

Neste artigo de duas partes, veremos formas de realizar a raspagem de dados para marketing de conteúdo. Na primeira parte, serão abordadas encontrar autores, detalhes extras sobre eles e obter a quantidade de seguidores nas redes sociais.
***
Como profissionais de marketing digital, Big Data deveria ser a explicação para muitas das decisões que tomamos. Usar inteligência e compreender o que funciona na nossa indústria de atuação é absolutamente crucial em campanhas de conteúdo, mas é impressionante ver que tantos negócios ainda não têm isso como um foco.
Uma das razões que eu ouço sempre é que não há orçamento suficiente para investir em ferramentas complexas e caras que podem alimentá-los com resmas de dados. Dito isso, você não precisa sempre investir em ferramentas caras para conseguir obter uma inteligência valiosa – e é aqui que o trabalho de raspagem de dados (ou, data scraping) entra.
Apenas para que você entenda claramente, eis uma breve definição de raspagem de dados pela Wikipedia:
Data scraping (ou raspagem de dados) é uma técnica na qual um programa de computador extrai dados de saída legível para humanos, proveniente de um outro programa, e disponibiliza esses dados de modo que se tornem legíveis para outros programas de computador.
Essencialmente, isso envolve varrer uma página web e reunir pedaços de informação que você pode usar para a sua análise. Por exemplo, você pode fazer uma busca em um site como Search Engine Land e raspar (scrape) os nomes dos autores de cada texto que já foi publicado, e a partir daí correlacionar isso aos dados sociais compartilhados para encontrar quem são os autores com o melhor desempenho naquele site.
Eu espero que você comece a ver quão valiosos esses dados podem ser. E mais, fazer isso não requer nenhum conhecimento de código – se você é capaz de seguir as minhas simples instruções, vai poder começar a juntar informação que se transformará em campanhas de conteúdo. Recentemente usei essa pesquisa para me ajudar a publicar um texto na primeira página do BuzzFeed, chegando a mais de 100 mil visitas e gerando uma enorme quantidade de tráfego para o meu blog pessoal.
Aviso: Algo que eu realmente preciso deixar claro antes que você continue a leitura é o fato de que fazer a raspagem de dados de um site pode violar termos de serviços. Você deve garantir que isso não vai acontecer antes de começar. Por exemplo, o Twitter proíbe completamente a raspagem de informação no site. Isso está nos Termos de Serviço:
“varrer o Serviço é permitido apenas em total acordo com as provisões do arquivo robots.txt, no entanto, raspar o Serviço sem consentimento prévio do Twitter é expressamente proibido” (tradução livre)
O Google também faz uma proibição similar para a raspagem de conteúdo em suas propriedades web:
Os Termos de Serviço do Google não permitem o envio automático de queries de qualquer tipo para o nosso sistema sem a permissão prévia do Google. (tradução livre)
Portanto, seja cauteloso.
Análise de conteúdo
Dominar o básico de raspagem de dados vai abrir um novo mundo de possibilidades para análise de conteúdo. Eu aconselho que todos que trabalham com marketing de conteúdo estudem isso.
Antes de começar nos exemplos específicos, você precisa checar se tem o Excel no seu computador (todo mundo deveria ter!) e também o plugin SEO Tools para o Excel (download gratuito aqui). Eu fiz um tutorial de como usar o plugin SEO Tools (em inglês) que pode te interessar.
Você também vai querer uma ferramenta de varredura (web crawling) como o Screaming Frog’s SEO Spider ou Xenu Link Sleuth (ambos têm opções gratuitas). Com tudo isso configurado, você conseguirá fazer tudo o que eu explicar abaixo.
Então, aqui vão algumas formas de como fazer raspagem de dados para análise de conteúdo e como isso pode ser aplicado em suas campanhas de content marketing.
1. Encontrar diferentes autores de um site
Fazer uma análise em grandes sites e blogs para encontrar os autores mais influentes pode render dados bastante valiosos. Uma vez que você tenha a listagem de autores, é possível encontrar quais criaram conteúdo que tiveram bom desempenho nas redes sociais, os com maior número de comentários para gerar engajamento e também alguns extras.
Eu uso esse tipo de informação diariamente para construir relacionamentos com os escritores mais influentes e fazer com que o meu conteúdo apareça nos melhores sites. Eis como fazer isso:
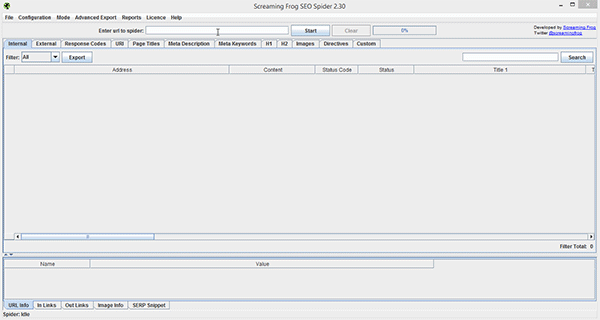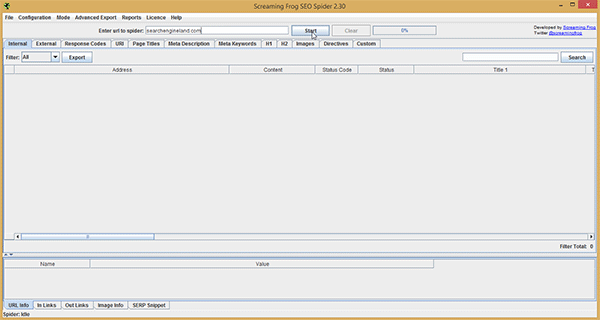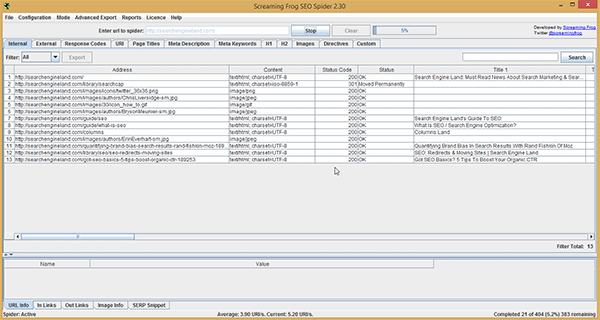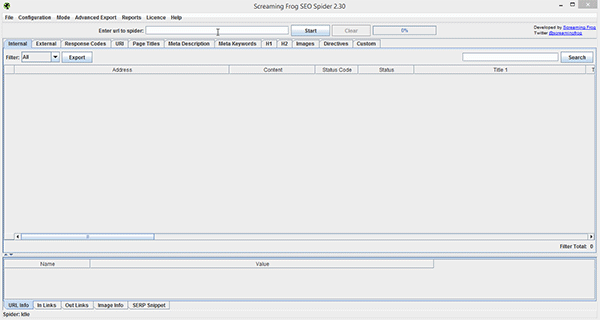
Passo 1: Faça uma lista de URLs dos domínios que você vai analisar usando o SEO Spider. Adicione a raiz do domínio na interface do programa e aperte “start” (se você nunca usou essa ferramenta, pode ver este meu tutorial – em inglês)
Quando a ferramenta terminar de reunir todas as URLs (o que pode levar um tempinho, dependendo do tamanho do site), exporte tudo para uma planilha Excel.
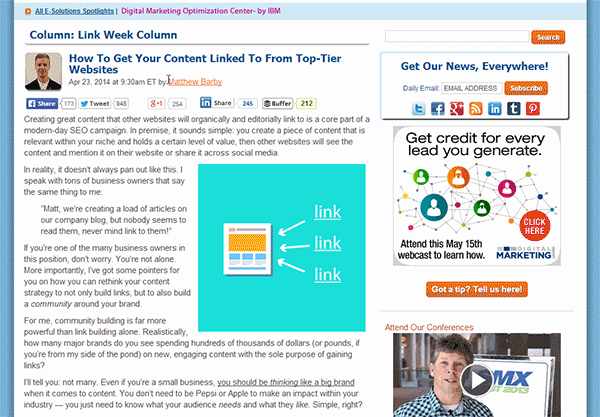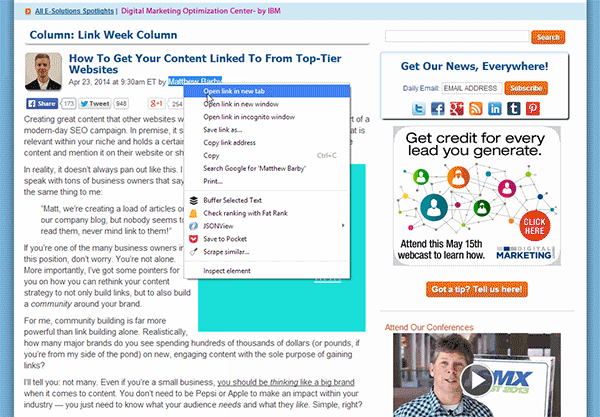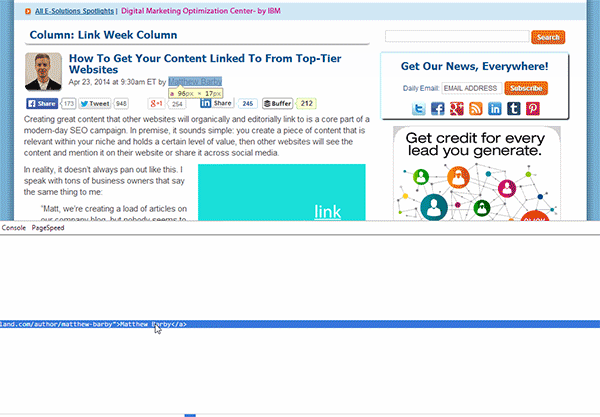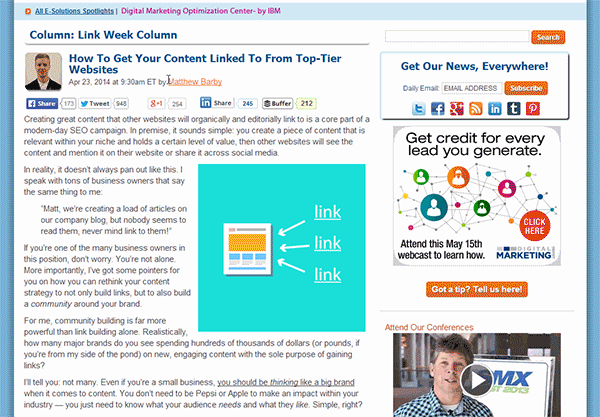
Passo 2: Abra o seu navegador – vamos usar o Chrome – e e vá até uma das páginas de artigo do domínio que você está analisando e descubra onde está a menção ao nome do autor (geralmente é junto de uma bio e/ou abaixo do título). Quando encontrar, clique com o botão direito no nome e selecione “Inspecionar Elemento” (no Chrome, isso vai fazer abrir o console do desenvolvedor).
Dentro desse painel que se abrirá, a linha de código associada ao nome do autor que você escolheu estará destacada (veja na imagem abaixo). Tudo o que você precisa fazer agora é clicar com o botão direito na linha de código destacada e selecionar Copiar XPath.
No site Search Engine Land, eu copiei o seguinte código
//*[@id="leftCol"]/div[2]/p/span/a
Talvez você ache que isso não faça nenhum sentido, por enquanto, mas segure aí que você já vai entender como isso funciona.
Passo 3: Volte para a sua planilha de URLs e delete todas as informações extra que o Screaming Frog oferece; deixe apenas a lista de URLs – adicione-as à primeira coluna (Coluna A) da sua planilha.
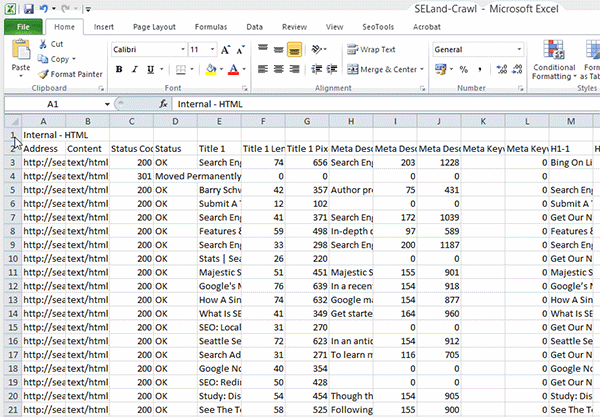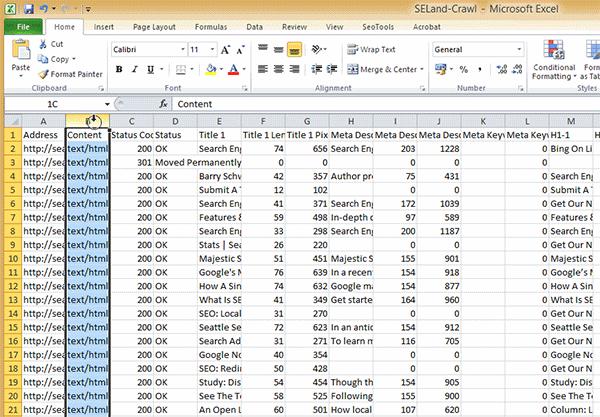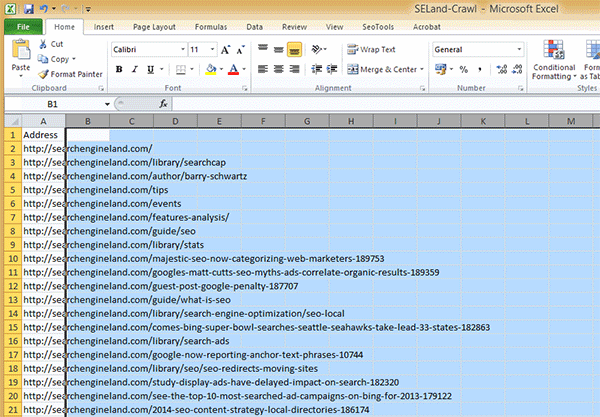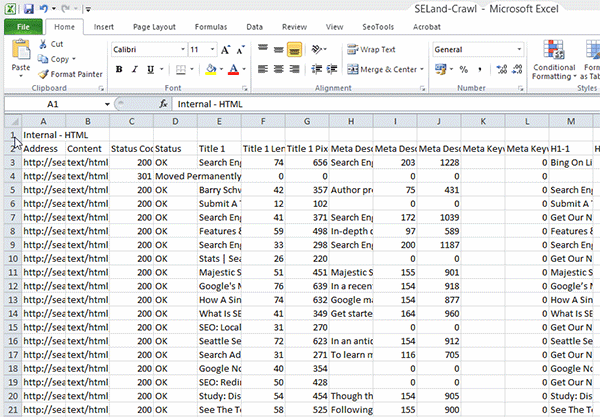
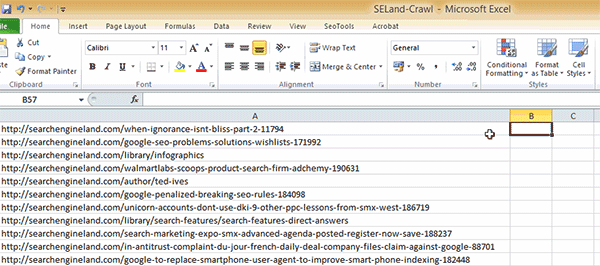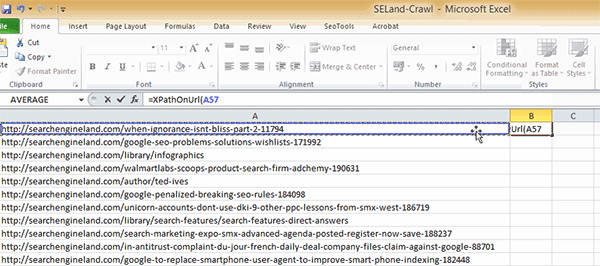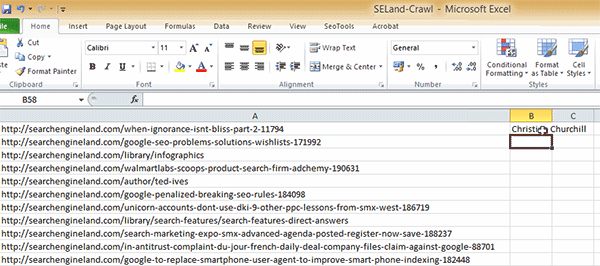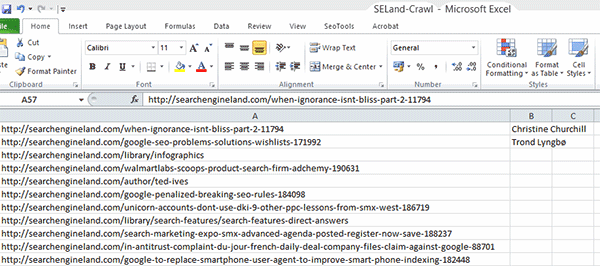
Passo 4: Na célula B2, adicione a seguinte fórmula:
=XPathOnUrl(A2,"//*[@id='leftCol']/div[2]/p/span/a")
Apenas para explicar essa fórmula, a função XPathOnUrl permite que você use o código XPath diretamente (ou seja, direto no plugin SEO Tools instalado; não vai funcionar sem ele). O primeiro elemento da função especifica qual URL vamos analisar. Eu selecionei a célula A2, que contém a URL da varredura (crawl) feita no Screaming Frog (de forma alternativa, você pode apenas digitar a URL, mas tenha certeza de que vai colocar entre aspas).
Finalmente, a última parte da função é o código XPath que reunimos. Uma coisa a observar é que você precisa remover as aspas duplas do código e substitui-las por aspas simples. Neste exemplo, me refiro à seção “leftCol”, que mudei para ‘leftCol’ – se você não fizer isso, o Excel não vai ler a fórmula corretamente.
Ao apertar o enter, pode haver alguns segundos de delay enquanto o plugin SEO Tools varre a página, e então ele vai retornar um resultado. É importante falar que, neste exemplo que dei acima, estamos procurando por nomes de autores em páginas de artigos, então se você tentar rodar isso em uma URL que não for de artigo (como na homepage), vai gerar um erro.
A quem interessar, o próprio código do XPath trabalha começando do início do código da URL especificada e seguindo as instruções delineadas para encontrar elementos da página e resultados. Então, para o seguinte código:
//*[@id='leftCol']/div[2]/p/span/a
Estamos dizendo para que ele procure por qualquer elemento (//*) que tenha uma id de leftCol (id@=’leftCol’) e então vá até a segunda tag div após isso (div[2]), seguindo por uma tag p, uma span e, finalmente, uma tag a (/p/span/a). O resultado retornado deve ser o texto dentro dessa tag a.
Não se preocupe se você não entendeu isso, mas, se entendeu, vai te ajudar a criar seu próprio XPath. Por exemplo, se você quer pegar o resultado da saída de uma tag a que tem um rel=author anexado (outra ótima forma de encontrar autores de páginas), então você pode usar um XPath que se pareça com isto:
//a[@rel='author']
Ou então uma fórmula do Excel que seja algo assim:
=XPathOnUrl(A2,"//a[@rel='author']")
Quando você tiver criado a fórmula, pode usá-la em um grande número de URLs de uma vez. Isso é um enorme poupador de tempo, já que você teria que ir manualmente em cada site e copiar/colar cada autor para obter o mesmo resultado, se não fizer a raspagem. Eu não preciso explicar o tanto de tempo que isso levaria.
Agora que já expliquei o básico, vamos a algumas outras formas de como usar a raspagem de dados…
2. Encontrando detalhes extras nas páginas de autores
Então, nós encontramos a listagem com os nomes de autores, o que é ótimo, mas para realmente obter algo dali é preciso mais do que dados. Novamente, isso pode geralmente ser obtido do site que você está analisando.
A maioria dos sites/blogs/publicações que listam os nomes dos autores dos artigos terá, na realidade, páginas individuais para autores. Novamente vou usar o Search Engine Land como exemplo – se você clicar no meu nome, no topo desta página, vai ser levado para uma página com detalhes sobre mim, como perfis nas redes sociais, e-mail, outros artigos publicados etc. Esse é o tipo de dado que queremos coletar porque oferece um ponto de contato com o autor que quero alcançar.
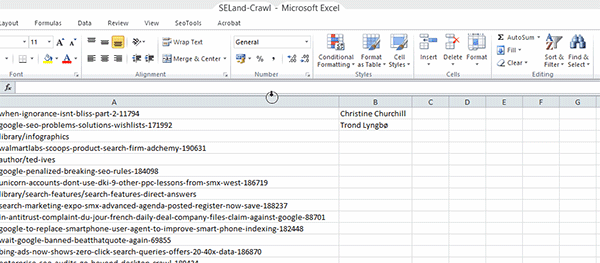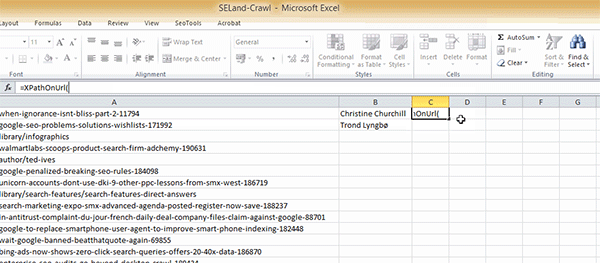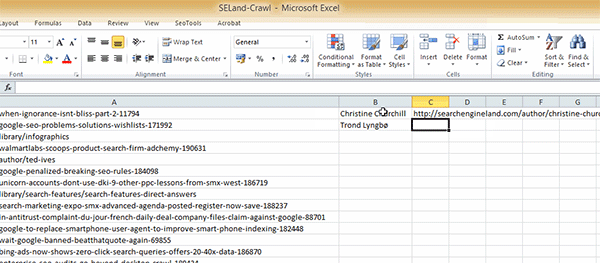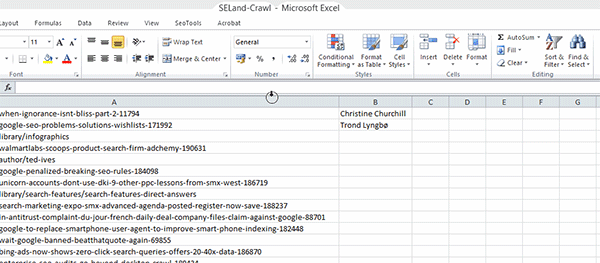
Passo 1: Primeiro, é necessário pegar a URL do perfil do autor, para raspar os detalhes extras. Para isso, use a mesma abordagem de encontrar o nome do autor, mas com uma pequena adição na fórmula:
=XPathOnUrl(A2,"//a[@rel='author']", <strong>"href"</strong>)
A adição da parte do “href” na fórmula vai extrair a saída do atributo href do atag. De acordo com Lehamn, isso vai resultar no hiperlink anexado ao nome do autor e retornará a URL como resultado.
Passo 02: Agora que já temos as URLs das páginas de autor, você pode buscar os perfis de redes sociais deles. Em vez de fazer o scraping na URL do artigo, vamos usar a URL do perfil.
Da mesma forma como na última vez, vamos encontrar o código XPath para obter os links de Twitter, Google+ e Linkedin. Para isso, abra o Chrome e vá até o final da página de perfil do autor, clique com o botão direito do mouse no link do Twitter e selecione “inspecionar elemento”.
Feito isso, vá até a linha de código marcada, clique com o botão direito e selecione “Copiar XPath”.
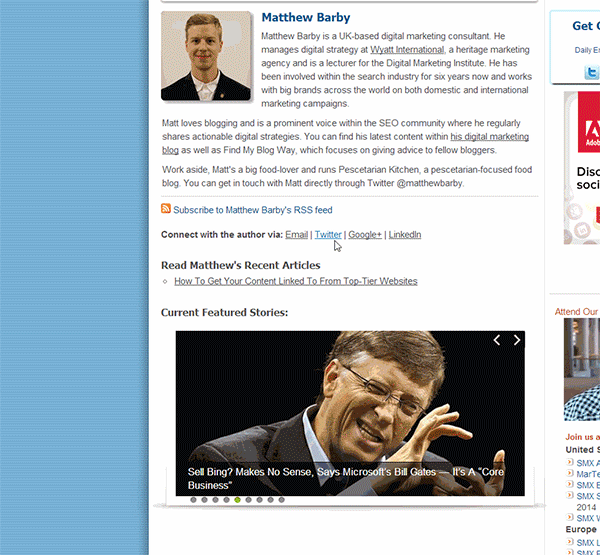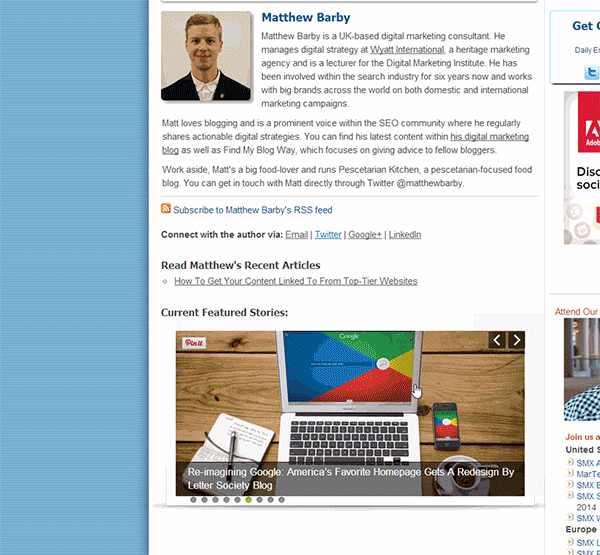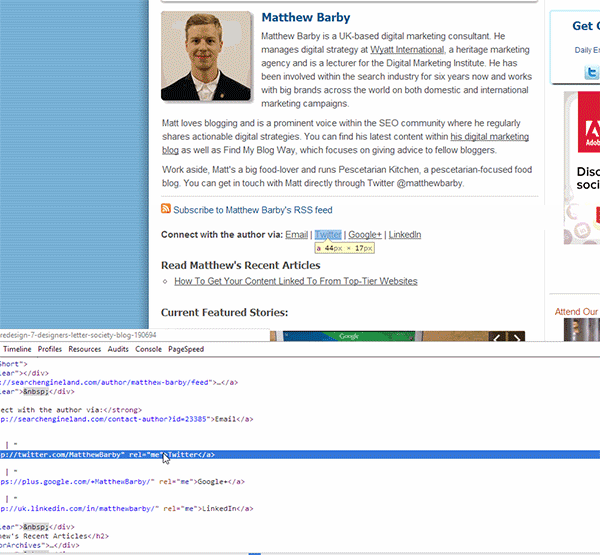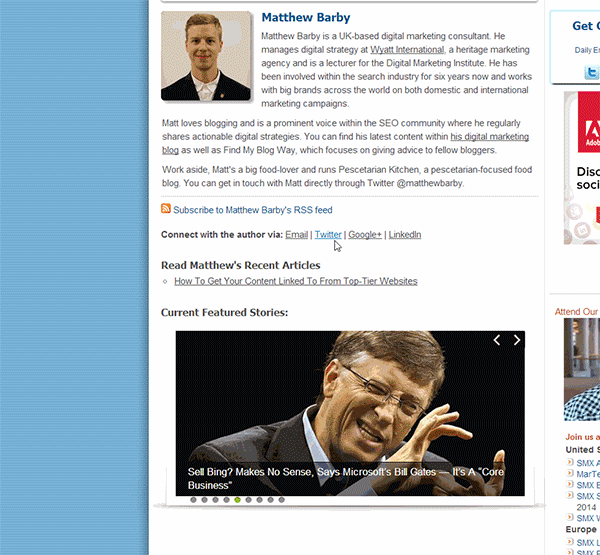
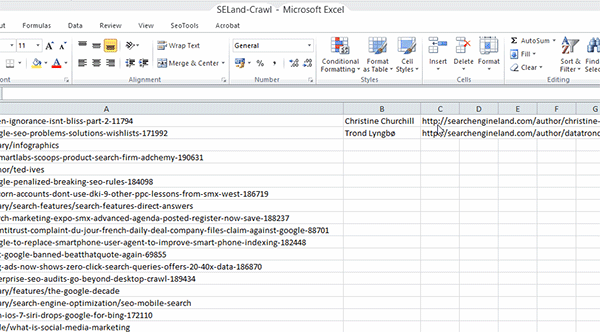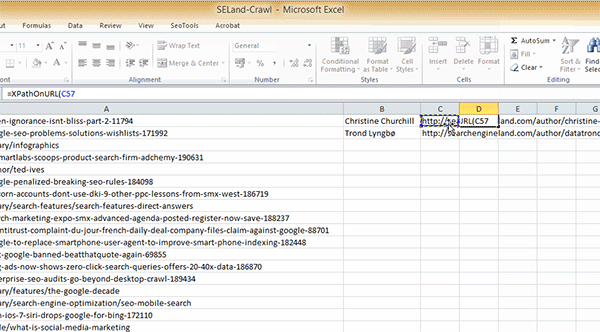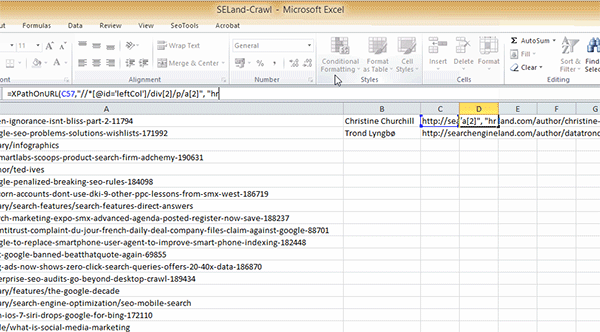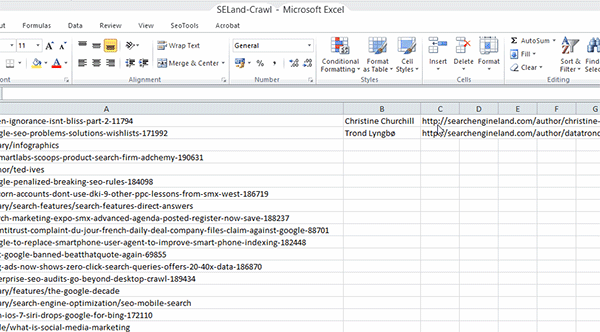
Passo 03: Finalmente, abra sua planilha Excel e adicione a seguinte fórmula (usando o XPath que você copiou):
=XPathOnUrl(C2,"//*[@id='leftCol']/div[2]/p/a[2]", "href")
Lembre que isso é o código para fazer a raspagem no Search Engine Land, então se você fizer isso em outro site, é quase certeza de que vai ser diferente. Algo importante de ressaltar é que eu selecionei a célula C2, que contém a URL da página de perfil de autor, e não apenas a página de artigo. Da mesma forma, você vai notar que eu incluí “href” no final porque queremos a URL do Twitter em si, e não apenas as palavras “Twitter”.
Você pode repetir esse mesmo processo para pegar links do Google+ e do LinkedIn e adicionar à sua planilha. Espero que você já esteja começando a ver o valor nesse processo, e como isso pode ser usado para adquirir mais inteligência no processo para todos os tipos de atividades online, não apenas suas campanhas de SEO e mídias sociais.
3. Obtendo as quantidades de seguidores nas redes sociais
Agora que já temos as contas em redes sociais dos autores, faz sentido saber quantos seguidores eles têm, de forma que se faça um ranking baseado na influência deles, em sua planilha no Excel.
Aqui estão as fórmulas XPath que você pode colocar diretamente no Excel para cada rede social e pegar os números de seguidores. Tudo o que você tem que fazer é substituir o texto INSERT SOCIAL PROFILE URL com a célula de referência à URL do Google+ ou do LinkedIn:
Google+:
=XPathOnUrl(<strong>INSERTGOOGLEPROFILEURL</strong>,"//span[@class='BOfSxb']")
LinkedIn:
=XPathOnUrl(<strong>INSERTLINKEDINURL</strong>,"//dd[@class='overview-connections']/p/strong")
***
Na próxima parte, veremos as duas formas restantes de realizar a raspagem de dados.
***
Este artigo é uma republicação feita com permissão. Moz não tem qualquer afiliação com este site. O original está em http://moz.com/blog/a-content-marketers-guide-to-data-scraping

De 0 a 10, o quanto você recomendaria este artigo para um amigo?