

O recurso Amazon Route 53 Health Checks oferece a possibilidade de verificar se endereços HTTP, HTTPS ou TCP estão plenamente acessíveis. Porém, há várias situações em que apenas um Health Check de conectividade não é o suficiente para determinar corretamente a saúde de uma aplicação. Nestes casos, a aplicação pode determinar sua própria saúde e expor um endereço específico para que o Route 53 verifique e execute o failover caso necessário. Neste artigo, veremos um exemplo usando Route 53 Health Checks para realizar o failover entre dois bancos de dados, um primário e outro secundário.
Determinando a saúde dos seus recursos
No exemplo deste artigo, usaremos pares de banco de dados, sendo que cada par possui um primário e outro secundário. Vamos considerar que o failover é necessário quando o banco primário não for capaz de responder à consultas. É importante ressaltar que os pares de bancos são independentes e sendo assim, um eventual failover de um dos pares não deve ter qualquer impacto sobre os outros.
Como sabemos, os tipos existentes de verificação do Route 53 não são realmente suficientes para determinar a saúde de um banco de dados. Um Health Check TCP poderia determinar se o banco de dados é alcançável, mas não se é capaz de responder a consultas. Além disso, gostaríamos de mudar para o banco secundário, não apenas se o primário é incapaz de responder a consultas, mas também de forma proativa se precisarmos realizar uma manutenção ou atualizações no primário. Então, como informar ao Route 53 sobre a saúde dos seus recursos?
Informando ao Route53
Uma vez que os bancos de dados em si não podem dar uma resposta adequada ao Health Check do Route 53, podemos criar um endereço HTTP para responder à requisições em nome dos bancos de dados. Este endereço atuará como um Health Proxy para o banco de dados, respondendo com status HTTP 200 quando o banco estiver saudável e HTTP 500 quando o banco de dados não estiver saudável. Nós podemos utilizar um único endereço HTTP para publicar a saúde de todos os pares de bancos de dados, e como cada endereço de Health Check do Route 53 pode conter URLs com caminhos específicos, podemos também atribuir um apontamento exclusivo para cada banco de dados.
Por exemplo, na Figura 1, vemos que o banco de dados primário usa o caminho “/DB1Primary”, enquanto o banco de dados secundário utiliza o caminho “/DB1Standby” no mesmo endereçamento IP e isso vai nos ajudar a economizar alguns recursos.
Nós também configuramos o failover para ocorrer quando há uma falha em um intervalo de dez segundos. Por padrão, esta configuração é de três falhas em trinta segundos, porém em nosso cenário já sabemos que apenas uma falha na verificação já é suficiente para deduzirmos que o banco não está saudável. Com esta configuração, o Route 53 irá detectar que o banco de dados está com problemas em aproximadamente 10 segundos.
Aumentando a disponibilidade
Até este momento, nós criamos Health Checks específicos para cada um dos nossos bancos de dados. Embora isso funcione bem para fornecer os estados ao Route 53, ele tem uma desvantagem que os controles tradicionais não possuem. Se o componente responsável em expor o endereço de verificação falhar, todas as verificações do Route 53 falharão também. Isso impediria a nossa estratégia de funcionar.
Portando, a primeira coisa a se fazer é expor múltiplos pontos de verificação para o Route 53. Nesta abordagem, todos os pontos de verificação devem fornecer o status dos mesmos recursos. Dessa forma, se um dos endereços HTTP não estiver disponível, ainda teremos outro para realizar o health check. Vamos, então, configurar uma verificação para cada par de banco de dados e endereço HTTP.
O diagrama abaixo mostra como cada componente que expõe o endereço HTTP fornece o status do banco primário e também do secundário. A linha em negrito no diagrama mostra como o estado do banco primário é fornecido pelos dois endereços HTTP ao Route 53.
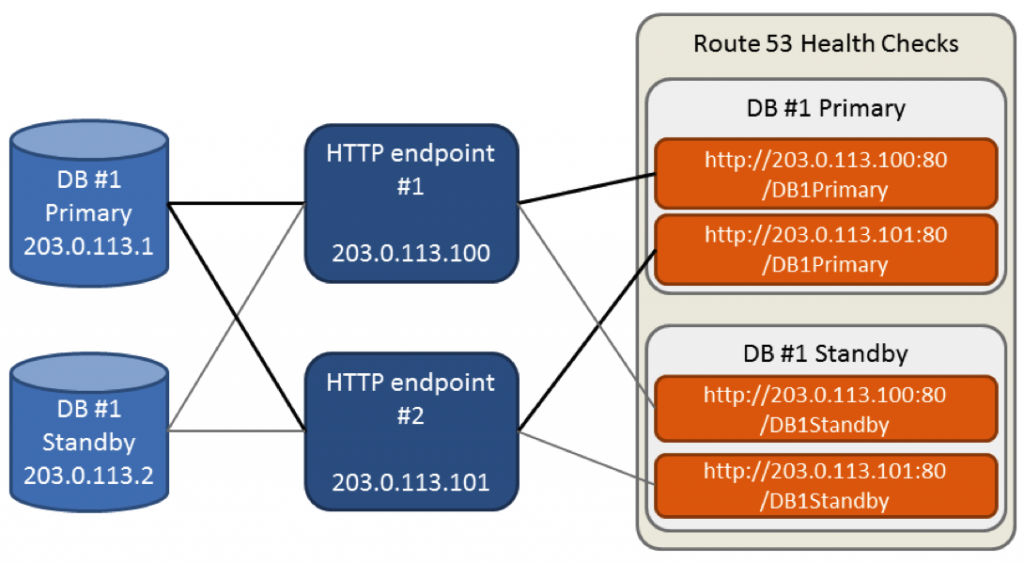
Com dois endereços HTTP, vamos considerar que o banco de dados primário está saudável se ao menos um endereço HTTP retornar que está tudo bem. Isso fornecerá o comportamento desejado caso todos os pontos de validação HTTP estejam desativados.
Para configurar esse comportamento, usaremos uma configuração do Route 53 chamada Weighted Round Robin (WRR). Cada ponto de verificação de banco de dados terá um conjunto de WRR separado, sendo a ponderação para o primário configurada como 01 e para a secundário 02. Quando todas as verificações de saúde do banco de dados primário retornam que estão saudáveis, o Route 53 escolhe aleatoriamente um dos registros de peso 01. Uma vez que todos contêm o mesmo endereço IP do banco de dados primário, não importa qual deles é escolhido. Quando todas as verificações de saúde do banco de dados primário apresentarem falha, seus conjuntos de WRR de peso 01 não serão considerados e o Route 53 escolhe aleatoriamente um dos registros com peso 02. Mais uma vez, todos estes registros devolvem o mesmo endereço IP, de modo que não importa qual deles é escolhido. Finalmente, se todas as verificações primário e secundários retornarem falha, o Route 53 irá considerar todos os conjuntos de WRR e escolhe entre os registros primários, pois possuem o peso 01.
O diagrama abaixo mostra um exemplo de conjuntos WRR configurados para failover DNS de um único banco de dados.

Aplicações e tradeoffs
Enquanto este artigo tratou apenas do failover para banco de dados, esta mesma estratégia vale para vários outros tipos de recursos. Isto pode ser aplicado a quaisquer outros recursos que não podem ser facilmente verificados pelo TCP, HTTP, HTTPS ou health check tradicionais, tais como servidores de arquivos, servidores de email, etc. Também poderia ser aplicada para outros cenários, tais como mover o workload para outro ambiente enquanto se realiza uma nova implantação ou quando a taxa de erro para um serviço sobe acima de 5%.
Também vale a pena mencionar que existem algumas desvantagens para esta abordagem que pode torná-la menos útil para algumas aplicações. O maior deles é que nesta abordagem as verificações não fornecem um status sobre a conectividade do recurso final, e sim do endereço HTTP. Para o caso de uso neste artigo, este não é um problema pois os bancos são avaliados e usados por componentes na mesma região, logo uma conectividade global não seria um problema.
O outro tradeoff é ter que manter componentes adicionais para os endereços HTTP. Em nosso exemplo, temos vários pares de banco de dados para avaliar, portanto o custo de dois servidores HTTP serão relativamente pequenos. Se tivermos apenas alguns bancos teremos que avaliar o custo-benefício da solução levando em conta parâmetros de negócio.
***
Artigo escrito por Ari Dias e Glauber Gallego.
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?