

Este artigo será o primeiro de uma série de três, onde falaremos sobre Storage relacionado à SQL Server. Conceitos, melhores e piores praticas.
RAID (Redundant Array of Independent Disk) ou (Matriz Redundante de Discos Independentes) é um assunto muito presente no dia a dia do DBA, Seja no momento de criar uma nova arquitetura, no troubleshooting de um problema de performance, em um relatório de dimensionamento de hardware para o próximo ano, entre outros.
Banco de dados e discos são mais íntimos do que podemos imaginar; e o RAID assume um papel muito importante nesse relacionamento, podendo sair como vilão ou salvador da pátria, tudo depende da forma como configuramos.
Conceitualmente, podemos definir RAID como uma inteligência composta por diversos discos físicos onde é nomeado de ARRAY, com o objetivo de escalonar a capacidade de armazenamento e proporcionar maior segurança e performance.
Dentro desse conceito, existem três grandes pilares que sustentam o RAID: espelhamento, divisão e paridade.
E com bases nesses pilares, são criadas as configurações de RAID para funcionar da melhor maneira possível em cada ambiente, de acordo com a necessidade. Vamos ver algumas das configurações mais “famosas” e mais utilizadas, e também as mais recomendas para ambientes SQL Server.
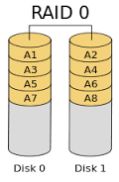
RAID level 0 – (Striped Disk Array no Fault Tolerance)
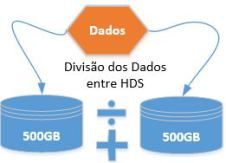
Neste nível, ocorre a divisão dos dados (small blocks) entre os discos que compõe o Array (conjunto de discos físicos). Na prática, o dado é quebrado em pequenos blocos e gravado fisicamente em discos diferentes.
Principais vantagens:
- Grande ganho de I/O devido a utilização de vários discos (treads) para gravação da informação;
- Foco em desempenho;
- Não tem “perda” de espaço, pois não espelha o dado. 100% dos HDs são utilizados para armazenamento.
Principais desvantagens:
- Não tem tolerância a falha. Caso ocorra a falha de um disco, perdemos toda informação.
- Não é aconselhado para sistemas com dados críticos.
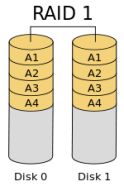
RAID level 1 – (Mirroring and Duplexing)
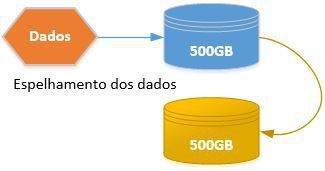
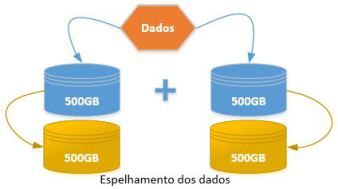
Neste nível, ocorre o Mirror entre dois ou mais discos. Onde os dados são duplicados entre os discos do array, garantindo uma tolerância a falha. Pode ser notado uma ligeira melhora em leitura, porém “pode” ocorrer degradação em escrita.
Principais vantagens:
- Tolerância a falha, devido ao espelhamento entre discos físicos;
- Ganho considerável em operações de leitura.
Principais desvantagens:
- Será utilizado o dobro de armazenado, devido ao espelhamento. Por exemplo, se temos a necessidade de armazenar 500GB, será necessário ter 1TB disponível para tal operação. 500GB para os dados “quentes” e 500GB para o espelhamento. Logo, o custo em $ aumenta.
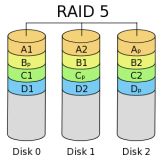
RAID level 5 – (Independent Data Disk With Distributed Parity)
Neste nível, a divisão é realizada em blocos de dados entre os discos do array. Com uma diferença, cada bloquinho é marcado com um bit adicional, e este bit é a paridade.
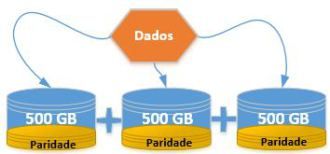
Como regra, a paridade teoricamente ocupa o espaço equivalente a um HD contido no array. Por exemplo, se o array contem 3 HDs de 500GB, teremos 1 TB para armazenado e 500GB será alocado para paridade. Assim, o RAID 5 também é tolerante a falha, garantindo maior segurança.
Principais vantagens:
- Relação custo x Beneficio legal em relação a Performance e $;
- Múltiplas threads, o que pode gerar ganhos em I/O.
Principais desvantagens:
- Perda em média de 1/3 do armazenamento, devido a alocação da paridade.
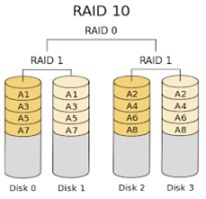
RAID level 10 ou 0+1 – (Very High Reliability Combined with High Performance)
Neste nível, as características do RAID 1 são somadas com o RAID 0, criando uma configuração hibrida de desempenho + redundância. Excelente para ambientes críticos, suportando várias falhas de hardware, e também boa performance em grandes volumes de dados.
Principais vantagens:
- Tolerância a falha eficiente;
- Performance otimizada para grandes volumes de dados, sistemas críticos em segurança e desempenho.
Principais desvantagens:
- Custo $ alto para implementação, devido a quantidade mínima de armazenamento requerida.
Ok, Luiz, mas qual deles é o melhor para meu ambiente SQL? A resposta é “depende”. Depende da criticidade do seu banco, depende do quanto de $ tem para investir, do negocio da sua empresa…
Por default, eu gosto e já vi em vários blogs e artigos a utilização de diferentes configurações para MDF, LDF, Tempdb, Backup, como por exemplo:
-> RAID (5) para MDF, NDF
-> RAID (1) para LDF
-> RAID (0 ou 10) para TempDB
-> RAID (5 ou 6) para Backup
Claro, isso depende do gosto do freguês e também do hardware que a empresa dispõe (eu gostaria muito de poder fazer tudo em RAID 10). Escolher a melhor configuração nos força a compreender melhor os conceitos de RAID e entender o negócio da empresa, assim, conseguiremos encontrar a melhor estratégia para cada cenário.
Grande abraço e bons estudos.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?