

Errar é humano. Já persistir no erro é teimosia e falta de inteligência.
Portanto, aprender com os próprios erros e não repeti-los, além de sábio, vai torná-lo um melhor programador.
Para ajudá-lo, vou mostrar 7 dos principais erros que podem ser encontrados com frequência e que você deve evitar.
Relação entre falha, erro e defeito:
- Falha – resultado ou manifestação de um ou mais defeitos (diferença indesejável entre o observado e o esperado (defeito encontrado).
- Um Erro (error) indica que certas funcionalidades do software não estão se comportando como especificado;(engano cometido por seres humanos;)
- O Defeito (failure) é a manifestação do erro, seja através de uma tela com uma mensagem para o usuário etc (resultado de um erro encontrado num código ou num documento).
1 – Tratamento de strings – evite concatenar strings usando o operador +
Quando você for tratar com strings, deve sempre acender a luz vermelha de atenção máxima, pois você pode cometer erros que podem lhe custar muito caro se descuidar no tratamento de strings.
O tipo String é um tipo de referência e é sempre imutável (repita: IMUTÁVEL). Portanto, quando você altera uma string, ela SEMPRE cria uma NOVA cópia e NUNCA muda o original.
Agora preste atenção no que eu vou escrever:
Cada vez que você usa um dos métodos da classe System.String, você cria um novo objeto string na memória que requer uma nova alocação de espaço para o novo objeto.
Então veja esse código que pode ser encontrando em muitos exemplo de aplicações que acessam um banco de dados e usam SQL para isso:
Problema:
string sql_AtualizaDados = “UPDATE Clientes SET Nome='” + nome + “‘ WHERE Codigo=” + id;
O que há de errado com esse código?
Além de ser confuso, estamos realizando a concatenação com strings, e strings são imutáveis, logo esse código cria três cópias de strings na memória como resultado das três concatenações feitas.
Dessa forma, estamos alocando espaço em memória para três cópias de strings de forma totalmente desnecessária.
Como realizar o tratamento da string neste caso? Usando o método string.Format.
O método string.Format utiliza internamente StringBuilder, que é mutável. Veja abaixo como ficou a declaração:
Solução:
string sql_Atualiza = string.Format(“UPDATE Clientes SET Nome='{0}’ WHERE Codigo={1}”, nome, id);
Uma operação de concatenação de String sempre aloca memória, ao passo que uma operação de concatenação com StringBuilder só aloca memória se o buffer do objeto StringBuilder for pequeno demais para acomodar os novos dados.
Assim, um objeto StringBuilder é preferível para uma operação de concatenação se um número arbitrário de cadeias são concatenadas.
2 – Tratamento de exceção – em métodos aninhados, evite realizar o tratamento de exceção em métodos para todos os métodos
Quando você estiver realizando o tratamento de exceções em um código aninhado, fique alerta. Perceba que esse caminho pode levá-lo a realizar o tratamento de exceção para cada método.
Veja o exemplo de um código no qual o tratamento de exceções é feito da forma que deve ser evitada:
public class TratamentoExcecoAninhado
{
public void MetodoPrincipal()
{
try
{
//implementação do código
F1();
}
catch (Exception ex)
{
//Tratamento de exceção
}
}
private void F1()
{
try
{
//implementação do código
F2();
}
catch (Exception ex)
{
//Tratamento de exceção
throw;
}
}
private void F2()
{
try
{
//implementação do código
}
catch (Exception ex)
{
//Tratamento de exceção
throw;
}
}
}
Nessa abordagem, além de estar realizando o tratamento de exceção em cada método, temos um cenário em que podemos ter a mesma exceção tratada muitas vezes, e isso vai impactar o desempenho do seu código.
Para evitar isso, podemos usar a abordagem abaixo, na qual temos o tratamento de exceção em um único lugar, no método MetodoPrincipal:
public void MetodoPrincipal()
{
try
{
//implementação do código
F1();
}
catch (Exception ex)
{
//Tratamento de exceção
}
finally
{
//codigo essencial
}
}
private void F1()
{
//implementação do código
F2();
}
private void F2()
{
//implementação do código
}
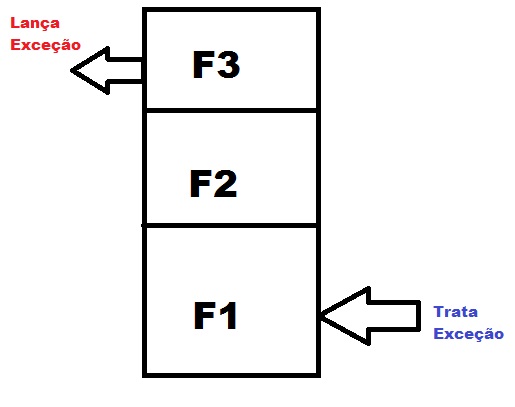
Para entender essa abordagem, considere que:
- O MetodoPrincipal chama F1() dentro do bloco try e manipula a exceção no bloco catch;
- F1() faz uma chamada para o método F2(). Mas nem envolve a chamada de F2() no bloco try, nem tem um manipulador de exceção;
- F2(): gera uma exceção (estamos supondo isso…).
Note que quando a exceção é lançada pelo método F2(), mesmo que o chamador seja F1(), como não há nenhum manipulador catch, a execução sai de F2() e entra no bloco catch do MetodoPrincipal(), viajando de volta da F2-> F1-> MetodoPrincipal.
Assim, uma exceção que ocorre em F2() será tratada pelo MetodoPrincipal mesmo quando não existir tratamento de exceção em F2().
3 – Faço foreach – evite usar um laço foreach em coleções com muitos dados
Você encontra com frequência a utilização do laço foreach. Parece que ele é o preferido dos programadores C#.
Ocorre que, para coleções com uma grande quantidade de dados, usar foreach pode impactar o desempenho do seu código, porque ele usa mais espaço para alocar variáveis.
Então qual a alternativa?
Usar laço for.
Vamos realizar uma comparação entre foreach e for:
versão do laço for
static int MetodoLacoFor(int[] array)
{
int a = 0;
for (int i = 0; i < array.Length; i++)
{
a += array[i];
}
return a;
}
versão do laço foreach
static int MetodoLacoForeach(int[] array)
{
int a = 0;
foreach (int valor in array)
{
a += valor;
}
return a;
}
Se analisarmos a MSIL (MS Intermediate Language), veremos que:
Você já deve saber que o código escrito em uma linguagem .NET, como C# ou Visual Basic, é chamado de código gerenciado, ou seja, o código não é compilado em instruções específicas de código de máquina. Em vez disso, a plataforma .NET compila o código para a MSIL (Microsoft Intermediate Language). A MSIL é um conjunto de instruções independente da máquina que é compilado em tempo de execução pela CLR (Common Language Runtime).
Nessa etapa de compilação extra está o diferencial das linguagens não compiladas, pois o código é executado em uma área protegida (sandbox): o ambiente gerenciado do CLR. Esse ambiente pode proporcionar maior segurança, estabilidade, e pode ser executado em qualquer hardware que possua suporte para CLR, como a máquina virtual (JVM) do Java.
- O MetodoLacoFor usa espaço de pilha suficiente para apenas duas variáveis locais (a e i).
- O MetodoLacoForeach usa espaço de pilha para quatro variáveis locais (a, valor, e duas variáveis temporárias geradas pelo compilado).
Como vemos, as variáveis locais extras geradas pelo laço foreach vão afetar o desempenho do código, principalmente em coleções com muito dados. Por esse motivo, nesses casos, use um laço for.
4 – Validação de tipos de dados primitivos – evite usar métodos customizados para validar tipos primitivos
Parece que grande parte dos desenvolvedores C# se esquecem dos métodos embutidos disponíveis para validar tipos de dados primitivos, como System.Int32.
Quando têm que realizar a validação de tipos primitivos, eles preferem usar uma implementação personalizada.
No exemplo abaixo, vemos um código que verifica se uma variável string é ou não um número.
versão do laço for
public bool VerificaSeENumero(string valor)
{
bool isNumerico = true;
try
{
int i = Convert.ToInt32(valor);
}
catch (FormatException ex)
{
isNumerico = false;
}
return isNumerico;
}
Podemos realizar a mesma validação usando o método int32.TryParse(string,Int32), que converte a representação da cadeia de caracteres de um número no inteiro assinado de 32 bits equivalente. Um valor de retorno indica se a conversão foi bem-sucedida.
A seguir, temos o código que usa o método int.TryParse():
Problema:
public bool VerificaSeENumero(string valor)
{
int saida = 0;
bool isNumerico = int.TryParse(valor, out saida);
return isNumerico;
}
É mais rápido e legível.
5 – Implementação da interface IDisposable() no tratamento de objetos – evite retardar a liberação dos recursos usados
Na plataforma .NET quando utilizamos qualquer objeto para consumir os seus recursos, nunca devemos nos esquecer de liberar os objetos usados. Isso é particularmente verdade quando usamos objetos de acesso a dados.
No entanto, parece que os desenvolvedores C# se esquecem desse importante detalhe. Veja o código abaixo, encontrado aos montes em exemplos na Internet:
Solução:
public void MetodoDAL()
{
SqlConnection connection = null;
try
{
connection = new SqlConnection("XXXXXXXXXX");
connection.Open();
//implementa o acesso aos dados
}
catch (Exception exception)
{
//tratamento exceção
}
finally
{
connection.Close();
connection.Dispose();
}
}
Nesse código, a liberação da conexão é chamada explicitamente no bloco finally.
No caso de haver uma exceção, o bloco catch será executado e depois o bloco será finally será executado para eliminar a conexão.
Então, a ligação é deixada na memória até que o último bloco seja executado. No .NET Framework, uma das diretrizes básicas é liberar o recurso quando ele não estiver mais sendo usado.
Para nos adequarmos a essa regra, vamos usar o código a seguir
Problema:
public void MetodoDAL()
{
using (SqlConnection connection = new SqlConnection("XXXXXXXXXX"))
{
connection.Open();
//implementar acesso aos dados
}
}
Quando usamos o bloco using, o método dispose no objeto será chamado assim que a execução sair do bloco.
Isso garante que o recurso SqlConnection seja descartado e liberado o mais cedo possível. Você também deve observar que isso vai funcionar em classes que implementam a interface IDisposable.
6 – Declarando variáveis públicas – evite declarar variáveis públicas
A declaração de variáveis deve merecer atenção redobrada, pois pode ser o foco de erros difíceis de localizar.
Lembre-se de que um dos pilares da orientação a objetos é o encapsulamento. No entanto, não é difícil encontrar código como o que vemos a seguir:
Nota: Uma das principais características das linguagens orientadas a objetos é fornecer mecanismos para a implementação de códigos seguros, ou seja, é garantir que as variáveis de uma classe recebam exatamente os valores que se espera que elas recebam. O encapsulamento esconde os detalhes de implementação de uma classe.
Problema:
static void Main(string[] args)
{
Teste teste = new Teste();
//Temos acesso a variável publica e podemos atribuir qualquer valor a ela
teste.numeroConta = "ZZZZZZZZZ";
Console.ReadKey();
}
public class Teste
{
public string numeroConta;
public Teste()
{
numeroConta = "XXXXX";
}
}
Observe que foi definida uma variável pública (numeroConta), que é usada no construtor da classe Teste().
Esse descuido fere o encapsulamento, visto que qualquer um pode criar uma instância da classe e acessar a variável publica alterando o seu valor.
O correto é usar uma propriedade para definir a variável pública numeroConta, conforme o código a seguir:
Problema:
public class Teste()
{
private string _numeroConta;
public string NumeroConta
{
get { return _numeroConta} ;
}
public Teste()
{
_numeroConta = "XXXXX";
}
}
Agora temos uma propriedade NumeroConta() que permite somente acessar o valor da variável, alterações não são permitidas.
A classe Teste agora tem controle sobre NumeroConta.
Quando precisar de uma variável global, faça isso usando uma propriedade.
7 – Valores-padrão para variáveis não inicializadas – evite considerar como null o valor padrão de tipos por valor
Ponha isto na sua cabeça: em C #, os tipos de valor não podem ser nulos.
Por definição, tipos de valor têm um valor, e até variáveis não inicializadas de tipos de valor devem ter um valor.
Isso é chamado o valor padrão para esse tipo e, se não for compreendido e corretamente tratado, traz como consequência valores inesperados quando você for verificar se uma variável foi inicializada.
Veja este código:
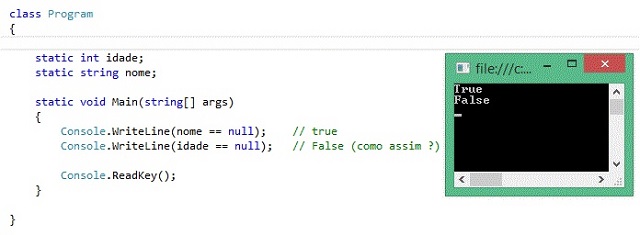
Por que idade não é null?
A resposta é que idade é um tipo de valor, e o valor padrão para uma idade é 0, e não nulo.
A incapacidade de reconhecer isso é um erro muito fácil (e comum) de se cometer em um código C#.
Muitos (mas não todos, incluindo o tipo int) tipos de valor têm uma propriedade IsEmpty, que você pode usar para verificar é igual ao seu valor padrão:
Console.WriteLine (tipoPorValor.IsEmpty); // true
Então quando você for verificar se uma variável foi inicializada ou não, é bom conhecer o tipo da variável e o seu valor padrão de inicialização, e não apenas considerar que todas as variáveis não inicializadas têm valor nulo.
Estes são os 7 erros básicos (é claro que existem mais…) que geralmente são cometidos por programadores C# e que podem ser evitados.
Seu código agradece…

De 0 a 10, o quanto você recomendaria este artigo para um amigo?