

Este artigo compara os tempos de execução de operações da árvore autobalanceada em C++ vs Haskell. Em particular, nós inserimos 713 mil sequências de um arquivo em uma árvore autobalanceada. Esta é uma operação O ( n log n ). Mas queremos investigar como o fator constante se parece em diferentes situações.
Instalação experimental: todo o código para estes testes está disponível no repositório do GitHub. A árvore autobalanceada em C++ foi criada em um curso de estruturas de dados que fiz recentemente, e a árvore autobalanceada em Haskell é originada a partir da biblioteca Haskell Data.Tree.AVL. Além disso, o código Haskell armazena strings como ByteString s, porque são muito mais eficientes do que a notoriamente lenta String. Para ver como o tempo de execução é afetado por arquivos de tamanhos diferentes, o arquivo foi dividido primeiramente em 10 segmentos. O primeiro segmento tem 71.300 palavras, o segundo, 71300 * 2 palavras, e assim por diante. Tanto o C++ quanto o Haskell são programas compilados com o parâmetro -O2 para otimização. O teste em cada segmento é a média do tempo de execução de três ensaios separados.
Eis os resultados obtidos:
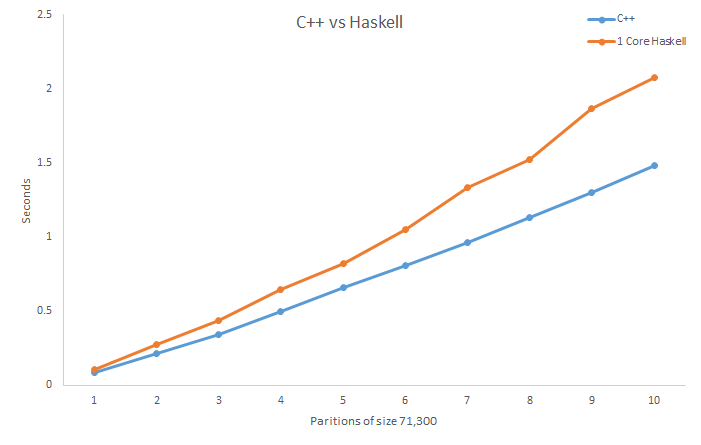
O C++ é um pouco mais rápido do que o Haskell na última partição para este teste.
Acredito que isso é devido ao fato de o Haskell operar sobre dados imutáveis. Cada vez que um novo elemento está para ser inserido dentro da árvore autobalanceada em Haskell, novos nós pais devem ser criados, porque os nós pais antigos não podem ser alterados, e isso cria uma certa sobrecarga. O C++, por outro lado, não tem dados mutáveis e pode simplesmente mudar o nó de um nó pai para outro. Isso é mais rápido do que fazer uma cópia totalmente nova como o código Haskell faz.
Existe uma maneira fácil de acelerar o nosso código Haskell?
Há uma biblioteca Haskell chamada parallel que faz computações paralelas realmente convenientes. Vamos tentar acelerar o nosso programa com essa biblioteca.
Você pode pensar que é injusto comparar o Haskell multithread com o C++, que não é multithread. E você está absolutamente certo! Mas vamos ser honestos, trabalhar manualmente com pthreads em C++ é uma grande dor de cabeça, mas paralelismo em Haskell é super fácil.
Antes de olhar para os resultados, vamos olhar para o código paralelizado. O que fazemos é criar quatro árvores, cada uma com uma parte do conjunto de strings. Então, chamamos par sobre as árvores para que o código seja paralelizado. Depois, os nós das árvores são unidos para torná-los uma única árvore. Finalmente, temos o que chamamos de deepseq de modo que o código seja avaliado.
{-# LANGUAGE TemplateHaskell #-}
import Control.DeepSeq.TH
import Control.Concurrent
import Data.Tree.AVL as A
import Data.COrdering
import System.CPUTime
import qualified Data.ByteString.Char8 as B
import Control.DeepSeq
import Data.List.Split
import System.Environment
import Control.Parallel
$(deriveNFData ''AVL)
-- Inserts elements from list into AVL tree
load :: AVL B.ByteString -> [B.ByteString] -> AVL B.ByteString
load t [] = t
load t (x:xs) = A.push (fstCC x) x (load t xs)
main = do
args <- getArgs
contents <- fmap B.lines $ B.readFile $ args !! 0
let l = splitEvery (length contents `div` 4) contents
deepseq contents $ deepseq l $ return ()
start <- getCPUTime
-- Loading the tree with the subpartitions
let t1 = load empty $ l !! 0
let t2 = load empty $ l !! 1
let t3 = load empty $ l !! 2
let t4 = load empty $ l !! 3
let p = par t1 $ par t2 $ par t3 t4
-- Calling union to combine the trees
let b = union fstCC t1 t2
let t = union fstCC t3 t4
let bt = union fstCC b t
let bt' = par b $ par t bt
deepseq p $ deepseq bt' $ return ()
end <- getCPUTime
n <- getNumCapabilities
let diff = ((fromIntegral (end-start)) / (10^12) / fromIntegral n)
putStrLn $ show diff
Ótimo, então agora que o código Haskell foi paralelizado, podemos compilar e executar o programa novamente para ver a diferença. Para compilar para paralelismo, devemos usar alguns sinalizadores especiais.
ghc –O2 filename -rtsopts –threaded
E para executar o programa ( -N4 refere-se ao número de núcleos).
./filename +RTS –N4
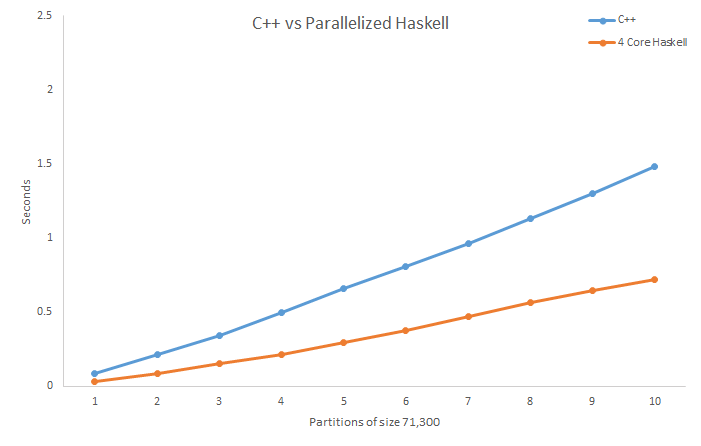
O Haskell agora obtém melhores tempos de execução do que o C ++.
Agora que sabemos que o Haskell é capaz de aumentar sua velocidade através do paralelismo, seria interessante ver como o tempo de execução é afetado pelo grau de paralelismo.
De acordo com a lei de Amdahl, um programa que está 100% paralelizado terá uma velocidade proporcional com base no número de threads de execução. Por exemplo, se um programa que está 100% paralelizado leva 2 segundos para ser executado em uma thread, então ele deve levar um segundo para executar usando duas threads. O código usado para o nosso teste, no entanto, não é 100% paralelizado, já que há uma operação de união realizada para combinar as árvores criadas pelos segmentos separados. A união das árvores é um O(n), enquanto a operação de inserção das strings na árvore autobalanceada é uma operação O (n logn/p), onde p é o número de threads. Portanto, o tempo de execução para o nosso teste deve ser O(nlogn/p+ n).
Aqui está um gráfico que mostra o tempo de execução da operação no maior conjunto (713 mil strings) através de aumento dos níveis de paralelismo.
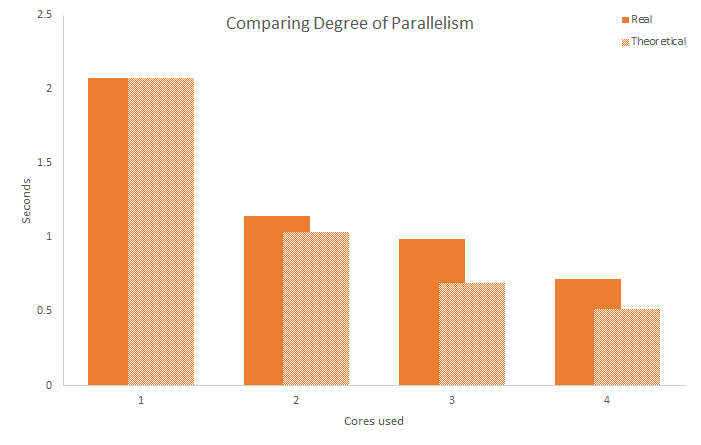
Dando uma olhada nos resultados, podemos ver que a melhoria no tempo de execução não se encaixa no modelo teórico paralelizado 100%, mas segue esse conceito de alguma forma. Em vez do tempo de execução de 2 núcleos sendo 50% do tempo de execução de 1 núcleo, o tempo de execução de 2 núcleos é 56% do tempo de execução de 1 núcleo, com a diminuição da eficiência conforme o número de núcleos aumenta. No entanto, está claro que há melhorias significativas na velocidade através da utilização de mais núcleos do processador e que o paralelismo é uma maneira fácil de obter velocidades de tempo de execução melhores e experiências com pouco esforço.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em https://izbicki.me/blog/avl-tree-runtimes-c%2B%2B-vs-haskell.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?