

Globalização na Netflix
Hoje eu trago a vocês mais uma abertura de código da Netflix e um case de estudo que eles publicaram em seu blog. Este artigo tratará do trabalho existente por trás das pesquisas relacionadas aos títulos da plataforma em diversas linguagens ao redor do mundo, as métricas utilizadas para a otimização das querys, como tratar as especificidades de cada idioma, como os resultados são tratados, além de um minitutorial de teste que você pode implementar.
Tendo lançado o serviço Netflix globalmente em janeiro, eles agora sustentam a pesquisa em 190 países. Atualmente, o Netflix tem suporte para 20 línguas, e isso vai continuar a crescer ao longo do tempo. Alguns dos maiores desafios de suporte de idioma foram encontrados quando eles fizeram o lançamento no Japão e na Coreia, assim como em outros países de língua chinesa e árabe. Eles têm trabalhado o ajuste sobre a pesquisa específica da língua antes de cada lançamento, criando e ajustando os conjuntos de dados localizados dos documentos e suas consultas correspondentes. Enquanto visam a um alto recall para o lançamento de uma nova linguagem, os seus sistemas de classificação se concentram em aumentar a precisão pelo ranking dos resultados mais relevantes no topo da lista.
Durante a fase de pré-lançamento, eles tentaram prever os tipos de falhas que o sistema de busca poderia ter através da criação de uma variedade de consultas de teste, incluindo correspondências exatas, correspondência de prefixo, transliteração e erro de ortografia. Em seguida, foi decidido se a configuração Solr de campo genérico seria capaz de lidar com esses casos ou se uma análise específica do idioma seria necessário ou, então, se um componente personalizado precisaria ser adicionado. Por exemplo, para lidar com questões transliteradas, nome e questões de título em árabe, eles adicionaram um novo componente de mapeamento de caracteres no topo das ferramentas tradicionais de análise Árabe Solr (como stemmer, filtro de normalização etc.), o que aumentou a precisão e o callback para aqueles casos específicos. Para mais detalhes, consulte o anexo do documento de descrição e o patch para o LUCENE-7321.
As pesquisas de suporte para idiomas seguem os esforços de localização, ou seja, isso significa que não suportam línguas que não estão no caminho de localização do Netflix. Esses idiomas não suportados ainda podem ser pesquisados, porém com uma qualidade que não foi testada. Após o lançamento da pesquisa localizada em um país específico, foram analisadas muitas métricas relacionadas para o callback (zero resultados de consultas) e precisão (clique com as taxas etc.) e outras melhorias. Os testes dos datasets foram então usados para o controle de calback quando as alterações foram introduzidas.
O Netflix, mais uma vez, decidiu abrir o seu código. Desta vez, eles abriram o código do framework de testes de consulta que eles usaram para o pré-lançamento e análise de regressão pós lançamento. No blog do Netflix, eles apresentam um caso de uso simples e descrevem como instalar e utilizar a ferramenta com Solr ou ElasticSearch.
Motivação
Ao recuperar os resultados da pesquisa, é útil saber como o sistema de pesquisa lida com os fenômenos específicos de linguagens, como variações morfológicas, palavras de interrupção etc. Ferramentas padrão podem funcionar bem nos casos mais gerais, como a pesquisa da língua Inglesa, mas não tão bem com outras línguas. A fim de medir a precisão dos resultados, pode-se contar manualmente os resultados relevantes e depois calcular a precisão no resultado ‘k’. Porém, fazer isso em uma escala maior é bem complicado, uma vez que requer algumas implementações e possíveis UI personalizadas para indicar dados que sejam verdadeiramente justificados.
É possível que o maior desafio ainda seja medir o recall. É preciso conhecer todos os documentos relevantes na coleção para que isso seja feito com sucesso. Para isso, eles desenvolveram um framework open source que tenta tornar esses desafios mais fáceis de resolver, permitindo que os testers insiram múltiplas consultas válidas por documento usando planilhas do Google. Dessa forma, não há necessidade de uma interface especializada, e o foco do teste poderia ser gasto na entrada dos documentos e nas consultas relacionadas ao formato da planilha. O conjunto de dados pode ser tão pequeno quanto uma centena de documentos e algumas centenas de consultas a fim de recolher as métricas que ajudarão a ajustar o sistema de precisão/recall. Aqui vale ressaltar que essa biblioteca não está preocupada com o ranking dos resultados, mas sim com o ajuste inicial dos resultados, normalmente otimizado para recall. Outros componentes são usados para medir a relevância do ranking.
Descrição
O framework de teste de consulta do Netflix é uma biblioteca que permite que eles testem um conjunto de dados de consultas em um mecanismo de busca. O foco está na manipulação de tokens específicos para diferentes idiomas como: separadores de palavras, caracteres especiais, morfemas, dentre outros. Morfemas são constituintes morfológicos de palavras, eles representam o menor fragmento significativo da palavra. Diferentes conjuntos de dados são mantidos em planilhas do Google, que podem ser facilmente preenchidas pelos testers. Essa biblioteca, em seguida, lê os conjuntos de dados, executa os testes contra o mecanismo de busca e publica os resultados. O conjunto de dados do Netflix tem crescido em cerca de 10 mil documentos, em mais de 20 mil consultas, em mais de 20 idiomas, e não para.
Embora os testes tenham sido feitos sobre campos de título curto, também é plenamente possível usar o framework de encontro aos campos de descrição que variam de pequenos a médios. Entretanto, testar documentos grandes e completos como por exemplo, documentos com 10K caracteres, pode ser uma tarefa problemática, mas os casos de teste podem ser adicionados aos trechos destes documentos.
Exemplo de teste de aplicação
Entrada de dados
Aqui segue um exemplo simples de um caso de uso que ajusta um campo de preenchimento automático curto. Será criado um pequeno conjunto de dados para demonstrar o aplicativo. Assumindo que os passos de configuração descritos no Apêndice A estão concluídos, você deve ter uma planilha como como a seguinte. Nesta planilha foi utilizada a língua sueca para exemplificar:
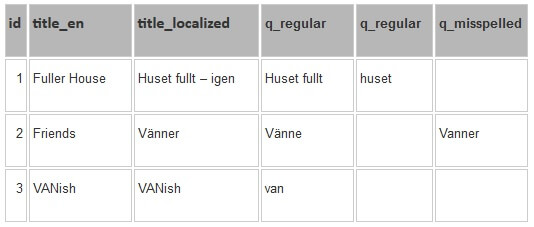
Descrição dos dados de entrada das colunas
- Id – campo obrigatório, pode ser qualquer sequência de caracteres, tem de ser única;
- title_en – obrigatório, nome do documento em inglês;
- title_localized – obrigatório, caracteres localizados no documento;
- q_regular – campos de busca opcionais, é necessário pelo menos um para representar um significado. ‘q_’ significa que algumas consultas serão inseridas nesta coluna. A categoria de consulta segue o underscore e precisa ser compatível na lista de propriedades.
search.query.testing.queryCategories=regular,misspelled
Há cinco consultas no total. Nós vamos testar o título localizado. O título em inglês será usado apenas para depuração. Diversas categorias de consulta podem ser usadas para agrupar os dados do relatório.
Configuração do mecanismo de busca
Por favor, siga o set-up para Solr (Anexo C) ou ElasticSearch (Apêndice D) para executar o primeiro experimento. Na configuração descrita no Anexo C/D, existem quatro campos: id, query_testing_type (necessário para filtragem durante o teste, por isso não há resultados vazados de outros tipos), e dois campos de título – title_en e title_sv.
A pesquisa será feita em título vs. A tokenização do pipeline é:
Index-time:
standard -> lowercase -> ngram
Search-time:
standard -> lowercase
Esse é um cenário de preenchimento automático típico. As consultas podem ser frases que possuem uma fluidez, ou consultas dismax (frase ou não-frase). O Netflix usa a consulta de frase para os testes com ElasticSearch ou consultas Phrase/EDismax com Solr neste exemplo. Essencialmente, o padrão e letras minúsculas são dois itens básicos para muitos cenários diferentes (simplificação dos caracteres especiais e lowercasing), e o ngram produz os tokens Ngram para combinar o prefixo (adequado para um caso de preenchimento automático).
Teste 1: Baseline
Se você executou e configurou a ferramenta contra esses dados (ver apêndices A e B), você deve visualizar o seguinte relatório:
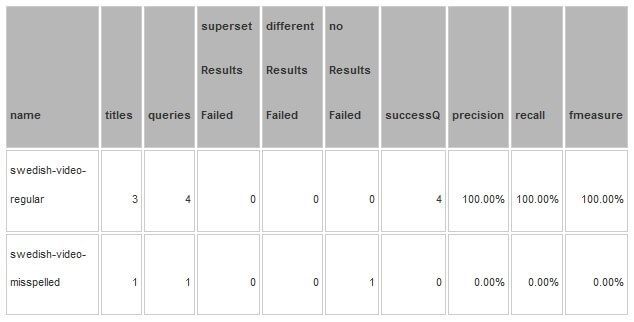
Resumo das descrições das colunas do relatório
- supersetResultsFailed – esta é uma contagem de pedidos de informação que tenham resultados adicionais (que afetam a precisão);
- noResultsFalied – contagem de consultas que não continha os resultados esperados (afetando o recall);
- differentResultsFailed – consultas com uma combinação de ambos – os documentos perdidos e os documentos extras;
- succesQ – consultas que correspondem exatamente à especificação;
- Precision – é calculado para todos os resultados, é o número de documentos relevantes recuperado sobre o número de todos os resultados obtidos;
- Recall – o número de documentos relevantes recuperados sobre o número de todos os resultados relevantes;
- Fmeasure – a média harmônica da precisão e recall.
Todas as medidas são tomadas no nível da consulta. Há um total de três títulos, e cinco consultas. Três consultas são regulares, e uma consulta está na categoria de consulta incorreta. As consultas se separam da seguinte maneira: uma com erros ortográficos que falhou que está no noResultFailed, e quatro que foram concluídas com sucesso.
Detalhes dos resultados
O relatório a seguir mostra os detalhes específicos para a consulta que falhou:

Observe que o relatório de detalhes não exibe os resultados que foram obtidos como esperado, ele só mostra a diferença dos resultados que falharam. Em outras palavras, se você não vê um título na coluna “actual” para uma consulta particular, isso significa que o teste passou.
Teste 2: Adicionando ASCII dobrável
O caso de tratar o caractere ‘a’ em ASCII como um erro de ortografia pode ser discutível, mas não resolve o problema. Digamos que se decidiu “consertar” esse problema e aplicar a dobra ASCII. A única mudança foi a adição de um analisador de dobramento ASCII para o time index e tempo de busca (ver Anexo C ou Anexo D para as alterações de configuração).
Se os testes forem executados novamente, podemos ver que a consulta com erro ortográfico foi consertada em detrimento da precisão da categoria de consulta ‘regular’:
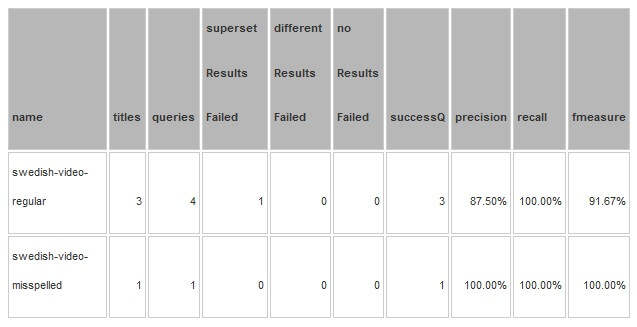
A tabela _dif mostra os detalhes das mudanças. O campo de comentários é preenchido com a mudança de status de cada item.
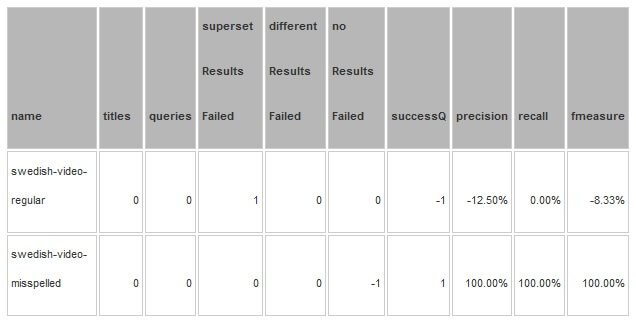
O relatório de detalhes mostra as mudanças específicas (um item foi consertado, uma falha é nova):

Neste ponto, pode-se decidir que os novos supersetResultsFailed são realmente um resultado legítimo (Vänner), então vá em frente e adicione consulta ‘van’ a esse título na planilha de entrada.
Resumo
Ajustar um sistema de busca pela modificação do processo de tokens de extração/normalização pode ser complicado porque exige metas para equilibrar a precisão/recall. Ao mesmo tempo, testar com uma única consulta não irá fornecer um quadro completo dos potenciais efeitos colaterais que afetam as alterações. Então, eles descobriram que utilizar a abordagem descrita aqui dava melhores resultados em geral, bem como permitia fazer testes de regressão enquanto introduziam alterações. Além disso, as formas colaborativas das planilhas do Google permitiam que os testers inserissem os dados, adicionassem os novos casos, e comentassem sobre as questões, assim como uma rápida volta de execução do completo conjunto de testes fornecia a capacidade de executar através de todo o ciclo de testes de maneira mais rápida.
Manutenção dos dados
O uso da biblioteca é projetado para usuários avançados de Solr/ElasticSearch. NÃO USE ISSO EM PRODUÇÃO. A eliminação de qualquer dado foi removida da biblioteca pelo design. Quando o conjunto de dados ou configuração é atualizado (por exemplo, novos testes são executados), o mecanismo de busca e a remoção do conjunto de dados obsoletos são de responsabilidade do desenvolvedor. No entanto, os usuários devem ter em mente que se eles executarem essa biblioteca em um nó prod ao vivo, enquanto usam o Live prod doc ID, os documentos de teste irão substituir o documento existente.
***
Fonte: http://techblog.netflix.com/2016/07/global-languages-support-at-netflix.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?