

Olá a todos novamente!
Hoje farei uma introdução à biblioteca scikit-learn de Python. Se você procurar no Google “machine learning library”, imagino que esse vai ser o primeiro resultado. E não é a toa, o scikit é fácil de usar, extramamente completo e possui muito material na internet.
Para exemplificar os principais pontos da biblioteca, faremos uma análise de evasão (churning).
Mas, “Senhor Mendes”, o que é churning?
Churning
A palavra churning em inglês possui vários significados: agitar leite em uma máquina para produzir manteiga e mover algo com muita força são algumas delas.
Mas a definição que queremos hoje é a de evasão – no caso, evasão de clientes. É bem simples: uma empresa tem (normalmente) muitos consumidores; por algum motivo, alguns deles querem abandonar a marca e/ou parar de utilizar o produto. Esses clientes estão evadindo, o que normalmente gera uma diminuição no lucro da empresa (e ninguém gosta de perder dinheiro, não é mesmo?).
O objetivo de uma análise de evasão é tentar entender os motivos dessa saída do cliente. Falamos um pouco sobre isso no artigo sobre análise de sobrevivência.
Hoje tentaremos prever quais clientes abandonarão a empresa/produto. Tendo essas informações em mãos, a empresa poderia entrar em contato com esses clientes de forma proativa, oferecendo um novo plano ou um BB-8 de controle remoto (quem não quer um BB-8 de controle remoto?).
Hora de programar

Dados: Vamos utilizar uma base de dados de churning comum na internet (você pode baixar o CSV).
Novamente, estou utilizando o Jupyter Notebook (antigo IPython Notebook) para escrever o artigo e fazer toda a programação. Você pode baixar o arquivo aqui e rodar em seu computador.
from __future__ import division
import pandas as pd
import numpy as np
# Primeiro, vamos ler o csv usando a biblioteca pandas.
df_churn = pd.read_csv('churn.csv')
# Agora vamos ver como se parecem esses dados.
df_churn.head()
<code class="language-python" data-lang="python"><span class="n">df_churn</span><span class="o">.</span><span class="n">head</span><span class="p">()</span>
</code>
| State | Account Length | Area Code | Phone | Int’l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | … | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | Churn? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KS | 128 | 415 | 382-4657 | no | yes | 25 | 265.1 | 110 | 45.07 | … | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 | False. |
| 1 | OH | 107 | 415 | 371-7191 | no | yes | 26 | 161.6 | 123 | 27.47 | … | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 | False. |
| 2 | NJ | 137 | 415 | 358-1921 | no | no | 0 | 243.4 | 114 | 41.38 | … | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 | False. |
| 3 | OH | 84 | 408 | 375-9999 | yes | no | 0 | 299.4 | 71 | 50.90 | … | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 | False. |
| 4 | OK | 75 | 415 | 330-6626 | yes | no | 0 | 166.7 | 113 | 28.34 | … | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 | False. |
Utilizamos no código acima a biblioteca pandas, lemos o CSV e passamos para um dataframe.
Pré-processamento dos dados
Antes de trabalhar com essa matriz, vamos limpar dados redundantes e não discriminantes.
Os campos de “Phone” e “Area Code” podem ser removidos da matriz.
df_churn.drop(['Area Code','Phone'], axis=1, inplace=True)
Agora, vamos separar a resposta em um vetor. Além disso, vamos transformar o “True” para 1 e o “False” para 0.
Depois disso, vamos remover a resposta do dataframe com os dados e visualizar o vetor de resposta e a tabela resultante. Essa separação é necessária para se adequar a interface dos modelos de predição do Scikit.
# adiciona uma nova coluna chamada "Churn" com valores booleanos df_churn['Churn'] = df_churn['Churn?'] == 'True.' # Vamos criar um vetor de resposta y trasnformando os booleanos em 0 e 1 y = df_churn['Churn'].as_matrix().astype(np.int) # agora vamos remover as colunas Churn e Churn? de nosso dataframe df_churn.drop(['Churn','Churn?'], axis=1, inplace=True) # Vamos ver como estão nosso dados print str(y) # deve ser composto de 0s e 1s df_churn.head()
[0 0 0 ..., 0 0 0]
| State | Account Length | Int’l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | Eve Mins | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KS | 128 | no | yes | 25 | 265.1 | 110 | 45.07 | 197.4 | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 |
| 1 | OH | 107 | no | yes | 26 | 161.6 | 123 | 27.47 | 195.5 | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 |
| 2 | NJ | 137 | no | no | 0 | 243.4 | 114 | 41.38 | 121.2 | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 |
| 3 | OH | 84 | yes | no | 0 | 299.4 | 71 | 50.90 | 61.9 | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 |
| 4 | OK | 75 | yes | no | 0 | 166.7 | 113 | 28.34 | 148.3 | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 |
A biblioteca do scikit trabalha exclusivamente com atributos numéricos. Logo, é necessário transformar labels” e campos *booleanos em números. No caso, vamos repetir o processo do campo “Churn” para “Int’l Plan” e “VMail Plan” e transformar “yes” em 1 e “no” em 0.
yes_or_no = ["Int'l Plan","VMail Plan"] df_churn[yes_or_no] = df_churn[yes_or_no] == 'yes' df_churn[yes_or_no] = df_churn[yes_or_no].astype(np.int) df_churn.head()
| State | Account Length | Int’l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | Eve Mins | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KS | 128 | 0 | 1 | 25 | 265.1 | 110 | 45.07 | 197.4 | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 |
| 1 | OH | 107 | 0 | 1 | 26 | 161.6 | 123 | 27.47 | 195.5 | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 |
| 2 | NJ | 137 | 0 | 0 | 0 | 243.4 | 114 | 41.38 | 121.2 | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 |
| 3 | OH | 84 | 1 | 0 | 0 | 299.4 | 71 | 50.90 | 61.9 | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 |
| 4 | OK | 75 | 1 | 0 | 0 | 166.7 | 113 | 28.34 | 148.3 | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 |
Agora, vamos lidar com o campo “State”. Ele possui valores em formato de string que transformaremos em números. Para isso podemos usar o LabelEnconder da biblioteca sklearn.
from sklearn import preprocessing # primeiro vamos criar um label encoder le_state = preprocessing.LabelEncoder() #agora vamos passar a coluna State le_state.fit(df_churn['State']) print 'Labels' print str(list(le_state.classes_)) df_churn['State'] = le_state.transform(df_churn['State']) #podemos também sair do valor numerico e chegar na label print '\nNúmero para label' print(list(le_state.inverse_transform([16, 35, 31]))) df_churn.head()
Labels ['AK', 'AL', 'AR', 'AZ', 'CA', 'CO', 'CT', 'DC', 'DE', 'FL', 'GA', 'HI', 'IA', 'ID', 'IL', 'IN', 'KS', 'KY', 'LA', 'MA', 'MD', 'ME', 'MI', 'MN', 'MO', 'MS', 'MT', 'NC', 'ND', 'NE', 'NH', 'NJ', 'NM', 'NV', 'NY', 'OH', 'OK', 'OR', 'PA', 'RI', 'SC', 'SD', 'TN', 'TX', 'UT', 'VA', 'VT', 'WA', 'WI', 'WV', 'WY'] Número para label ['KS', 'OH', 'NJ']
| State | Account Length | Int’l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | Eve Mins | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16 | 128 | 0 | 1 | 25 | 265.1 | 110 | 45.07 | 197.4 | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 |
| 1 | 35 | 107 | 0 | 1 | 26 | 161.6 | 123 | 27.47 | 195.5 | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 |
| 2 | 31 | 137 | 0 | 0 | 0 | 243.4 | 114 | 41.38 | 121.2 | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 |
| 3 | 35 | 84 | 1 | 0 | 0 | 299.4 | 71 | 50.90 | 61.9 | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 |
| 4 | 36 | 75 | 1 | 0 | 0 | 166.7 | 113 | 28.34 | 148.3 | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 |
Vamos, então, dar uma olhada em como os valores dessa tabela se comportam?
Primeiro, veremos a média, mediana, variância e o desvio padrão de alguns campos.
# Primeiro vamos pegar os nomes das colunas
col_names = ['Account Length','Day Mins','Day Calls','Day Charge','Intl Calls', 'CustServ Calls']
# Agora vamos mostrar a média
for name in col_names:
print name
print 'Média:' + str(df_churn[name].mean())
print 'Mediana:' + str(df_churn[name].median())
print 'Variância:' + str(df_churn[name].var())
print 'Desvio Padrão:' + str(df_churn[name].std())
print '\n'
Account Length Média:101.064806481 Mediana:101.0 Variância:1585.80012059 Desvio Padrão:39.8221059286 Day Mins Média:179.77509751 Mediana:179.4 Variância:2966.69648652 Desvio Padrão:54.4673892024 Day Calls Média:100.435643564 Mediana:101.0 Variância:402.76814092 Desvio Padrão:20.0690842073 Day Charge Média:30.5623072307 Mediana:30.5 Variância:85.7371282585 Desvio Padrão:9.25943455393 Intl Calls Média:4.47944794479 Mediana:4.0 Variância:6.05757568554 Desvio Padrão:2.46121427055 CustServ Calls Média:1.56285628563 Mediana:1.0 Variância:1.73051668912 Desvio Padrão:1.31549104487
E analisaremos um pouco as entradas booleanas.
bool_fields = ['Int\'l Plan','VMail Plan']
# Agora vamos mostrar a somatoria
print 'Total de usuários: ' + str(len(df_churn['VMail Plan']))
print '\n'
for name in bool_fields:
print name
print 'Soma: ' + str(df_churn[name].sum())
print 'Percentual: ' + str(df_churn[name].sum()/len(df_churn[name]))
print '\n'
Total de usuários: 3333 Int'l Plan Soma: 323 Percentual: 0.0969096909691 VMail Plan Soma: 922 Percentual: 0.276627662766
Vamos olhar outro dado importante: quantos casos de churning temos nesses 3333 usuários.
print('Número total de usuários: {}'.format(y.shape[0]))
print('Quantidade de churn: {}'.format(y.sum()))
print('Percentual de churn: {}'.format(y.sum()/y.shape[0]))
Número total de usuários: 3333 Quantidade de churn: 483 Percentual de churn: 0.144914491449
Temos, então, 14.4% de casos de churning dentro dos nossos 3333 usuários observados, o que mostra um desbalanceamento de classes.
O próximo passo no tratamento/processamento da entrada é normalizar os seus valores entre aproximadamente -1.0 e 1.0. Para isso, utilizaremos o StandardScaler.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() print 'X antes de dimensionar\n' print str(df_churn.head()) X = scaler.fit_transform(df_churn) print '\nValores depois do StandardScaler\n' print str(X)
X antes de dimensionar State Account Length Int'l Plan VMail Plan VMail Message Day Mins \ 0 16 128 0 1 25 265.1 1 35 107 0 1 26 161.6 2 31 137 0 0 0 243.4 3 35 84 1 0 0 299.4 4 36 75 1 0 0 166.7 Day Calls Day Charge Eve Mins Eve Calls Eve Charge Night Mins \ 0 110 45.07 197.4 99 16.78 244.7 1 123 27.47 195.5 103 16.62 254.4 2 114 41.38 121.2 110 10.30 162.6 3 71 50.90 61.9 88 5.26 196.9 4 113 28.34 148.3 122 12.61 186.9 Night Calls Night Charge Intl Mins Intl Calls Intl Charge \ 0 91 11.01 10.0 3 2.70 1 103 11.45 13.7 3 3.70 2 104 7.32 12.2 5 3.29 3 89 8.86 6.6 7 1.78 4 121 8.41 10.1 3 2.73 CustServ Calls 0 1 1 1 2 0 3 2 4 3 Valores depois do StandardScaler [[-0.6786493 0.67648946 -0.32758048 ..., -0.60119509 -0.0856905 -0.42793202] [ 0.6031696 0.14906505 -0.32758048 ..., -0.60119509 1.2411686 -0.42793202] [ 0.33331299 0.9025285 -0.32758048 ..., 0.21153386 0.69715637 -1.1882185 ] ..., [ 0.87302621 -1.83505538 -0.32758048 ..., 0.61789834 1.3871231 0.33235445] [-1.35329082 2.08295458 3.05268496 ..., 2.24335625 -1.87695028 0.33235445] [ 1.07541867 -0.67974475 -0.32758048 ..., -0.19483061 1.2411686 -1.1882185 ]]
Avaliando o modelo (matriz de confusão e métricas de sucesso)
Agora vamos definir nossa função para avaliar o modelo com um cross-validation. Nesse caso, vou utilizar o StratifiedKFold, já que existe um desbalanceamento de classes.
O StratifiedKFold mantém o percentual de cada classe nos folds gerados, impedindo que tenhamos pouquíssimos ou nenhum caso de evasão em algum dos folds.
Além disso, vamos criar uma função que desenha a matriz de confusão.
from sklearn import cross_validation
# função que realiza a divisão de folds e retorna o y previsto
def stratified_cv(X, y, clf_class, shuffle=True, n_folds=10, **kwargs):
stratified_k_fold = cross_validation.StratifiedKFold(y, n_folds=n_folds, shuffle=shuffle, random_state=12)
y_pred = y.copy()
for ii, jj in stratified_k_fold:
X_train, X_test = X[ii], X[jj]
y_train = y[ii]
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
y_pred[jj] = clf.predict(X_test)
return y_pred
import pylab as pl
import matplotlib.pyplot as plt
%matplotlib inline
def plot_confusion_matrix(cm, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
def test_classifier(X,y,print_cm,classifier,**kwargs):
# testando com Random Forest
y_pred = stratified_cv(X, y, classifier,**kwargs)
# Acurácia
print 'Acurácia do modelo: ' + str(accuracy_score(y,y_pred))
print 'F1 do modelo: ' + str(f1_score(y,y_pred))
if print_cm:
# adicionando resultado na matriz de confusão
cm = confusion_matrix(y, y_pred)
print '\nMatriz de confusão'
print str(cm)
plot_confusion_matrix(cm)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print('\nMatriz de confusão normalizada')
plt.figure()
plot_confusion_matrix(cm_normalized, title='Normalized confusion matrix')
print(cm_normalized)
test_classifier(X,y,True,RF,random_state=12)
Acurácia do modelo: 0.940894089409 F1 do modelo: 0.760048721072 Matriz de confusão [[2824 26] [ 171 312]] Matriz de confusão normalizada [[ 0.99087719 0.00912281] [ 0.35403727 0.64596273]]
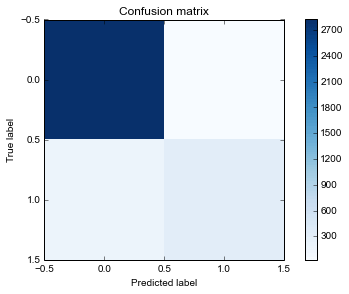
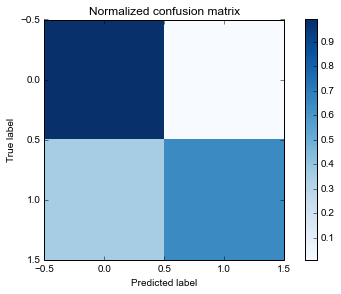
Primeiramente, preciso dizer que estamos utilizando o algoritmo Random Forests, que utiliza várias árvores de decisão para fazer a classificação. Passamos para ele a matriz X com as features e o vetor y de respostas.

Como estamos considerando aqui o problema como uma classificação binária, precisamos escolher uma métrica de sucesso condizente. No caso, vamos mostrar tanto a acurácia, que é simples de entender e explicar, quanto a métrica f1, que é mais apropriada para avaliar o modelo quando existe um desbalanceamento de classes.
Utilizamos também a matriz de confusão normalizada para melhor visualizar o quão bem o modelo prevê o churning.
Agora vamos listar a importância das features.
Fonte: Feature importances with forests of trees
Importância de features
A importância de uma feature mostra o quão relevante ela foi considerada na criação do modelo. Essa informação pode ser utilizada para selecionar as melhores features para um modelo (Feature Selection).
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
def feature_importance(X,y):
# Build a forest and compute the feature importances
forest = RandomForestClassifier(random_state=12)
forest.fit(X, y)
importances = forest.feature_importances_
std = np.std([tree.feature_importances_ for tree in forest.estimators_],
axis=0)
indices = np.argsort(importances)[::-1]
# Print the feature ranking
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# Plot the feature importances of the forest
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices],
color="r", yerr=std[indices], align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()
i = 0
for feature in df_churn.columns.tolist():
print str(i) + ' - ' +feature
i += 1
print '\n'
feature_importance(X,y)
0 - State 1 - Account Length 2 - Int'l Plan 3 - VMail Plan 4 - VMail Message 5 - Day Mins 6 - Day Calls 7 - Day Charge 8 - Eve Mins 9 - Eve Calls 10 - Eve Charge 11 - Night Mins 12 - Night Calls 13 - Night Charge 14 - Intl Mins 15 - Intl Calls 16 - Intl Charge 17 - CustServ Calls Feature ranking: 1. feature 5 (0.150194) 2. feature 17 (0.122422) 3. feature 7 (0.121427) 4. feature 8 (0.078148) 5. feature 2 (0.074473) 6. feature 10 (0.070833) 7. feature 14 (0.045192) 8. feature 15 (0.042706) 9. feature 11 (0.038932) 10. feature 16 (0.037543) 11. feature 12 (0.035036) 12. feature 13 (0.034994) 13. feature 6 (0.031734) 14. feature 1 (0.028708) 15. feature 9 (0.024622) 16. feature 3 (0.022160) 17. feature 0 (0.020662) 18. feature 4 (0.020216)
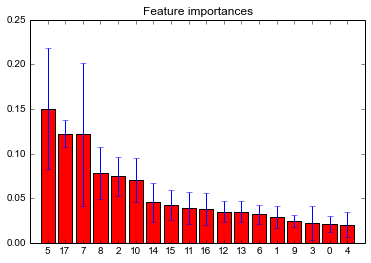
Podemos ver por esses dados que as features mais importantes são:
- Day Charge
- Day Mins
- Customer Service Calls
Isso faz sentido, uma vez que um usuário que utiliza pouco e/ou faz muitas ligações para o SAC tem uma chance maior de cancelar seu plano.
Vamos agora variar alguns hyper-parâmetros do classificador?
Vamos utilizar aqui o GridSearchCV. Ele analisa todas as combinações possíveis e escolhe a melhor baseada na métrica desejada.
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
def gridSearch(X,y,classifier, tuned_parameters):
scores = ['f1', 'accuracy']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=0)
for score in scores:
print("# Otimização hyper-parametros para %s" % score)
clf = GridSearchCV(classifier, tuned_parameters, cv=5,
scoring=score)
clf.fit(X_train, y_train)
print("Melhores parâmetros encontrados no conjunto de treino:")
print
print(clf.best_params_)
print
print("Resultado do grid:")
print
for params, mean_score, scores in clf.grid_scores_:
print("%0.3f (+/-%0.03f) for %r"
% (mean_score, scores.std() * 2, params))
print
print("Detalhamento:")
print
print("O modelo é treinado com o conjunto de treino")
print("Os resultados finais são do conjunto de teste")
print
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred))
print
tuned_parameters = [{'n_estimators': [10,100,250],'max_features':['auto','sqrt','log2', None]}]
# Buckle up, this may take a while
gridSearch(X,y,RandomForestClassifier(random_state=12),tuned_parameters)
# Otimização hyper-parametros para f1
Melhores parâmetros encontrados no conjunto de treino:
{'max_features': 'auto', 'n_estimators': 250}
Resultado do grid:
0.687 (+/-0.081) for {'max_features': 'auto', 'n_estimators': 10}
0.806 (+/-0.062) for {'max_features': 'auto', 'n_estimators': 100}
0.815 (+/-0.054) for {'max_features': 'auto', 'n_estimators': 250}
0.687 (+/-0.081) for {'max_features': 'sqrt', 'n_estimators': 10}
0.806 (+/-0.062) for {'max_features': 'sqrt', 'n_estimators': 100}
0.815 (+/-0.054) for {'max_features': 'sqrt', 'n_estimators': 250}
0.687 (+/-0.081) for {'max_features': 'log2', 'n_estimators': 10}
0.806 (+/-0.062) for {'max_features': 'log2', 'n_estimators': 100}
0.815 (+/-0.054) for {'max_features': 'log2', 'n_estimators': 250}
0.751 (+/-0.109) for {'max_features': None, 'n_estimators': 10}
0.787 (+/-0.068) for {'max_features': None, 'n_estimators': 100}
0.793 (+/-0.069) for {'max_features': None, 'n_estimators': 250}
Detalhamento:
O modelo é treinado com o conjunto de treino
Os resultados finais são do conjunto de teste
precision recall f1-score support
0 0.96 0.98 0.97 1422
1 0.87 0.73 0.80 245
avg / total 0.94 0.94 0.94 1667
# Otimização hyper-parametros para accuracy
Melhores parâmetros encontrados no conjunto de treino:
{'max_features': 'auto', 'n_estimators': 250}
Resultado do grid:
0.927 (+/-0.018) for {'max_features': 'auto', 'n_estimators': 10}
0.951 (+/-0.014) for {'max_features': 'auto', 'n_estimators': 100}
0.953 (+/-0.011) for {'max_features': 'auto', 'n_estimators': 250}
0.927 (+/-0.018) for {'max_features': 'sqrt', 'n_estimators': 10}
0.951 (+/-0.014) for {'max_features': 'sqrt', 'n_estimators': 100}
0.953 (+/-0.011) for {'max_features': 'sqrt', 'n_estimators': 250}
0.927 (+/-0.018) for {'max_features': 'log2', 'n_estimators': 10}
0.951 (+/-0.014) for {'max_features': 'log2', 'n_estimators': 100}
0.953 (+/-0.011) for {'max_features': 'log2', 'n_estimators': 250}
0.935 (+/-0.028) for {'max_features': None, 'n_estimators': 10}
0.943 (+/-0.019) for {'max_features': None, 'n_estimators': 100}
0.945 (+/-0.019) for {'max_features': None, 'n_estimators': 250}
Detalhamento:
O modelo é treinado com o conjunto de treino
Os resultados finais são do conjunto de teste
precision recall f1-score support
0 0.96 0.98 0.97 1422
1 0.87 0.73 0.80 245
avg / total 0.94 0.94 0.94 1667
Lembrando que o GridSearchCV utilizado aqui pode demorar muito, dependendo do número de hyper-parâmetros, dado que ele testará todas as combinações possíveis. Existem outras maneiras de variar esses hyper-parâmetros; para aprender mais sobre isso visite a página relativa a GridSearch.
Podemos ver, depois de todos esses testes, que o melhor resultado encontrado foi com os seguintes parâmetros do classificador:
{‘max_features’: ‘auto’, ‘n_estimators’: 250}
Vamos agora verificar como fica nossa matriz de confusão com esses parâmetros.
test_classifier(X,y,False,RandomForestClassifier,max_features='auto', n_estimators= 250,random_state=12)
Acurácia do modelo: 0.954695469547 F1 do modelo: 0.825433526012
Podemos ver que houve uma pequena melhora dos resultados variando os hyper-parâmetros.
Antigos:
- Acurácia do modelo: 0.940894089409
- F1 do modelo: 0.760048721072
Novos:
- Acurácia do modelo: 0.954695469547
- F1 do modelo: 0.825433526012
Para finalizar nosso exemplo, vamos tentar gerar mais features?
Vamos utilizar PolynomialFeatures. Com ele conseguimos gerar mais colunas em nossa tabela X, gerando features baseados nos dados existentes.
No caso, se você possui duas features [a,b] essa operação irá gerar [1, a, b, a^2, ab, b^2] – isto é, vai combinar as features com elas mesmas e com as outras.
from sklearn.preprocessing import PolynomialFeatures print 'Número de features: ' + str(X.shape[1]) poly = PolynomialFeatures(2) X_poly = poly.fit_transform(X) print '\nNúmero de features depois da transformação: ' + str(X_poly.shape[1])
Número de features: 18 Número de features depois da transformação: 190
Saímos de 18 features para 190!
Outra opção é não gerar as features que são combinações delas mesmas, passando o parâmetro interaction_only como true. Dessa forma, apenas as combinações de features serão geradas.
Exemplo: [1,a,b,ab]
poly_less = PolynomialFeatures(interaction_only=True) X_poly_less = poly_less.fit_transform(X) print '\nNúmero de features com interaction_only: ' + str(X_poly_less.shape[1])
<code class="language-" data-lang="">Número de features com interaction_only: 172</code>
Vamos testar nosso classificador agora com 190 features.
test_classifier(X_poly,y,False,RandomForestClassifier,max_features='auto', n_estimators= 250, n_jobs=-1, random_state=12)
Acurácia do modelo: 0.952895289529 F1 do modelo: 0.818497109827
Uai (sim, sou mineiro), temos mais features e o valor da acurácia piorou?
Provavelmente, isso aconteceu pois fizemos o GridSearch para as 18 features iniciais ou as novas entradas adicionam ruído.
Vamos testar agora um GridSearch nesse hiper-parâmetro para nossas 190 features.
tuned_parameters = [{'max_features':['auto','sqrt','log2', None]}]
# Buckle up, this REALLY may take a while
gridSearch(X_poly,y,RandomForestClassifier(n_estimators= 250, n_jobs=-1),tuned_parameters)
# Otimização hyper-parâmetros para f1
Melhores parâmetros encontrados no conjunto de treino:
{'max_features': None}
Resultado do grid:
0.798 (+/-0.063) for {'max_features': 'auto'}
0.783 (+/-0.045) for {'max_features': 'sqrt'}
0.693 (+/-0.094) for {'max_features': 'log2'}
0.803 (+/-0.064) for {'max_features': None}
Detalhamento:
O modelo é treinado com o conjunto de treino
Os resultados finais são do conjunto de teste
precision recall f1-score support
0 0.96 0.97 0.97 1422
1 0.84 0.75 0.79 245
avg / total 0.94 0.94 0.94 1667
# Otimização hyper-parâmetros para accuracy
Melhores parâmetros encontrados no conjunto de treino:
{'max_features': 'sqrt'}
Resultado do grid:
0.947 (+/-0.016) for {'max_features': 'auto'}
0.950 (+/-0.016) for {'max_features': 'sqrt'}
0.928 (+/-0.012) for {'max_features': 'log2'}
0.950 (+/-0.013) for {'max_features': None}
Detalhamento:
O modelo é treinado com o conjunto de treino
Os resultados finais são do conjunto de teste
precision recall f1-score support
0 0.96 0.98 0.97 1422
1 0.88 0.73 0.80 245
avg / total 0.94 0.95 0.94 1667
test_classifier(X_poly,y,False,RandomForestClassifier,max_features='sqrt', n_estimators= 250, n_jobs=-1, random_state=12)
Acurácia do modelo: 0.952895289529 F1 do modelo: 0.818497109827
Demorou MUITO para rodar e mesmo assim não melhoramos o resultado. Talvez alguma dessas 172 features seja interessante, mas parece que o ruído que elas geram não melhora o resultado.
Conclusão
Nesse artigo, passamos por praticamente todas as etapas de um projeto de ciência de dados: limpamos, pré-processamos e criamos novos dados. Também fizemos um gridsearch para achar os melhores hiper-parâmetros e verificamos os resultados vendo as métricas (acurácia e f1), além de verificar a matriz de confusão gerada.
Logicamente, em um projeto real de churning existem outras complicações. Normalmente os dados são por tempo, e no CSV utilizado aqui, foram apenas os dados relativos a um mês. Além disso, em projetos de evasão temos que levar em conta o negócio para encontrar as melhores métricas de sucesso e o melhor algoritmo. Pode ser que você tenha que retornar uma lista de tamanho definido com os clientes com maior probabilidade de saída, mas com o ferramental apresentado nesse post é possível atacar esses problemas.
Espero que o artigo tenha sido interessante e os ajude a usar o Scikit.
Abraços e até a próxima!
***
Artigo publicado originalmente em: http://developers.hekima.com/machine%20learning/python/2016/05/17/churn-prediction/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?