

Paginar e limitar dados no elasticsearch é uma tarefa simples, então, qual o motivo do artigo? Muitas pessoas passam por problemas de performance quando vão a produção por não entender ou não considerar a implementação de determinadas funcionalidades do elasticsearch, uma delas é a paginação.
A paginação usada da maneira default exige muito trabalho repetitivo, tanto dos shards, quanto do coordinator node, por isso tende a se tornar mais custosa com o aumento dos dados.
Paginando resultados no elasticsearch
Por padrão, os dados são limitados a 10 documents. Esse limite pode ser alterando usando o parâmetro size do pagination. No exemplo a seguir, o limite de documents vai ser aumentado para 20:
curl -XPOST "http://192.168.99.100:9200/example/some_type/_search" -d'
{
"query": {
"match_all": {}
},
"size": 20
}'
É possível indicar a partir de onde serão buscados os dados, similar a um offset de banco de dadosSQL, usando o parâmetro “from”:
curl -XPOST "http://192.168.99.100:9200/example/some_type/_search" -d'
{
"query": {
"match_all": {}
},
"size": 20,
"from": 50
}'
Desta maneira o elasticsearch entende que deve buscar um limite de 20 documents a partir de 50 documents. Apesar desse tipo de navegação em dados ser muito utilizada, ela é extremamente custosa e não é recomendada (pela própria elastic) para lidar com grandes volumes de dados. O pagination faz com que todos os shards calculem os dados individualmente e enviem para o coordinator node. O exemplo a seguir mostra uma busca que vai trazer resultados entre 10000 e 10010:
curl -XPOST "http://192.168.99.100:9200/example/some_type/_search" -d'
{
"query": {
"match_all": {}
},
"size": 10,
"from": 10000
}'
Dado um index com 5 shards, cada um irá gerar 10010 resultados para o coordinator node, que receberá um total de 50050 resultados e irá extrair apenas o valor do size, que neste caso é 10. Os outros 50040 documents serão descartados como no exemplo abaixo:
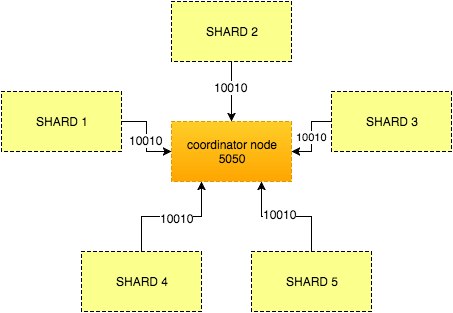
Nas buscas seguintes, o mesmo cálculo terá que ser feito.
Entendendo a Scroll API
Muita vezes, as paginações são feitas sequencialmente, ou seja, sob demanda, por exemplo: next,next,next,next ou pagina 1,2,3 ou até mesmo scrolls incrementais. Para esse tipo de cenário é possível usar a scan/scroll api (que é usada internamente pelo elasticsearch para navegar entre os dados). Ela foi desenhada para trabalhar com grandes volumes de dados sem precisar recalcular o tamanho e nem o ponto onde os dados estão, similar a um ponteiro de banco de dados comum. No exemplo abaixo os resultados da busca serão guardados pela scroll api por 1 minuto:
curl -XPOST "http://192.168.99.100:9200/example/some_type/_search?scroll=1m" -d'
{
"query": {
"match_all": {}
},
"size": 10
}'
O resultado da busca trará além dos documents da resposta também um scroll_id referente ao ponto do próximo volume de dados, similar a este:
"_scroll_id": "cXVlcnlUaGVuRmV0Y2g7NTsyNjprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzI3OmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7Mjg6a21HbHFad3hUa0tMWVlKNk5xakZSQTsyOTprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzMwOmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7MDs="
Agora com o identificador do próximo grupo de documents em mãos, basta fazer uma requisição passando ele:
curl -XPOST "http://192.168.99.100:9200/example/_search/scroll" -d'
{
"scroll" : "1m",
"scroll_id" : "cXVlcnlUaGVuRmV0Y2g7NTsyNjprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzI3OmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7Mjg6a21HbHFad3hUa0tMWVlKNk5xakZSQTsyOTprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzMwOmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7MDs="
}'
Os próximos documents serão retornados junto a um novo scroll_id referente ao próximo grupo de documents.
Para entender melhor, veja abaixo o exemplo de busca com size de 10:
curl -XPOST "http://192.168.99.100:9200/example/some_type/_search?scroll=1m" -d'
{
"query": {
"match_all": {}
},
"size": 10
}'
Internamente, o elasticsearch irá produzir algo como a imagem abaixo, ou seja, uma lista dedocuments em grupos de 10 (size) e irá devolver os primeiros 10 resultados com um scroll_idpara que seja possível buscar os próximos 10 (que ele já salvou os ids em memória e relacionou com um scroll_id).

O exemplo seguinte passa o id do scroll para buscar os próximos documents, note que não é necessário fazer a query novamente:
curl -XPOST "http://192.168.99.100:9200/example/_search/scroll" -d'
{
"scroll" : "1m",
"scroll_id" : "cXVlcnlUaGVuRmV0Y2g7NTsyNjprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzI3OmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7Mjg6a21HbHFad3hUa0tMWVlKNk5xakZSQTsyOTprbUdscVp3eFRrS0xZWUo2TnFqRlJBOzMwOmttR2xxWnd4VGtLTFlZSjZOcWpGUkE7MDs="
}'
Internamente, o elasticsearch irá buscar pelos documents relacionados ao scroll_id passados como na imagem a seguir:

Dessa maneira, os shards não precisam calcular o size novamente e nem o coordinator node precisa processar um monte de documents para depois descartá-los. Isso só será necessário na primeira vez.
Versão em vídeo:
Espero que seja útil.
Grande abraço!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?