

Computadores mais antigos com discos e ventoinhas cada vez mais têm sido escondidos em centros de dados, blindados pela nuvem. Dessa forma, os usuários não notam quanto calor produzem ou quanto barulho eles fazem. E novos computadores como smartphones e tablets permeiam muitas áreas da vida atualmente: afinal, são dispositivos móveis, silenciosos e eficientes em termos de energia.
Uma razão pela qual são mais eficientes vem do fato de que sistemas de armazenamento embarcado utilizam chips em vez de discos rotativos. Memória Flash em estado sólido não possui partes móveis e é, portanto, muito robusta por não possuir estresse mecânico. Além disso, a memória sem disco acessa os dados desejados mais rapidamente por não exigir um cabeçote em movimento.
Um dispositivo sem disco também produz menos calor, tornando desnecessário o barulho provocado pela vetoinha. Neste artigo, descreveremos alguns sistemas de arquivos Linux e ferramentas que operam com uma enorme variedade de dispositivos de armazenamento Flash suportados pelo Linux.
Armazenamento Flash
O armazenamento Flash, também chamado de “estado sólido” (solid state), possui muitas vantagens em relação ao armazenamento rotativo (rotating storage). Em primeiro lugar, a ausência de peças mecânicas e em movimento elimina o ruído, aumenta a resistência e segurança a choques e vibrações, e reduz a dissipação de calor e consumo de energia. Segundo, o acesso aleatório a dados é muito mais rápido, pois já não é preciso mover um cabeçote de disco para o local correto no dispositivo, o que pode levar alguns milissegundos.

O Flash também tem suas deficiências. Primeiro, pelo mesmo preço, temos apenas um décimo da capacidade de armazenamento. Segundo, escrever armazenamento Flash possui restrições especiais; não podemos escrever para o mesmo local de um bloco Flash várias vezes sem apagar todo o bloco, chamado de “bloco de apagar” (erase block). Essa restrição também pode fazer com que a velocidade de escrita seja muito menor que a de leitura. Terceiro, os blocos Flash podem suportar apenas um número limitado de erases – de alguns milhares de chips NAND mais densos a um milhão, no máximo. Hardware e software, portanto, precisam espalhar as operações de escrita em um processo conhecido como “nivelamento de desgaste” (wear leveling).
NAND/NOR
A memória Flash NOR (Not OR), que nomeia as portas usadas no chip, foi o primeiro tipo de armazenamento Flash inventado. O NOR é conveniente, pois a CPU pode acessar qualquer byte diretamente e em ordem aleatória. Desse modo, o processador pode executar o código diretamente da NOR, permitindo que seja utilizado em bootloaders, e não necessita ser copiado para a RAM antes de ser executado.
O tipo mais popular de armazenamento é a memória Flash NAND (Not AND) (figura 1), que oferece maior capacidade de armazenamento ao menor preço. A desvantagem é que, como um dispositivo externo, o armazenamento NAND está conectado via controlador, através do qual é possível acessar os dados. A CPU não pode executar código da NAND sem copiar o código para a memória RAM primeiro. Outra restrição é que os dispositivos Flash NAND podem possuir blocos defeituosos (bad blocks) fora da caixa, exigindo soluções de hardware ou software que funcionam em torno dessa limitação durante a operação.
Dois tipos de armazenamento Flash NAND estão disponíveis hoje. O primeiro tipo emula um bloco padrão de interface e contém um hardware “Flash Translation Layer” (camada de tradução Flash) que cuida de apagar blocos e implementar nivelamento de desgaste, assim como o gerenciamento de blocos defeituosos. Dispositivos desse tipo incluem drives USB Flash, cartões de mídia, cartões multimídia embutidos (eMMCs), e discos de estado sólido (da sigla SSDs, de solid state disks). O sistema operacional não tem controle sobre a forma como são geridos os setores Flash, pois só considera um dispositivo emulado de bloco.
Embora essa abordagem reduza a complexidade do software do lado do sistema operacional, os fabricantes de hardware costumam manter em segredo os algoritmos da camada de tradução Flash, deixando os desenvolvedores de sistemas sem alternativas para verificar e ajustar esses algoritmos ou corrigir implementações pobres.
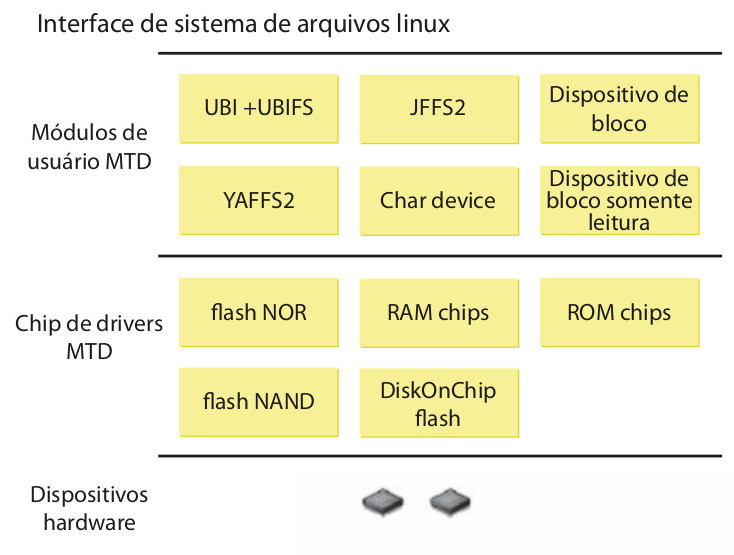
O segundo tipo de memória NAND é a raw Flash. O sistema operacional tem acesso ao controlador de Flash e pode gerenciar diretamente seus blocos. O raw Flash pode usar um “block erase count” para determinar com qual frequência um bloco tem sido sobrescrito. O kernel Linux implementa um subsistema Memory Technology Device (MTD), que permite o acesso e controle de vários tipos de dispositivos Flash com uma interface comum (figura 2).
Partições
Acesso bruto (raw access) significa que nenhum sistema de arquivo é necessário, a menos que o usuário deseje armazenar muitos arquivos; um único e grande arquivo binário é suficiente para alguns aplicativos. Dispositivos MTD geralmente são particionados para definir áreas com fins específicos, como o gerenciador de inicialização (bootloader) ou o sistema de arquivos raiz. Acessar as partições e o armazenamento raw flash é algo semelhante a acessar dispositivos brutos do bloco (raw block devices) através de arquivos de dispositivos (por exemplo, todo o dispositivo com /dev/sda ou partições com /dev/sda1, /dev/sda2 etc.
Declarar partições somente leitura (da sigla RO, de read-only) pode proteger o sistema contra erros e tentativas de modificação não autorizadas. Observe também que as partições não podem ser ignoradas, acessando todo o dispositivo como compensação, uma vez que o Linux não possui nenhum arquivo de dispositivo para esse tipo de acesso.
A figura 3 mostra um esquema de particionamento típico. Em contraste com os discos rígidos, a tabela de partição não é salva no ambiente MTD – um local inseguro por conta dos blocos potencialmente ruins. Em vez disso, uma estrutura de dados no kernel Linux define as partições.
A listagem 1 mostra o excerto relevante do arquivo arch/arm/mach‐OMAP2/board-OMAP3Beagle.c, que define as partições para o Flash NAND na BeagleBoard. Felizmente, podemos substituir estas configurações padrão sem necessidade de recompilar o kernel. Para identificar o nome do dispositivo MTD, percorra as mensagens de inicialização do kernel. Neste exemplo de BeagleBoard, a listagem 2 mostra que o nome do dispositivo NAND é omap2-nand.0.
Logo que o nome do dispositivo é conhecido, o parâmetro de boot mtdparts passa no particionamento com (tudo em uma única linha):
mtdparts=omap2‐nand.0:128k(X‐Loader)ro,256k(U‐Boot)ro,128k(Environment),4m(Kernel)ro,32m(RootFS)ro,‐(Data)
O código acima define seis partições:
» Primeiro estágio do bootloader (128KB, RO) » Bootloader U-Boot (256KB, RO) » Variáveis de ambiente U-Boot (128KB) » Kernel Linux (4MB, RO) » Sistema de arquivos raiz (16MB, RO) » Dados (espaço de armazenamento restante).
O tamanho da partição deve ser um múltiplo do tamanho do erase block, que pode ser encontrado no sistema de destino em /sys/class/mtd/mtdx/erasesize. Os tamanhos das partições recém-criadas, que o usuário pode ver em /proc/mtd estão em hexadecimal (listagem 3).
Nomes de arquivos para partições de dispositivo de bloco se referem ao nome completo do dispositivo (por exemplo, /dev/sda1 para a primeira partição /dev/sda), mas note que as partições MTD são mostradas como dispositivos MTD independentes; portanto, o mtd1 poderia ser a segunda partição do primeiro dispositivo Flash ou a primeira partição do segundo dispositivo Flash. Não é possível perceber a diferença de nomes dos dispositivos.
A partição "Environment” é onde as variáveis de ambiente U-Boot bootloader são armazenadas. Essas variáveis podem ser alteradas a partir do U-Boot Shell, mas também a partir do Linux, piscando (flashing) uma nova imagem para a partição. Os desenvolvedores da Free Electrons têm contribuído de forma bastante útil para gerar tal imagem.
Manipulação de dispositivos MTD
Os dispositivos MTD podem ser endereçados através de duas interfaces. A primeira utiliza o identificador (letra) do dispositivo dev/mtd//N// (onde N é o número do dispositivo MTD) e o driver mtdchar. Em particular, esse identificador fornece os comandos ioctl, que são geralmente utilizados por mtd-utils para manipular e apagar blocos de um dispositivo MTD. A segunda interface fornece o dispositivo de bloco dev/mtdblock//N// e o driver mtdblock. Esse dispositivo é usado principalmente para montar sistemas de arquivos MTD, como JFFS2 e YAFFS2, pois o comando mount só funciona com dispositivos de bloco.
Embora possamos ser tentados a usar esse dispositivo para gravar no MTD, o driver correspondente não é sofisticado o suficiente para uso em produção por não suportar nivelamento de desgaste; uma série de gravações para a mesma parte do dispositivo de bloco poderia danificar muito rapidamente os correspondentes erase blocks. Pior, se copiarmos uma imagem de sistema de arquivos para /dev/mtdblock//N//, o sistema de arquivos poderia ser corrompido, pois os blocos danificados não são levados em conta. Portanto, a maneira ideal de manipular dispositivos MTD é através do identificador de interface (character interface) e mtd-utils.
Os comandos mais importantes são:
» mtdinfo: informações detalhadas sobre um dispositivo MTD » flash_eraseall: apaga por completo um dado dispositivo MTD » flashcp: escreve para Flash NOR » nandwrite: escreva para Flash NAND » Utilitários UBI (veja o tópico “UBI e UIFS”) » mkfs.jffs2, mkfs.ubifs: ferramentas de criação de imagem de sistema de arquivo Flash.
Esses comandos estão disponíveis através do pacote mtd‐utils em distribuições GNU/Linux e também podem ser compilados de forma cruzada (cross-compiled), a partir da fonte por sistemas embarcados Linux, tais como o BuildRoot e o OpenEmbedded. Simples implementações dos comandos mais comuns também estão disponíveis no BusyBox, tornando muito mais fácil de fazer a compilação cruzada em sistemas embarcados menos complexos.
JFFS2
O Journaling Flash File System versão 2 (JFFS2), que foi adicionado ao kernel Linux em 2001, é um sistema de arquivos muito popular para o armazenamento Flash. Como é esperado para um sistema de arquivos Flash, ele implementa a detecção e a gestão do bloco danificado, bem como o nivelamento de desgaste. Também é projetado para ficar em um estado consistente após falhas abruptas de energia e quebras do sistema. Por último, mas não menos importante, o JFFS2 também armazena dados compactados.
Diversos esquemas de compressão estão disponíveis de acordo com o que é mais importante: desempenho para ler/escrever ou taxa de compressão. Por exemplo, o zlib comprime melhor que o lzo, mas também é muito mais lento.
A implementação de arquivos de sistemas em Flash possui restrições especiais. Para modificar um arquivo existente, não podemos simplesmente copiar os blocos correspondentes para a RAM, apagá-los e piscar (flash) os blocos com a nova versão. Primeiro, uma falha de energia durante esse procedimento poderia causar perda de dados irrecuperáveis. Segundo, podemos rapidamente desgastar blocos específicos, fazendo várias atualizações para o mesmo arquivo.
Uma alternativa seria escrever os novos dados para um novo bloco e atualizar os indicadores (pointers) para os dados antigos. Contudo, isso implicaria outra escrita, que poderia provocar outras modificações até que a referência root fosse alcançada.
O JFFS2 resolve esses problemas com uma abordagem de log estruturado. Cada arquivo é mapeado para um nó com dados e metadados, e cada nó tem um número de versão associado. Em vez de fazer alterações locais, a ideia é escrever uma versão mais recente do nó em outra parte do erase block com espaço livre. Isso simplifica as operações de escrita, mas complica as operações de leitura, pois o sistema de arquivos precisa localizar o nó mais recente.

Para otimizar o desempenho, o JFFS2 mantém um mapa de memória dos nós mais recentes para cada arquivo; no momento da montagem, digitaliza os nós, cria e armazena o mapa. Uma vez que o tempo de montagem do JFFS2 é proporcional ao número de nós, sistemas embarcados utilizando JFFS2 em grandes partições Flash poderão incorrer em enormes sanções no momento de inicialização. Felizmente, foi adicionada uma opção do kernel CONFIG_JFFS2_SUMMARY, que confere ao Linux o armazenamento do mapa entre as ações de montagem no dispositivo Flash, reduzindo drasticamente o tempo de montagem. No entanto, essa opção não é ativada por padrão.
Nós mais velhos devem ser recuperados em algum ponto para manter o espaço livre para novas escritas. Um nó é criado como “válido” e é considerado “obsoleto” quando uma nova versão é criada. O JFFS2 gerencia três tipos de blocos Flash:
» Blocos limpos, que contêm apenas nós válidos » Blocos sujos, que contêm pelo menos um nó obsoleto » Blocos livres, que não contêm nenhum nó.
O JFFS2 executa um coletor de lixo em segundo plano, que recicla blocos sujos transformando-os em blocos livres. Faz isso através do recolhimento de todos os nós válidos em um bloco sujo e os copia para um bloco limpo (com o espaço que restar) ou para um bloco livre. O antigo bloco sujo é então apagado e marcado como livre. Para fazer todos os erase blocks participarem do nivelamento de desgaste, o coletor de lixo ocasionalmente também consome blocos limpos.
Há duas maneiras de criar uma partição JFFS2. A primeira é apagar a partição, formatá-la para JFFS2, e depois montá-la:
flash_eraseall ‐j /dev/mtd2 mount ‐t jffs2 /dev/mtdblock2 /mnt/flash
o flash_eraseall e o -j apagam a partição do Flash e os formata para JFFS2. A segunda opção é geralmente uma melhor combinação para o fluxo integrado de trabalho do desenvolvedor pois cria a imagem JFFS2 no computador desktop e escreve a imagem na partição. Para criar a imagem, use o comando mkfs.jffs2 fornecido pelo mtd-utils, mas não se confunda com seu nome: ao contrário de alguns outros comandos mkfs, ele não cria um sistema de arquivos, mas uma imagem de sistema de arquivos.
O comando seguinte cria um arquivo de imagem com o nome rootfs.jffs2. Para este exemplo, vamos assumir que o tamanho do erase block é de 256MB.
mkfs.jffs2 ‐‐pad ‐‐no‐cleanmarkers ‐‐eraseblock=256 ‐d rootfs/ ‐o rootfs.jffs2
O parâmetro -d indica o diretório com o conteúdo desejado para o sistema de arquivos e o --pad cria uma imagem que é de tamanho múltiplo ao do erase block; o ‐‐no‐cleanmarkers só deve ser utilizado para o Flash NAND. Para formatar a partição alvo e escrever a imagem, utilize:
flash_eraseall /dev/mtd2 nandwrite ‐p /dev/mtd2 rootfs.jffs2
Se a imagem é menor que a partição, o JFFS2 ainda pode utilizar todo o espaço posteriormente, fornecido pela partição que foi completamente apagada anteriormente. Para preparar dispositivos de produção, é muito mais conveniente escrever as partições MTD do bootloader, utilizando um comando que pode lidar com os blocos danificados sem inicializar o Linux. Dessa forma, utilitários de desenvolvimento como o flash_eraseall não precisam estar na raiz do sistema de arquivos Linux, que é outra razão pela qual as imagens do sistema de arquivos são úteis.
Normalmente, baixamos a imagem do sistema de arquivos para a memória RAM e copiamos a imagem para o Flash. Quando fazemos isso, apenas temos que nos certificar de haver copiado o tamanho exato da imagem. Com as imagens JFFS2, se copiarmos mais bytes da RAM para o Flash, acabaremos escrevendo bytes aleatórios no final da imagem, o que irá corromper o sistema de arquivos.
YAFFS2
Uma alternativa ao JFFS2 é o YAFFS2 (sigla para Yet Another Flash Filesystem), encontrado em smartphones com as primeiras versões do Android. O YAFFS2 não usa compressão, mas apresenta tempos de montagem muito mais rápidos, bem como melhor desempenho de escrita e leitura. O código é duplamente licenciado, sob o GPL e uma licença proprietária (ou seja, GPL para uso no kernel Linux e a licença para sistemas operacionais proprietários). A receita da licença proprietária tem financiado seu desenvolvimento.
O YAFFS2 é menos popular que o JFFS2, provavelmente por não fazer parte do planejamento do kernel Linux. Em vez disso, está disponível como um patch externo com um conjunto de scripts auxiliares. Um esforço foi feito para tê-lo na linha de frente cerca de um ano atrás, mas essa tentativa falhou, pois as alterações solicitadas pelos mantenedores do kernel teriam quebrado a portabilidade para outros sistemas operacionais.
Depois de fazer o patch do kernel, o usuário pode criar um novo sistema de arquivos YAFFS2 com o comando:
flash_eraseall /dev/mtd2
O sistema de arquivos é formatado automaticamente na primeira montagem:
mount ‐t yaffs2 /dev/mtdblock2/mnt/flash
Outra opção consiste em utilizar a ferramenta mkyaffs, dos utilitários YAFFS2.
UBI e UBIFS
O JFFS2 e o YAFFS2 têm um problema em comum: eles implementam o nivelamento de desgaste, restringindo-o a partições individuais. No entanto, os níveis de utilização podem ser muito diferentes. Partições são montadas muitas vezes no modo somente leitura, enquanto as partições de dados estão expostas a muitas escritas – razão pela qual são conhecidas como partições “quentes”. Para evitar o desgaste de partições quentes muito rapidamente, todas as áreas da memória Flash precisam participar do nivelamento de desgaste. Isso é exatamente o que o projeto Unsorted Block Images (UBI) oferece.
O UBI é uma camada acima do MTD que gerencia erase blocks e bad blocks e implementa o nivelamento de desgaste, tirando essas tarefas dos ombros do sistema de arquivos. O UBI também suporta partições ou volumes flexíveis, que podem ser criados e redimensionados dinamicamente, parecido com o que o Logical Volume Manager opera para dispositivos de bloco.
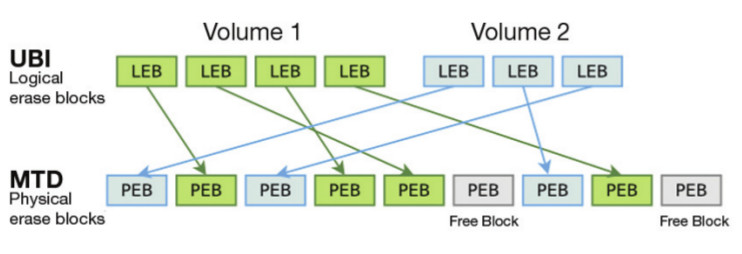
O UBI implementa o Logical Erase Blocks (LEBs), que o mapeia para o Physical Erase Blocks (PEBs) (figura 4). Camadas superiores, tais como sistemas de arquivos, apenas visualizam os LEBs. Se uma LEB visualiza muita ação, o UBI pode trocar os ponteiros, substituindo o PEB “quente” por um “frio”. Esse mecanismo requer alguns PEBs livres para trabalhar de forma eficiente, e a sobrecarga faz a UBI menos apropriada para dispositivos menores com apenas alguns megabytes de espaço.
Um sistema de arquivos para UBI, chamado UBIFS, foi criado pelo projeto MTD Linux como sucessor do JFFS2. O UBIFS suporta a compressão e apresenta desempenhos de mount, escrita e leitura muito melhores. No Linux, o UBI e o UBIFS são iniciados com alguns comandos. Primeiro, o root precisa montar o diretório do dispositivo como um pseudo sistema de arquivos devtmpfs. O comando
ubiformat /dev/mtd1
exclui uma partição Flash sem precisar reiniciar a contagem erase (erase count). Para habilitar o UBI na partição MTD, digite:
ubiattach /dev/ubi_ctrl ‐m 1
Isso cria uma nova identidade (letra) para o dispositivo, /dev/ubi0. Agora podemos criar um ou vários volumes sobre o dispositivo,
ubimkvol /dev/ubi0 ‐N test ‐s 116MiB ubimkvol /dev/ubi0 ‐N test ‐m
onde o -m é o tamanho máximo disponível. Para montar um sistema de arquivos UBIFS vazio no novo volume de teste, insira
mount ‐t ubifs ubi0:test /mnt/flash
e para popular o sistema de arquivos com os arquivos. Uma abordagem alternativa é primeiro criar uma imagem do sistema de arquivos UBIFS com o comando mkfs.ubifs e copiar a imagem com ubiupdatevol. Outra abordagem é criar uma imagem de todo o espaço UBI, que pode ser escrito do bootloader com o comando que pode lidar com blocos danificados (bad blocks). Para fazer isso, primeiro crie um arquivo ubi.ini descrevendo o espaço UBI, seus volumes e seus conteúdos. Um exemplo é mostrado na listagem 4.
Esse arquivo descreve quais volumes devem ser criados, juntamente com seus tamanhos. A imagem UBI é criada com o comando
ubinize ‐o ubi.img ‐p 128KiB ‐m 4096 ubi.ini
que também especifica erase blocks físicos 128KB e um tamanho mínimo de I/O de 4096 bytes. Para transferir a imagem, use uma ferramenta bootloader que possa lidar com os bad blocks. Além disso, a linha de comando do kernel precisa da opção ubi.mtd=1 (equivalente ao ubiattach).
Se quiser que o UBIFS controle a partição root, adicione
rootfstype=ubifs root=ubi0:rootfs
ao comando boot.
LogFS
O LogFS é outro sistema de arquivos estruturado em log para a memória Flash que possui um design inovador e tem sido parte principal do kernel Linux desde a versão 2.6.34. O inovador sistema de arquivos poderia ter influência sobre o UBIFS mas, infelizmente, mostrou-se instável, causando problemas no kernel no momento de desmontagem, quando testado pela Free Electrons. Graças à integração com o kernel Linux oficial, há boas chances de que o desenvolvedor venha a resolver esses problemas.
SquashFS
Partições somente leitura podem usar o sistema de arquivos de blocos SquashFS em dispositivos MTD. Copiar uma imagem SquashFS diretamente para o dispositivo /dev/mtdblock//N// funciona bem – afinal, não temos que nos preocupar com o nivelamento de desgaste – até encontrar bad blocks no dispositivo. Mais uma vez, o driver mtdblock não pode lidar com bad blocks, então outra solução se faz necessária.
Uma possibilidade consiste em utilizar o driver gluebi, que emula um dispositivo MTD em cima de um volume UBI. Como o UBI descarta bad blocks, o mdtblock pode agora ser usado com segurança.
Uma segunda possibilidade é usar o driver ubiblk, que implementa um dispositivo de bloco somente leitura diretamente acima da UBI. A Free Electrons apresentou o ubiblk à Linux Kernel Mailing List, mas ainda não foi considerado (mainlined). Os benchmarks mostram que o ubiblk é uma solução eficiente, por não precisar emular um dispositivo intermediário MTD.
Benchmarks
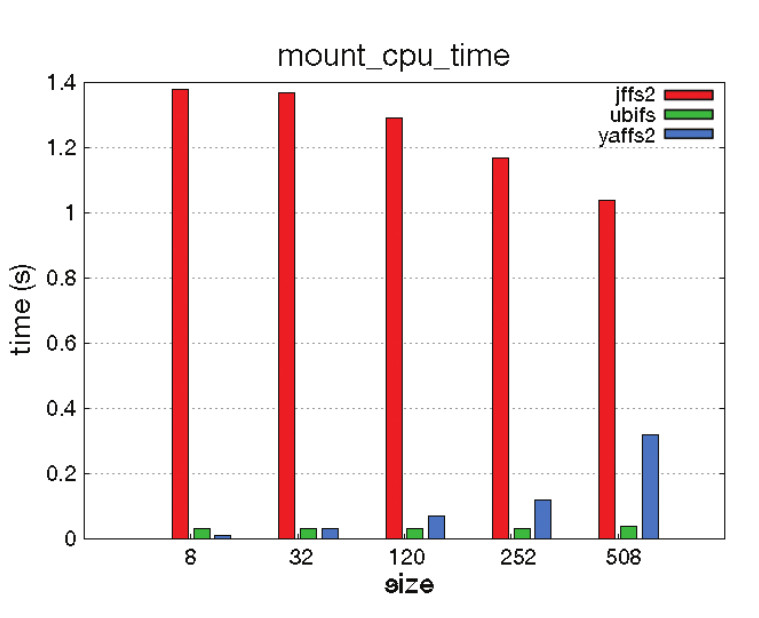
Com financiamento da Linux Foundation, a Free Electrons testou o desempenho de vários sistemas de arquivos Flash em diferentes versões do kernel. Os resultados (figura 5) estão descritos online. Em resumo, o JFFS2 teve o pior desempenho e deve ser compilado com CONFIG_SUMMARY para um tempo de inicialização aceitável. No entanto, o JFFS2 ainda é a melhor promessa para dispositivos com partições Flash pequenas que necessitam de compressão e onde o UBI teria muita sobrecarga. Essa é a razão pela qual o JFFS2 ainda está em uso no OpenWRT, uma distribuição focada principalmente em dispositivos embarcados, como gateways residenciais e roteadores, geralmente com 4MB a 16MB de armazenamento Flash.
Graças a melhorias nos últimos anos, o YAFFS2 apresenta desempenho muito bom, senão o melhor, em muitos cenários de teste. No entanto, a falta de compressão continua sendo uma desvantagem, assim como sua ausência no kernel Linux. O YAFFS2 também mostra problemas de desempenho incomuns na gestão de diretórios. O UBIFS é agora a melhor solução em termos de desempenho e espaço. A necessidade de espaço adicional será um problema somente em partições muito pequenas. A implementação também requer um pouco mais de trabalho do que os outros candidatos.
No momento da publicação deste artigo, o LogFS ainda é muito experimental para ser usado em sistemas de produção, embora possamos esperar que seus bugs sejam corrigidos com o tempo. O SquashFS exibe boa compressão e tempo de mount, assim como desempenho de leitura no Flash MTD em sistemas com partições somente leitura. A necessidade de parear o SquashFS com o UBI, no entanto, compromete o desempenho do tempo de mount. Em sistemas de arquivos de bloco, o SquashFS exibe o melhor tempo de mount, mas perde muito tempo com a UBI, o que leva a uma quantidade substancial de tempo para inicializar (a operação ubiattach).
A boa notícia é que é muito barato mudar sistemas de arquivos. Os aplicativos nem sequer notarão a diferença. Como os benchmarks mostram, podemos obter resultados de desempenho notável, dependendo do tamanho e número das partições e arquivos, da leitura e escrita padrões do sistema, e da necessidade de compressão. Tudo o que o usuário precisa fazer é tentar vários sistemas de arquivos, executar seus aplicativos e testes de sistema, e manter a solução que maximiza o desempenho do seu sistema particular.
Sovinas
A memória Flash em seu estado natural (raw) oferece aos desenvolvedores de sistemas embarcados muitas oportunidades de otimização. A tendência entre os fabricantes de hardware, no entanto, está longe da memória flexível NAND incorporada ao MMC. Essas superfícies montadas de cartões de memória usam uma interface mais parecida com a de uma placa externa. Elas escondem os detalhes dos blocos ruins e de nivelamento de desgaste do sistema operacional. Por serem muito acessíveis, provavelmente irão derrubar o Flash mais caro.
Felizmente, o eMMC não é totalmente opaco. Arnd Bergmann, desenvolvedor do kernel, escreveu uma ferramenta chamada Flashbench, que permite determinar experimentalmente as características da mídia de armazenamento, tais como o tamanho dos blocos de apagar. Com a ajuda desses resultados, podemos também otimizar os parâmetros do sistema de arquivos que estivermos utilizando. Bergmann descreve seu trabalho em um artigo online.
Conselhos finais
Algumas simples regras de ouro são necessárias para trabalhar com memória Flash, incluindo não criar uma partição swap em Flash. Sempre que possível, devemos montar partições somente leitura. Dados voláteis, tais como arquivos de log, podem ser mantidos na memória RAM, usando o pseudo sistema de arquivos tmpfs.
Listagem 1: Partições definidas no kernel
01 static struct mtd_partition omap3beagle_nand_partitions[] = {
02 /* All the partition sizes are listed in terms of NAND block size */
03 {
04 .name = "X-Loader",
05 .offset = 0,
06 .size = 4 * NAND_BLOCK_SIZE,
07 .mask_flags = MTD_WRITEABLE, /* force read‐only */
08 },
09 {
10 .name = "U‐Boot",
11 .offset = MTDPART_OFS_APPEND, /* Offset = 0x80000 */
12 .size = 15 * NAND_BLOCK_SIZE,
13 .mask_flags = MTD_WRITEABLE, /* force read‐only */
14 },
15 {
16 .name = "U‐Boot Env",
17 .offset = MTDPART_OFS_APPEND, /* Offset = 0x260000 */
18 .size = 1 * NAND_BLOCK_SIZE,
19 },
20 {
21 .name = "Kernel",
22 .offset = MTDPART_OFS_APPEND, /* Offset = 0x280000 */
23 .size = 32 * NAND_BLOCK_SIZE,
24 },
25 {
26 .name = "File System",
27 .offset = MTDPART_OFS_APPEND, /* Offset = 0x680000 */
28 .size = MTDPART_SIZ_FULL,
29 },
30 };
Listagem 2: Mensagens de inicialização
01 omap2‐nand driver initializing 02 ONFI flash detected 03 NAND device: Manufacturer ID: 0x2c, Chip ID: 0xba (Micron NAND 256MiB 1,8V 16‐bit) 04 Creating 5 MTD partitions on "omap2‐nand.0": 05 0x000000000000‐0x000000080000 : "X‐Loader" 06 0x000000080000‐0x000000260000 : "U‐Boot" 07 0x000000260000‐0x000000280000 : "U‐Boot Env" 08 0x000000280000‐0x000000680000 : " 09 0x000000680000‐0x000010000000 : "File System"
Listagem 3: /proc/mtd
01 dev: size erasesize name 02 mtd0: 00020000 00020000 "X‐Loader" 03 mtd1: 00040000 00020000 "U‐Boot" 04 mtd2: 00020000 00020000 "Environment" 05 mtd3: 00400000 00020000 "Kernel" 06 mtd4: 02000000 00020000 "File System" 07 mtd5: 0dbc0000 00020000 "Data"
Listagem 4: ubi.ini
01 [RFS‐volume] 02 mode=ubi 03 image=rootfs.ubifs 04 vol_id=1 05 vol_size=30MiB 06 vol_type=dynamic 07 vol_name=rootfs 08 vol_flags=autoresize 09 vol_alignment=1
***
Artigo publicado originalmente na Linux Magazine.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?