

Esta é a continuação de um artigo que mostrava o básico sobre por que logs de servidor são uma parte importante do kit de ferramentas do SEO. Neste artigo, eu forneço algumas informações sobre como formatar os dados no Excel para encontrar e analisar as oportunidades de otimizar a indexação do Googlebot.
Antes de se aprofundar nos logs, é importante entender o básico de como o Googlebot rastreia o seu site. Há três fatores básicos que o Googlebot considera. Primeiro são as páginas que devem ser rastreadas. Isso é determinado por fatores como o número de links que apontam para a página, a estrutura interna de links do site, o número e a força com a qual os links internos apontam para aquela página e outros sinais internos como sitemaps.
Em seguida, o Googlebot determina o número de páginas a serem rastreadas. Isso é normalmente chamado de “orçamento de rastreamento” (crawl budget). Fatores que normalmente são levados em conta ao alocar o orçamento para rastreamento são: a autoridade e a confiança do domínio, desempenho, tempo de carregamento e estrutura limpa de URLs (se o Googlebot ficar preso num loop de pesquisa sem fim, isso custará dinheiro ao Google). Para muito mais detalhes sobre orçamento de rastreamento, cheque o artigo do Ian Lurie sobre o assunto.
Finalmente, a taxa de indexação – a frequência com a qual o Googlebot retorna – é determinada pela frequência com a qual o site é atualizado, a autoridade do domínio, pelo vigor das citações, menções sociais e links para a página.
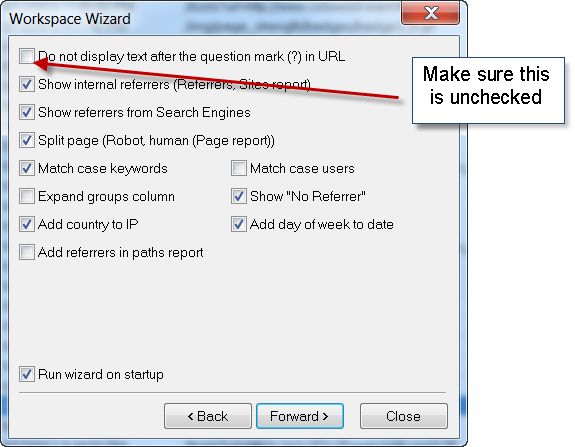
Agora, vamos ver como o Googlebot está indexando o Moz.com (NOTA: os dados que estou analisando são do SEOmoz.org, anteriores à nossa migração para o Moz.com. Muitos dos potenciais problemas que eu aponto abaixo já foram resolvidos. Oba!). O primeiro passo é conseguir os dados dos logs em um formato que permita nosso trabalho. Eu expliquei em detalhes como fazer isso em meu artigo anterior sobre logs de servidor. Entretanto, desta vez, certifique-se de incluir os parâmetros com as URLs para que possamos analisar caminhos assustadores para o robô. Certifique-se de que a opção abaixo está desmarcada ao importar o seu arquivo de log.
A primeira coisa que queremos ver é onde em nosso site o Googlebot está gastando mais tempo e dedicando a maior parte dos recursos. Agora que você exportou seu arquivo de log para o formato .csv, será necessário fazer um pouco de formatação e limpeza dos dados.
1. Salve o arquivo com uma extensão do Excel, por exemplo .xlsx.
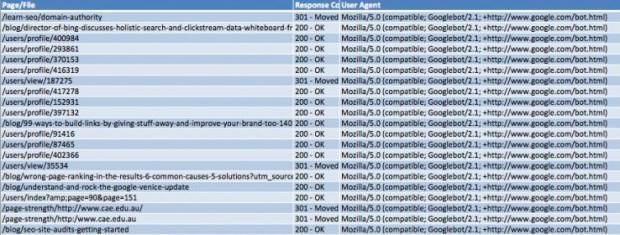
2. Remova todas as colunas, exceto Page/File, Código de resposta e User Agent. Deve ficar parecido com isto (formatado como tabela, o que pode ser feito ao selecionar seus dados e ^L):
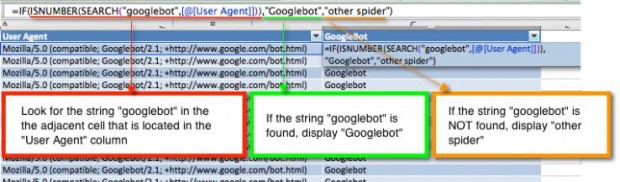
3. Isole o Googlebot de outros mecanismos ao criar uma nova coluna e escreva uma fórmula que procura por “Googlebot” nas células da terceira coluna.
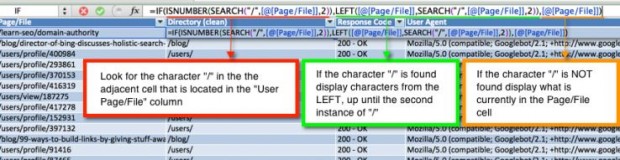
4. Limpe a coluna Page/File pelo diretório home para que mais tarde possamos pivotar uma tabela e ver quais seções o Google está rastreando mais.
5. Uma vez que deixamos em ordem o parâmetro da URL para checarmos os caminhos de rastreamento, queremos removê-lo para que os dados sejam incluídos na análise do diretório home (top-level) que faremos na tabela a ser pivotada. O parâmetro URL sempre começa com “?”, portanto é por esse termo que buscaremos no Excel. Isso pode confundir, porque o Excel usa o caractere de interrogação como coringa. Para indicar ao Excel uma interrogação literal, usamos o caractere precedido do til: “~?”
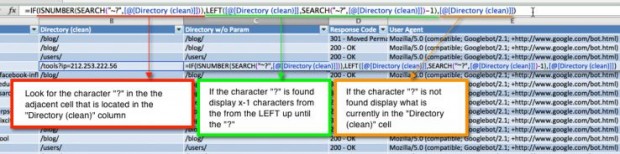
6. Os dados podem agora ser analisados e pivotados em uma tabela (dados > tabela dinâmica). O número associado com esse diretório é o número total de vezes que o Googlebot requisitou um arquivo durante o tempo coberto pelo log, que nesse caso é de um dia.
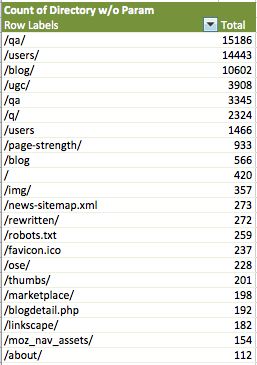
O Google está alocando o orçamento de rastreamento de forma apropriada? Podemos mergulhar profundamente em diferentes partes dos dados aqui:
- Mais de 70% do orçamento de rastreamento do Google estão focados em três seções, enquanto que 50% disso referem-se a /qa/ e /users/. Moz deve procurar por dados de referências de busca do Google Analytics para ver o quão orgânicos são os valores de busca que essas seções fornecem. Se forem desproporcionalmente baixos, gerenciamento de indexação ou melhorias de otimização na página devem ser levadas em conta.
- Outra potencial percepção a partir desses dados é que /page-strength/, uma URL utilizada para postar dados para uma ferramenta do Moz, está sendo rastreada próximo de mil vezes. Esses rastreamentos são acionados provavelmente a partir de links externos apontando para os resultados da ferramenta do Moz. A recomendação seria excluir esse diretório utilizando o robots.txt.
- Do outro lado do espectro, é importante entender os diretórios que são raramente rastreados. Há seções sendo sub-rastreadas? Vamos ver alguns resultados do Moz:

Nesse exemplo, o diretório /webinars aparece como um dos que não recebem muita atenção do Google. De fato, apenas o diretório superior está sendo rastreado, enquanto que o conteúdo dentro de Webinar está sendo ignorado.
Esses são apenas alguns exemplos de questões relativas à indexação que podem ser encontradas em logs de servidor. Algumas questões para se prestar atenção incluem:
- Os mecanismos de busca estão rastreando páginas que estão excluídas pelo robots.txt?
- Os mecanismos de busca estão rastreando páginas que devem ser excluídas pelo robots.txt?
- Algumas seções estão consumindo muita banda? Qual é o número de páginas rastreadas em uma seção em relação à quantidade de banda necessária?
Como bônus, fiz um screencast dos processos acima para formatar e analisar o rastreamento do Googlebot.
No meu próximo artigo sobre a análise de arquivos de log, explicarei em mais detalhes como identificar conteúdo duplicado e visualizar tendências em relação ao tempo.
***
Este artigo é uma republicação feita com permissão. Moz não tem qualquer afiliação com este site. O original está em http://moz.com/blog/seo-log-file-analysis-part-2

De 0 a 10, o quanto você recomendaria este artigo para um amigo?