

O Instagram conta atualmente com a maior implementação do mundo do framework web Django, que é inteiramente escrito em Python. Nós escolhemos inicialmente usar Python por causa de sua reputação de simplicidade e praticidade, que se alinha bem com a nossa filosofia de “fazer a coisa simples em primeiro lugar”. Mas a simplicidade pode vir com uma troca: a eficiência. O Instagram dobrou de tamanho nos últimos dois anos e recentemente passou a marca de 500 milhões de usuários, de modo que há uma forte necessidade de maximizar a eficiência do serviço web para que a nossa plataforma possa continuar a escalar sem problemas. No ano passado, fizemos do nosso programa de eficiência uma prioridade, e ao longo dos últimos seis meses temos sido capazes de manter o nosso crescimento de usuários sem adicionar nova capacidade em nossos níveis Django. Neste artigo, vamos compartilhar algumas das ferramentas que construímos e como podemos usá-las para otimizar nosso fluxo de implantação diária.
Por que eficiência?
Instagram, como todo software, é limitado por restrições físicas, como poder de servidores e data center. Com estss limitações em mente, existem dois objetivos principais que queremos alcançar com o nosso programa de eficiência:
- O Instagram deve ser capaz de servir o tráfego normalmente com implementações de código contínuas no caso da capacidade perdida na região de um data center, devido a desastres naturais, problemas de rede regionais etc.
- O Instagram deve ser capaz de adicionar livremente novos produtos e funcionalidades sem ser bloqueado por capacidade.
Para atender a esses objetivos, percebemos que precisávamos monitorar persistentemente o nosso sistema e batalhar contra a regressão.
Definindo eficiência
Os web services têm normalmente um gargalo no tempo de CPU disponível em cada servidor. Eficiência, nesse contexto, significa usar a mesma quantidade de recursos da CPU para fazer mais trabalho, ou seja, processar mais solicitações dos usuários por segundo (RPS). Conforme nós procuramos maneiras de otimizar, o nosso primeiro desafio é tentar quantificar a eficiência atual. Até esse ponto, fomos nos aproximando do ponto de eficiência usando o ‘Tempo médio de CPU por solicitação”, mas havia duas limitações inerentes ao uso dessa métrica:
- Diversidade de dispositivos. Usar o tempo de CPU para medir os recursos da CPU não é o ideal, porque ele é afetado por ambos os modelos de CPU e as cargas da CPU.
- Impacto dos dados solicitados. Medir os recursos da CPU por solicitação não é o ideal, porque adicionar e remover solicitações leves ou pesadas também teriam impacto na métrica da eficiência por usar a medição por solicitações.
Em comparação com o tempo de CPU, a instrução de CPU é uma métrica melhor, já que ela reporta os mesmos números, independentemente dos modelos de CPU e das cargas de CPU para o mesmo pedido. Em vez de ligar todos os nossos dados a cada solicitação do usuário, optou-se por usar a métrica de um ‘por usuário ativo’. Nós finalmente começamos a medição da eficiência pelo uso de ‘instrução de CPU por usuário ativo durante o pico do minuto’. Com a nossa nova métrica estabelecida, o nosso próximo passo foi saber mais sobre nossas regressões usando o perfil no Django.
Traçando o perfil do serviço Django
Há duas grandes questões que queremos responder fazendo o perfil do nosso serviço web Django:
- A regressão da CPU acontece?
- O que causa a regressão da CPU e como podemos corrigir isso?
Para responder à primeira pergunta, precisamos acompanhar a métrica instrução por usuário ativo na CPU (CPU-instruction-per-active-user). Se essa métrica aumenta, sabemos que uma regressão CPU ocorreu.
A ferramenta que construímos para esse fim é chamada Dynostats. Ela utiliza o middleware do Django para pegar exemplos das solicitações dos usuários em uma determinada taxa, registrando as métricas chave de eficiência e desempenho, tais como número total de instruções de CPU, latência nos pedidos de ponta a ponta, tempo gasto no acesso a serviços do memcache e banco de dados etc. Por outro lado, cada pedido tem múltiplos metadados que podemos usar para agregar, tais como o nome do endpoint, o código de retorno HTTP do pedido, o nome do servidor que serve esse pedido, e o último commit hash do pedido. Ter dois aspectos de um único registro de solicitação é especialmente poderoso, porque podemos cortar e pegar em várias dimensões o que nos ajuda a reduzir a causa de qualquer regressão de CPU. Por exemplo, podemos agregar todas as solicitações por seus nomes de endpoint, como mostrado no gráfico de séries temporais abaixo, onde é muito óbvio detectar se uma regressão acontece em um terminal específico.
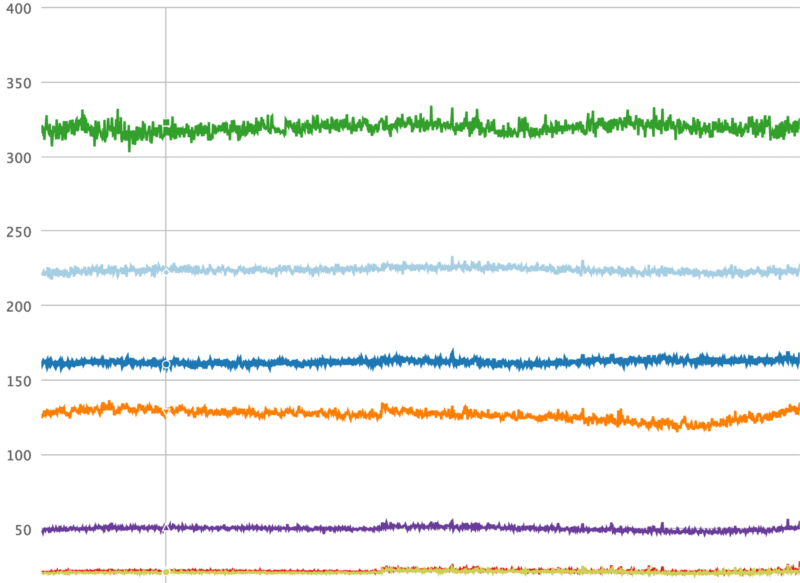
Instruções da CPU importam para medir a eficiência – e elas também são as mais difíceis de obter. Python não têm bibliotecas padrões que suportam acesso direto aos contadores de hardware da CPU (contadores de hardware CPU são os registros de CPU que podem ser programados para pegar as métricas de desempenho, tais como instruções de CPU). Linux kernel, por outro lado, fornece a chamada de sistema perf_event_open. Fazer a ponte com o ctypes do Python nos permite chamar a função syscall na biblioteca C padrão, que também fornece tipos de dados C compatíveis para programar os contadores de hardware e a leitura de dados a partir deles.
Com Dynostats, já podemos encontrar regressões CPU e cavar a causa da regressão da CPU, tais como quais endpoint são os mais afetados, quem fez o commit com as mudanças que realmente causaram a regressão da CPU etc. No entanto, quando um desenvolvedor é notificado de que suas mudanças causaram uma regressão da CPU, ele geralmente tem dificuldade de encontrar o problema. Se fosse óbvio, a regressão provavelmente não teria sido feita no commit em primeiro lugar!
É por isso que nós precisávamos de um profiler Python para que o desenvolvedor pudesse usar para encontrar a causa raiz da regressão (uma vez que Dynostats a identificasse). Em vez de começar do zero, nós decidimos fazer pequenas alterações no Cprofile, um profiler Python já disponível. O módulo cProfile normalmente fornece um conjunto de estatísticas descrevendo quanto tempo e quantas vezes as várias partes de um programa foram executadas. Em vez de medir o tempo, pegamos o cProfile e substituímos o temporizador por um contador de instruções da CPU que lê a partir dos contadores de hardware. Os dados são criados no final dos pedidos de amostras e enviados para algumas data pipelines. Também enviamos metadados semelhantes ao que temos em Dynostats, tais como nome do servidor, cluster, região, nome do endpoint etc.
No outro lado do data pipeline, criamos um tailer para consumir os dados. A principal funcionalidade do tailer é analisar os dados estatísticos do cProfile e criar entidades que representam as instruções da CPU de nível de função do Python. Ao fazer isso, podemos agregar instruções da CPU pelas funções do Python, tornando mais fácil dizer quais funções contribuem para a regressão da CPU.
Monitoramento e mecanismo de alerta
No Instagram, nós fazemos o deploy do nosso backend 30-50 vezes por dia. Qualquer um desses deploys pode conter regressões de CPU problemáticas. Uma vez que cada rollout geralmente inclui pelo menos um diff, é fácil identificar a causa de qualquer regressão. Nosso mecanismo de monitoramento de eficiência inclui a varredura da instrução da CPU em Dynostats antes e depois de cada deploy, e o envio de alertas quando a mudança excede um determinado limite. Para as regressões de CPU que acontecem durante longos períodos de tempo, temos também um detector que faz a varredura das mudanças diárias e semanais para os pontos mais carregados dos endpoints.
O deploy de novas alterações não é a única coisa que pode desencadear uma regressão da CPU. Em muitos casos, as novas funcionalidades ou novos caminhos do código são controlados por variáveis de ambiente globais (GEV). Existem práticas muito comuns para implementação de novas funcionalidades para um subconjunto de usuários com um cronograma planejado. Nós adicionamos essa informação como campos de metadados adicionais para cada pedido de dados estatísticos em Dynostats e cProfile. O agrupamento de pedidos por esses campos revelam possíveis regressões da CPU causadas ao ativar os GEVs. Isso nos permite pegar regressões da CPU antes que possam afetar o desempenho.
Qual é o próximo passo?
Dynostats e nossa cProfile personalizada, juntamente com o mecanismo de monitoramento e alerta que construímos para apoiá-los, podem efetivamente identificar o culpado pela maioria das regressões da CPU. Esses desenvolvimentos têm nos ajudado a recuperar mais de 50% das regressões de CPU desnecessárias, que de outra forma teriam passado despercebidas.
Há ainda áreas em que podemos melhorar e tornar mais fácil de incorporar no fluxo de deploy diário do Instagram:
- A métrica de instruções da CPU é esperada para ser mais estável do que outras métricas, como o tempo de CPU, mas nós ainda observamos variações que tornam o nosso alerta muito barulhento. Manter a taxa de signal:noise razoavelmente baixa é importante para que os desenvolvedores possam se concentrar nas regressões reais. Isso pode ser melhorado através da introdução do conceito de intervalos de confiança e emitir o alarme único quando estive alto. Para diferentes endpoints, o limite da variação também pode ser definido de maneira diferente.
- Uma limitação para detectar regressões de CPU pela mudança GEV é que nós temos que habilitar manualmente o registro dessas comparações no Dynostats. Com o número de GEVs aumentando e mais recursos sendo desenvolvidos, isso não é bem dimensionado. Em vez disso, poderíamos aproveitar um framework automático que agenda o registro dessas comparações e percorre todas as GEVs e envia alertas quando regressões são detectadas.
- cProfile precisa de algum reforço para lidar com funções de wrapper e suas funções filhas de uma forma melhor.
Com esse trabalho que temos colocado para construir o framework de eficiência para o web service do Instagram, estamos confiantes de que vamos continuar escalando nossa infraestrutura de serviços utilizando Python. Nós também começamos a investir mais na própria linguagem Python, e estamos começando a explorar como mover o nosso Python da versão 2 para a 3. Vamos continuar a explorar isso e mais experimentos para continuar a melhorar a infraestrutura e a eficiência do desenvolvedor, e estamos ansiosos para compartilhar mais em breve.
***
Instagram Engineering é a equipe responsável pela engenharia de software do Instagram. Este artigo é de Min Ni, engenheiro de software no Instagram. Confira o original em https://engineering.instagram.com/web-service-efficiency-at-instagram-with-python-4976d078e366#.j3hj3bkb5

De 0 a 10, o quanto você recomendaria este artigo para um amigo?