

A visualização de texto é uma maneira eficiente e às vezes reveladora de verificar rapidamente o que um texto específico está dizendo. Como um subproduto, a visualização também fornece um meio para as análises ad hoc de um texto. O artigo mostra como desenvolver um software de análise e visualização de texto com bibliotecas e ferramentas de software livre. O aplicativo compara e analisa dois textos com um contexto igual ou semelhante, permitindo que os usuários obtenham um novo insight sobre esses textos ou seu contexto.
O aplicativo desenvolvido é baseado na visualização de nuvem de palavras. Uma visualização de nuvem de palavras analisa um texto específico e classifica suas palavras na proporção em com qual frequência elas ocorrem. As palavras classificadas são, então, baseadas no tamanho em suas classificações. A palavra com a classificação mais alta é exibida com a maior fonte na visualização. A posição das palavras na visualização pode avariar, mas normalmente elas lembram uma nuvem, como na Figura 1:

Para gerar a nuvem de palavras na Figura 1, usei o IBM Many Eyes para analisar a carta do President e CEO no Relatório Anual da IBM de 2011.
O aplicativo nesse artigo gera uma onda de palavras — uma visualização de texto que tem o formato semelhante ao de uma nuvem. Essa onda de palavras coloca as palavras com maior classificação no canto superior esquerdo. Figura 2 mostra um exemplo que usa o mesmo texto que é visualizado na Figura 1:

A visualização de um texto revela as palavras de classificação alta. A análise do texto, que é baseada na visualização, assume que as palavras de classificação alta têm uma hierarquia de importância. A comparação acontece quando duas visualizações de texto são exibidas juntas. Se os contextos de ambos os textos forem iguais ou semelhantes, a comparação é especialmente significativa. Por exemplo, uma comparação de textos que descrevem as estratégias de duas empresas no mesmo segmento de mercado deve revelar semelhanças e diferenças entre as prioridades dessas duas empresas.
A Figura 3 é um rascunho grosseiro de uma comparação final de dois textos. A visualização do primeiro texto está na parte superior e a visualização do segundo está na parte inferior. As palavras de classificação alta em ambas estão no lado esquerdo.

Os objetivos do artigo e seu código são mostrar como:
- Desenvolver um aplicativo de linha de comando para visualizar e comparar textos com bibliotecas e ferramentas de software livre;
- Criar uma visualização (semelhante a Figura 2) de um texto especificado com uma visualização de onda de palavras;
- Combinar duas visualizações na mesma imagem para comparação e análise;
- Criar um vídeo visualmente atraente a partir da visualização.
O artigo não se aprofunda nos detalhes de desenvolvimento, então a experiência com o desenvolvimento em Java™ e com o modelo de programação do Eclipse é útil para os leitores. Todo o código-fonte do aplicativo — os projetos do Eclipse para o aplicativo e um site de atualização pronto para implementação — estão disponíveis para download.
Iniciarei com uma visão geral dos componentes do ambiente de desenvolvimento.
Ambiente de desenvolvimento
O ambiente de desenvolvimento consiste em várias bibliotecas e ferramentas de software livre que, combinadas, fazem com que seja fácil de criar vídeos e ondas de palavras. O aplicativo em si é relativamente curto. As bibliotecas e ferramentas cuidam do processamento pesado de imagens, vídeos e da interface da linha de comandos.
Eclipse
Quando o Eclipse é usado como um IDE, é possível aproveitar o Command Line Program.
Command Line Program
O Command Line Program é um aplicativo Rich Client Platform (RCP) Eclipse de terceiros para a criação de aplicativos de linha de comando. Ele usa o modelo de programação de plug-in do Eclipse, incluindo features e sites de atualização (consulte ‘Recursos’ para encontrar um link para os conceitos do Eclipse). O Command Line Program fornece a infraestrutura para os aplicativos de linha de comando, como análise de linha de comando, um comando de ajuda, criação de log e outras funções básicas. A ideia é desenvolver um software de análise e visualização como um comando de extensão para o Command Line Program.
Processing e WordCram
O Processing é uma linguagem e um ambiente de desenvolvimento para a criação de animações e imagens. Para uma introdução ao Processing, consulte “Visualização de dados com Processing – Parte 1“. O Processing é fácil de aprender e usar, embora seja possível realizar grandes feitos com ele (consulte ‘Recursos’ para encontrar um link para exemplos no OpenProcessing.org). O WordCram é uma biblioteca customizável para a criação de nuvens de palavras no Processing.
Monte Media Library
A Monte Media Library é uma biblioteca de software livre simples e excelente para escrever, ler e manipular vídeos e imagens. O autor, Werner Randelshofer, diz em seu website que a Monte Media Library é experimental para seus estudos pessoais. Apesar disso, felizmente ele decidiu publicá-la para que outras pessoas também possam usá-la. Diferente de outras bibliotecas disponíveis que parecem complicadas e requerem um código nativo, a Monte Media Library é fácil de usar e é puramente em código Java.
Desenvolvendo o aplicativo
Agora que está familiarizado com as ferramentas, é possível começar a desenvolver um aplicativo chamadoTextVisualizationAndAnalysis e um comando de extensão chamado Compare — para o Command Line Program.
O projeto do Command Line Program é necessário para que seja possível desenvolver a extensão para ele. Faça o download do código fonte do módulo CLP_Plugin_Main project e importe na área de trabalho do Eclipse. O projeto inclui o código fonte para o Command Line Program e fornece pontos de extensão para desenvolver extensões em seus próprios projetos.
Crie um projeto de plug-in
Para desenvolver um comando de extensão pra o Command Line Program, primeiro crie um projeto de plug-in, como seria necessário com qualquer outro projeto de extensão do Eclipse:
- Crie um novo projeto de plug-in e insira
TextVisualizationAndAnalysiscomo o nome do projeto; - Selecione 3.5 or greater como a versão do Eclipse e clique em Próximo;
- Insira
0.0.1como o número da versão, desmarque (se estiver selecionada) a opção This plug-in will make contributions to the UI e aceite os padrões nos outros campos. Clique em Próximo para chegar à tela final; - Desmarque (se estiver selecionada) a opção Create a plug-in using one of the templatese clique em Concluir para criar o projeto;
- O novo projeto agora está na área de trabalho do Eclipse e o arquivo plugin.xml está aberto na tela. (Se não estiver e se o plugin.xml não existir no diretório do projeto, abra o arquivo META-INF/MANIFEST.MF no lugar dele);
- Abra a guia Dependencies e na seção Required Plug-ins adicione
com.softabar.clpp.applicationao projeto. Esse plug-in é fornecido com o projeto Command Line Program Eclipse que foi importado na área de trabalho do Eclipse; - Acesse a guia Extensions e adicione uma extensão que amplia o ponto de extensão
com.softabar.clpp.application.command, que é fornecido com o Command Line Program; - Insira os detalhes da extensão. Insira
comparena seção nome . InsiraVisualize and compare two text filesna seção help. Insiratextvisualizationandanalysis.Compare Commandna seção. Consulte Figura 4:
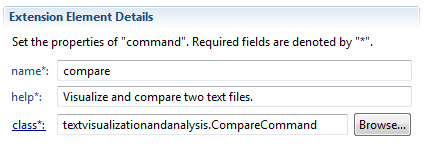
Crie a classe posteriormente. Além disso, adicione novas informações ao plug-in posteriormente, conforme o necessário.
Adicione as bibliotecas necessárias
Para criar o procedimento Compare, adicione essas bibliotecas ao plug-in:
- core.jar, do Processing;
- WordCram.jar, jsoup-1.3.3.jar, e (opcionalmente) cue.language.jar do WordCram;
- monte-cc.jar, da Monte Media Library.
Para adicioná-las:
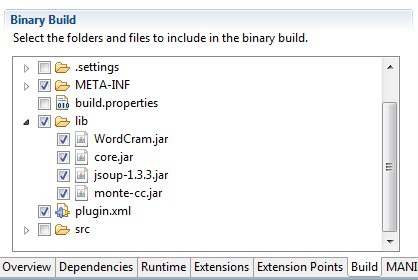
- Crie um diretório lib no projeto de plug-in e adicione os arquivos JAR a esse diretório;
- Para incluir o diretório lib no desenvolvimento do plug-in, abra o plugin.xml e selecione a guia Compilação. Para selecionar o diretório lib no diálogo Binary Build, clique em sua caixa de seleção, como naFigura 5:
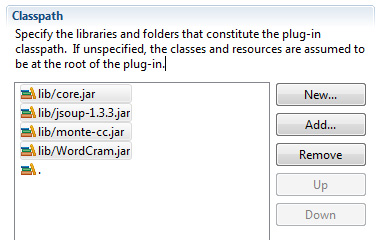
- Abra a guia Runtime no diálogo Classpath, selecione Incluir para adicionar as bibliotecas ao caminho de classe do plug-in. Figura 6 mostra o diálogo Classpath com todas as bibliotecas (não incluindo a cue.language.jar) incluídas:
- Salve o arquivo plugin.xml.
Escreva o código
Agora é possível escrever o código real para o comando. O código-fonte para o comando está nas listagens a seguir (com as instruções de importação e pacote intencionalmente omitidas). Também é necessário incluir algumas informações no arquivo plugin.xml file, que mostrarei após passarmos pelas listagens de código.
Lista 1 contém as variáveis e a declaração de classe:
[xml]</p>
<p>public class CompareCommand extends PApplet implements ICommand, WordColorer {<br />
private static final long serialVersionUID = -188003470351748783L;<br />
private static CLPPLogger logger = CLPPLogger.getLogger(CompareCommand.class);<br />
private static boolean testing = true;<br />
private static boolean processingDone = false;<br />
private static String fileName;<br />
private static String outputDir;<br />
private static File inputTextFile1;<br />
private static File inputTextFile2;<br />
private static boolean drawTitle;<br />
private static String title1;<br />
private static String title2;<br />
private static boolean createVideo = false;<br />
private static int frameRate;<br />
private int frameWidth = 1280;<br />
private int frameHeight = 720;<br />
private int maxWords = 50;<br />
// font to be used<br />
private String font = "c:/windows/fonts/georgiab.ttf";<br />
private WordCram wordCram1;<br />
private PGraphics buffer1;<br />
private WordCram wordCram2;<br />
private PGraphics buffer2;<br />
// colors used in word waves</p>
<p>private int[] colors = { 0x22992A, 0x9C3434, 0x257CCD, 0x950C9E } [xml]</p>
<p>Em Lista 1, a classe processing.core.PApplet é estendida para aproveitar os métodos do Processing. Em seguida, são implementadas duas interfaces: com.softabar.clpp.program.ICommand e wordcram.WordColorer. A opçãocom.softabar.clpp.program.ICommand de interface é para o Command Line Program. Ela é chamada pelo Command Line Program quando o comando é executado. A opção wordcram.WordColorer de interface manipula as cores das nuvens (ou ondas) de palavras. Algumas das variáveis são declaradas <code>estático</code> , pois precisam estar visíveis no código de Processing durante a execução.</p>
<p>Lista 2 mostra a classe execute() da função ICommand:</p>
<p>[xml]</p>
<p>public void execute(CommandLine commandLine, IProgramContext programContext) {<br />
testing = false;<br />
String inputFileStr = commandLine.getOptionValue("input1");<br />
inputTextFile1 = new File(inputFileStr);<br />
if (!inputTextFile1.exists()) {<br />
Output.error(inputFileStr + " does not exist.");<br />
return;<br />
}<br />
inputFileStr = commandLine.getOptionValue("input2");<br />
inputTextFile2 = new File(inputFileStr);<br />
if (!inputTextFile2.exists()) {<br />
Output.error(inputFileStr + " does not exist.");<br />
return;<br />
}<br />
drawTitle = commandLine.hasOption("title");<br />
fileName = commandLine.getOptionValue("filename", "results");<br />
outputDir = commandLine.getOptionValue("outputdir", ".");<br />
if (!outputDir.endsWith("/")) {<br />
outputDir = outputDir + "/";<br />
}<br />
title1 = commandLine.getOptionValue("title1", inputTextFile1.getName());<br />
title2 = commandLine.getOptionValue("title2", inputTextFile2.getName());<br />
String frate = commandLine.getOptionValue("framerate", "5");<br />
frameRate = Integer.parseInt(frate);<br />
createVideo = commandLine.hasOption("video");<br />
Output.println("Generating comparison word waves…");<br />
generateWordCloud();<br />
createVideo();<br />
}[/xml]
In Lista 2, o método execute() recebe uma instância org.apache.commons.cli.CommandLine como um parâmetro. O parâmetro obtém as opções para o comando. Adicione as opções suportadas ao plugin.xml posteriormente. Após obter e configurar as opções, crie a nuvem de palavras ao chamar o método generateWordCloud() usual. Em seguida, crie o vídeo ao chamar o método createVideo().
Lista 3 mostra a classe generateWordCloud() (método) que chama o método main na classe processing.PApplet e então espera até que o Processing/WordCram conclua a renderização da nuvem de palavras:
[xml]</p>
<p>private void generateWordCloud() {<br />
try {<br />
main(new String[] { "–present", getClass().getName() });<br />
// wait until word wave is finished<br />
while (!processingDone) {<br />
try {<br />
Thread.sleep(0, 1);<br />
} catch (InterruptedException e) {<br />
}<br />
}<br />
} catch (Exception e) {<br />
logger.error(e.toString(), e);<br />
Output.error(e.toString());<br />
}<br />
}[/xml]
Lista 4 mostra a configuração para a geração de nuvens de palavras:
[xml]</p>
<p>public void setup() {<br />
if (testing) {<br />
logger.debug("testing");<br />
inputTextFile1 = new File("c:/CocaCola_MissionVisionValues.txt");<br />
inputTextFile2 = new File("c:/PepsiCo_MissionVisionValues.txt");<br />
outputDir = "c:/output/";<br />
fileName = "results";<br />
drawTitle = true;<br />
createVideo = false;<br />
title1 = "Coke";// inputTextFile1.getName();<br />
title2 = "Pepsi";// inputTextFile2.getName();<br />
}<br />
logger.debug("frameWidth: {}, frameHeight: {}", frameWidth, frameHeight);<br />
size(frameWidth, frameHeight);<br />
background(255);<br />
logger.debug("setup");<br />
// create buffer to draw the upper word wave<br />
buffer1 = createGraphics(frameWidth, frameHeight / 2, JAVA2D);<br />
buffer1.beginDraw();<br />
buffer1.background(255);<br />
wordCram1 = initWordCram(inputTextFile1, buffer1);<br />
// create buffer to draw the lower word wave<br />
buffer2 = createGraphics(frameWidth, frameHeight / 2, JAVA2D);<br />
buffer2.beginDraw();<br />
buffer2.background(255);<br />
wordCram2 = initWordCram(inputTextFile2, buffer2);<br />
// set up font for titles<br />
fill(0);<br />
textFont(createFont(font, 40));<br />
textAlign(CENTER);<br />
}[/xml]
In Lista 4, o método setup() é chamado pelo Processing antes de ele iniciar o desenho. Aqui são inicializados o tamanho da tela e a cor do plano de fundo e são criados os buffers de gráfico em que a nuvem de palavras gerada pelo WordCram é desenhada . Esse código também especifica as variáveis para teste a partir do Eclipse.
WordCram, a biblioteca responsável por gerar as nuvens de palavras é inicializada na Lista 5. É possível especificar os aspectos da nuvem de palavras como as cores e a localização. A WordCram fornece alguns posicionadores, como a nuvem usada aqui, além de algumas colorações para as palavras. Aqui, use sua própria coloração.
[xml]</p>
<p>private WordCram initWordCram(File inputFile, PGraphics buffer) {<br />
WordCram wordCram = new WordCram(this);<br />
if (buffer != null) {<br />
wordCram = wordCram.withCustomCanvas(buffer);<br />
}<br />
// initialize WordCram with specified placer, text file,<br />
// colorer, and other details<br />
wordCram = wordCram.fromTextFile(inputFile.getPath());<br />
wordCram = wordCram.withColorer(this);<br />
wordCram = wordCram.withWordPadding(2);<br />
wordCram = wordCram.withPlacer(Placers.wave());<br />
wordCram = wordCram.withAngler(Anglers.randomBetween(-0.15f, 0.15f));<br />
wordCram = wordCram.withFont(createFont(font, 40));<br />
wordCram = wordCram.sizedByWeight(7, 52);<br />
wordCram = wordCram.maxNumberOfWordsToDraw(maxWords);<br />
return wordCram;<br />
}[/xml]
Lista 6 mostra a nuvem de palavras que é gerada pelo método draw() do operador:
[xml]</p>
<p>public void draw() {<br />
logger.debug("Draw..");<br />
// draw one word at a time<br />
if (wordCram1.hasMore()) {<br />
// draw next word in upper word wave<br />
wordCram1.drawNext();<br />
buffer1.endDraw();<br />
image(buffer1, 0, 0);</p>
<p>buffer1.beginDraw();<br />
// draw next word in lower word wave<br />
wordCram2.drawNext();<br />
buffer2.endDraw();<br />
image(buffer2, 0, frameHeight / 2);<br />
buffer2.beginDraw();<br />
} else {<br />
buffer1.endDraw();<br />
buffer2.endDraw();<br />
image(buffer1, 0, 0);<br />
image(buffer2, 0, frameHeight / 2);<br />
listSkippedWords(inputTextFile1.getName(), wordCram1);<br />
listSkippedWords(inputTextFile2.getName(), wordCram2);<br />
noLoop();<br />
// if no video then<br />
// save only last frame result<br />
if (!createVideo) {<br />
saveFrame(outputDir + fileName + ".png");<br />
}<br />
// for testing purposes within Eclipse<br />
if (testing) {<br />
createVideo();<br />
}<br />
processingDone = true;<br />
}<br />
if (drawTitle) {<br />
color(0);<br />
textSize(20);<br />
text(title1, 0, 0, frameWidth, 50);<br />
text(title2, 0, frameHeight / 2, frameWidth, 50);<br />
}<br />
if (createVideo) {<br />
saveFrame(outputDir + fileName + "-####.png");<br />
}<br />
}[/xml]
A geração da nuvem de palavras acontece com uma palavra de cada vez. A Lista 6 usa dois buffers diferentes para duas nuvens de palavras e, então, ambos os buffers são desenhados na tela. Após a nuvem de palavras ser concluída, termine o desenho e liste todas as palavras ignoradas. Caso crie um vídeo, salve cada frame como uma imagem. Essas imagens são usadas para gerar o vídeo.
O propósito do método listSkippedWords() na Lista 7, é imprimir uma lista de palavras que não podem ser colocadas na visualização:
[xml]</p>
<p>private void listSkippedWords(String desc, WordCram wordcram) {<br />
Word[] words = wordcram.getWords();<br />
int skipped = 0;<br />
// for each word check whether it was skipped<br />
List<String> skippedWords = new Vector<String>();<br />
for (Word word : words) {<br />
if (word.wasSkipped()) {<br />
int skippedBecause = word.wasSkippedBecause();<br />
if (skippedBecause == WordCram.NO_SPACE) {<br />
// increase number of skipped words<br />
// only if no space for word<br />
skippedWords.add(word.word);<br />
skipped++;<br />
}<br />
}<br />
}<br />
// print number of skipped words<br />
if (skipped > 0) {<br />
logger.debug("skippedWords: {}, {}", desc, skippedWords);<br />
Output.println(desc + ": no space for " + skipped + " words: "<br />
+ skippedWords);<br />
}<br />
}[/xml]
Se qualquer palavra ignorada for retornada, isso potencialmente significa que a visualização tem palavras importantes ausentes. Análises posteriores que são baseadas na visualização podem ser enganosas ou até mesmo falsas. Se qualquer palavra ignorada for retornada, é possível executar o programa novamente para que ele possa tentar posicionar todas as palavras na nuvem de palavras.
A opção colorFor() da Lista 8 implementa o método WordColorer da interface do WordCram. O método retorna cores escolhidas aleatoriamente a partir de uma lista predefinida.
[xml]</p>
<p>public int colorFor(Word w) {<br />
int index = (int) random(colors.length);<br />
int colorHex = colors[index];<br />
int r = colorHex >> 16;<br />
int g = (colorHex >> 8) & 0x0000ff;<br />
int b = colorHex & 0x0000ff;<br />
logger.debug("R: {}, G: {}, B: {}", new Integer[] { r, g, b });<br />
return color(r, g, b);<br />
}[/xml]
Lista 9 mostra createVideo(), o método final que é chamado na Lista 6:
[xml]</p>
<p>private void createVideo() {<br />
if (createVideo) {<br />
Output.println("Generating video…");<br />
try {<br />
File aviFile = new File(outputDir, fileName + ".avi");<br />
// format specifies the type of video we are creating<br />
// video encoding, frame rate, and size is specified here<br />
Format format = new Format(org.monte.media.FormatKeys.EncodingKey,<br />
org.monte.media.VideoFormatKeys.ENCODING_AVI_PNG,<br />
org.monte.media.VideoFormatKeys.DepthKey, 24,<br />
org.monte.media.FormatKeys.MediaTypeKey, MediaType.VIDEO,<br />
org.monte.media.FormatKeys.FrameRateKey,<br />
new Rational(frameRate, 1),<br />
org.monte.media.VideoFormatKeys.WidthKey, width,<br />
org.monte.media.VideoFormatKeys.HeightKey, height);<br />
logger.debug("Framerate: {}", frameRate);<br />
AVIWriter out = null;<br />
try {<br />
// create new AVI writer with previously specified format<br />
out = new AVIWriter(aviFile);<br />
out.addTrack(format);<br />
int i = 1;<br />
// read the first image file<br />
String frameFileName = String.format(fileName + "-%04d.png", i);<br />
File frameFile = new File(outputDir, frameFileName);<br />
while (frameFile.exists()) {<br />
logger.debug("Frame filename: {}", frameFileName);<br />
// while frame images exist<br />
// create a Buffer and write it to AVI writer<br />
Buffer buf = new Buffer();<br />
buf.format = new Format(org.monte.media.FormatKeys.EncodingKey,<br />
org.monte.media.VideoFormatKeys.ENCODING_BUFFERED_IMAGE,<br />
org.monte.media.VideoFormatKeys.DataClassKey,<br />
BufferedImage.class).append(format);<br />
buf.sampleDuration = format.get(<br />
org.monte.media.FormatKeys.FrameRateKey).inverse();<br />
buf.data = ImageIO.read(frameFile);<br />
out.write(0, buf);<br />
// read next frame image<br />
i++;<br />
frameFileName = String.format(fileName + "-%04d.png", i);<br />
frameFile = new File(outputDir, frameFileName);<br />
}<br />
} finally {<br />
if (out != null) {<br />
out.close();<br />
}<br />
Output.println("Done.");<br />
}<br />
} catch (IOException e) {<br />
logger.error(e.toString(), e);<br />
Output.error(e.toString());<br />
}<br />
}<br />
}[/xml]
A Lista 9 demonstra a simplicidade de criar um vídeo a partir de imagens. É necessário apenas especificar um formato de vídeo e, em seguida, criar o vídeo com uma imagem de cada vez.
Adicione opções de linha de comando ao plugin.xml
Agora, o código está pronto. Antes de implementá-lo, adicione as opções de linha de comando ao arquivo plugin.xml para que o Command Line Program possa analisá-las:
- Abra o plugin.xml e abra a guia Extensions;
- Selecione
compare-command, clique com o botão direito do mouse e selecione New > option; - A opção
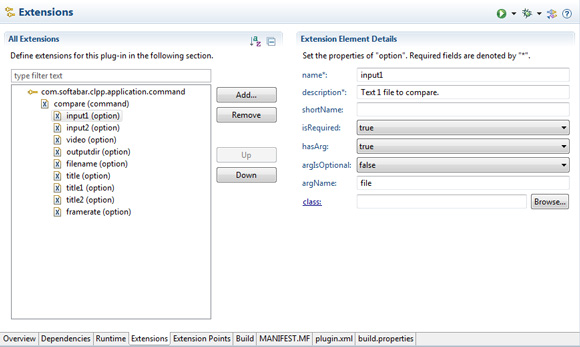
input1,input2evideosão necessárias para o aplicativo.input1einput2especificam os nomes de arquivo dos dois arquivos de texto que se deseja comparar.videogera o vídeo (ou, caso seja omitido, não gera o vídeo). Figura 7 mostra a classeinput1de definição de opção (Text 1 file to compare) e outras opções que podem ser adicionadas caso desejado:
A opção Compare para o Command Line Program agora está concluída e é possível implementá-la.
Instalando o aplicativo
Para usar a classe TextVisualizationAndAnalysis (aplicativo), é necessário implementá-la no Command Line Program. Crie um recurso e um site de atualização para o plug-in TextVisualizationAndAnalysis e instale-o no Command Line Program.
Crie um recurso
Os recursos no Eclipse são coleções de plug-ins que podem ser instaladas e atualizadas. O Command Line Program usa a funcionalidade de recurso padrão do Eclipse para permitir a instalação e a atualização de novos comandos de extensão. As etapas rápidas para criar um recurso para o comando Compare são:
- Crie um projeto de recurso e atribua o nome de
TextVisualizationAndAnalysisFeature; - Defina o número da versão para 0.0.1 e clique em Próximo;
- Selecionar o ponto de rastreamento
TextVisualizationAndAnalysis(plug-in) e clique em Concluir;
Gere um site de atualização
Os sites de atualização incluem recursos que podem ser instalados nos aplicativos. O site de atualização pode ser um diretório local ou um servidor da web remoto. Para gerar um site de atualização para o programa TextVisualizationAndAnalysis:
- Crie um projeto de site de atualização e atribua o nome de
TextVisualizationAndAnalysisUpdateSite; - Na página Update Site Map, em Managing the Site, selecione Add Feature para adicionar
TextVisualizationAndAnalysisFeature, como mostra a Figura 8:
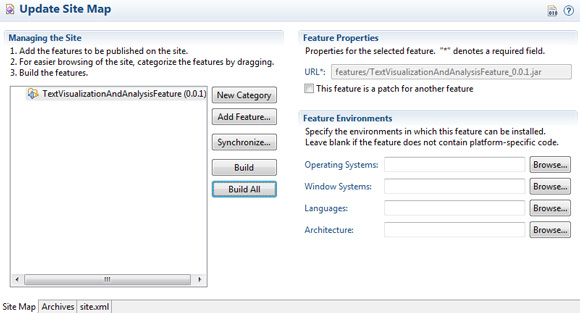
- Clique em Build All.
Instale o comando
Não é possível executar o comando independentemente porque é necessário instalá-lo no Command Line Program. A instalação é feita com o Command Line Program em si. Insira o admin, (comando) (que aqui assume que o site de atualização criado está no diretório c:/workspace/):
[xml]clp.cmd admin –install –dir=’c:\workspace\TextVisualizationAndAnalysisUpdateSite'[/xml]
Executar o aplicativo
Aqui estão alguns comandos de amostra que mostram como executar o aplicativo.
Gerar e mostrar uma imagem de comparação de texto:
[xml]clp.cmd compare –input1=’c:/path/file1.txt’ –input2=’c:/path/file2.txt'[/xml]
Usar os nomes de arquivos como um título para a visualização:
[xml]clp.cmd compare –input1=’c:/path/file1.txt’ –input2=’c:/path/file2.txt’ –title[/xml]
Usar títulos customizados:
[xml]</p>
<p>clp.cmd compare –input1=’c:/path/file1.txt’ –input2=’c:/path/file2.txt'<br />
–title –title1=’Text1′ –title2=’Text2′ [/xml]
Gerar uma imagem e um vídeo:
[xml] clp.cmd compare –input1=’c:/path/file1.txt’ -–input2=’c:/path/file2.txt’ -title –video [/xml]
Resultados e análises
Agora é possível colocar o aplicativoTextVisualizationAndAnalysis em funcionamento. Eu o utilizei para visualizar dois textos semelhantes: as declarações de missão publicamente disponíveis de duas corporações no mesmo segmento de mercado, a — Coca Cola Company e a o PepsiCo (consulte Recursos). Em seguida, usei a visualização para fazer uma análise. A suposição é de que as ondas de palavras irão visualizar o que essas corporações acreditam que seja mais importante para elas, agora e no futuro. (Para obter os textos de origem e o código de aplicativo completo no projeto de plug-in consulte Downloads).
Visualização
Usei o último comando na seção anterior, Executar o aplicativo, para gerar a imagem e o vídeo. A Figura 9 é uma comparação de visualização dos dois textos:
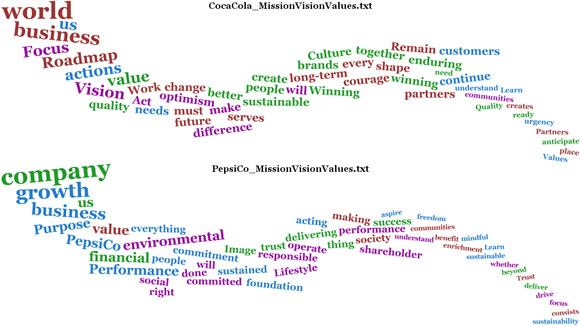
A onda de palavras superior na Figura 9 visualiza a declaração Mission, Vision & Values da Coca-Cola, que aponta sua missão, visão e valores. A da parte inferior visualiza a declaração Value & Philosophy da PepsiCo, que aponta seus valores e filosofia. As ondas de palavras mostram as 50 palavras mais usadas nos textos, com as palavras mencionadas com maior frequência no canto superior esquerdo. O tamanho da fonte diminui para a direita, indicando que as palavras no canto inferior direito são mencionadas com menor frequência do que as palavras na parte superior esquerda.
Na barra lateral, veja um vídeo de dez segundos da geração palavra a palavra da visualização
Análise
Para analisar a comparação da visualização na Figura 9, atribua a maior importância às palavras no quarto mais a esquerda. Primeiro desenhei uma linha vertical na visualização aproximadamente em um quarto a partir da esquerda de cada onda de palavras, como na Figura 10:
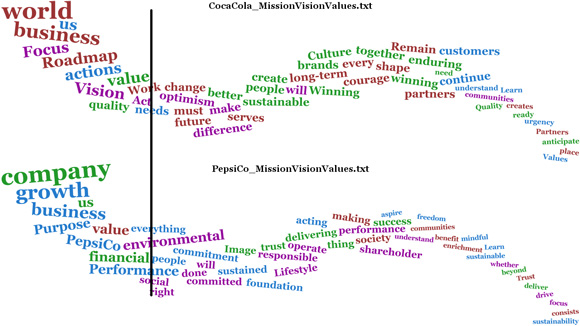
Presumo que as palavras à esquerda da linha são o que ambas as corporações consideram o mais importante.
A Coca-Cola parece ter o foco em sua visão e ter um roteiro para conquistar essa visão. Ela também parece ver o mundo como seus negócios e valoriza ações e a qualidade de seu trabalho para conquistar sua visão.
A PepsiCo parece dizer que seu propósito comercial é o crescimento da empresa, incluindo o desempenho financeiro. Ela também parece valorizar os aspectos ambientais e sociais.
Essa rápida comparação das visualizações nos mostra, então, como duas corporações no mesmo segmento de mercado podem ser diferentes em seu pensamento. Uma conclusão razoável da análise é a de que a Coca-Cola Company está mais preocupada com seu lugar no mundo futuro e que a PepsiCo está mais preocupada com os negócios e seu crescimento.
Atualizando o aplicativo
Em algum momento pode-se desejar atualizar o aplicativo TextVisualizationAndAnalysis . A atualização usa o mesmo mecanismo que a instalação. Siga essas etapas para atualizar o aplicativo:
- Faça as alterações necessárias no código ou em outros arquivos.
- Aumente a versão do plug-in e do recurso.
- Importante: Tanto o plug-in como o recurso precisam de uma alteração de versão. Caso contrário, o mecanismo de atualização falha em detectar que foram realizadas alterações.
- O número da versão deve ser aumentado pelo menos no segmento do serviço. Por exemplo, a versão antiga é 0.0.1 e a nova versão é 0.0.2.
- Adicione a nova versão ao site de atualização e ao site de atualização de desenvolvimento.
- Execute esse comando:
clp.cmd admin --update --dir='c:\workspace\TextVisualizationAndAnalysisUpdateSite'
- Execute o aplicativo normalmente
Conclusão
A visualização é uma ferramenta eficiente para colher novos insights de textos. Foram usadas ferramentas de software livre para desenvolver um aplicativo de visualização que compara e analisa quaisquer dois textos. O aplicativo TextVisualizationAndAnalysis está pronto para comparar quaisquer outros tipos de texto — por exemplo, estratégias corporativas, biografias de celebridades ou obras de ficção. Melhor ainda, é possível usar as técnicas e ferramentas sobre as quais aprendeu aqui para criar seus próprios aplicativos de visualização.
Downloads
| Descrição | Nome | Tamanho | Método de download |
|---|---|---|---|
| Plug-in projects, ready to import into Eclipse | TextVisualizationAndAnalysis_projects.zip | 1.3MB | HTTP |
| Update site for deploying to Command Line Program | TextVisualizationAndAnalysisUpdateSite.zip | 1.3MB | HTTP |
Informações sobre métodos de download
Recursos
Aprender
- Eclipse plug-in concepts: Leia sobre os recursos, sites de atualização e outros conceitos do plug-in do Eclipse no Plug-in Development Environment Guide.
- “Data visualization with Processing, Part 1: An introduction to the language and environment” (M. Tim Jones, developerWorks, novembro de 2010): Apresentação ao ambiente e à linguagem do Processing na primeira parte de uma série de três artigos.
- OpenProcessing: Visite esse site para visualizar uma extensa galeria de rascunhos que foram criados como Processing.
- Mission, Vision & Values: O texto da Coca-Cola Company que é usado no exemplo no artigo é do segundo trimestre de 2012.
- PepsiCo Values & Philosophy O texto da PepsiCo que é usado no exemplo no artigo (sem incluir sua seção Guiding Principles) é do segundo trimestre de 2012.
- IBM Many Eyes visualizations: Essas visualizações, geradas com o IBM Many Eyes, incluem a nuvem de palavras em a Figura 1.
- Blog do Sami Salkosuo: O blog do Sami inclui muitas visualizações de nuvem de palavras que foram geradas com as ferramentas nesse artigo.
- IBM InfoSphere Streams: Obtenha uma plataforma de analítica escalável eficiente que pode manipular taxas de rendimento de dados inacreditavelmente altas que podem variar de milhões de eventos ou mensagens por segundo.
- IBM InfoSphere BigInsights: Gerencie e analise grandes volumes de dados estruturados e não estruturados em repouso com o InfoSphere BigInsights, a distribuição desenvolvida do Hadoop para a analítica de Big Data da IBM. Ele amplia o Hadoop com recursos corporativos, incluindo analítica avançada, aceleradores de aplicativo, suporte a diversas distribuições, otimização de desempenho, integração corporativa entre outros.
- Tópico técnico do Open source no developerWorks: encontre informações práticas, ferramentas e atualizações de projeto amplas para ajudá-lo a desenvolver com tecnologias de software livre e utilizá-las com produtos IBM.
{kind=link}
Obter produtos e tecnologias
- Eclipse: Faça o download do Eclipse para sua plataforma.
- Command Line Program: O Command Line Program da Softbar é uma plataforma de software livre para o desenvolvimento de aplicativos de linha de comando.
- Monte Media Library: A Monte Media Library é a biblioteca Java para o processamento de dados de mídia.
- O processamento de : Processing é um ambiente e uma linguagem de programação de software livre para criar imagens, animações e interações.
- WordCram: WordCram é uma biblioteca do Processing para a geração de nuvens de palavras.
- VLC: VLC é um reprodutor multimídia de software livre grátis.
- IBM InfoSphere Streams: Faça download do InfoSphere Streams e desenvolva aplicativos que rapidamente alimentam, analisam e correlacionam as informações conforme elas chegam de milhares de fontes em tempo real.
- IBM InfoSphere BigInsights: Faça download do InfoSphere BigInsights e gerencie e analise grandes volumes de dados estruturados e não estruturados em repouso.
Discutir
- Participe da comunidade do developerWorks. Conecte-se com outros usuários do developerWorks enquanto explora as wikis, os grupos, os fóruns e blogs voltados aos desenvolvedores.
***
Sobre o autor: Sami Salkosuo é Software Client Architect (também conhecido como Software IT Architect) do IBM Software Group na Finlândia, e trabalhou na IBM por aproximadamente 15 anos atualmente trabalha com os clientes no setor de manufatura. Ele também é autor do Command Line Email Client for Lotus Notes, um projeto de software livre disponível em OpenNTF.org. Em seu tempo livre, ele gosta de escrever ficção científica como autor independente. É possível visitar o blog de Sami ou segui-lo no Twitter.
***
Artigo original disponível em: http://www.ibm.com/developerworks/br/library/os-txtviz/index.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?