para consultas em tempo real e o Hive para treinamento e analytics.
Parâmetros de treinamento
A regressão KNN é um algoritmo online, o que significa que não precisamos treinar modelos para isso. Mas os valores para k e os parâmetros de regressão ainda precisam ser treinados e selecionados de forma apropriada. Construímos um serviço de treinamento para selecionar valores para K e parâmetros de regressão. Esse serviço pode treinar esses parâmetros em diferentes granularidades, bem como produzir valores padrão globais, valores por país, valores por cidade e valores por produto. Uma vez que esses parâmetros são treinados, o serviço de treinamento empurra os valores para o nosso serviço de configuração dinâmico.
A partir daí, o serviço de configuração entrega parâmetros acionáveis para o nosso serviço de previsão. O serviço de viagem então chama as métricas previstas do nosso serviço de previsão para a próxima viagem. Nessa etapa, nosso serviço de previsão consulta o Elasticsearch para candidatos e o serviço de configuração para parâmetros, alimentando-os no algoritmo para gerar previsões. Os resultados da previsão são devolvidos ao nosso serviço de viagem e armazenados como dados de viagem, mais tarde serão publicados no Elasticsearch e no Hive para que possamos acompanhar o desempenho de nossas previsões para treinar os futuros parâmetros e melhorar a precisão.
Crescendo em uma escala Uber
Nosso sistema de previsão foi otimizado para escalabilidade horizontal em mercados e produtos, por isso foi relativamente fácil implementá-lo e mantê-lo no início. No entanto, à medida que expandimos nossa escala para incorporar mais produtos em mais cidades, tivemos que considerar a alta latência causada por uma pausa de garbage collection e falhas em cascata induzidas por excesso de CPU. Essas duas questões são causadas pela sobrecarga dos nós Elasticsearch, por isso focamos nossos esforços em melhorar o desempenho da pesquisa e projetar uma arquitetura mais escalável.
Reduzindo o tamanho da consulta para melhorar o desempenho da pesquisa
O tamanho dos dados importa no Elasticsearch; um índice grande significa dados demais, caching churn e tempo de resposta ruim. Quando os volumes de consulta são grandes, os nós ELK ficam sobrecarregados, causando longas pausas de coleta de lixo ou até interrupções do sistema.
Para resolver isso, mudamos para consultas hexagonais, dividindo nossos mapas em células hexagonais. Cada célula hexagonal tem uma ID de string determinada pelo nível de resolução hexagonal. Uma consulta de geodistância pode ser aproximadamente traduzida em um anel de IDs de hexágono; embora um anel hexagonal não seja uma superfície circular, está próximo o suficiente para o nosso caso de uso. Devido a esse ajuste, a capacidade de consulta do nosso sistema mais do que triplicou.
Escalando horizontalmente com clusters virtuais
À medida que o sistema se expande para novos mercados, precisamos adicionar mais nós aos nossos clusters. Um método comum de escalar o Elasticsearch é adicionar mais nós horizontalmente. Para isso, organizamos dados de viagem em índices diários, com cada índice possuindo um único fragmento replicado para todos os nós de dados no cluster. Um HAProxy é implementado para equilibrar o tráfego de pesquisa em todos os nós de dados no cluster. Nesse modelo, o sistema é linearmente escalável em relação ao número de nós do cluster.
Entretanto, conforme os nós são adicionados, o cluster desestabiliza. Enquanto uma única arquitetura de cluster pode lidar com aproximadamente três mil consultas por segundo, nosso sistema totaliza 40 nós (e contando) em um tamanho de 500 GB por nó. Nesse escopo, o custo da comunicação inter-nó de cluster começa a superar o benefício de usar um grande cluster.
Para superar essa limitação, desenvolvemos um cluster virtual. Uma escolha arquitetônica incomum, os clusters virtuais consistem em múltiplos clusters físicos que compartilham o mesmo alias de cluster. Os aplicativos acessam o cluster virtual através do HAPROxy, especificando o alias de cluster, e as solicitações podem ser encaminhadas para qualquer um dos clusters com o alias de cluster. Com essa arquitetura, conseguimos escalabilidade praticamente ilimitada, apenas adicionando mais clusters.
Lições aprendidas: Elasticsearch como um banco de dados NoSQL
Usamos o Elasticsearch como um armazenamento secundário que empurra dados para ele de forma assíncrona, porque não foi projetado para ter consistência. Para efetivamente utilizar seus valiosos recursos de pesquisa, precisamos operar o Elasticsearch com cuidado. Abaixo, descrevemos algumas lições aprendidas trabalhando com essa base de dados poderosa mas complexa:
- Proporcionar recursos suficientes. O Elasticsearch funciona bem quando é alimentado por recursos amplos. Ele é projetado para velocidade e recursos poderosos, com a suposição de que hardware e pessoal são abundantes. No entanto, ele hesita quando os recursos são restritos. Para tirar o máximo de proveito do Elasticsearch, você precisa entender a escala com a qual está lidando e fornecer recursos suficientes.
- Organize dados de acordo com sua lógica de negócios. Quando o tamanho de seus dados é muito grande para caber em um nó, você precisa organizar seus dados de forma inteligente.
- Solicite consultas Elasticsearch para obter ganhos de eficiência. O Elasticsearch suporta muitos filtros em sua consulta, e essa solicitação afeta muito o desempenho. Os filtros mais específicos devem ser priorizados e colocados antes de filtros menos específicos para que possam filtrar o máximo de dados possível, o mais cedo possível, no processo de consulta. Filtros menos intensivos em recursos devem ser implementados antes de filtros mais intensivos em recursos para que eles tenham menos dados para filtrar. Da mesma forma, os filtros armazenáveis em cache devem ser exibidos antes dos filtros não-cacheáveis, para que os caches possam ser alavancados.
Nossa jornada com previsão e ELK apenas começou – você está pronto?
Atualização: desde que a Uber começou a usar o ELK, a pilha ELK se expandiu para incluir tecnologias adicionais e agora é chamada de Elastic Stack.
***
Este artigo é do Uber Engineering. Ele foi escrito por Guocheng Xie e Yanjun Huang. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em:https://eng.uber.com/elk/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?