

São muitos os controles e métricas normalmente criados para monitorar os elementos críticos que compõem o ambiente de TI de médias e grandes empresas. Tais elementos são reconhecidos por fazerem parte de um grande stack para dar suporte às operações de negócio: sistemas OLTP, bancos de dados, sistemas de entrada e saída de dados e aqueles de apoio ou suporte à decisão. Obviamente, esses são elementos básicos, mas, ainda podemos abrir o leque e abordar servidores de aplicação, como WebSphere, Apache, Tomcat; ou ainda bancos de dados como Oracle, MySQL, SQL Server e sistemas desenvolvidos em Java, .NET e qualquer outra linguagem.
A grande questão é que todos estes pontos têm os seus controles e, na maioria das vezes, as práticas não permitem uma análise real do que está acontecendo por debaixo de todos aqueles aparatos. Normalmente, quando um problema acontece, não existe uma ferramenta gráfica que colete a informação correta para que se possa fazer uma análise mais detalhada sem passar antes por todos os profissionais do departamento de TI e acabar naquele jogo de empurra entre as áreas – isso realmente acontece.
Geralmente acontece assim: alguém nota alguma instabilidade e a comunica; é quando o gerente de área fica sabendo e aciona, além de pessoal interno, uma consultoria ou mesmo uma auditoria de sistemas para dar conta do problema. Nestes casos e em muitos outros, o tempo dos profissionais envolvidos na resolução reativa dos problemas toma grande parte dos recursos que a empresa poderia empregar para tornar a TI mais proativa e menos reativa. Reagir a um problema é trabalhar para colocar um sistema de volta às operações normais após um crash de algum dos elementos de TI já citados. Na maioria das vezes, o profissional precisa analisar vários logs e tomar nota dos vários registros após consultar vários arquivos.
Este processo de investigação de informação ou ocorrência de um evento em vários arquivos de log pode consumir bastante tempo e pessoal dedicado a fazer esse tipo de trabalho. Tais arquivos de log fazem parte de um conceito que é muito discutido nos dias atuais, que é o Big Data – dados que as empresas só sabem que os têm quando precisam acessá-los. Na maioria das vezes, em momentos de downtime dos sistema (o conceito de Big Data serão discutido em um próximo artigo). Hoje, as empresas já estão mais atentas a estes tipos de dados para utilizá-los em prol da criação de maior inteligência operacional e, assim, crescer em competitividade.
Tendo esse cenário em mente, vou apresentar neste artigo uma ferramenta que está revolucionando a maneira de monitorar TI: o Splunk, que foi desennvolvido por uma empresa que teve o seu IPO há pouco tempo e que se mantém em um crescimento. O conceito do produto é fácil de entender, basta que você adicione todas as suas fontes de dados, como logs de aplicações, softwares, logs de segurança, de sistemas operacionais, logs de operações de billing, de carrinho de compras e várias outras fontes. Com todas as fontes configuradas, os dados serão indexados e sobre eles, o administrador de sistemas, DBA, analista de sistemas e/ou gestor de áreas, poderão facilmente criar alertas e gráficos para o monitoramento dos elementos do ambiente de TI. A granularidade do monitoramento vai da necessidade dos profissionais envolvidos, pois, o Splunk é capaz de meramente monitorar um arquivo de log ou ser utilizado para pesquisar toda a movimentação de um usuário por todos os elementos da TI. A ideia é justamente fazer em minutos, o que normalmente se levaria horas, baseando-se em pesquisa textual e centralização da informação.
Conhecendo o Splunk
O Splunk é o mecanismo de indexação e reconhecimento automático de padrões de informação tidos como dados de máquina. Permite a coleta, indexação, criação de alertas e gráficos para monitoramento da TI. O software exato para empresas que precisam de agilidade em detectar o que está se passando com os elementos que compõem sua tecnologia de informação de forma proativa, com possibilidade de levantamento de padrões e tendências. Com o Splunk, é possível solucionar problemas através da investigação de incidentes de segurança em questão de minutos e também monitorar a infraestrutura de TI de ponta a ponta para evitar a degradação ou as interrupções dos serviço. Ele também cumpre os requisitos de conformidade, correlacionando e analisando eventos complexos que abrangem vários sistemas.
Uma vez que todos os seus logs, de todos os elementos de TI, estejam adicionados ao Splunk, é possível correlacionar as informações de vários logs através de uma linguagem simples de busca textual; e a partir dos resultados, criar alertas e gráficos, além de relatórios completos (estes que podem ser entregues automaticamente de acordo com uma periodicidade definida pelo usuário e em formato PDF).
Com configuração fácil, o usuário poderá simplesmente configurar suas fontes de informação e estas serão imediatamente indexadas. Tal indexação é realizada sobre o disco, onde os dados são organizados utilizando o Map Reduce – modelo desenvolvido pelo Google para armazenamento de grandes conjuntos de dados não estruturados.

O Splunk não utiliza um banco de dados, pois, ele próprio é uma máquina de dados e o seu próprio engine organiza os dados em discos, de maneira que ocupe o menor espaço possível. Tudo isso de acordo com as estratégias de recuperação da informação indexada e de forma distribuída. Por isso, um dos requisitos para colocar o Splunk em produção é que se tenha discos rápidos, onde o requisito mínimo é que tais discos suportem 800 I/O por segundo cada um. Volumes NFS não são indicados e SSD conseguem deixar o ambiente com ótima performance. Veja mais sobre requisitos mínimos de instalação aqui.
Para fazer a instalação do produto é necessário acessar o site splunk.com e fazer um pequeno cadastro – assim, além de fazer o download do produto de acordo com a sua plataforma, o usuário já possuirá também um perfil para acessar o fórum oficial de usuários Splunk, conhecido por Splunk Answers e também, baixar aplicativos no Splunkbase, onde a própria Splunk disponibiliza aplicativos desenvolvidos por eles e também aplicativos de terceiros. Tais aplicativos podem ser baixados de dentro da sua instalação de Splunk. Online você encontrará o seguinte conteúdo também:
Depois de instalar o Splunk, precisamos iniciá-lo e trocar as credenciais que vêm configuradas por padrão. Para usuários de Windows, é mais fácil iniciar os serviços do Splunk (Splunkd e Splunkweb) através do painel de serviços. No Linux ou Mac, é necessário utilizar a linha de comando para iniciar, parar ou checar o status atual dos serviços do Splunk.
- Mac – iniciando o Splunk pela primeira vez
localhost:~ wbianchi$ /Applications/splunk/bin/splunk start --accept-license
Splunk> See your world. Maybe wish you hadn’t.
Checking prerequisites…
Checking http port [8000]: open
Checking mgmt port [8089]: open
Checking configuration… Done.
Checking index directory…
Validated databases: _audit _blocksignature _internal _thefishbucket appmgmt blackberry history main msexchange perfmon sos sos_summary_daily summary summary_forwarders summary_indexers teste
Done
Success
Checking conf files for typos…
All preliminary checks passed.
Starting splunk server daemon (splunkd)…
Done.
Starting splunkweb… Done.
If you get stuck, we’re here to help.
Look for answers here: http://docs.splunk.com/Documentation/Splunk
The Splunk web interface is at http://localhost:8000
- Linux – iniciando o Splunk pela primeira vez
root@localhost:~# /opt/splunk/bin/splunk start
splunkd 3997 was not running.
Stopping splunk helpers...
Done.
Stopped helpers.
Removing stale pid file… done.
Splunk> Be an IT superhero. Go home early.
Checking prerequisites…
Checking http port [8000]: open
Checking mgmt port [8090]: open
Checking configuration… Done.
Checking index directory…
Validated databases: _audit _blocksignature _internal _thefishbucket history main os summary
Done
Success
Checking conf files for typos…
All preliminary checks passed.
Starting splunk server daemon (splunkd)…
Done.
Starting splunkweb… Done.
If you get stuck, we’re here to help.
Look for answers here: http://docs.splunk.com/Documentation/Splunk
The Splunk web interface is at http://localhost:8000
Note que tanto no Linux quanto no Mac, utilizamos a flag –accept-license para aceitar a licença e evitar que todo o texto da licença seja exibido no terminal. Ao final da saída do comando de start, perceba que já é informado o endereço para ser acessado via browser para, então, fazermos o primeiro login em nossa instalação de Splunk.
Após o primeiro login, o usuário será convidado a trocar a senha padrão do usuário admin. Inicialmente, a senha é “changeme” e a partir de então, você poderá colocar aquela que você desejar. Sua tela inicial no Splunk deverá ser parecida com a apresentada à seguir:
Adicionando dados
Para fazer a adição de uma nova fonte de dados no Splunk, utilizaremos o arquivo de log gerado pelo servidor de aplicação Apache, que é muito utilizado por vários dos servidores de hospedagem no mundo. Para ir em frente nas práticas que serão realizadas neste artigo, garanta que o seu computador conte com uma instalação do Apache e que o seu servidor Apache esteja rodando.
Adicionar dados ao Splunk é o principal ponto para que a ferramenta, considerando os seus algoritmos internos, comece a indexar informação e a montar os esquemas de dados em arquivos em disco e, por consequência, criar estruturas de reconhecimento de padrões e tendências. Lembro mais uma vez que o Splunk não utiliza um banco de dados relacional, já que as fontes de dados são organizadas inicialmente em um arquivo que representa um índice padrão, que é denominado “main”. Para que possamos adicionar dados, acesse a opção “Add Data” que está localizado na tela logo após o login (veja a imagem abaixo).
![]()
Após clicar em “Add Data”, uma nova tela lhe oferecerá vários dos padrões de eventos suportados para uma instalação padrão do Splunk. Além destes vários padrões, existem vários outros que podem ser adicionados no formato de App através do Splunkbase.
Seguindo com a adição dos logs do Apache, na tela “Add Data to Splunk”, clique na opção “Apache Logs”. Na tela seguinte, clique em “Next”, que está logo abaixo da opção “Consume Apache logs on this Splunk server”. Selecione “Skip Preview” e clique em “Continue”. A próxima tela, denominada “Add New”, é uma tela que configurará como a fonte de dados que será indexada, sendo muito importante que se compreenda as três opções que esta apresenta:
- Continuously index data from a file or directory this Splunk instance can access: fará a indexação continua do arquivo, possibilitando utilizar o monitoramento do arquivo em tempo real através da timeline que veremos mais à frente;
- Upload and index a file: esta opção permite que o usuário que está configurando/adicionando a nova fonte de dados faça o upload de um arquivo que terá o seu conteúdo indexado – esta opção não possibilita o monitoramento em tempo real, sendo indexado todo de uma só vez;
- Index a file once from this Splunk server: esta opção indexa um arquivo no servidor aonde está instalado o Splunk e também não possibilita o seu monitoramento em tempo real.
Como estamos configurando o monitoramento do log do servidor Apache como exemplo, seria interessante termos a opção de monitoramento em tempo real devido à criticidade daquele software. Poderemos com facilidade pesquisar pelos erros padrão do Apache para tornar o processo cada vez mais rico em informação. Escolha a primeira opção, informe no campo “Full Path to Your Data” o caminho no qual se encontra o arquivo de log do apache (access.log). Consulte a tabela a abaixo e verifique se o arquivo de acessos do Apache em seu sistema operacional se encontra no mesmo local.
Se a tela do seu Splunk estiver parecida com a seguinte, clique “Save” e vamos em frente!

Clicando em “Save”, a próxima etapa é “Start Searching”, ou seja, é hora de iniciar a correlacionar os eventos indexados do arquivo de log do Apache. Lembre-se que este á somente um exemplo de utilização e que o Splunk não é nem de longe um software para somente monitorar logs, mas pode ser utilizado para isso também. Veremos a seguir alguns comandos básicos de busca da linguagem Splunk.

Buscando dados indexados
A busca de dados é realizada através do aplicativo padrão chamado “Search App”, que pode ser acessado clicando sobre o link “Start Searching” após adicionar uma nova fonte de dados ou através do menu localizado no canto superior direto, clicando em App >> Search. Tal aplicativo é padrão, pois se encontra em todos os Apps disponíveis para o Splunk, no Splunkbase e é através dele que é possível criar alertas e gráficos para monitoramento dos elementos de TI. Acessando a tela de busca, o usuário contará com três áreas que são: host, source, e sourcetype, once:
- Source é a fonte da informação; aqui pode ser um arquivo ou vários;
- Sourcetype é o tipo de informação, que aqui podem ser de vários tipos – desde de devices até Windows Security Logs, Syslogs, etc. E o Splunk identificará a informação em tempo de execução;
- Host é de onde vem a informação; podendo ser um IP ou DNS.
O usuário poderia colocar somente um * no campo de busca para retornar todos os eventos indexados, mas, SOURCE, SOURCETYPE e HOST são declaração que podem ser utilizadas para filtrar os eventos. Você perceberá que assim que escrever no campo de busca uma das três declarações acima, todas as opções que podem ser aplicadas como valor para tais declarações serão oferecida com uma aba de auto-complete que se abrirá logo abaixo do campo de busca. Isso ajuda e dá mais agilidade ao usuário para determinar, por exemplo, a fonte de dados da qual se deseja obter dados. Lembrando que a fonte de dados é determinada pela declaração SOURCE.
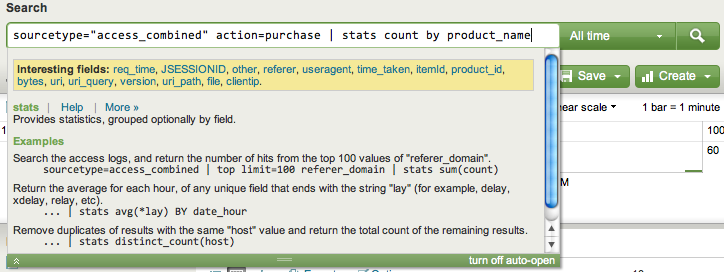
A partir da busca, ou da Search App, é interessante gerarmos consultas que interaja com os dados de acesso ao sistema de e-commerce, por exemplo, sabendo que tal informação é parte do access.log do Apache – o qual estamos indexando continuamente no nosso Splunk. Com isso, podemos escrever a seguinte consulta para gerar uma tabela e por consequência, um gráfico que nos mostra a quantidade de produtos vendidos (isso só analisando logs do apache!!).

Clicando no ícone para gerar o gráfico, temo a seguinte visão – isso em três cliques:
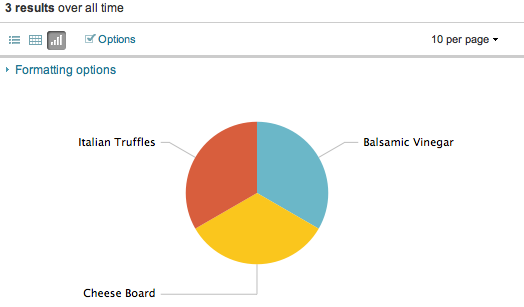
Para maiores informações sobre a maioria dos comandos de busca, acesse o Splunk Quick Reference Card.
Conclusão
Agora que você já instalou o Splunk e aprendeu a adicionar dados do Apache ao mesmo, é hora de aprofundar um pouco mais. E para isso, prometo em um próximo artigo aprofundar na busca por dados utilizando a Search App e a linguagem de busca de dados dentro dos eventos indexados pelo Splunk.
Vou mostrar como implementar gráficos a partir de dados não estruturados e gerar conhecimento para o seu negócio de maneira fácil e rápida. Obtenha aquele relatório que o seu gestor lhe pediu em menos tempo com o Splunk. Além disso, mostrarei como salvar sua busca, criar alertas e dashboards.
Deseja saber mais sobre o produto? Estaremos em São Paulo dia 29/08, clique aqui para saber mais.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?