

Eu sempre falo um pouco sobre estatística e, como um grande cético, creio que eu possa pensar além do “senso comum” em que muitas pessoas confiam. Sou muito familiarizado com tendenciosidades, dados distorcidos e perguntas erradas levando a respostas erradas.
Provavelmente, posso detalhar por que um argumento está errado. Mas sou muito incompetente no caminho contrário: dada uma coleção apropriada de dados, como analisá-los de maneira exploratória corretamente? Quais as metodologias corretas para cada cenário dado? E, claro, qual a matemática envolvida?
Por exemplo, eu postei recentemente dois artigos para tentar jogar alguma luz exatamente sobre isso: O “senso comum” da maioria dos desenvolvedores para lidar com dados é utilizar agregações primitivas como somas e médias. Comece a falar sobre o “desvio padrão”, e você perdeu a metade da população de desenvolvedores. Comece a falar sobre distribuições poisson ou binomial, e você perdeu a outra metade. Agora fale sobre regressão linear, estatísticas Bayesianas, e quase todos os que tinham restado na sala já saíram.
Nós vivemos no século 21. A cada 60 segundos,o Facebook recebe 3,3 milhões de novos posts; o YouTube recebe 400 horas de vídeos; o Instagram recebe 55.555 fotos; o WhatsApp troca 44,4 milhões de mensagens; mais de 206 milhões de e-mails são enviados. Quando você terminar de ler este artigo, pode multiplicar esse número por 5 ou 10!
Estamos nos afogando em informação, mas famintos de conhecimento – vários autores, provavelmente original de John Naisbitt.
Passarei algumas semanas me aprofundando em R. Sim, muitas pessoas falarão de Julia, mas não podemos negar o incrível corpo de conhecimento, a experiência, o robusto e extenso conjunto de pacotes disponível para R, incluindo o material de aprendizado. Existe uma ótima ferramenta, RStudio, da qual acabei de ver a versão 1.0.
E entre todo o material que coletei, um se sobressaiu somente por sua introdução (ainda estou para revisar os livros completos). É chamado “Learning Statistics with R”, de Daniel Navarro, da Universidade de Adelaide, Austrália. Eu achei interessante porque é um professor de psicologia ensinando estatística através da base do R, que é exatamente o que eu queria. Você pode comprar uma cópia impressa ou baixar o PDF gratuito.
Eu gosto tanto da introdução que quero compartilhar alguns parágrafos para motivar você a se juntar a mim no melhor aprendizado de estatística. Então, vamos nos aprofundar nisso.
O conto cauteloso do paradoxo de Simpson
A história a seguir é verdadeira. Em 1973, a Universidade da Berkeley encontrou alguns problemas com as admissões dos alunos nos cursos de pós-graduação. Especificamente, o que causou o problema foi que a separação por gênero deles ficou assim…
| Número de candidatos | Percentual admitido | |
| Masculino | 8442 | 44% |
| Feminino | 4321 | 35% |
… e eles foram processados. Dado que houve aproximadamente 13 mil candidaturas, uma diferença de 9% entre taxas de admissão de homens e mulheres é muito grande para ser coincidência. Dados bastante persuasivos, certo? E se eu dissesse que esses dados realmente refletem uma pequena tendência para as mulheres, você certamente diria que sou louco ou sexista.
Estranhamente, isso é quase verdade… depois que Berkeley foi processada, as pessoas passaram a olhar muito cuidadosamente para os dados das admissões (Bickel, Hammel, & O’Connell, 1975). E, notavelmente, quando elas observaram departamento por departamento, descobriram que na maioria dos departamentos, na verdade, havia uma taxa de sucesso mais alta para as mulheres do que para os homens. A tabela abaixo mostra os percentuais de admissão para os seis maiores departamentos (com os nomes dos departamentos removidos por questão de privacidade):
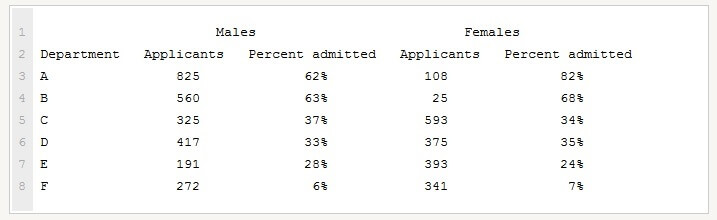
Notavelmente, a maioria dos departamentos tinha uma taxa maior de admissão de mulheres do que de homens! Ainda assim, a taxa geral de admissão na universidade de mulheres era menor que a de homens. Como pode ser? Como ambas afirmações podem ser verdadeiras ao mesmo tempo?
Eis o que está acontecendo. Em primeiro lugar, note que os departamentos não são todos iguais em termos de porcentagens de admissão: alguns departamentos (por exemplo, Engenharia, Química) tenderam a admitir uma maior quantidade dos candidatos qualificados, enquanto outros (como Inglês) tenderam a rejeitar a maioria dos candidatos, mesmo sendo bem qualificados.
Então, entre os seis departamentos mostrados acima, note que o departamento A é o mais generoso, seguido por B, C, D, E e F, nessa ordem. Depois, note que homens e mulheres tenderam a se candidatar a departamentos diferentes. Se nós ranquearmos os departamentos em relação ao total de homens inscritos, temos: A>B>D>C>F>E (os departamentos “fáceis” estão em negrito).
No todo, os homens tenderam a se candidatar aos departamentos com as maiores taxas de admissão. Agora compare isso com a maneira como as candidaturas das mulheres estão distribuídas. Ranqueando os departamentos de acordo com o total de candidatas, temos uma ordem diferente: C>E>D>F>A>B.
Em outras palavras, o que esses dados parecem sugerir é que as mulheres tenderam a se candidatar aos departamentos mais difíceis.
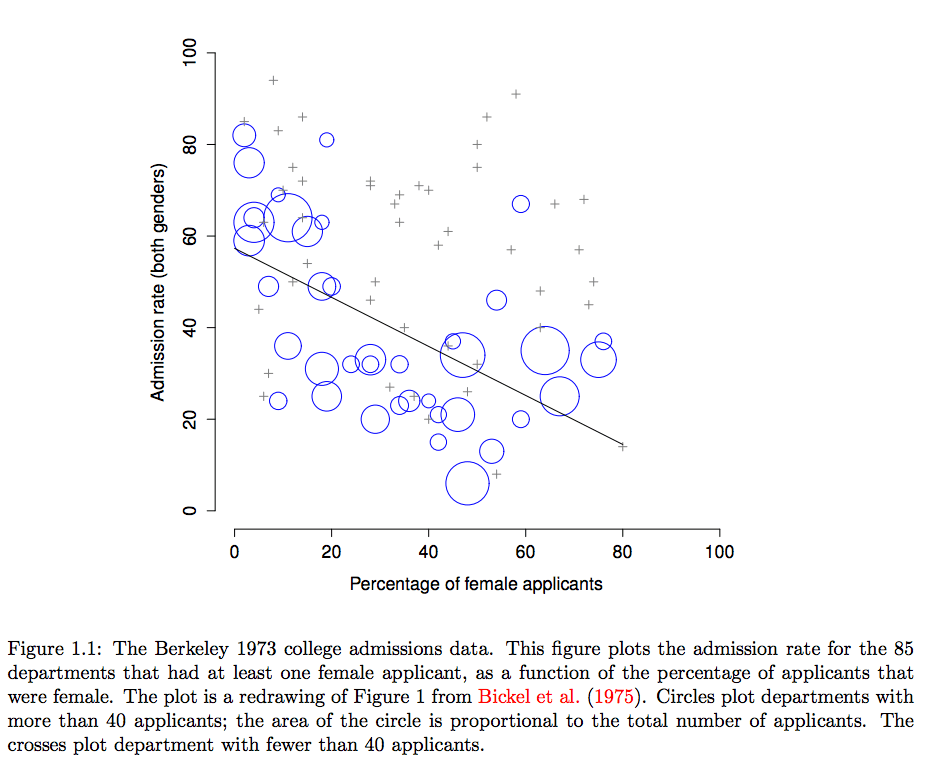
E, de fato, se olharmos para a figura acima, nós vemos que essa tendência é sistemática e bem surpreendente. Esse efeito é chamado de paradoxo de Simpson. Não é comum, mas acontece na vida real, e a maioria das pessoas fica muito surpresa quando o vê pela primeira vez, e muitas se recusam a acreditar que seja real. É muito real. E enquanto existem muitas lições sutis de estatística escondidas aí, eu quero utilizar isso para expressar um ponto muito mais importante… pesquisar é difícil, e existem muitas sutilezas, armadilhas contraditórias escondidas aguardando os ingênuos. Essa é a razão número 2 pela qual os cientistas adoram estatística, e por que nós ensinamos métodos de pesquisa. Porque a ciência é difícil, e a verdade às vezes está astuciosamente escondida pelos cantos e fendas de dados complicados.
Antes de sair inteiramente desse tópico, quero apontar algo realmente crítico que normalmente é ignorado nas aulas de métodos de pesquisa. As estatísticas resolvem somente parte do problema. Lembre-se de que começamos esse tópico com a preocupação de o processo seletivo de Berkeley ser injustamente tendencioso contra as mulheres. Quando olhamos para os dados “agregados”, realmente parecia que a universidade discriminava as mulheres, mas quando “desagregamos” e olhamos o comportamento individual dos departamentos, percebemos que os departamentos estavam, na verdade, ligeiramente a favor das mulheres.
A tendenciosidade no total de admissões foi causada pelo fato de as mulheres se candidatarem para departamentos mais difíceis. Em uma perspectiva puramente legal, isso livra a universidade. As admissões para a pós-graduação são determinadas em um nível individual por departamento (e existem boas razões para isso), e no nível dos departamentos as decisões são mais ou menos tendenciosas (a baixa tendência em relação às mulheres nesse nível é pequena e não é consistente entre os departamentos). Como a universidade não pode dizer quais departamentos as pessoas vão escolher para se candidatar, e a tomada de decisão acontece no nível departamental, ela dificilmente pode ser responsabilizada por quaisquer tendências que as escolhas possam produzir.
Essa foi a base para os meus comentários um pouco superficiais acima, mas essa não é exatamente a história completa, certo? Afinal de contas, se estamos interessados nisso de uma perspectiva mais sociológica ou psicológica, podemos nos perguntar por que existem diferenças tão fortes de gênero nas candidaturas. Por que os homens tendem a se candidatar para engenharia com mais frequência que as mulheres e por que isso é o contrário no departamento de inglês? E por que os departamentos que tendem a ter mais candidaturas de mulheres tendem a ter uma menor taxa de admissão que os que têm mais candidaturas masculinas? Isso ainda poderia refletir uma tendência de gênero, mesmo que cada departamento não seja tendencioso? Sim.
Suponha, hipoteticamente, que os homens prefiram se candidatar para as ciências exatas e as mulheres, para humanas. E suponha também que a razão para as taxas de admissão de humanas serem baixas é que o governo não quer investir em humanas (cursos de Ph.D., por sinal, estão normalmente ligados a projetos de pesquisa custeados pelo governo). Isso constitui uma tendência de gênero? Ou somente uma visão desinformada sobre o valor das ciências humanas? E se alguém em um alto nível do governo cortar o financiamento de humanas porque acha que humanas são “conteúdo inútil de meninas”? Isso parece bem descaradamente preconceituoso. Nada disso entra no alcance da estatística, mas importa para o projeto de pesquisa.
Se você está interessado nos efeitos gerais do sutil preconceito de gêneros, então você provavelmente vai querer olhar para ambos os dados (agregados e desagregados). Se você está interessado na tomada de decisões da Universidade de Berkeley, provavelmente estará interessado somente nos dados desagregados.
Em resumo, existem muitas questões críticas que você não pode responder com estatística, mas as respostas para essas questões terão um grande impacto em como você analisa e interpreta os dados. E essa é a razão pela qual você deveria sempre pensar em estatística como uma ferramenta para ajudar você a aprender sobre seus dados – nem mais, nem menos. É uma ferramenta poderosa para isso, mas não há substituto para o pensamento cuidadoso.
Baixe o livro
Ficou intrigado? Então baixe o livro (em inglês) e vamos estudar estatística além do básico. Não estou dizendo que esse seja o melhor livro, somente um que parece interessante, e se você conhecer um bom livro que ensine estatística para um novato utilizando o R sem conhecimento prévio, avise-me nos comentários.
***
Artigo traduzido com autorização do autor. Publicado originalmente em http://www.akitaonrails.com/2016/11/01/off-topic-learning-statistics.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?