

O Cherami é um sistema de filas de mensagens distribuído, durável, escalável e de alta disponibilidade que nós desenvolvemos na engenharia da Uber para transportar tarefas assíncronas. Nós nomeamos o sistema em homenagem a um heróico pombo-correio com a esperança de que esse sistema fosse muito resiliente e tolerante a falhas, permitindo que os componentes lógicos críticos para os negócios do Uber dependam dele para a entrega das mensagens.

Introdução
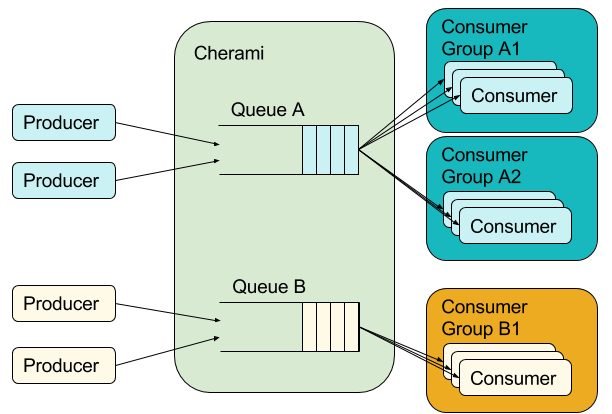
Uma fila de tarefas dissocia componentes em um sistema distribuído e permite que eles se comuniquem de maneira assíncrona. As duas partes que se comunicam podem escalar separadamente, com as funcionalidades adicionadas de aumento ou redução de carga. Em sistemas distribuídos complexos, uma fila de tarefas é essencial. O Cherami tem um papel equivalente ao do Simple Queue Service (SQS) no ecossistema da infraestrutura da Uber. Construir nosso próprio sistema traz melhor integração com nossa infraestrutura existente enquanto trata algumas necessidades de desenvolvimento únicas, como o suporte à múltiplos grupos de consumidores e maior disponibilidade, especialmente durante a partição da rede.
Os usuários do Cherami são definidos como produtores ou consumidores. Os produtores enfileiram as tarefas. Os consumidores são processos que assincronamente pegam e processam as tarefas enfileiradas. O modelo de entrega do Cherami é um padrão típico de consumidores concorrentes, onde os consumidores do mesmo grupo recebem pacotes de tarefas desmembrados (exceto em casos de falhas, que causam redistribuição). Utilizando esse modelo, o trabalho se espalha para muitos trabalhadores em paralelo. O número de trabalhadores é independente de quaisquer mecanismos de particionamento ou fragmentação internos do Cherami e podem aumentar ou diminuir simplesmente adicionando ou removendo trabalhadores. Se um trabalhador falha em realizar uma tarefa, outro pode redistribuir e tentar realizar a tarefa novamente.
O Cherami também suporta múltiplos grupos de consumidores, onde cada consumidor recebe todas as tarefas da fila. Cada grupo de consumidores é associado à uma fila de mensagens não entregues. As tarefas que excedam o máximo de tentativas de redistribuição (por exemplo, “pílulas de veneno”) chegam a essa fila para que o grupo de consumidores possa continuar com o processamento das outras mensagens. Essas funcionalidades de tratamento dos consumidores diferenciam o Cherami dos serviços de mensagens simples que normalmente são utilizados na absorção e análise de big data (Ex. Apache Kafka), e dão vantagem ao Cherami nos casos de uso de enfileiramento de tarefas.
Antes do Cherami, a Uber utilizava filas com o Celery apoiado pelo Redis para todos os casos de uso de enfileiramento de tarefas. O combo de Celery e Redis ajudou o Uber a escalar rápido, até certo ponto. As desvantagens? O Celery é somente em Python, enquanto nós estávamos apostando em Go e Java para construir serviços de backend com melhor performance. Além disso, o armazenamento do Redis é apoiado na memória, o que não é tão durável e escalável quanto precisávamos.
Precisávamos de uma solução de longo prazo para o futuro da Uber, então, criamos o Cherami para satisfazer esses requisitos:
- Durabilidade, sem perdas e tolerante à falhas de hardware;
- Flexibilidade entre disponibilidade e consistência durante a partição de rede;
- Habilidade de aumentar ou diminuir a taxa de transferência facilmente;
- Suporte completo para o modelo de consumidores concorrentes;
- Agnóstico quanto à linguagem;
Para satisfazer a esses requisitos, o design do Cherami segue esses princípios:
- Nós escolhemos a consistência como um princípio fundamental. Isso permite a alta disponibilidade e durabilidade, com a contrapartida de não oferecermos garantias de ordenação. No entanto, isso significa que podemos continuar aceitando solicitações durante falhas catastróficas ou partições de rede, e também melhora a disponibilidade eliminando a necessidade de um arquivo consistente de metadados como o Zookeeper.
- Nós escolhemos não suportar o padrão de consumidores particionados, e não exibimos as partições ao usuário. Isso simplifica o gerenciamento dos consumidores, já que os trabalhadores não precisam coordenar de qual partição consumir. Isso também simplifica o provisionamento, pois tanto o consumidor quando o produtor podem ser escalonados independentemente.
Nas próximas sessões, vamos elaborar mais sobre os principais elementos do design do Cherami e explicar como nós aplicamos os princípios de design e contrapartidas.
Elementos chave do design do Cherami
Recuperação de falhas e replicação
Para ser realmente livre de perdas e disponível, Cherami deve tolerar falhas de hardware. Na prática, isso requer que o Cherami replique cada mensagem por hardwares diferentes para que as mensagem possam ser confiantemente lidas, mas ele também deve estar apto a aceitar novas mensagem quando o hardware falha temporária ou permanentemente.
A tolerância a falhas vem da influência da propriedade de somente anexar dos sistemas de mensagem e utilização da canalização das transferências de mensagens. Cada mensagem em uma fila é um elemento independente que, uma vez criado, nunca é modificado. Em outras palavras, as filas de mensagens são apenas anexadas.
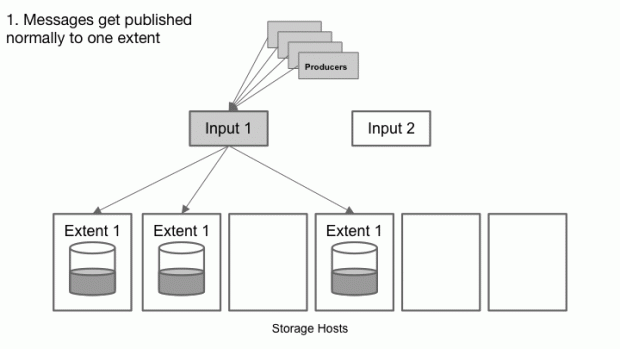
Uma fila do Cherami consiste em uma ou mais extensões, que são subconsumos conceituais dentro de uma fila que independentemente suporta mensagem anexadas. As extensões são replicadas para a camada de armazenamento por uma tarefa chamada input host. Quando uma extensão é criada, seus metadados contêm informações da tupla do host que são inalteráveis (host de entrada e lista dos hosts de armazenamento. Em cada host de armazenamento, a cópia replicada da extensão é chamada réplica, e o host de armazenamento pode ter várias réplicas de extensões diferentes. Se um único ponto de armazenagem falha, não perdemos as mensagens porque a extensão ainda é legível de outras réplicas.
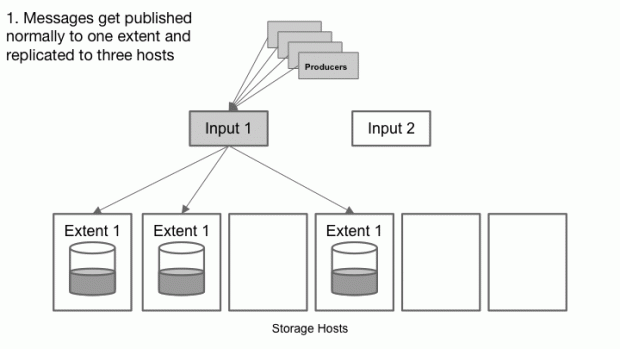
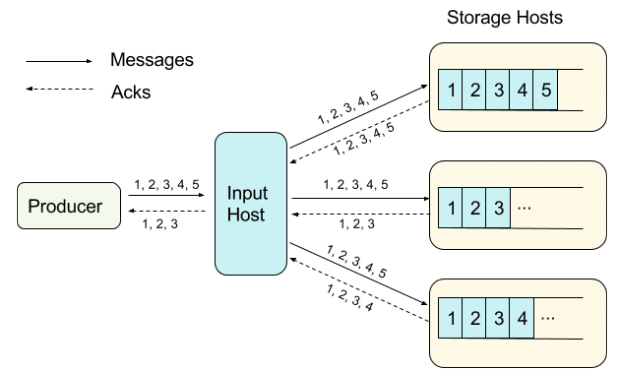
Os produtores se conectam aos pontos específicos de entrada para publicar em uma extensão que pertença a alguma fila. Ao receber uma mensagem de um produtor, o ponto de entrada simultaneamente canaliza a mensagem para todas as extensões de réplica através de uma conexão WebSocket, e recebe os retornos (acks) das respectivas réplicas da mesma conexão.
Essa canalização significa que o ponto de entrada não aguarda o retorno antes de encaminhar a próxima mensagem, e que não existe a reordenação ou o salto das mensagens entre o ponto de entrada e todas as réplicas. Isso também se aplica ao retorno de cada réplica; os retornos são enviados na ordem em que as mensagens são recebidas. O ponto de entrada rastreia todos os retornos. Somente quando todos os retornos dos pontos de armazenamento são recebidos, o ponto de entrada encaminha um retorno ao produtor. Esse retorno final significa que a mensagem completa foi armazenada de maneira durável em todas as réplicas.
Dentro de cada extensão, as mensagens são ordenadas de acordo com a propriedade de canalização. Isso assegura que as mensagens em todas as réplicas estão consistentes, exceto nos pontos onde um ponto de armazenamento ainda precisa persistir as mensagens.
Quando qualquer uma das réplicas falha, o ponto de entrada não pode receber os retornos daquele ponto de armazenamento após a falha. Então, esse ponto não é mais anexável. Caso o ponto de entrada falhe, nós perderíamos os retornos dos pontos de armazenamento. Em ambos os casos, os fins das mensagens podem ser inconsistentes: uma ou mais mensagens não são replicadas em todas as réplicas. Para se recuperar dessa inconsistência, ao invés de tentar varrer e reparar as mensagens, que seria uma operação complicada, nós simplesmente declaramos essa extensão fechada como está; é legível, mas nenhuma outra escrita é permitida.
Após fechá-la, o Cherami cria uma nova extensão para essa fila, e o canal de sinalização notifica o produtor a reconectar e publicar na nova extensão. Se uma fila consistir em apenas uma extensão aberta, fechá-la a deixaria temporariamente indisponível para publicações por um curto espaço de tempo, até uma nova extensão ser criada. Para evitar picos de latência das publicações durante falhas, uma fila normalmente utiliza um número mínimo de extensões para a publicação continue quando uma extensão está sendo fechada e outra criada.
Nós escolhemos utilizar o fechamento como mecanismo de recuperação porque é fácil de implementar. A contrapartida aqui é que a duplicação pode ocorrer. A razão para a duplicação é que após uma falha, o fim das réplicas vai conter mensagem para as quais o retorno não foi encaminhado ao publicador, e não é possível determinar quais são, se a falha for no ponto de entrada. No entanto, no caminho de leitura, vamos ter que entregar tudo, incluindo as mensagens sem retorno. Os publicadores normalmente vão tentar novamente quando houver falha no enfileiramento de uma mensagem, então algumas dessas mensagens podem ser republicadas em uma nova extensão, o que causa ao consumidor, recebê-las duplicadas.
Escala de gravações
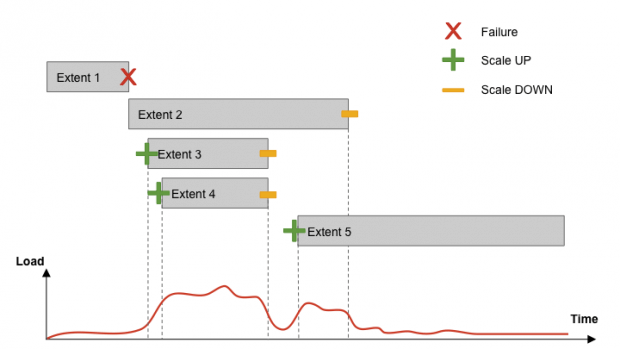
As extensões do Cherami são subjacentes e nada-compartilhadas. O Cherami observa as taxas de transferência de cada uma. Conforme a carga de gravações de uma determinada fila aumenta e algumas extensões excedem seu limite de taxa de transferência, o Cherami cria extensões adicionais automaticamente. As novas extensões recebem parte da carga de gravações, aliviando a carga nas existentes.
Conforme a carga diminui, o Cherami fecha algumas das extensões sem substituí-las. Dessa maneira o Cherami reduz alguns recursos(memória, conexões de rede, e outras manutenções) necessárias para manter uma extensão aberta.
Tratamento do consumo
Consumidores no mesmo grupo recebem tarefas da mesma fila, mas podem receber de uma ou mais extensões. Quando um consumidor recebe uma mensagem e a processa com sucesso, ele envia um retorno para o Cherami. Se o Cherami não receber o retorno dentro do tempo configurado, ele encaminha a mensagem para uma nova tentativa. O retorno do consumidor pode atrasar ou não ser entregue quando o consumidor trava, quando uma sequência de alguma dependência não está disponível, quando uma única tarefa demora demais, ou quando o processamento trava devido à um deadlock. Um consumidor também pode enviar um retorno negativo, uma mensagem, disparando imediatamente o reenvio. Os retornos negativos permitem que grupos de consumidores processem tarefas que alguns membros não são capazes de processar (por exemplo, por falhas locais, atualização parcial ou contínua de um grupo de consumidores para uma nova tarefa).
Por diferentes consumidores poderem levar uma quantidade de tempo diferente para processar as mensagens, os retornos chegam ao Cherami em uma ordem diferente da ordenação providenciada pelas réplicas. Alguns dos sistemas de mensagem arquivam o estado lido/não lido (também conhecido como estado de visibilidade) por mensagem. No entanto, para fazer isso, teríamos que atualizar os estados dos discos (com gravações aleatórias) e lidar com a complexidade fazer isso para grupo múltiplo de consumidores.
O Cherami tem uma abordagem diferente. Em cada grupo de consumidores, para cada extensão, nós mantemos um contador dos retornos, que é o número de sequência da mensagem, sob o qual todas as mensagens forem respondidas. Nós temos uma função chamada output host, na qual os consumidores se conectam para receber as entregas de mensagens. O hospedeiro de saída lê as mensagens do armazenamento em sequência, mantendo elas na memória. Ele mantém o histórico das mensagens em transição (Entregues ao consumidor, mas ainda sem um retorno) e atualiza o contados quando possível. O hospedeiro de saída também mantém o histórico de tempo e retornos negativos para que as mensagens possam ser entregues para outros consumidores conforme a necessidade. No Cherami, uma extensão pode ser consumida simultaneamente por vários grupos de consumidores, por isso, múltiplos hospedeiros de saída podem ler da mesma extensão.
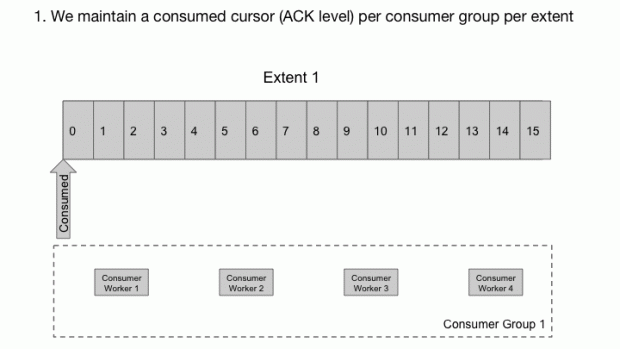
Adicionalmente, o sistema é configurado para redistribuir cada mensagem um número limitado de vezes. Se o limite de redistribuição é atingido, a mensagem é encaminhada para fila de mensagens não entregues e a mensagem é marcada como tendo recebido o retorno, para que o contador possa avançar. Dessa maneira nenhuma “pílula de veneno” bloqueia o processamento das mensagens no DLQ, e então tratam elas e uma das duas perguntas: eliminá-las ou absorvê-las. Eliminá-las apaga a mensagem, e é apropriado com ela é inválida, ou não temos valor(ex. Eram sensíveis ao período). O proprietário pode, por outro lado, juntá-la ao grupo consumidor, o que é apropriado quando o software consumidor foi corrigido para tratar mensagens que ele não conseguira tratar antes, ou quando a condição de falha tiver diminuído.
Armazenamento
As mensagens no Cherami são armazenadas duravelmente em discos. Nos hosts de armazenamento, nós escolhemos o RocksBD como nossa engine de performance para o armazenamento e funcionalidades de indexação, e utilizamos uma instância separada do RocksBD por extensão com os blocos de cache LRU compartilhados. As mensagens são armazenadas no banco de dados com um número de sequência incremental como chave, e a própria mensagem como valor. Devido às chaves sempre serem incrementadas, o RocksBD otimiza a compactação para não sofremos de amplificação das gravações. Quando output host lê as mensagens de uma extensão, ele simplesmente busca o contador de retorno do grupo de consumidores que ele está tratando e faz a iteração pelo número de sequência para ler as próximas mensagens.
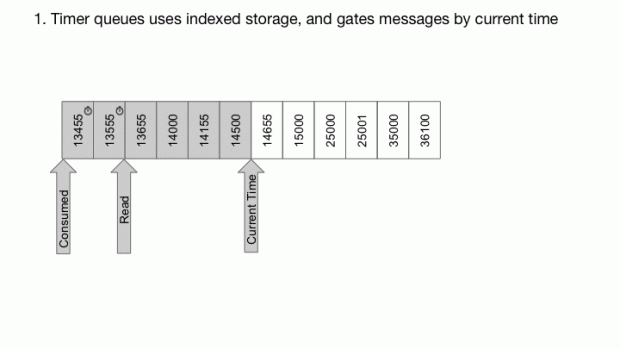
Com o RocksBD, podemos facilmente implementar filas de temporizadores, que são filas em que cada mensagem está associada à um tempo de atraso. Nesses casos, a mensagem somente é entregue após esse tempo. Para solicitações de temporizadores, nós construímos a chave para conter o tempo de entrega em bits de alta ordem e a sequência em bits de baixa ordem. Como Cherami possui um contador ordenado, as chaves são atualizadas de acordo com a hora da entrega, enquanto a sequência dos bits e garante que as chaves serão únicas
Arquitetura do Sistema
O Cherami consiste em diferentes funções. Adicionalmente à entrada, armazenamento e saída que nós já apresentamos, existem o controller e o frontend. Uma implementação típica do Cherami consiste em várias instancias da mesma atividade.
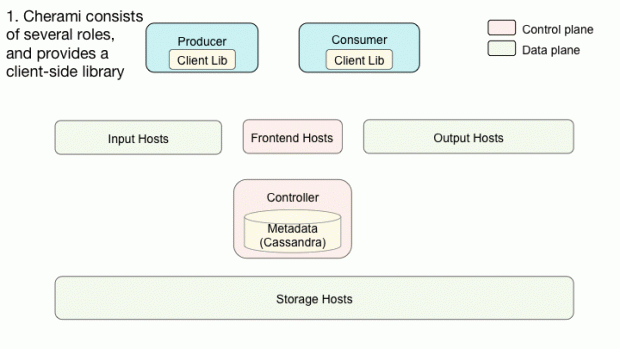
Diferentes funções podem existir no mesmo hospedeiro físico ou até estarem atreladas à um binário simples. Na Uber, cada tarefa executa um docker individual. Entrada, armazenamento, e saída dos dados do sistema. O Controller e o frontend controlam funções planas e operações de metadados.
Controller
O Controller é o grande coordenador, a inteligência que coordena todos os outros componentes. Ele primeiramente determina quando criar e onde alocar (para quais hospedeiros de entrada e armazenamento) uma extensão. Ele também determina quais os hospedeiros de saída vão tratar o consumo de um grupo.
Todas as funções de plano de dados reportam as informações de carga para o Controller utilizando chamadas RPC. Com essa informação, ele toma as decisões de alocação e balanceamento das cargas. Existem várias instancias dessa função de Controller, uma delas é escolhida como a líder utilizando a biblioteca Ringpop da Uber para relatórios e análises consistentes. O Ringpop realiza verificações distribuídas dos estados e funções dos membros.
Frontend
Os hospedeiros de frontend exibem os APIs TChannel e Thrift que realizam as operações CRUD das filas e grupos de consumidores. Eles também exibem os APIs com propósitos de planos de dados. Quando um produtor quer publicar mensagens em uma fila, ele chama o API de distribuição para descobrir qual hospedeiro de entrada contém as extensões da fila. Após isso, o produtor se conecta aos hospedeiros de entrada utilizando conexões WebSocket e publica as mensagens nos hospedeiros selecionados.
Similarmente, quando um consumidor quer consumir mensagens de uma fila, primeiro chama o API de distribuição para descobrir quais os hospedeiros de saída gerenciam o consumo das extensões nas filas. Então, o produtor se conecta aos hospedeiros utilizando os conectores WebSocket e recebe as mensagens. Quando novas extensões são criadas, Cherami envia a notificação para o produtor e consumidor para que eles possam se conectar às novas extensões. Nós criamos bibliotecas que rodem no lado do cliente para simplificar essas interações.
Cassandra e Enfileiramento
Finalmente, o Cherami armazena os metadados utilizando o Cassandra, que é implementado separadamente. Os metadados contém informações sobre uma fila, todas suas extensões, e todas as informações do grupo de consumidores, como as mensagens de retorno, por extensão e por grupo de consumidores. Nós não escolhemos o Cassandra somente por que é um sistema de armazenamento de dados de alta disponibilidade, mas também por seu modelo de consistência ajustável. Tal flexibilidade nos permite oferecer filas que podem ser tolerantes à partições enquanto não preservar a ordem (filas AP) ou que preservem a ordem (filas CP), mas não fiquem disponíveis durante a partição. A principal diferença no manuseio dos dois tipos de fila é se a criação de extensões requer uma operação de atualização condicional.
Filas AP
Para filas AP, a criação de extensões não necessita de consistência à nivel de quorum no Cassandra. Quando uma partição de rede ocorre, as extensões podem ser criadas em ambos os lados da partição. Vamos chamar as partições de A e B. Os produtores na partição A podem publicar nas extensões nessa partição, e os produtores na partição B podem publicar nessa partição. No entanto, a gravação não é bloqueada pela partição da rede. Para leitura, os consumidores na partição A podem consumir somente das extensões dessa partição e o mesmo para os consumidores da partição B. No entanto, quando a partição da rede é sanada, os consumidores podem alcançar todas as extensões. A contrapartida aqui é que as mensagens serão eventualmente consistentes: Não é possível estabelecer um ordenamento global das mensagens pois as extensões podem ser criadas a qualquer momento. Em nossa implementação, nós utilizamos o nível de consistência do Cassandra nível 1 quando gravamos na extensão de metadados.
Filas CP
Para as filas CP, a criação das extensões precisa ser linearizável: no caso de uma partição da rede, nos devemos ter certeza que somente uma partição pode criar uma extensão para suceder uma anteriormente encerrada. Para garantir isso, nos utilizamos a transação de peso leve do Cassandra para que ao mesmo tempo que mais de uma extensão pode ser criada por qualquer motivo, somente uma pode ser utilizada para a fila CP.
Cherami, resumido
O Cherami é um sistema de filas de mensagens de consumidores concorrentes que é durável, tolerante a falhas, de alta disponibilidade e escalável. Nós atingimos a durabilidade e tolerância à falhas replicando as mensagens através dos hospedeiros de armazenamento, e alta disponibilidade alavancando a propriedade de somente anexar das filas de mensagens e escolhendo uma consistência eventual como nossa base de modelo. O Cherami também é escalável, já que o design não possui um único gargalo.
O Cherami foi planejado e desenvolvido do zero em seis meses em nosso escritório de engenharia de Seattle. Atualmente, o Cherami transporta centenas de milhões de tarefas, duravelmente, por dia, entre os microsserviços da engenharia da Uber, ajudando em casos como o processamento pós-viagem, detecção de fraudes, notificação de usuário, campanhas de incentivo e muitos outros casos.
O Cherami é inteiramente escrito em Go, uma linguagem que faz o desenvolvimento de um sistema de software concorrente e altamente performático divertido. Adicionalmente, o Cherami utiliza muitas bibliotecas que a Uber já abriu os códigos: TChannel para o RPC e o Ringpop para verificação do estado e membros do grupo. O Cherami depende de várias tecnologias open source de terceiros: Cassandra para armazenamento de metadados, RocksDB para armazenamento das mensagens, e muitos outros pacotes em Go de terceiros que estão disponíveis no GitHub. Nós planejamos abrir o código do Cherami no futuro próximo.
***
Este artigo é do Uber Engineering. Ele foi escrito por Xiaobing Li e Ankur Bansal. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/cherami/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?