

No site do SEOmoz, nós acabamos de mudar a maneira de detectar as páginas duplicadas ou quase duplicadas no nosso crawler personalizado. Fizemos isso para melhor atendê-los. Nosso código anterior produziu bons resultados, mas poderia desmoronar em grandes crawls (maiores que cerca de 85 mil páginas), e levava muito tempo (às vezes várias semanas) para terminar.
Agora que a mudança é ao vivo, você verá algumas melhorias e mudanças:
- Os resultados virão mais rápido (até uma hora mais rápido em pequenos crawls e literalmente dias mais rápido nos maiores crawls);
- Ele é mais exato na remoção de duplicados, resultando em menos duplicados nos seus resultados de crawls;
Este artigo fornece um olhar sobre as motivações por trás de nossa decisão de mudar a maneira que o crawl personalizado detecta páginas duplicadas e quase duplicadas em um alto nível. Divirta-se!
Melhorando a medida de similaridade da nossa página
A heurística que usamos atualmente para medir a similaridade entre duas páginas é chamada de fingerprints. Elas dependem de transformar cada página em um vetor de 128 de 64 bits de tal forma que as páginas duplicadas ou quase duplicadas resultem num vetor idêntico ou quase idêntico. A diferença entre algumas páginas é proporcional ao número de entradas correspondentes nos dois vetores que não são os mesmos.
A heurística mais rápida, na qual estamos trabalhando para implementar, é chamada de similarity hash, ou simhash para abreviar. A simhash é um único número inteiro de 64-bit, não assinado e novamente calculada de tal maneira que as páginas duplicadas ou quase duplicadas resultem em valores simhash, que são idênticos, ou quase. A diferença entre as páginas é proporcional ao número de bits que diferem nos dois números.
O problema: evitar duplicadas falsas
O problema é que estas duas medidas são muito diferentes: uma é um vetor de 128 valores, enquanto a outra é de valor único. Por causa dessa diferença, as medidas podem variar em como veem a diferença da página. Com a possibilidade de um crawl único contendo mais de um milhão de páginas, isso significa uma quantidade terrível de números que precisamos comparar para determinar o melhor valor de limite possível para a nova heurística.
Mais especificamente, precisamos definir o limite heurístico para detectar tantas duplicadas e quase duplicadas quanto possível, minimizando o número de duplicadas falsas. É mais importante minimizar o número de pares de páginas que não são duplicadas, de modo que não esteja removendo uma página como uma cópia, a menos que, na verdade, seja uma duplicada. Isto significa que é necessário ser capaz de detectar páginas em que:
- As duas páginas não são, na verdade, duplicadas ou quase duplicadas;
- A heurística fingerprints atual os vê corretamente como diferente;
- A heurística simhash incorretamente os vê como semelhantes.
Estamos sendo extremamente cuidadosos sobre isso e para evitar a experiência ruim do cliente, nós nos antecipamos: ter uma mudança por trás das cenas da nossa heurística de detecção de duplicados, causando a aparição de um súbito rash de erros de páginas duplicadas incorretas sem um bom motivo aparente.
A solução: visualização dos dados
Nossa necessidade de tomar uma decisão, onde muitas quantidades numéricas estão envolvidas, é um caso clássico onde a visualização de dados pode ser de grande ajuda. O o especialista de dados do SEOmoz, Matt Peters, sugeriu que a melhor maneira de normalizar estas duas medidas muito diferentes de mensurar o conteúdo da página fosse se concentrar em como medir a diferença entre as páginas existentes. Levando isso para o lado pessoal, eu decidi sobre a seguinte abordagem:
- Exemplo de cerca de 10 milhões de pares de páginas a partir de cerca de 25 crawls selecionados aleatoriamente;
- Para cada par de páginas amostrado, traçar a sua diferença, como medido pela herança heurística fingerprints no eixo horizontal (0 a 128), e sua diferença, como medido por simhash no eixo vertical (0 a 64).
A trama resultante desta abordagem fica assim:
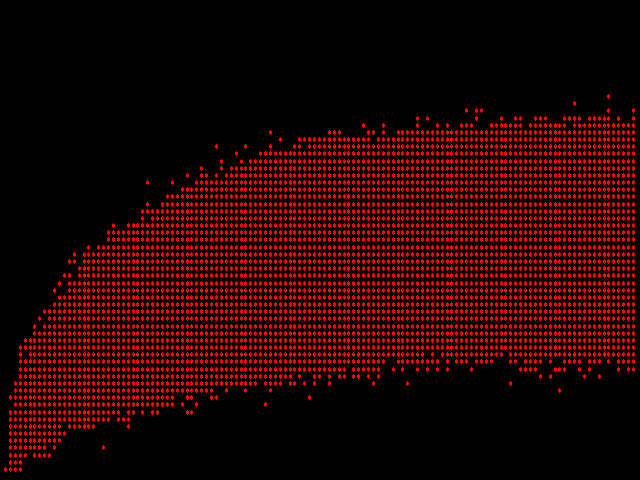
Imediatamente, um problema é óbvio: não existe uma medição de tendência central (ou falta dela) nesta imagem. Se mais do que um par de páginas possui a mesma diferença medida pelo legacy fingerprints e simhash, o software de plotagem coloca um segundo ponto vermelho precisamente em cima do primeiro. E assim por diante para o terceiro ponto de dados em quarto lugar, centésimo, e possivelmente milésimo idêntico.
Uma maneira de resolver este problema é a cor dos pontos de maneira diferente, dependendo de quantos pares de páginas eles representam. Então, o que acontece se selecionarmos a cor utilizando um comprimento de onda de luz que corresponde ao número de vezes que chegamos num ponto no mesmo local? Essa tática nos dá um terreno com vermelho (um comprimento de onda longa), indicando mais pontos de dados, descendo através de laranja, amarelo, verde, azul e violeta (realmente magenta, nesta escala), representando apenas um ou dois valores:
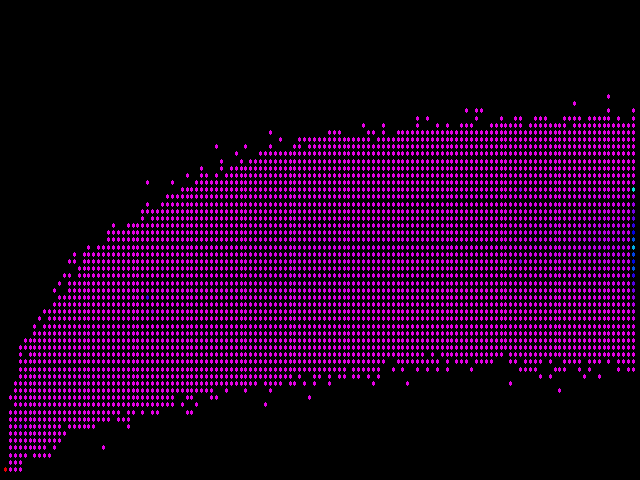
Que frustrante! Não tem quase nenhuma mudança. No entanto, se olhar cuidadosamente, você pode ver alguns pontos azuis nesse mar de magenta; e o mais importante de tudo, o ponto inferior mais à esquerda é vermelho, representando o maior número de casos de todos. O que está acontecendo aqui é que ponto vermelho representa uma contagem muito maior do que todas as outras contagens que a maioria das outras cores entre elas e as que representam os números mais baixos acabam não sendo utilizadas.
A solução é atribuir cores de tal modo que a maior parte delas acaba sendo utilizada para a codificação das contagens mais baixas e para atribuir progressivamente menos cor conforme a contagem aumenta. Ou, em termos matemáticos, para atribuir cores com base numa escala logarítmica, em vez de linear. Se fizermos isso, vamos acabar com o seguinte:
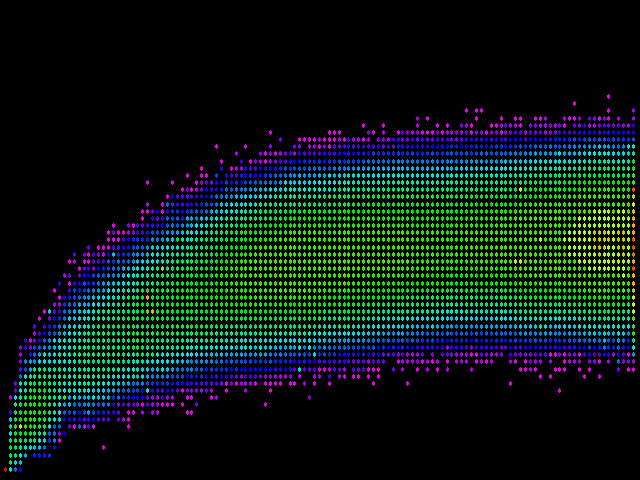
Agora estamos chegando a algum lugar! Como esperado, existe uma tendência central dos dados, mesmo que ela seja muito ampla. Uma coisa que está imediatamente evidente é que embora na teoria, a diferença medida por simhash pode ir até um máximo de 64; na prática, raramente obtém muito mais do que 46 (três quartos do máximo). Em contraste, utilizando a diferença de fingerprints, várias páginas atingem a diferença máxima possível de 128 (dê uma olhada em todos os pontos vermelhos e laranja ao longo do lado direito do gráfico). Tenha em mente que os pontos vermelhos e laranja representam contagens realmente grandes, porque a escala de cor é logarítmica.
Temos que ser mais cuidadosos na margem inferior. Ela representa valores simhash que indicam pares de páginas que são bastante semelhantes. Se duas páginas não são, de fato, similar, ainda sim o simhash mede como semelhantes, onde fingerprints viu uma diferença significativa, esta é exatamente o tipo de experiência negativa para o cliente que estamos tentando evitar. Um ponto problemático em potencial está circulado abaixo:
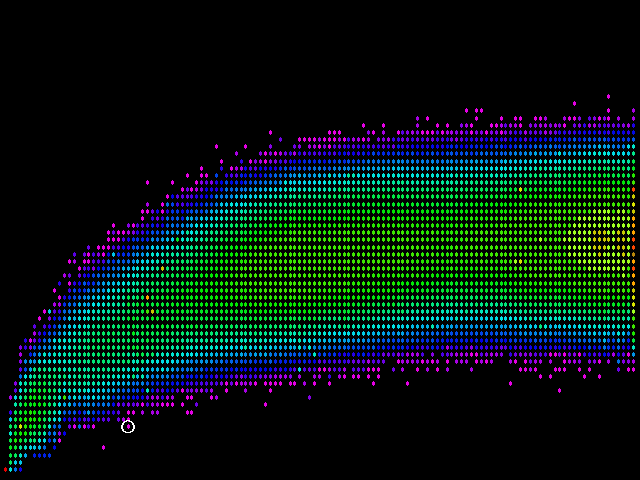
O ponto circulado representa um par de páginas que são realmente muito diferentes, mas que simhash acha que são bastante semelhantes. O ponto para a esquerda e ainda mais abaixo acaba não sendo um problema: representa um par de páginas quase duplicadas que a velha heurística deixou passar!
A posição vertical do ponto problemático representa uma diferença simhash de 6 (6 bits correspondentes dos dois valores de 64 bits que o simhash difere). Não é o único caso, ou, ocasionalmente, tais pares de páginas surgem de tempos em tempos. Isso acontece em 1% ou menos do crawl, mas acontece. Se escolhermos um limiar de diferença simhash de 6 (correspondente ao limiar temos atualmente definida para fingerprints legacy), haverá falsos positivos.
Escolhendo um limiar
Felizmente, 6 parece ser um caso limite. Acima de 6 bits de diferença, a chance de um falso positivo aumenta. Abaixo de 6, eu era incapaz de encontrar esses casos patológicos, e eu examinei milhares de crawls tentando encontrar um. Então, eu escolho uma diferença de limiar de 5 para simhash baseado em detecção duplicada. Isso resulta em uma situação representada pelo gráfico final:
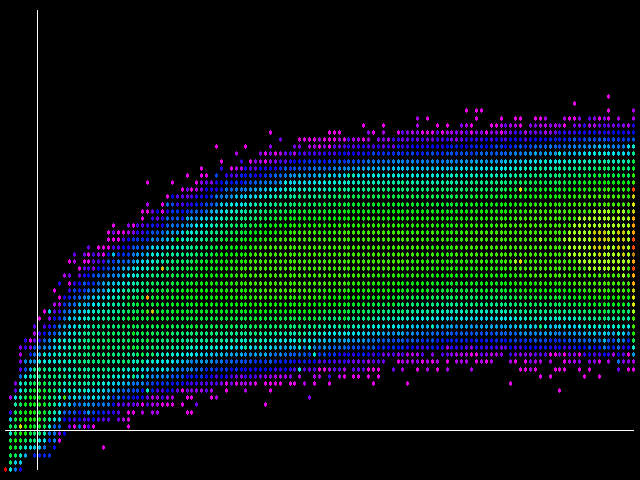
Aqui nós temos linhas desenhadas para representar as duas diferenças de limiar. Tudo para a esquerda da linha vertical representa o que o código atual relataria como duplicado. Tudo abaixo da linha horizontal representa o que o código simhash irá reportar. Tendo em mente a escala de cores logarítmica e o ponto vermelho no canto inferior esquerdo, vemos que o número de pares de página onde as duas heurísticas concordam sobre a similaridade supera o número de pares de página onde discordam.
Observe que ainda há coisas no quadrante “falso positivo” (inferior direito). Acontece que os pares tendem a não diferir muito dos pares onde as duas medidas concordam, ou, para essa matéria, a partir de pares falsos negativos no quadrante superior esquerdo. Em outras palavras, com os limiares escolhidos, tanto simhash e fingerprints legacy deixam de ver algumas quase-duplicações de verdade.
Os resultados visíveis
Com essa decisão do limiar, o número de falsos negativos supera o número de falsos positivos. Isto vai ao encontro do nosso objetivo de minimizar o número de falsos positivos, mesmo às custas de incorrer falsos negativos. Observe que os falsos positivos, no quadrante inferior direito são realmente muito semelhantes um ao outro, e, portanto, deveriam ser descritos como falsos negativos da heurística fingerprints legacy, em vez de os falsos positivos da heurística fingerprints.
Os aspectos mais visíveis da mudança para os clientes são:
- Menos erros de página duplicadas: uma diminuição geral do número de notificações de erros de página duplicadas. Entretanto, cabe ressaltar que:
- Nós ainda podemos perder algumas quase duplicações. Como a corrente de heurística, apenas um subconjunto das páginas quase duplicadas é relatado.
- Páginas completamente idênticas ainda serão relatadas. Duas páginas que são completamente idênticas terão o mesmo valor simhash, e, portanto, uma diferença de zero, como medido pela heurística simhash. Assim, todas as páginas completamente idênticas ainda serão relatadas.
- Velocidade, velocidade, velocidade: A heurística simhash detecta duplicações e quase duplicações cerca de 30 vezes mais rápido do que o código legacy fingerprints. Isto significa que, em breve, nenhum crawl vai gastar mais de um dia de trabalho através de pós-processamento de crawl, o que vai facilitar a entrega dos resultados significativamente mais rápido para crawls grandes.
Espero que este artigo tenha fornecido algumas dicas significativas em nossas próximas mudanças.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?