

Hoje trazemos a vocês o NDBench, uma ferramenta utilizada para integração e testes de desempenho funcional, assim como a validação AMI na Netflix. Neste artigo, será demonstrado o processo de maturidade da ferramenta até a sua abertura para a comunidade.
A experiência de membro do Netflix é oferecida a mais de 83 milhões de pessoas em todo o mundo, e entregue usando milhares de microservices. Esses serviços são de propriedade de várias equipes, cada uma com a sua própria build e ciclos de vida, gerando uma variedade de dados que são armazenados em diferentes tipos de sistemas de armazenamento de dados. O time do Cloud Database Engineering (CDE) gerencia esses sistemas de armazenamento de dados, de modo que eles executam os benchmarks para validar atualizações para esses sistemas, realizam planejamento de capacidade e testam as instâncias de nuvem da empresa com várias cargas de trabalho e sob diferentes cenários de falha. Eles também tinham interesse em uma ferramenta que pudesse avaliar e comparar novos sistemas de armazenamento de dados quando eles aparecessem no mercado ou no domínio de código aberto, determinar suas características de desempenho e limitações, e avaliar se eles poderiam ser usados na produção de casos de uso relevantes. Para esse fim, a Netflix escreveu o Netflix Data Benchmark (NDBench), uma ferramenta de benchmarking conectável, pronta para a nuvem e que pode ser usada em qualquer sistema de armazenamento de dados. O NDBench fornece suporte via plug-in para os principais sistemas de armazenamento de dados que são utilizados na Netflix, como: Cassandra (Thrift e CQL), Dynomite (Redis) e Elasticsearch. Ele também pode ser estendido para outras APIs clientes.
Introdução
Como a Netflix executa milhares de microservices, eles nem sempre estão cientes do tráfego que os microservices empacotados podem gerar em seu sistema de back-end. Assim, eles tiveram uma grande dificuldade em entender as implicações que os novos microservices desempenham no seu sistemas de back-end. Foi necessário um framework para ajudá-los a determinar o comportamento do seus sistemas de armazenamento de dados sob várias cargas de trabalho, operações de manutenção e tipos de instância. Eles queriam estar conscientes do provisionamento dos seus clusters, dimensioná-los tanto na horizontal (adicionando nodes) ou vertical (atualizando os tipos de instância), e operando sob diferentes cargas de trabalho e condições, tais como falhas de nodes, partições de rede etc.
Conforme novos sistemas de armazenamento de dados são inseridos no mercado, eles tendem a relatar números de desempenho no “sweet spot”, e normalmente são baseados em hardware otimizado e configurações de benchmark. Como eles são uma equipe de banco de dados cloud nativa, é de suma importância que eles tenham certeza de que seus sistemas podem fornecer alta disponibilidade sob vários cenários de falha, e também é necessário garantir que estão utilizando seus recursos de instância de forma otimizada. Há muitos outros fatores que afetam o desempenho de um banco de dados implantado na nuvem, tais como tipos de instância, padrões de carga de trabalho e os tipos de implementações (ilha vs global). O NDBench ajuda a simular a avaliação de desempenho, imitando vários casos de uso em produção.
A Netflix também se preocupava com alguns requisitos adicionais; por exemplo, enquanto eram atualizados os seus sistemas de armazenamento de dados (tais como atualizações no Cassandra), eles testaram os sistemas anteriores para implementá-los em produção. Para os sistemas que foram desenvolvidos in-house, como o Dynomite, eles automatizaram as condutas de teste funcional, compreenderam o desempenho de Dynomite sob várias condições e sob diferentes mecanismos de armazenamento. Por isso, foi necessário um gerador de carga de trabalho que pudesse ser integrado em seus pipelines antes de promover um AWS AMI para um AMI pronto para produção.
Assim, ele olharam várias ferramentas de benchmark, bem como ferramentas de desempenho baseadas em REST. Enquanto algumas ferramentas cobriam um subconjunto das suas necessidades, eles estavam interessados em uma ferramenta que poderia alcançar o seguinte:
- Dinamicamente alterar as configurações de benchmark enquanto o teste está sendo executado, portanto, realizar testes junto com os seus microservices em produção.
- Ser capaz de integrar com os serviços de plataforma em nuvem, como configurações dynamic, discovery, métricas etc.
- Executar por uma duração infinita, a fim de introduzir cenários de falha e testar manutenções de execução longa, como reparos de banco de dados.
- Fornecer padrões conectáveis e cargas.
- Suportar diferentes APIs clientes.
- Implementar, gerenciar e monitorar múltiplas instâncias de um único ponto de entrada.
Por essas razões, foi criado o Netflix Data Benchmark (NDBench). O NDBeanch foi incorporado ao ecossistema Netflix Open Source, integrando-o com componentes como Archaius para configuração, Spectator para métricas e Eureka para o serviço de descoberta. No entanto, o NDBench foi projetado para que essas bibliotecas fossem injetadas, permitindo que a ferramenta pudesse ser portada para outros ambientes de nuvem, rodar localmente e ao mesmo tempo satisfazer os usuários do ecossistema Netflix OSS.
Arquitetura do NDBench
O diagrama a seguir mostra a arquitetura do NDBench. O framework consiste em três componentes:
- Núcleo: O gerador de carga de trabalho
- API: Permite que vários plugins sejam desenvolvidos contra o NDBench
- Web: A interface do usuário e o ouvinte contextual do servlet
Atualmente, são fornecidos os seguintes plugins cliente – Datastax Java Driver (CQL), C* Astyanax (Thrift), API Elasticsearch e Dyno (suporte para Jedis). Outros plugins podem ser adicionados ou o usuário pode usar scripts dinâmicos no Groovy para adicionar novas cargas de trabalho. Cada driver é apenas uma implementação da interface do driver de plugin.
NDBench-core é o componente central do NDBench, onde se pode definir a configuração de carga de trabalho.
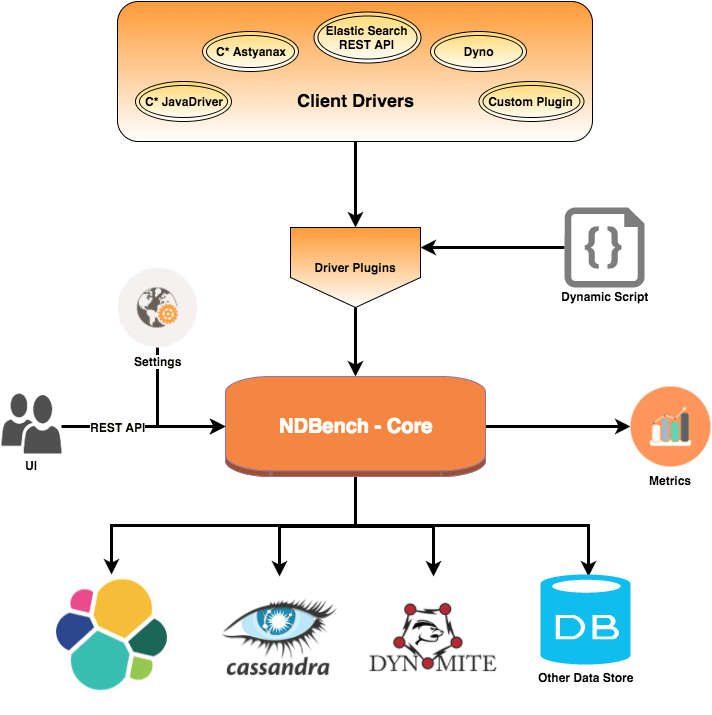 Fig. 1: Arquitetura NDBench
Fig. 1: Arquitetura NDBench
O NDBench pode ser usado a partir da linha de comando (usando chamadas REST), ou a partir de uma interface de usuário baseada na web (UI).
NDBench Runner UI
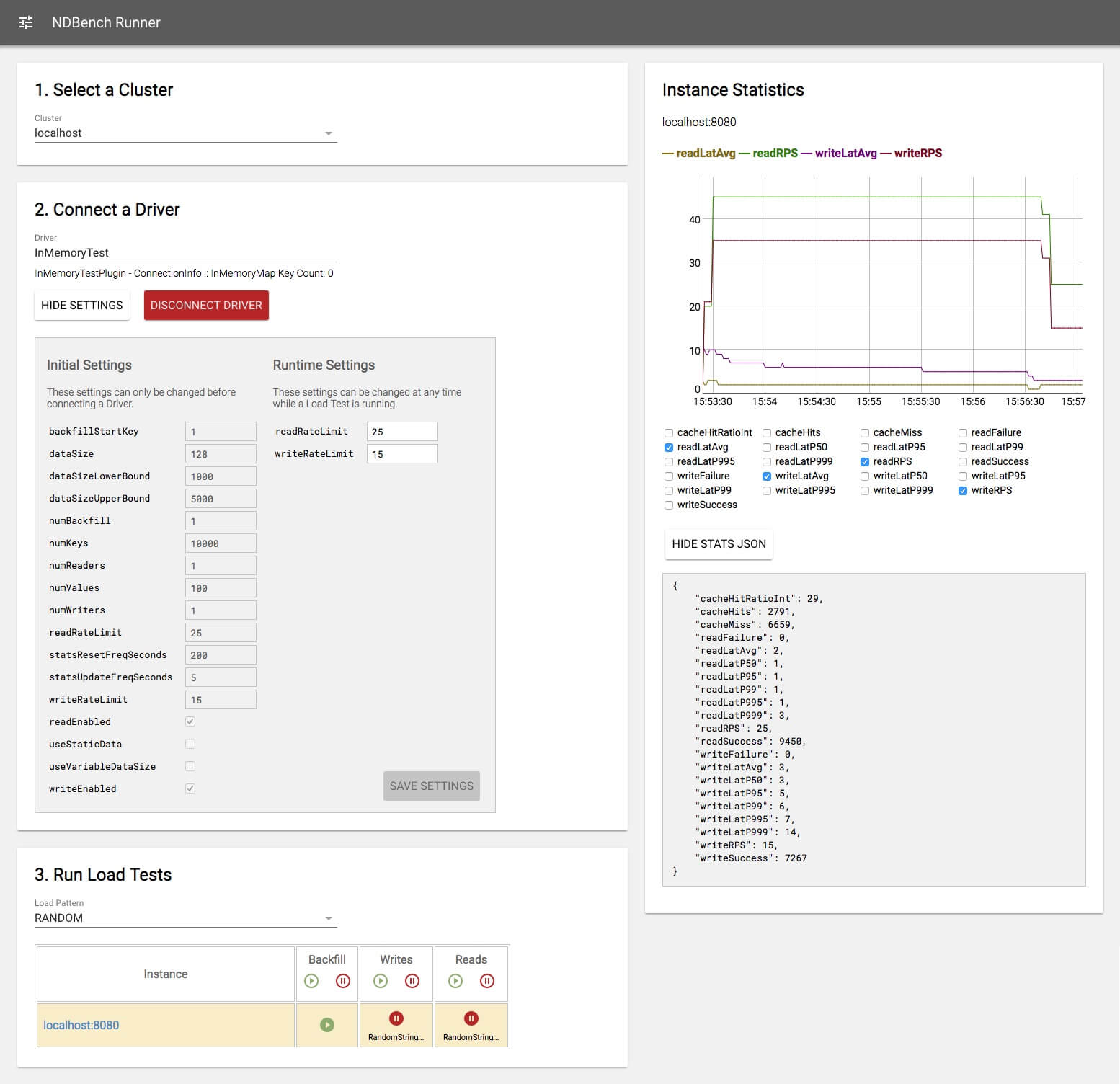 Fig.2: NDBench Runner UI
Fig.2: NDBench Runner UI
Uma captura de tela do NDBench Runner (Web UI) é mostrada na Figura 2. Através dessa interface, o usuário pode selecionar um cluster, conectar um driver, modificar as configurações, definir um padrão de teste de carga (janela deslizante ou aleatória) e, finalmente, executar os testes de carga. Selecionar uma instância enquanto um teste de carga está sendo executado também permite ao usuário visualizar as estatísticas com atualização em tempo real, como latências de leitura/escrita, requisições por segundo, cache hits contra misses e muito mais.
Propriedades de carga
NDBench fornece uma variedade de parâmetros de entrada que são carregados de forma dinâmica e podem mudar dinamicamente durante o teste de carga de trabalho. Os seguintes parâmetros podem ser configurados em uma base por node:
- numKeys: o espaço amostral para as chaves geradas aleatoriamente
- numValues: o espaço amostral para os valores gerados
- dataSize: o tamanho de cada valor
- numWriters/numReaders: o número de threads por node NDBench para gravações/leituras
- writeEnabled/readEnabled: booleano para ativar ou desativar escrita ou leitura
- writeRateLimit/readRateLimit: o número de gravações por segundo e leituras por segundo
- userVariableDataSize: booleano para ativar ou desativar a capacidade da carga a ser gerada aleatoriamente.
Tipos de carga de trabalho
NDBench oferece testes de carga conectáveis. Atualmente, ele oferece dois modos – o tráfego aleatório e o tráfego de janela deslizante. O teste de janela deslizante é um teste mais sofisticado que pode exercitar simultaneamente dados que são repetidos dentro da janela, proporcionando uma combinação de dados locais temporais e dados locais espaciais. Esse teste é importante para a Netflix, pois eles querem exercitar tanto a camada de cache fornecida pelo sistema de armazenamento de dados, como IOPS do disco (operações de entrada/saída por segundo).
Geração de carga
A carga pode ser gerada individualmente para cada node no lado da aplicação, ou todos os nodes podem gerar leituras e escritas simultaneamente. Além disso, o NDBench fornece a capacidade de usar o recurso de “backfill”, a fim de iniciar a carga de trabalho com dados quentes. Assim, o tempo de início do benchmark é reduzido.
NDBench na Netflix
O NDBench tem sido amplamente utilizado dentro da Netflix. Nas seções seguintes, falaremos sobre alguns casos de uso em que o NDBench provou ser uma ferramenta útil.
Ferramenta de benchmarking
Dois meses atrás, foi finalizada a migração do Cassandra da versão 2.0 para a 2.1. Antes de iniciar o processo, era imperativo para a Netflix compreender os ganhos de desempenho que seriam atingidos, assim como o impacto no desempenho que aconteceria durante a atualização gradual das suas instâncias Cassandra. As figuras 3 e 4 abaixo ilustram as diferenças de latência de leitura p99 e p95 usando NDBench. Na Fig. 3, foram destacadas as diferenças entre Cassandra 2.0 (linha azul) contra a 2.1 (linha marrom).
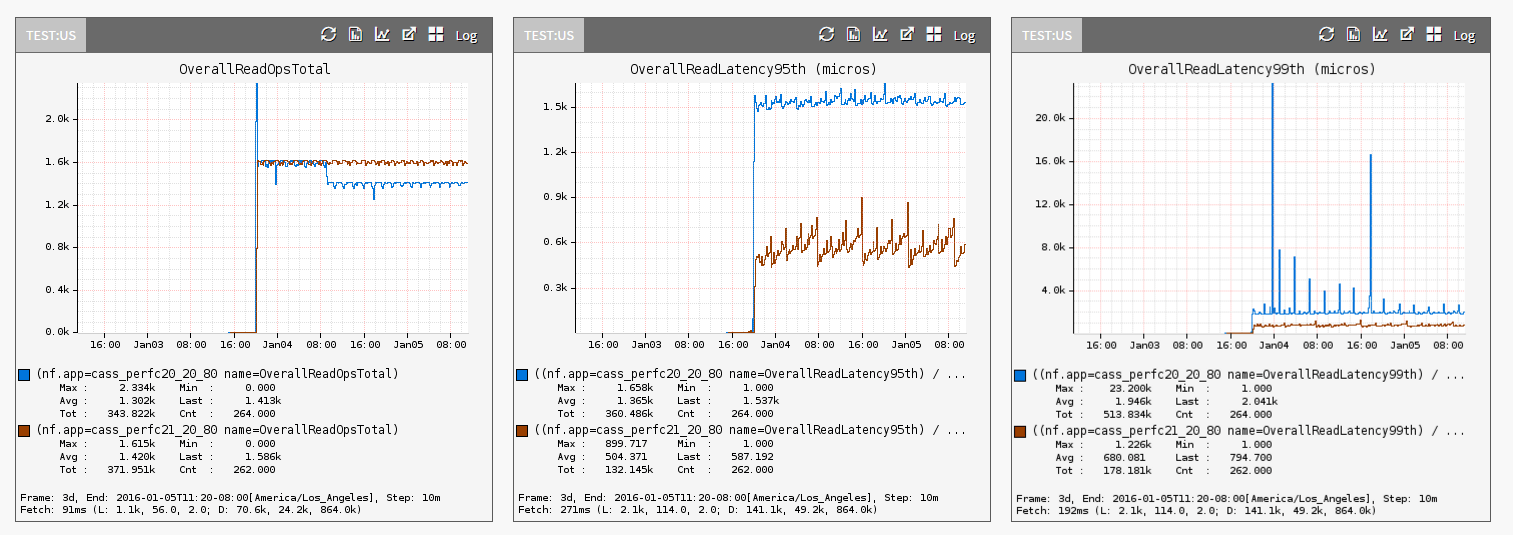 Fig.3: Capturando OPS e percentuais de latência do Cassandra
Fig.3: Capturando OPS e percentuais de latência do Cassandra
No ano passado, eles também migraram todas as instâncias do Cassandra Red Hat 5.10 para o Ubuntu 14.04 (Trusty Tahr). Foi utilizado o NDBench para medir o desempenho sob o sistema operacional mais recente. Na figura 4, são apresentadas as três fases do processo de migração, usando a capacidade de longa execução de benchmark do NDBench. Foi utilizado o rolling terminations do Cassandra para atualizar as AMIs com o novo sistema operacional, e NDBench para verificar que não haveria nenhum impacto no lado do cliente durante a migração. O NDBench também permitiu validar que o desempenho do novo sistema operacional foi melhor após a migração.
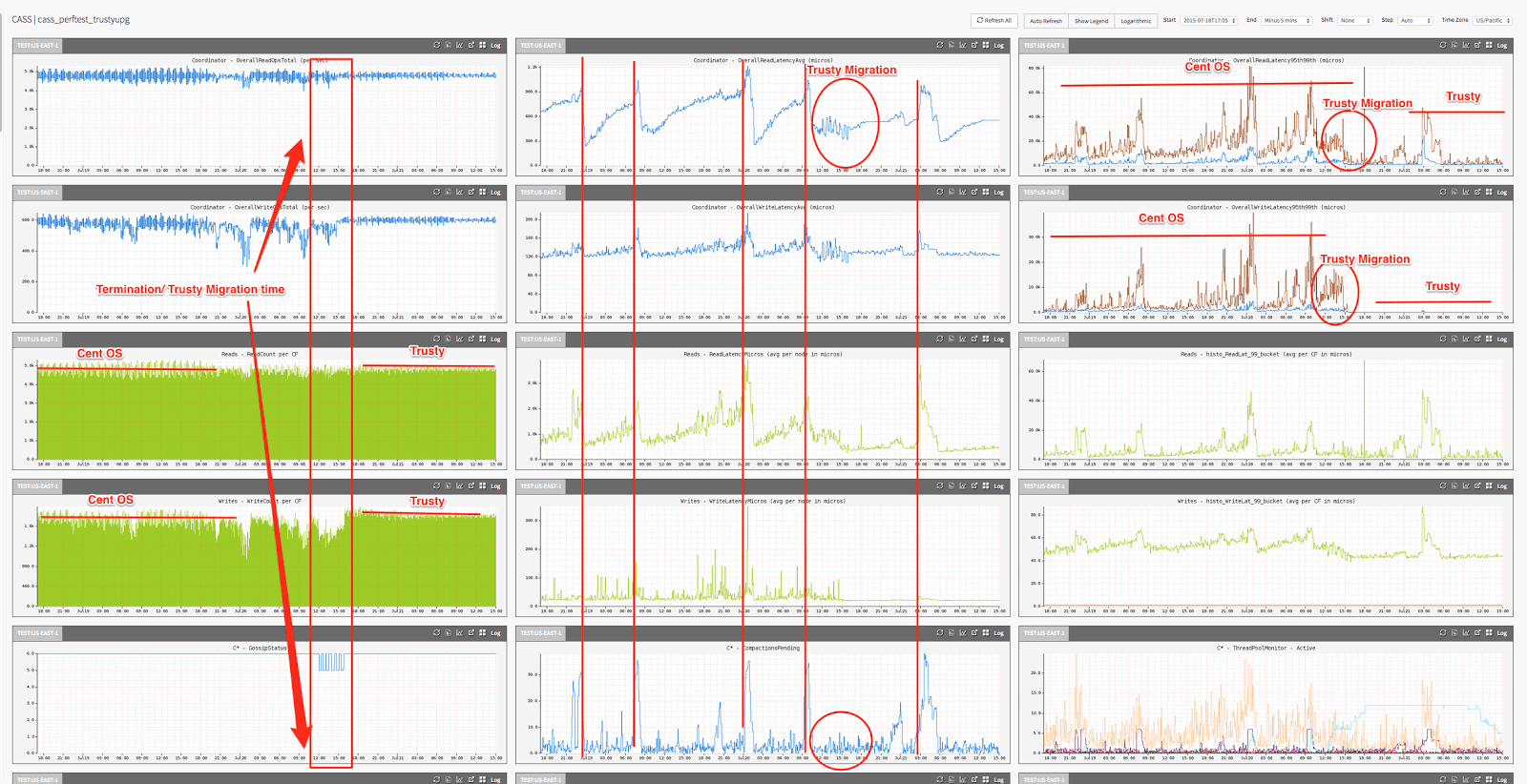 Fig.4: A melhoria do desempenho da nossa atualização do Red Hat 5.10 para o Ubuntu 14.04
Fig.4: A melhoria do desempenho da nossa atualização do Red Hat 5.10 para o Ubuntu 14.04
Processo de certificação AMI
O NDBench também faz parte do processo de certificação AMI da Netflix, que consiste em testes de integração e validação de implementação. Eles projetaram os pipelines no Spinnaker e integraram o NDBench neles. A figura a seguir mostra o ciclo de vida desde a concepção até o release. Inicialmente, foi construído um AMI com Cassandra, foi criado um cluster Cassandra e também um cluster NDBench que foi configurado e, em seguida, foi executado um teste de desempenho. Ao final disso, eles puderam observar os resultados. Com os resultados em mãos, foi possível tomar a decisão sobre a possibilidade de promover o AMI de “Experimental” para “Candidate”. Assim, eles utilizaram pipelines semelhantes para o Dynomite, testando as funcionalidades de replicação com diferentes APIs do lado do cliente. Os ensaios de desempenho NDBench significam que o AMI está pronto para ser usado no ambiente de produção. Pipelines semelhantes são utilizados em toda a linha para outros sistemas de armazenamento de dados na Netflix.
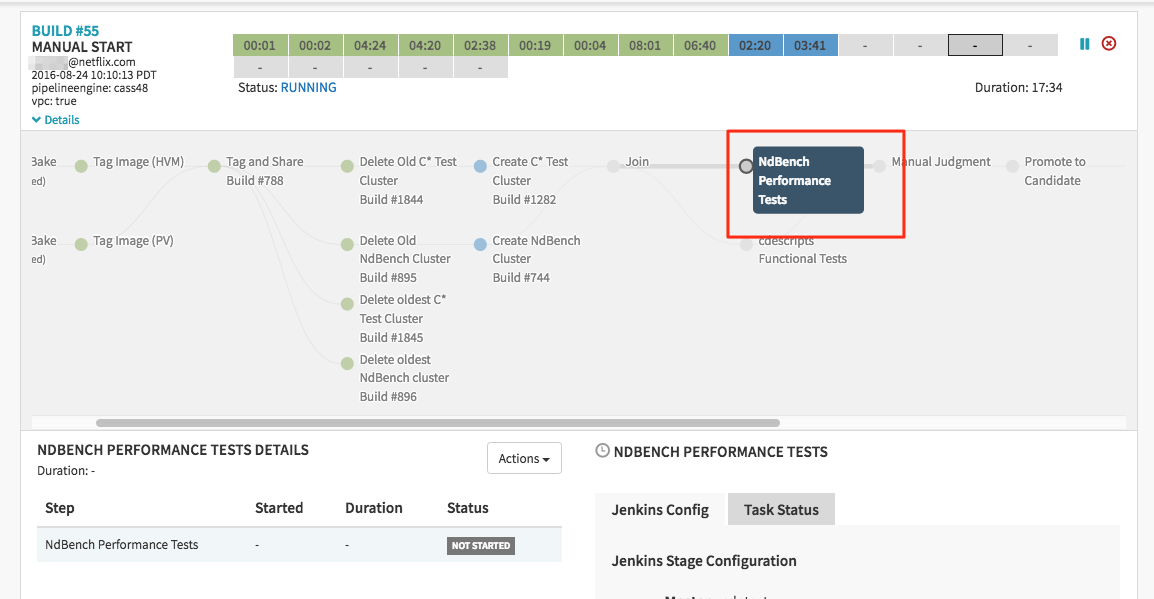 Fig.5: NDBench integrado com pipelines Spinnaker
Fig.5: NDBench integrado com pipelines Spinnaker
No passado, foram publicados benchmarks do Dynomite com Redis como um mecanismo de armazenamento alavancando o NDBench. Na Fig. 6, veja algumas das latências percentuais mais elevadas nos derivados de Dynomite alavancando o NDBench.
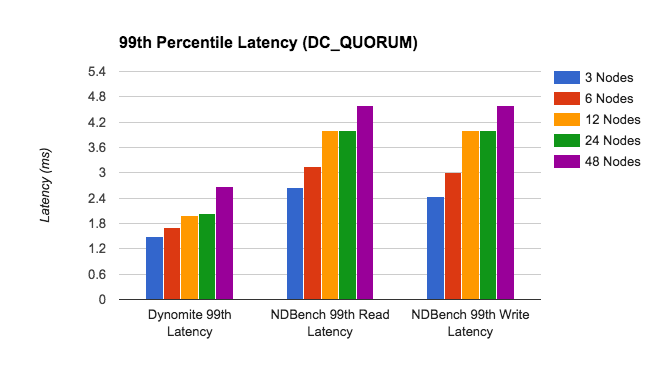 Fig.6: Latências P99 para o Dynomite com consistência definida para DC_QUORUM com NDBench
Fig.6: Latências P99 para o Dynomite com consistência definida para DC_QUORUM com NDBench
O NDBench permite ao Netflix executar testes de horizonte infinito para identificar potenciais vazamentos de memória de processos de longa duração que foram desenvolvidos ou utilizados in-house. Ao mesmo tempo, nos testes de integração, foram introduzidas condições de falha, alteradas as variáveis subjacentes dos seus sistemas, introduzidas operações intensivas de CPU (como o reparo/reconciliação) e determinado o melhor desempenho com base nos requisitos da aplicação. Finalmente, os anexados como Priam, Dynomite-manager e Raigad realizam várias atividades, tais como backups multi-threaded para sistemas de armazenamento de objetos. Para a Netflix é muito importante ter certeza, através de testes de integração, de que o desempenho dos seus sistemas de armazenamento de dados não é afetado.
Conclusão
Nos últimos anos, o NDBench tem sido uma ferramenta amplamente utilizada para integração e testes de desempenho funcional, assim como a validação AMI. A capacidade de alterar os padrões de carga de trabalho durante um teste, suporte para diferentes APIs do cliente e integração com suas implantações de nuvem têm ajudado muito na validação dos seus sistemas de armazenamento de dados. Há uma série de melhorias que a Netflix ainda gostaria de fazer no NDBench, tanto para aumentar a usabilidade quanto para o suporte para recursos adicionais. Algumas das características que ele tem interesse são:
- Gerenciamento de perfil de desempenho
- Análise canary automatizada
- Geração de carga dinâmica com base em esquemas de destino
O NDBench tem provado ser extremamente útil para a equipe Cloud Database Engineering da Netflix, e eles estão felizes por ter a oportunidade de compartilhar esse valor com a comunidade. Portanto, estão liberando o NDBench como um projeto open source, e estão ansiosos para receber feedback, ideias e colaborações da comunidade open source. Você pode encontrar o NDBench no GitHub em: https://github.com/Netflix/ndbench.
***
Fonte: http://techblog.netflix.com/2016/09/netflix-data-benchmark-benchmarking.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?